






flask部署机器学习
The deployment of the machine learning model is rarely discussed. Most of the data science programs, online courses do not focus on model deployment. It is one of the important and last stages in the machine learning life cycle. To start using your machine learning model for practical decision-making, it needs to be effectively deployed into production. The focus of this article is to deploy a machine learning model using a flask.
很少讨论机器学习模型的部署。 在大多数数据科学计划中,在线课程并不专注于模型部署。 它是机器学习生命周期中重要且最后的阶段之一。 要开始将机器学习模型用于实际决策,需要将其有效地部署到生产中。 本文的重点是使用烧瓶部署机器学习模型。
Here I am using mall customer dataset to understand customer behavior. We are going to build a clustering model on historic data. Using this model we can predict the behavior of the new customer.
在这里,我使用商场客户数据集来了解客户行为。 我们将基于历史数据构建聚类模型。 使用此模型,我们可以预测新客户的行为。
Let’s build our model using k-means clustering.
让我们使用k-均值聚类建立模型。
Import Libraries
导入库
We need to import all the required libraries
我们需要导入所有必需的库

2. Get the data
2.获取数据

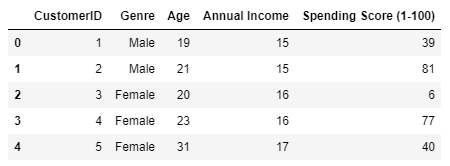
Getting the dataset is not enough. We have to perform exploratory data analysis.
仅获取数据集还不够。 我们必须进行探索性数据分析。
3. Perform Exploratory Data Analysis
3.执行探索性数据分析
I have performed some initial analysis of this data. In this article, we will not more focus on EDA.
我已经对该数据进行了一些初步分析。 在本文中,我们将不再专注于EDA。

4. Model Building
4.模型制作
Now it’s time to cluster the data. Here we are clustering our data using k-means.
现在是时候对数据进行聚类了。 在这里,我们使用k均值对数据进行聚类。
We are clustering our data based on annual income and spending scores. For our dataset, we are using the elbow method to find the optimum number of clusters.
我们正在根据年收入和支出得分对数据进行聚类。 对于我们的数据集,我们使用弯头法找到最佳的聚类数。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 744
744











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









