







来源:人工智能大讲堂
本文约7100字,建议阅读10分钟
只要人人都追求无偏差,世界会变成美好的人间。作者:张英锋
链接:https://www.zhihu.com/question/20099757/answer/658048814
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
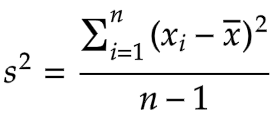
为什么样本方差(sample variance)的分母是 n-1?或者,怎么理解统计学中「自由度」这个概念?
这是一个非常好的问题,探索这个问题的答案,不仅能更好地了解自己和这个世界,还能避免被征收“偏差税”Bias Tax!
先说结论,样本标准差的分母写成n-1,是为了对自由度进行校正,这叫贝塞尔校正(Bessel's Correction)[1]。注意这个贝塞尔不是贝塞尔曲线(Bézier curve)那个贝塞尔。
为了让中学水平的读者就能理解,我尽量不用公式,用浅显的语言和生活中的案例,来叙述这个问题的来龙去脉。这算是对其他答案的补充,也许看完后,再看其他高手的回答就没那么难了。
在统计领域,你经常会看到,为了减少干扰数据对结论的影响,数学家设计了大量的技术手段来对数据进行校正。
先看一篇我改编的故事《比尔盖茨冲进酒吧》:
一天晚上,小镇酒吧里坐着9个人,大家都是小镇上的工薪族,年薪的平均值在5万美元左右。
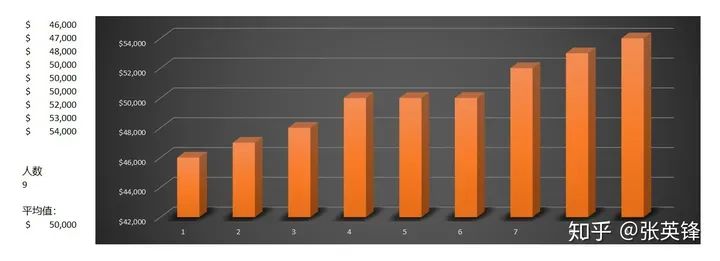
从上面的数据和图表,你可以看出50000美元这个平均值,比较准确地体现了9个人的收入水平。
正在此时,比尔盖茨急匆匆地走进酒吧,冲向厕所……
假如比尔盖茨的年薪是10亿美元,在他上厕所的时间里,另外9个人啥也没做,加上比尔盖茨,10个人的平均年薪平均值一下子从5万爆涨到1亿美元。
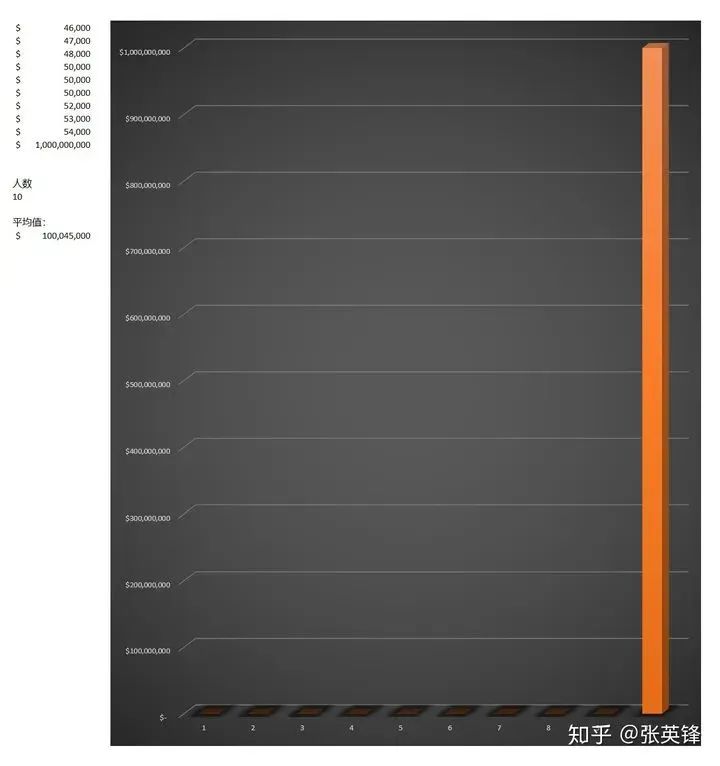
如图,相比之下,和比尔盖茨相比,9人的年薪太渣,完全看不出高度,像二向箔一样薄。
而当比尔盖茨离开后,他们还是啥也没做,平均年薪却暴跌了近1亿美元。
9人抱头哭死在厕所……
剧终^_^
在这个例子里,比尔盖茨就是一个干扰数据,因为他的存在,让平均值的计算并不能体现酒吧里工薪族的真实平均水平,9人的平均年薪无缘无故地涨到了1亿。当然这个数也无法体现比尔盖茨的真实收入水平,因为他缩水到了1亿。
那统计学家应该怎么办呢?
在统计上,把比尔盖茨这种干扰数据称为异常值(Outlier)。
应对这种异常值,最简单的方法就是排除掉它们。在计算平均值时把比尔盖茨排除掉,就无法干扰平均值了。(当然实际应用比较复杂,排除异常值需要谨慎,不能随意的排除)
排除法这种技术手段也经常应用在比赛打分上。
我们知道裁判打分的主观性非常大,为了减少单个教练的影响,比赛通常会安排多个裁判一起给选手打分,然后再取一个平均值。
但实际上在求平均值时,还会再去掉最高分和最低分,然后对剩下的分数计算平均值。
这种排除最高/低分的手段也是为了消除干扰,因为最高分和最低分对平均值的影响比较大,会大幅偏离真实的水平。
例如,下面是10个裁判的打分:
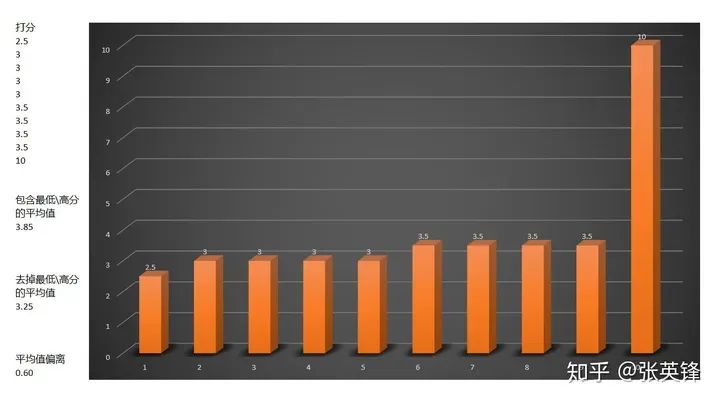
上图中最高分把选手的平均值拉高了0.60分,你可能会说,这点分数不算啥,应该影响不大。
但在实际的比赛中,选手的差距通常非常的小,0.1分都会对选手的排名产生显著的影响。
为了尽可能消除其干扰,得到一个相对客观的平均值,通常在计算平均值时,会排除掉最低分和最高分,这样算出来的平均值叫裁剪平均值(Truncated mean)。
比尔盖茨和去掉最高/低分的这两个例子,都是为了说明统计领域的校正技术,用排除法来消除掉干扰数据的影响。
现在你也可能意识到了,在样本方差的计算上,分母使用(n-1),而不是n,也是一种排除法来消除干扰的技术手段。
为什么要减去1,这个1代表的是哪个数?
这个减去的1,不特指任何一个数,1代表那个失去“独立客观”的维度(自由度)。
看不明白?
正常,听我慢慢解释。
在我们在对全体进行采样时,有一个至关重要的前提条件,就是一定要随机采样,这其中的关键词是随机。
之所以要随机,这是为了避免出现样本偏差。因为如果样本错了,后面的计算步骤即使全部都正确,最终结果也是错的。
例如,要想回答“中国人是不是喜欢吃狗肉?”的问题。

请问,以下两个采样,哪一个能得到客观的结论?
只去玉林狗肉节上采样。
对中国人进行时间和地点都随机的采样。
两种采样方法,会得出截然相反的结论:
前一种采样很不自由,被限制在一个极其有限的时空里。
后一种采样有充分的自由,跳出限制,可以没有干扰的随机采样。
如果只在玉林采样,这个样本就是偏差样本(Biased Sample),是不具代表性的样本(Unrepresentative Sample)。
如果根据这个偏差样本,得出了“中国人居然吃狗肉,太野蛮了!”的结论。无论在逻辑上如何完美,最终结论也是荒谬的。
这就是所谓的“垃圾进,垃圾出”(Garbage in , garbage out)[2]
你在玉林采样越多,你的偏见就会越深,只会进一步的固化你的偏见。
但自由的随机采样,你采样越多,你的偏见就会越来越少,看到更真实、更多样化的中国人。
在这里需要暂停一下:请大家反思一下,自己是不是也曾犯过同样的错误,取错了样本,出现了偏差或偏见(Bias)?
反正,我经常会犯这样的错误,轻易就相信传言[3],或轻易给别人扣上帽子[4],这都是偏见。
(罪过,罪过,宽恕我吧,我知道自己错了!)
我们普通人经常会因为样本偏差,被收取“偏差税”(Bias Tax)
例如彩票,就是利用了人们的这一弱点。
彩民们只注意到了那些极少数获得大奖的人,看不到绝大数人赔钱。
越是盯着那些获奖的人看,彩民们的偏见越深,越是坚信自己会中奖。
他们因为在选取样本时出现偏差,而被别人收税。
好吧,我承认,偏差税这个词是我根据智商税这个词编造出来的(^_-)。
很多人喜欢用智商税这个词来嘲笑犯错的人智商低,但智商税这个词是有偏差的。
因为不能根据一个事件就推算出一个人整体的智商,这是不具代表性的有偏样本,这是偏见。
例如很多彩民的智商很高,他们使用各种复杂的公式,做了大量复杂的计算,他们的智商一点都不低,他们的问题是出在样本偏差上。
而偏差税这个词和智商税不一样,不论我们的智商高低,人人都会有偏见,事事都会出偏差,这个税每个人都在交。
例如,股票市场上的散户,迷信中医和保健品的大爷大妈,轻信谣言的吃瓜群众,……,几乎无人可以幸免,都在为样本偏差付出代价。
推荐一个TED演讲《为什么应该热衷于统计学》。
看完就知道人们对这个世界的偏差有多大了。
所以人们不是智商出了问题,是在选取样本时出现了偏差,所以偏差税是一个更客观(无偏)的词。
其实,不仅是普罗大众,就是那些权倾一时的政治家,也曾为样本偏差付出过惨重的代价。
1948年美国大选,大部分报纸都预测杜威会战胜杜鲁门,当选美国总统。社会舆论一致看好杜威,以至于竞选当天,杜威认为杜鲁门很快就会打电话庆祝他当选。
但竞选结果却大跌眼镜,最终是杜鲁门当选。(是不是有些似曾相识?)

杜鲁门获胜后,兴高采烈的举着那些提前预测杜威击败杜鲁门的报纸,笑得好真诚啊!图片来源:https://www.youtube.com/watch?v=h4uUV1klrkM
这次的预测之所以会失败,是因为调查机构通过电话调查的方式做的采样。
1948年,虽然电话已发明多年,但价格并不便宜,有电话的多是相对富裕的家庭,多数人的家里没有普及电话。也就是说,这种采样是有偏差的,只反映了富裕阶层的观点,无法反映当时主流选民的意愿,也就是统计出现了样本偏差。[5]
在当时,除了很多美国人被误导,还有一个人也因为这个样本偏差,把所有筹码错压在了杜威的身上,结果却因此而丢掉了整个江山,此人就是蒋介石。本来杜鲁门在做副总统时就对蒋介石印象很差,在他当选后,更是变本加厉,很快减少了对蒋介石的援助。[6]
常凯申也哭死在厕所!
事实上,有太多的仇恨、歧视、偏见和武断的观点,是建立在样本偏差的垃圾数据之上的。
因为“垃圾进,垃圾出”,无论人们如何雄辩,逻辑上如何完美,算法上如何先进,结论也是一堆错误的垃圾。[7]
这是值得你、我、以及所有人都应该警惕的现象。
例如:你想知道当代日本人是怎样的。就不能只对抗日神剧进行采样,不能只对日本右翼进行采样,要获得真实的数据,必须去日本实地对日本人进行随机采样。
只有采样是随机,是不带偏差的(Unbiased),才能保证自己吃进去的不是垃圾信息,这是得出正确结论的第一步。
只要人人都追求无偏差,世界会变成美好的人间。
除了要做到采样是随机的,还要确保样本之间是互相独立的,在统计上用自由度(Degrees of freedom)来描述这种独立性。
我们以常见的招投标为案例,解释一下独立性。
有个学校要盖教学楼,邀请几个建筑公司来投标。学校希望建筑公司的报价尽可能低,而且还要确保质量。所以学校不能只选价格最低的方案,而是要挑选出综合评分最优的方案。
要做到公正客观的评分,必须确保几件事:
首先,学校不能让内部员工来评分,因为内部员工和项目有直接的利益关系,员工都希望自己在项目中获得更多利益,做不到评分上客观独立。
所以学校只能从外部请专家来评标,因为外人独立于学校之外,会减少直接利益所产生的影响。
于是学校计划邀请3个专家来评审,让专家对建筑公司的方案和报价进行综合评分。
其次,学校在挑选专家时,要尽可能确保这些专家之间的观点也必须是互相独立的,不能人云亦云。
假如其中1人是另外2人的上级,那上级说话,下级的观点就倾向于和上级保持一致,在评分时无法做到独立,这样的评分是有偏差的。花了3个专家的钱,却成了1个专家的一言堂。专家独立性从3变成了1,这偏差也太大了。
最后,学校还必须确保,任何一个专家都没有被建筑公司收买,是独立于建筑公司,没有利益输送的。
如果被收买了,专家就会修改评分,让贿赂的商家胜出,这个专家的数据也是不独立客观的。
从上面的这个案例里,你会发现独立的重要性,一旦出现利益关联,独立性就会降低,数据必然会出现偏差。
类似的制度设计非常的广泛,例如陪审团制度,就设计了大量的机制来保证陪审团成员的独立性。

电影《十二怒汉》剧照推荐重温一下《十二怒汉》这部经典,看看人们的偏见(Bias)是如何的根深蒂固,消除偏见是如何的困难。
几千年来,人类为了提高独立性,殚精竭虑的设计了各种精巧的制度,这些制度历久弥坚,逐渐成为了现代社会的基石。
在统计实践中人们发现,偏差的产生,很多时候也是因为样本数据之间出现了各种隐含的关联关系,降低了数据之间的独立性。
而解决的策略还很清晰,就是发现其中隐含的关联关系,然后进行校正。
让我们再回到样本方差(Sample Variance)的分母(n-1)上来。
你既然在看这个问题,那就已经知道了方差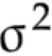 的计算公式:
的计算公式:
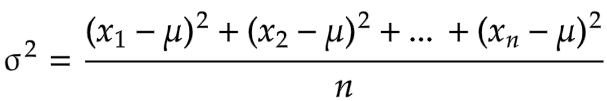
需要注意的是这里的方差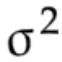 其实是全体的方差,μ是全体的平均值,n是全体变量的数量。
其实是全体的方差,μ是全体的平均值,n是全体变量的数量。
例如一家啤酒厂每天生产1万瓶啤酒,我们想知道这些啤酒的质量差异性如何,可以打开这1万瓶啤酒测量,再把所有测量结果代入到上面的公式里求方差,在计算中,没有漏下任何一瓶啤酒的数据。
你也发现了,这样做不仅麻烦了,而且成本极高。
更好方法是对出厂的啤酒进行随机的采样,计算这部分样本的方差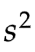 。
。
例如,随机的从产品中找出100瓶,用这100瓶来估算1万瓶啤酒的质量差异,注意,除了这100瓶的数据,其他9900瓶啤酒数据是完全未知的。
样本方差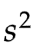 它是从全体数据中随机取出一小部分所做的计算,用这个局部的100瓶啤酒的方差去估计全体1万瓶啤酒的方差。
它是从全体数据中随机取出一小部分所做的计算,用这个局部的100瓶啤酒的方差去估计全体1万瓶啤酒的方差。
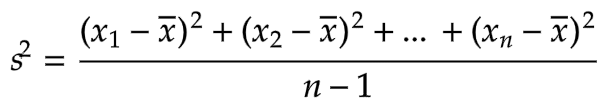
上面这个样本方差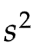 公式,尽管在形式上和全体方差
公式,尽管在形式上和全体方差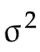 的公式近似,但是内涵上发生了天翻地覆的变化。
的公式近似,但是内涵上发生了天翻地覆的变化。
我们来比较一下,全体方差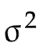 和样本方差
和样本方差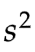 :
:
全体方差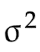 是一个客观事实(Fact),是对所有个体数据的全体所作的客观描述(Describe)。
是一个客观事实(Fact),是对所有个体数据的全体所作的客观描述(Describe)。
而样本方差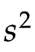 更像一个观点(Opinion),是我们根据少量抽样个体的数据,对全体所作出的估算(Estimation),或者说是预测。
更像一个观点(Opinion),是我们根据少量抽样个体的数据,对全体所作出的估算(Estimation),或者说是预测。
既然样本方差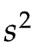 不是一个事实,而是一个观点,是一种估算,为了让这个估算尽可能的接近事实,就必须注意样本不要出现偏差(Bias),否则就会“垃圾进,垃圾出”,得出错误的估算。
不是一个事实,而是一个观点,是一种估算,为了让这个估算尽可能的接近事实,就必须注意样本不要出现偏差(Bias),否则就会“垃圾进,垃圾出”,得出错误的估算。
例如:
我们不能只对某批产品取样,某个特定时间取样,我们的随机取样必须尽可能地覆盖所有批次,取样要有充分的自由度,足够的随机。
另外还要注意,避免样本里的变量之间存在隐含的关联关系。
我们来看一个例子:
假设随机抽出的样本里只有两个数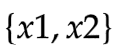
如果这2个数是独立和随机抽取的,你就不能从x1猜出x2,例如我告诉你x1=10,请问x2等于多少?
你根本猜不出来,因为随机抽取让x2和x1之间没有关联。
但是,没想到的是,因为一个数据的存在,让这个随机取样产生了一个隐含的关联关系。
这个数就是计算样本方差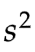 时,需要用到的样本平均值
时,需要用到的样本平均值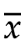 ,他的引入让随机抽取的独立性和自由度减少了一点点。
,他的引入让随机抽取的独立性和自由度减少了一点点。
因为样本平均值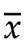 引入了一些信息,让x1和x2之间不再是相互独立的关系了。
引入了一些信息,让x1和x2之间不再是相互独立的关系了。
根据平均值公式:
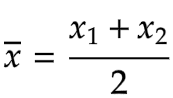
只要知道了x1和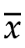 ,就可以计算出x2的值。
,就可以计算出x2的值。
如果x1=10,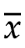 =10,那x2=10
=10,那x2=10
同样,知道了x2和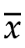 ,就可以计算出x1的值。
,就可以计算出x1的值。
如果x2=10,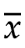 =11,那x1=12
=11,那x1=12
也就是说,出问题的并不是x1或者x2,这两个数本来好好的,互相独立的。出问题的是平均值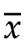 ,他引入的新信息,让样本数据之间的独立性减少了,关联性增加了。
,他引入的新信息,让样本数据之间的独立性减少了,关联性增加了。
或者还可以说,在平均值的介入下,x1和x2的自由度降低了,原来是两个独立的数,现在只有一个独立了,另一个则不再自由,好像有些人云亦云了。
同样的,对于更多的样本量:如果样本是3个数 {x1,x2,x3}
则知道了x1,x2,就能通过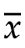 ,计算出x3,独立性或者说自由度,就从3降到了2。
,计算出x3,独立性或者说自由度,就从3降到了2。
如果样本是4个数 {x1,x2,x3,x4}
则知道了x1,x2,x3,就能通过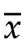 ,计算出x4,独立性或者说自由度,就从4降到了3。
,计算出x4,独立性或者说自由度,就从4降到了3。
……
如果样本是n个数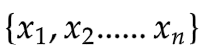 则知道了
则知道了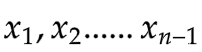 ,就能通过
,就能通过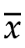 ,计算出
,计算出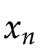 ,独立性或者说自由度,就从n降到了n-1。
,独立性或者说自由度,就从n降到了n-1。
平均值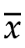 让样本的独立性或自由度减少了1,导致了样本出现了偏差。
让样本的独立性或自由度减少了1,导致了样本出现了偏差。
这就是为什么样本方差的分母不是n,也不是n-2或n-3,而是n-1的原因。
自由度变小会对样本方差产生什么影响呢?
这意味着,样本方差会变小。
我们知道,方差是通过计算样本和平均值之间的距离,来描述样本的分散程度,数据之间差异越大,方差越大,数据之间越是趋同,方差越小。
还是用专家评分的案例来解释:
如果专家组中,所有人都独立,每个人的评分会出现较大的差异性。
但如果专家组中有个领导,他自己没有任何主见,只是在看完大家的评分之后,取个折中的评分,是个老好人型的领导。
请注意,这个领导没有贡献任何新观点,他的观点不独立,只是重复了别人的观点,但这个重复数据污染了整体数据的独立性,让原本差异性较大数据,因为折中数据的出现,减少了差异,或者说,出现了一些趋同效应,这就产生了偏差。
回到样本方差 上,因为样本平均值
上,因为样本平均值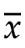 就是根据样本来计算的,样本平均值
就是根据样本来计算的,样本平均值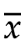 成了那个贡献重复数据的领导,让原来独立的、随机的、没有偏差的样本数据,在计算加工过程中引入了偏差,减少了数据之间的差异性,这种趋同效应让样本方差
成了那个贡献重复数据的领导,让原来独立的、随机的、没有偏差的样本数据,在计算加工过程中引入了偏差,减少了数据之间的差异性,这种趋同效应让样本方差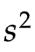 变小。
变小。
也就是说,数据取样没问题,是无偏的。但是在后来的方差计算中,均值的引入,让差异性减少,本来无偏的数据出现了偏差。样本方差会一直小于总体方差,这是一个有偏样本方差。
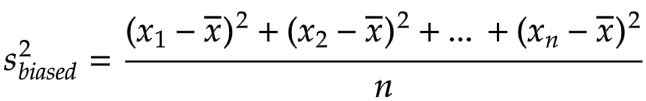
上面是有偏差的样本方差公式,是没有经过校正的。
普鲁士天文学家贝塞尔(Bessel)在对海量的观测数据做计算时,也注意到了这个偏差。
这个偏差的特点是:
在样本量小的时候偏差影响比较明显,样本方差比全体方差偏小。
但是当样本量增大时,偏差逐渐减少,直到影响可以忽略不计。
既然样本方差变小了,那干脆让分母变小,增大样本方差就行了。
贝塞尔给出了修正方法,即把样本方差公式的分母修正为n-1,所以这个修正被后人称为贝塞尔校正。
具体的公式推导过程,可以看Emory University的这篇关于Bessel's Correction推导的文章 [8]

德国天文学家和数学家弗里德里希·威廉·贝塞尔图片出处:https://zh.wikipedia.org/wiki/弗里德里希·威廉·贝塞尔
样本方差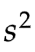 公式里的分母n-1,就是这么来的,那个减去的1,就是用来校正
公式里的分母n-1,就是这么来的,那个减去的1,就是用来校正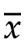 所带来的偏差,他不代表某一个样本,而是对自由度的补偿,让缩小的样本方差重新变大一点。
所带来的偏差,他不代表某一个样本,而是对自由度的补偿,让缩小的样本方差重新变大一点。
样本方差偏小是不是采样出现问题?因为越接近平均值,就越容易被采样?
从直觉上好像是这样的,比如下面的这个鱼类长度的分布,数据聚集在平均值106(蓝线)附近,如果采样,在平均值周围的确有更大的概率被采样到。
但是,直觉是靠不住的。上面的分布只是一种,还有很多的分布,其数据不在平均值附近,而是分散在四处。
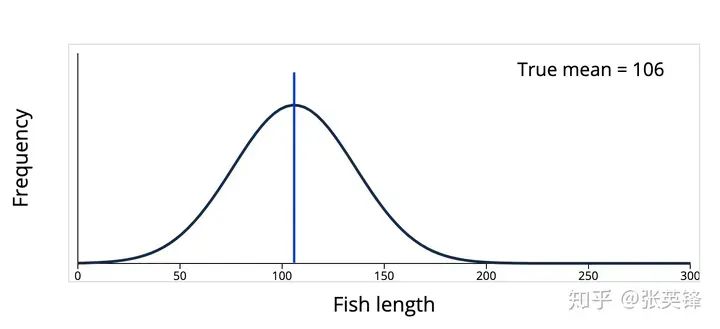
例如,下面这个西班牙流感死亡年龄的分布:
数据并没有聚集在平均值43附近,如果取样,就会发现样本更大的概率是远离平均值,而不是在平均值附近。
所以样本方差出现偏小的原因,并不是因为平均值附近被采样到的概率更大,这只在部分情况下成立,在很多情况下并不成立。
样本方差出现偏差的原因和采样无关,也和平均值附近更容易被采样无关,因为在很多情况下,远离平均值的数据更容易被采样到,这无法解释样本方差为什么会比全体方差小。
更好的解释是,计算过程中引入样本平均值,降低了样本的自由度,减少了数据的差异性。
所以直觉也是靠不住的,事实上,有太多的偏差和偏见(Bias)是由直觉贡献的。
结论
样本标准差的分母写成n-1,是为了对数据进行校正,这叫贝塞尔校正(Bessel's Correction)。
统计经常用各种方法来消除掉干扰数据的影响,例如比尔盖茨和去掉最高/低分的这两个例子。
样本数据之间也经常会出现各种隐含的关联关系,降低了数据之间的独立性或自由度(Degrees of freedom),这会让样本更聚集,让样本偏差变小。
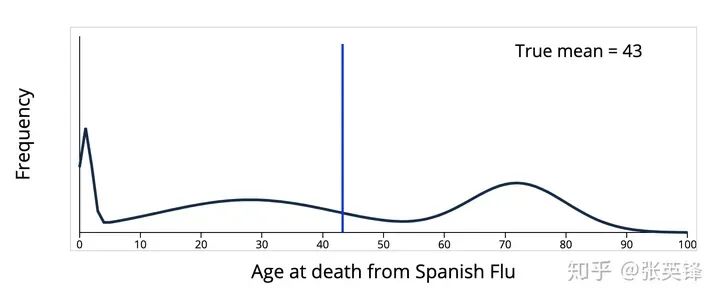
样本方差
 公式里的分母n-1,就是校正样本平均值
公式里的分母n-1,就是校正样本平均值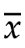 所减少的自由度,样本数据本身没有偏差,是计算过程中引入的新信息(样本均值),让计算结果出现了偏差。
所减少的自由度,样本数据本身没有偏差,是计算过程中引入的新信息(样本均值),让计算结果出现了偏差。
推荐阅读
[1]https://en.wikipedia.org/wiki/Bessel%27s_correction
[2]https://heap.io/blog/data-stories/garbage-in-garbage-out-how-anomalies-can-wreck-your-data
[3]https://zh.wikipedia.org/wiki/%E8%BB%BC%E4%BA%8B%E8%AD%89%E6%93%9A
[4]https://zh.wikipedia.org/wiki/%E4%BB%A5%E5%81%8F%E6%A6%82%E5%85%A8
[5]https://zh.wikipedia.org/wiki/1948%E5%B9%B4%E7%BE%8E%E5%9B%BD%E6%80%BB%E7%BB%9F%E9%80%89%E4%B8%BE
[6]http://www.todayonhistory.com/lishi/201705/62790.html
[7]https://zh.wikipedia.org/wiki/%E5%81%8F%E5%B7%AE%E6%A8%A3%E6%9C%AC[8]http://math.oxford.emory.edu/s
编辑:黄继彦


















 1455
1455

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









