








作者:Abhinav Sagar
翻译: 申利彬
校对: 吴金笛
本文约
2700字 ,建议阅读
7分钟 。
本文可以让你把训练好的机器学习模型使用Flask API 投入生产环境。
本文旨在让您把训练好的机器学习模型通过Flask API 投入到生产环境 。
当数据科学或者机器学习工程师使用Scikit-learn、Tensorflow、Keras 、PyTorch等框架部署机器学习模型时,最终的目的都是使其投入生产。通常,我们在做机器学习项目的过程中,将注意力集中在数据分析,特征工程,调整参数等方面。但是,我们往往会忘记主要目标,即从模型预测结果中获得实际的价值。
部署机器学习模型或者将模型投入生产,意味着将模型提供给最终的用户或系统使用。
然而机器学习模型部署具有一定的复杂性,本文可以让你把训练好的机器学习模型使用Flask API 投入生产环境。
我将使用线性回归,通过利率和前两个月的销售额来预测第三个月的销售额。
线性回归是什么?
线性回归模型的目标是找出一个或多个特征(自变量)和一个连续目标变量(因变量)之间的关系。如果只有一个特征,则称为单变量线性回归;如果有多个特征,则称为多元线性回归。
线性回归的假设
线性回归模型可以用下面的等式表示:
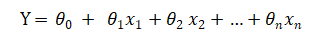

线性回归图解
为什么使用Flask?
容易上手使用
内置开发工具和调试工具
集成单元测试功能
平稳的请求调度
详尽的文档
项目结构
这个项目分为四个部分:
1. model.py -- 包含机器学习模型的代码,用于根据前两个月的销售额预测第三个月的销售额。
2. app.py – 包含用于从图形用户界面(GUI)或者API调用获得详细销售数据的Flask API,Flask API根据我们的模型计算预测值并返回。
3. request.py -- 使用requests模块调用app.py中定义的API并显示返回值。
4. HTML/CSS – 包含HTML模板和CSS风格代码,允许用户输入销售细节并显示第三个月的预测值。
</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 733
733











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









