







 本文探讨了如何通过可视化和统计方法比较两个或多个分布的形态。从箱线图、直方图、核密度图、累积分布图和Q-Q图等多个角度展示了比较方法,以及使用t检验、Mann-Whitney U检验、置换检验、卡方检验和Kolmogorov-Smirnov检验等统计检验。通过实例和代码,阐述了在数据分析和因果推断中如何评估分布的差异和相似性。
本文探讨了如何通过可视化和统计方法比较两个或多个分布的形态。从箱线图、直方图、核密度图、累积分布图和Q-Q图等多个角度展示了比较方法,以及使用t检验、Mann-Whitney U检验、置换检验、卡方检验和Kolmogorov-Smirnov检验等统计检验。通过实例和代码,阐述了在数据分析和因果推断中如何评估分布的差异和相似性。

作者:Matteo Courthoud
翻译:陈超
校对:赵茹萱
本文约7700字,建议阅读15分钟
本文从可视化绘图视角和统计检验的方法两种角度介绍了比较两个或多个数据分布形态的方法。从可视化到统计检验全方位分布形态比较指南:
图片来自作者
比较同一变量在不同组别之间的经验分布是数据科学当中的常见问题,尤其在因果推断中,我们经常在需要评估随机化质量时遇到上述问题。
我们想评估某一政策的效果(或者用户体验功能,广告宣传,药物,……),因果推断当中的金标准就是随机对照试验,也叫作A/B测试。在实际情况下,我们会选择一个样本进行研究,随机分为对照组和实验组,并且比较两组之间结果差异。随机化能够确保两组间唯一的差异是是否接受治疗,平均而言,以便于我们可以将结果差异归因于治疗效应。
问题是,尽管进行了随机化,两组也不会完全相同。有时,他们甚至不是“相似的”。例如,我们可能会在一组中有更多男性或年龄更大的人,等等(我们通常把这些叫做特质协变量或控制变量)。这种情况发生时,我们再也无法确定结果的差异仅仅是由治疗的效果导致,也不能将其完全归因于不平衡的协变量。因此,随机化之后非常重要的一步就是检查是否所有观测变量都是组间平衡的,是否不存在系统性差异。另外一个选择是分层抽样,额可以事先确保特定协变量是平衡的。
在本文中,我们将通过不同方式比较两组(或多组)分布并评估他们之间差异的量级和显著性水平。可视化和统计角度这两种方法通常是严谨性和直觉的权衡:从图上,我们可以迅速评估和探究差异,但是很难区分这些差异是否是系统性的还是仅仅由于噪声导致。
例子
假设我们需要将一组人随机分到处理组和对照组。我们需要让两组尽可能地相似,以便于将组间差异归因于治疗效应。我们也需要将处理组分成几个亚组来测试不同治疗的影响(例如,同一种药物的细微变化)。
对于这个例子来说,我们已经模拟了1000个被试数据集,我从src.dgp导入了数据生成过程dgp_rnd_assignment(),并从src.utils导入了一些绘图函数和库,从而观测到一系列特征。
from src.utils import *
from src.dgp import dgp_rnd_assignment
df = dgp_rnd_assignment().generate_data()
df.head()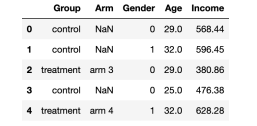
数据快照,图片来自作者
我们有1000个被试的信息,从中可以观测到性别、年龄和周收入。每个被试被分配到处理组或对照组,被分到处理组的被试又被分到四种不同的治疗亚组当中去。
两组-图
让我们从最简单的情况开始:比较处理组和对照组的收入分布。首先用可视化方法来进行探究,然后再使用统计方法。可视化方法的优势在于直观,而统计方法方法的优势则在于严谨。
对大多数可视化来说,我会使用python当中的searborn库。
箱线图
第一种可视化方法是箱线图。箱线图是统计概要和数据可视化之间的很好的兑易。箱体的中心表征中位数,上下边界则表征第1和第3百分位数。须体延长到超过箱体四分位数(Q3-Q1)1.5倍的第一个数据点。落在须体之外的点则分别绘制,且通常被视作异常值。
因此,箱线图提供了统计概要(箱体和须体)以及直观的数据可视化(异常值)。
sns.boxplot(data=df, x='Group', y='Income');plt.title("Boxplot");
处理组合对照组的收入分布,图片来自作者
看起来处理组的收入分布更加分散:橘色箱体更大,须体覆盖范围更广。然而,箱线图的问题在于它隐藏了数据的形态,仅仅告诉我们统计概要而未向我们展示真实的数据分布情况。
直方图
直方图是展示分布最直观的方式,它将数据分成同等宽度的组,将每组观测值数量画出来。
sns.histplot(data=df, x='Income', hue='Group', bins=50);plt.title("Histogram");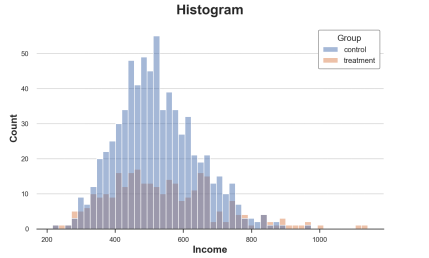
处理组和对照组的收入分布情况,图片来自作者
该图也存在很多问题:
因为两组观测值数量不同,两个直方图不具备可比性。
分组的数量是武断的。
我们可以通过stat选项来解决第一个方法,绘制density而非计数,将common_norm选项设置为False来分别对每个直方图进行归一化。
sns.histplot(data=df, x='Income', hue='Group', bins=50, stat='density', common_norm=False);plt.title("Density Histogram");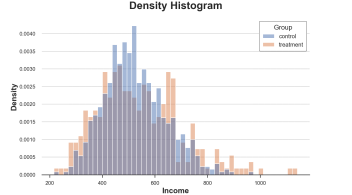
处理组和对照组的分布,图片来自作者
现在两组直方图就可比较了!
然而,一个重要的问题仍然存在:分组的大小是武断的。在极端情况下,如果我们把更少的数据捆绑在一起,最后会得到每组至多一条观测数据,如果我们把更多的数据捆绑在一起,我们最终可能会得到一个组。在两种情况下,如果我们夸大,图就会损失信息量。这就是经典的偏差-变异兑易。
核密度图
一种可能的解决方法是使用核密度函数,使用核密度估计(KDE)用连续函数近似直方图。
sns.kdeplot(x='Income', data=df, hue='Group', common_norm=False);plt.title("Kernel Density Function"); 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1525
1525

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









