







 本文详细介绍了DXT1和DXT5纹理压缩格式,特别是DXT1的实时压缩和YCoCg-DXT5在CPU和GPU上的实现。通过YCoCg色彩空间,YCoCg-DXT5可以实现高质量的彩色图像压缩,减少内存占用,同时保持较好的图像质量。文中探讨了实时压缩的优化方法,包括选择最佳对角线和插值策略,以及在GPU上的实现,指出YCoCg-DXT5在性能和质量上优于DXT1格式。
本文详细介绍了DXT1和DXT5纹理压缩格式,特别是DXT1的实时压缩和YCoCg-DXT5在CPU和GPU上的实现。通过YCoCg色彩空间,YCoCg-DXT5可以实现高质量的彩色图像压缩,减少内存占用,同时保持较好的图像质量。文中探讨了实时压缩的优化方法,包括选择最佳对角线和插值策略,以及在GPU上的实现,指出YCoCg-DXT5在性能和质量上优于DXT1格式。
JMP van Waveren |
|
2007年9月14日
©2007,id Software,Inc.
(有删节。仍需整理,目前就先这)
抽象
(译者注,在Doom3bfg代码中具有Dxt压缩算法,
对于rage,我觉得应该也是应用了Dxt压缩算法,来进行对于纹理图像的解压缩运算)
介绍
纹理是绘制到几何形状上的数字化图像,以增加视觉细节。在今天的计算机图形学中,在光栅化
过程中将大量的细节映射到几何图形上。不仅使用颜色的纹理,还可以指定表面属性(例如镜面反
射)或精细表面细节(以正常或凹凸贴图的形式)的纹理。
所有这些纹理都可以消耗大量的系统和视频内存。
幸运的是,可以使用压缩来减少存储纹理所需的内存量。
今天的大多数显卡允许纹理以各种在光栅化期间实时解压缩的压缩格式存储。
一种这样的格式,它是由大多数图形卡支持的,是S3TC -也被称为DXT压缩[ 1,2 ]。
压缩纹理不仅需要显卡更少的内存,而且由于带宽要求降低,
通常渲染速度比未压缩纹理要快。
由于压缩,某些质量可能会丢失。
然而,减少的内存占用允许使用更高分辨率的纹理,
使得在质量上实际上可以获得显着的增益。
DXT1
在DXT1格式[ 1,2 ]在图形卡上的硬件渲染过程中设计用于实时解压缩。
DXT1是具有8:1固定压缩比的有损压缩格式。
DXT1压缩是块截断编码(BTC)[ 3 ]的一种形式,其中图像被划分为非重
叠块,并且每个块中的像素被量化为有限数量的值。
4×4像素块中的像素的颜色值通过RGB颜色空间在一行上的等距点近似。
该行由两个端点定义,对于4x4块中的每个像素,2位索引存储在该行上的一个等距点上。
通过颜色空间的线的端点被量化为16位5:6:5 RGB格式,
通过插值生成一个或两个中间点。
DXT1格式允许通过根据终点的顺序切换到不同的模式,
其中仅生成一个中间点并指定一个附加颜色,这是黑色和完全透明的。
下图显示柯达无损真彩色图像套件[ 16 ] 的图像14的一小部分。
左边的图像是原来的。
中间的图像显示了图像14的相同部分,其首先被缩小到四分之一的尺寸,
然后用双线性滤波放大到原始尺寸。
右图显示了压缩成DXT1格式的相同部分。
|
|
|
|
| 切出 柯达图像套件图像14 的部分。 1.5 MB |
将图像缩小 到四分之一的大小。 384 kB |
以最好的质量压缩到DXT1 。 192 kB |



DXT1压缩图像具有比首先缩小到四分之一尺寸的图像更多的细节,
然后用双线性滤波放大到原始尺寸。
此外,DXT1压缩的图像使用图像的一半存储空间缩小到四分之一的大小。
然而,与原始图像相比,DXT1压缩图像的质量明显下降。
3. CPU上的实时DXT1
DXT1格式设计用于硬件实时解压缩,而不是实时压缩。
虽然解压缩非常简单,但对DXT1格式的压缩通常需要大量的工作。
有几种好的DXT压缩机可用。
最显着的是ATI Compressonator [ 4 ]和NVIDIA DDS Utilities [ 5 ]。
两台压缩机都生产高品质的DXT压缩图像。
然而,这些压缩机不是开源的,并且它们被优化用于高质量的离线压缩,
并且对于实时使用来说太慢。
NVIDIA还发布了一套开源的纹理工具[ 6 ],其中包括DXT压缩器。
这些DXT压缩机也以超速的质量为目标。
有一个开源的DXT压缩器可供Roland Scheidegger用于Mesa 3D图形库[ 7 ]。
另一个好的DXT压缩器是西蒙·布朗的Squish [ 8 ]。
直到最近,对DXT1格式的实时压缩并不被认为是一个可行的选择。
然而,DXT1的实时压缩是非常有可能的,如[ 9 ] 所示,
与最佳DXT1压缩相比,质量损失对于大多数图像是合理的。
4×4像素块中的RGB颜色倾向于很好地映射到RGB颜色空间的边界区域的线上的等距点,
因为该线跨越完整的动态范围,并且倾向于与亮度分布。
下面的图像再次显示柯达无损真彩色图像套件的图像14的小部分[ 16 ]。
图14的该特定部分示出了由于DXT压缩而可能发生的一些最差的压缩伪像。
左边的图像是原来的。中间的图像显示了以最佳质量压缩到DXT1的相同部分。
右图显示了实时DXT1压缩机的结果。
|
|
|
|
| 切出 柯达图像套件图像14 的部分。 1.5 MB |
以最好的质量压缩到DXT1 。 192 kB |
压缩到DXT1与 实时DXT1压缩机。 192 kB |

使用实时DXT1压缩器时会出现明显的工件,但对DXT1格式的最佳压缩也显示出明显的质量损失。
然而,对于许多图像,由于实时压缩造成的质量损失是不明显的或完全可以接受的。
4. YCoCg-DXT5
所述DXT5格式[ 2,3 ]存储三个颜色通道中的相同的方式DXT1确实,
但没有1位alpha通道。
代替1位alpha通道,DXT5格式存储与DXT1色彩通道相似的单独的Alpha通道。
4x4块中的alpha值通过α空间在一行上的等距点近似。
通过α空间的线的端点存储为8位值,并且基于端点的顺序,通过插值生成4或6个中间点。
对于4个中间点的情况,生成两个附加点,一个完全不透明,另一个用于完全透明。
对于4x4块中的每个像素,3位索引通过alpha空间存储在该行上的一个等距点上,
或完全不透明或完全透明的两个附加点之一。
使用相同数量的位来将alpha通道编码为三个DXT1颜色通道。
因此,与三维颜色空间相反,α通道以比每个颜色通道更高的精度被存储,
因为α空间是一维的。
此外,总共有8个样本表示4×4块中的α值,而不是4个样本来表示颜色值。
由于额外的Alpha通道,DXT5格式消耗DXT1格式的内存量的两倍。
与每个颜色通道相比,alpha通道的存储精度高于每个颜色通道,
因为与三维色彩空间相反,alpha空间是一维的。
此外,总共有8个样本表示4×4块中的α值,而不是4个样本来表示颜色值。由于额外的Alpha通道,DXT5格式消耗DXT1格式的内存量的两倍。与每个颜色通道相比,alpha通道的存储精度高于每个颜色通道,因为与三维色彩空间相反,alpha空间是一维的。
此外,总共有8个样本表示4×4块中的α值,而不是4个样本来表示颜色值。
由于额外的Alpha通道,DXT5格式消耗DXT1格式的内存量的两倍。
DXT5格式可以以多种方式用于不同的目的。
一个众所周知的例子是绞合正常映射[DXT5的压缩12,13 ]。
DXT5格式也可用于通过使用YCoCg色彩空间进行高质量的彩色图像压缩。
在YCoCg中颜色空间中首次引入了对H.264压缩[ 14,15 ]。
已经显示RGB到YCoCg变换能够实现比由各种RGB到YCbCr变换获得的去相关更好的去
相关性,并且当测量用于代表性的高质量RGB测试集合时,
非常接近KL变换的解相关图像[ 15 ]。
此外,从RGB到YCoCg的转换非常简单,只需要增加整数和移位。
在将RGB_数据转换为CoCg_Y后,可以通过使用DXT5格式实现彩色图像的高质量压缩。
换句话说,亮度(Y)被存储在α通道中,色度(CoCg)被存储在5:6:5颜色通道中的前两个中。
对于彩色图像,这种技术产生4:1的压缩比,质量非常好 - 通常优于4:2:0 JPEG在最高质量设置。
|
|
|
|
| 切出 柯达图像套件图像14 的部分。 1.5 MB |
以最好的质量压缩到DXT1 。 192 kB |
以最好的质量压缩到YCoCg-DXT5 。 384 kB |

CoCg_Y DXT5压缩图像没有显着的质量损失,消耗原始图像的四分之一。
CoCg_Y DXT5看起来也比压缩成DXT1格式的图像好多了。
显然,在片段程序中检索到CoCg_Y颜色数据,需要一些工作来执行转换回RGB。
然而,转换成RGB是相当简单的:
Co = color.x - (0.5 * 256.0 / 255.0)
Cg = color.y - (0.5 * 256.0 / 255.0)
Y = color.w
R = Y + Co-Cg
G = Y + Cg
B = Y-Co-Cg
此转换只需要片段程序中的三个指令。此外,过滤和其他计算通常可以在YCoCg空间中完成。
DP4 result.color.x,color,{1.0,-1.0,0.0 * 256.0 / 255.0,1.0};
DP4 result.color.y,color,{0.0,1.0,-0.5 * 256.0 / 255.0,1.0};
DP4 result.color.z,color,{-1.0,-1.0,1.0 * 256.0 / 255.0,1.0};
色度橙色(Co)和色度绿色(Cg)存储在前两个通道中,
其中Co端点以5位存储,Cg终点存储6位。
即使端点以不同的量化存储,这样也能获得最佳质量。
由于Cg值影响所有三个RGB通道,Cg通道的终点以比Co通道的终点(5位)更高的精度(6位)存储,而Co值仅影响红色和蓝色渠道。
CoCg颜色空间的5:6量化可能导致轻微的颜色偏移和可能的颜色损失。
理想情况下,不会有任何量化,通过CoCg颜色空间的线的终点将以8:8格式存储。
幸运的是,DXT5格式的第三个通道可以用于为4×4像素块中的许多块获得高达2位的精度。
当4×4块中的颜色的动态范围非常低时,颜色空间的量化是最显着的。
量化可以使颜色映射到单个点,或者颜色映射到动态范围之外的点。
为了克服这个问题,当颜色的动态范围很低时,颜色可以放大。
在压缩过程中,颜色被放大,并在片段程序中按比例缩小到其原始值。
当CoCg空间映射到[0,255] x [0,255]的范围时,颜色灰色表示为点(128,128)。
对于大多数图像,随着CoCg空间的动态范围减小,颜色趋向于变得更接近于灰色。
因此,通过从所有颜色中减去(128,128),4×4像素块的颜色空间首先以灰色为中心。
然后,围绕原点测量4x4块的色彩空间的动态范围:max(abs(min),abs(max))。
如果两个通道的动态范围小于64,则所有CoCg值都按比例放大2倍。
如果动态范围小于32,则所有CoCg值都按比例增加4倍。
动态范围范围必须分别小于64和32,以确保颜色值不会溢出。
实际上,将颜色缩放2,所有CoCg值的最后一位总是设置为零,因此不受量化的影响。
以相同的方式,如果颜色按比例放大4,则最后两位始终为零,也不受量化影响。
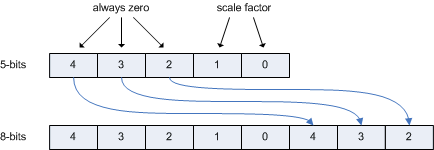
在DXT5格式的第三个通道中,比例因子1,2或4作为一个恒定值存储在整个4×4像素块上。
存储在整个块上的恒定值,比例因子的存在不影响CoCg通道的压缩。
比例因子存储为(scale-1)* 8,使得比例因子仅使用5位通道的两个最低有效位。
因此,比例因子不受到5比特的量化和DXT5解码器中的反量化和扩展的影响,
其中较高的3比特被复制到较低的三比特。
下图显示了DXT5解码器中缩放因子从5位扩展到8位。
当像这样将图像编码为YCoCg-DXT5时,片段程序需要更多的工作才能转换回RGB。
以下伪代码显示了转换。
scale =(color.z *(255.0 / 8.0))+ 1.0
Co =(color.x - (0.5 * 256.0 / 255.0))/ scale
Cg =(color.y - (0.5 * 256.0 / 255.0))/ scale
Y = color.w
R = Y + Co-Cg
G = Y + Cg
B = Y-Co-Cg
在片段程序中,这意味着:
MAD color.z,color.z,255.0 / 8.0,1.0;
RCP color.z,color.z;
MUL color.xy,color.xyxy,color.z;
DP4 result.color.x,color,{1.0,-1.0,0.0 * 256.0 / 255.0,1.0};
DP4 result.color.y,color,{0.0,1.0,-0.5 * 256.0 / 255.0,1.0};
DP4 result.color.z,color,{-1.0,-1.0,1.0 * 256.0 / 255.0,1.0};
换句话说,片段程序中只需要三个指令来缩小CoCg值。
右下方的图像显示了在左侧原始图像旁边的CoCg值缩放的YCoCg压缩结果。
|
|
|
| 切出 柯达图像套件图像14 的部分。 1.5 MB |
压缩至可扩展的YCoCg-DXT5 ,质量最好。 384 kB |

对于几乎所有的图像,当放大CoCg值时,质量明显更高。
然而,值得注意的是,缩放的CoCg值的线性纹理滤波(例如双线性滤波)
可以导致颜色值的非线性滤波。
在颜色值按比例缩小之前,分别对颜色值和比例因子进行过滤。
换句话说,将过滤的比例因子应用于过滤的CoCg值 - 这与先前按比例缩小的过滤颜色值不同。
有趣的是,当测量双线性滤波的YCoCg-DXT5压缩纹理相对于双线性滤波的原始纹理的质量时,
当CoCg值被放大时,质量仍然显着更高,即使纹理过滤可能导致颜色被缩放向下错误
不正确的缩放仅影响具有不同比例因子的4×4块纹素之间的边界上的样本,
并且大多数时间相邻块的比例因子相同。
具有不同比例因子的块之间的内插颜色趋向于与具有最高比例因子的4×4块的颜色值更快地收敛。
然而,由于难以辨别双线性滤波器图案和非线性滤波器图案之间的差异,感知质量通常没有明显的差异。
也没有不自然的色彩转换,因为Co和Cg值经历相同的非线性滤波,不会漂移。
换句话说,颜色转换仍然沿着CoCg空间中的直线 - 只是不是以恒定的速度。
由于过滤在具有不同比例因子的4x4块的边界处是非线性的,
重要的是滤除的颜色值保持在来自4×4块的原始颜色值之间。
换句话说,颜色值不应超出范围 - 这将导致伪像。
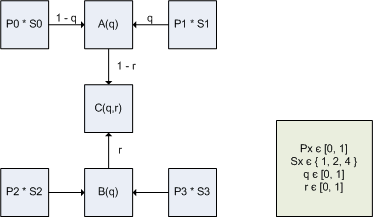
下图显示了带有比例因子S0,S1,S2和S3以及参数“q”和“r”的纹素值P0,P1,P2和P3之间
双线性滤波的工作原理。
对于常规双线性滤波,比例因子S0,S1,S2和S3都设置为1,并且纹理值如下内插。
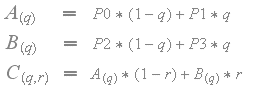
当CoCg值用相邻块的不同比例因子放大时,则滤波变为非线性,如下。
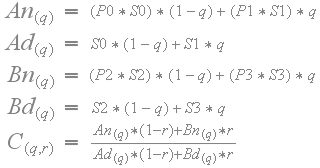
滤波后的颜色值不应超出范围,因此对于滤波后的样本C(q,r),
必须满足以下条件:min(P0,P1,P2,P3)<= C(q,r)<= max ,P1,P2,P3)。
首先,看到滤波后的样本C(q,r)等于拐角处的原始纹素值之一是很简单的。
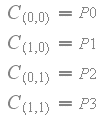
由于样本C(q,r)等于拐角处的原始纹理值之一,
所以函数C(q,r)对于任何常数“r”必须单调递增或单调递减,因此样本不能出来的范围。
换句话说,C(q,r)相对于'q'的偏导数不能改变符号。C(q,r)相对于'q'的偏导数如下:
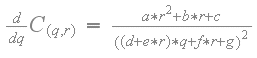
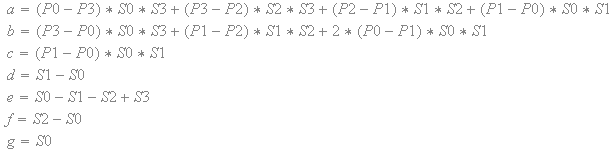
基于纹素值和比例因子,'a','b','c','d','e','f'和'g'的表达式是正或负常数。
分子是正或负的常数。变量“q”只能在分母中出现一次。
此外,分母是平方的,因此总是积极的。
换句话说,偏导数永远不会改变符号。
同样,函数C(q,r)对于任何常数“q”必须单调增加或单调递减,
这意味着C(q,r)相对于'r'的偏导数也必须永远不会改变符号。
C(q,r)相对于'r'的偏导数如下:
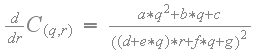
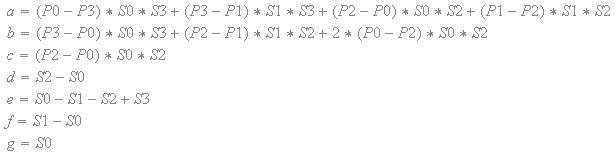
与对于'q'的偏导数一样,相对于'r'的偏导数也从不改变符号。
由于函数C(q,r)经过了角部的原始纹素值,并且函数在常数“r”下单调增加或单调递减,
并且在恒定“q”时也单调递增或单调递减,样本C(q,r)永远不能超出范围,
如下:min(P0,P1,P2,P3)<= C(q,r)<= max(P0,P1,P2,P3)
如果比例因子不同,三线滤波和各向异性过滤也会变得非线性。然而,与双线性滤波一样,滤波后的样本也在原始纹素值之间很好地界定。
5. CPU上的实时YCoCg-DXT5
使用常规实时DXT5压缩器压缩到YCoCg-DXT5确实比使用DXT1压缩更好的质量,
并且通常几乎没有细节损失[ 9 ]。
然而,有明显的色彩瑕疵。特别是有颜色阻挡和颜色渗色伪像。
来自[ 9 ] 的实时DXT5压缩器通过CoCg空间在线上以等距点近似每个4x4块中的颜色,
其中线通过CoCg空间的边界框的范围创建。
问题是,经常选择CoCg空间边界的错误对角线。
这在基本颜色之间的过渡特别明显,这导致颜色渗色伪像。
要获得更好的质量,应使用CoCg空间的二维边界盒的两个对角线中最好的。
[ 9 ]中描述的实时DXT5压缩器可以扩展为选择两个对角线之一。
确定使用哪个对角线的最佳方式是测试颜色值相对于CoCg空间边界中心的协方差的符号。
以下例程通过CoCg空间交换线的端点的两个坐标,
基于哪个对角线最适合4×4像素块中的颜色。
void SelectYCoCgDiagonal(const byte * colorBlock,byte * minColor,byte * maxColor){
字节mid0 =((int)minColor [0] + maxColor [0] + 1)>> 1;
字节mid1 =((int)minColor [1] + maxColor [1] + 1)>> 1;
int协方差= 0;
for(int i = 0; i <16; i ++){
int b0 = colorBlock [i * 4 + 0] - mid0;
int b1 = colorBlock [i * 4 + 1] - mid1;
协方差+ =(b0 * b1);
}
if(协方差<0){
字节t = minColor [1];
minColor [1] = maxColor [1]
maxColor [1] = t;
}
}
计算协方差需要颜色值的乘法,这增加了动态范围,
并限制了通过SIMD指令集可以利用的并行度。
代替计算颜色值的协方差,
也可以选择仅相对于颜色空间的边界框的中心的颜色的符号位的协方差。
有趣的是,仅使用符号位时质量的损失真的很小,一般可以忽略不计。
以下例程仅基于符号位的协方差,通过CoCg空间交换线路端点的两个坐标。
void SelectYCoCgDiagonal(const byte * colorBlock,byte * minColor,byte * maxColor){
字节mid0 =((int)minColor [0] + maxColor [0] + 1)>> 1;
字节mid1 =((int)minColor [1] + maxColor [1] + 1)>> 1;
字节边= 0;
for(int i = 0; i <16; i ++){
字节b0 = colorBlock [i * 4 + 0]> = mid0;
字节b1 = colorBlock [i * 4 + 1]> = mid1;
侧+ =(b0 ^ b1);
}
byte mask = - (side> 8);
字节c0 = minColor [1];
字节c1 = maxColor [1];
c0 ^ = c1 ^ = mask&= c0 ^ = c1;
minColor [1] = c0;
maxColor [1] = c1;
}
动态范围没有增加,上述例程中的循环可以使用仅对字节进行操作来实现,
这允许通过SIMD指令集最大化并行化。
实际上,该例程将CoCg空间的边界框划分为四个统一象限如下:
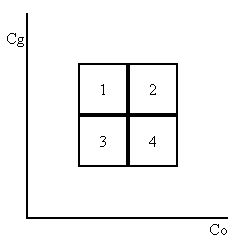
然后,例程计算落入每个象限的颜色数量。
如果大多数颜色在象限2和3中,则使用通过边界框扩展区的规则对角线。
然而,如果大多数颜色在象限1和4中,则使用相反的对角线。
例程首先计算Co和Cg范围的中点。
然后将颜色值与这些中点进行比较。
下表显示了4个象限与大于或等于中点的CoCg值之间的关系。
对比较结果使用按位逻辑异或运算,只能对于象限1或4中的颜色产生“1”。
颜色的异或运算结果可以累加,以计算颜色数在象限1和4中。
如果超过一半的颜色在象限1或4中,则对角线需要翻转。
| 象限 | > = Co中点 | > = Cg中点 | XOR |
|---|---|---|---|
| 1 | 0 | 1 | 1 |
| 2 | 1 | 1 | 0 |
| 3 | 0 | 0 | 0 |
| 4 | 1 | 0 | 1 |
使用MMX和SSE2指令集的实现可以分别在附录C和D中找到。
MMX / SSE2指令“pavgb”用于计算Co和Cg范围的中点。
不幸的是,在MMX或SSE2指令集中没有指令用于比较无符号字节。
只有“pcmpeqb”指令对有符号和无符号字节都有效。
但是,'pmaxub'指令使用无符号字节。
为了评估一个大于或等于的关系,使用'pmaxub'指令后跟'pcmpeqb'指令,
因为表达式(x> = y)等价于表达式(max(x,y)== x )。
MMX / SSE2指令“psadbw”通常用于计算绝对差的和。
但是,该指令也可用于通过将其中一个操作数设置为全零来执行水平加法。
附录C和D中的MMX / SSE2实现使用“psadbw”指令来添加按位逻辑异或运算的结果。
为了翻转对角线,例程使用一个掩蔽的XOR交换,这只需要4条指令。
该掩码用于选择需要交换的两个寄存器的位。
假设要交换的位被存储在寄存器“xmm0”和“xmm1”中,掩码存储在寄存器“xmm2”中。
以下SSE2代码从“xmm0”和“xmm1”中的每对位置换掉,“xmm2”中的等效位设置为1。
pxor xmm0,xmm1 pand xmm2,xmm0 pxor xmm1,xmm2 pxor xmm0,xmm1
使用屏蔽XOR交换,“minColor”和“maxColor”字节数组可以直接读入两个寄存器。
然后可以通过使用适当的掩码来交换第二个字节,而不必从寄存器中提取字节。
以下图像显示原始图像,压缩为YCoCg-DXT5的图像与实时DXT5压缩器[ 9 ]之间的差异,
以及使用新的实时YCoCg-DXT5压缩器压缩为YCoCg-DXT5的图像最好的对角线。
图像显示当使用这个小型扩展到实时DXT5压缩器时,没有明显的颜色渗色。
|
|
|
|
| 切出 柯达图像套件图像14 的部分。 1.5 MB |
压缩至具有 实时DXT5压缩机的YCoCg-DXT5 。 384 kB |
使用 实时YCoCg-DXT5压缩机压缩至YCoCg-DXT5 。 384 kB |


来自[ 9 ] 的DXT5压缩器插入了颜色空间和alpha空间的边界框,以提高均方误差(MSE)。
颜色空间的边界框通过颜色空间在线上的两点之间的距离总共为一半。
通过颜色空间有4点,因此边框在任意一端插入范围的1/16。
以相同的方式,α空间的界限通过α空间在线上的两点之间的距离总共插入一半。
换句话说,alpha空间的边界在任一端插入范围的1/32。
插入边框的副作用是对于具有低动态范围(小边界框)的4x4像素的块,
通过颜色空间或α空间的线上的点可能捕捉到彼此非常接近的点。
在这种情况下,将线的端点稍微分开一点,以便覆盖较大的动态范围,
其中内插点通常将更接近原始值。
以下代码首先插入颜色空间的边界框,然后向外舍入线的端点,以便线覆盖更大的动态范围。
以同样的方式,α空间的界限首先插入,然后向外舍入。
#define INSET_COLOR_SHIFT 4 //插入颜色边界框
#define INSET_ALPHA_SHIFT 5 //插入alpha边界框
#define C565_5_MASK 0xF8 // 0xFF减去最后三位
#define C565_6_MASK 0xFC // 0xFF减去最后两位
void InsetYCoCgBBox(byte * minColor,byte * maxColor){
int inset [4];
int mini [4];
int maxi [4];
inset [0] =(maxColor [0] - minColor [0]) - ((1 <<(INSET_COLOR_SHIFT-1)) - 1);
inset [1] =(maxColor [1] - minColor [1]) - ((1 <<(INSET_COLOR_SHIFT-1)) - 1);
inset [3] =(maxColor [3] - minColor [3]) - ((1 <<(INSET_ALPHA_SHIFT-1))-1);
mini [0] =((minColor [0] << INSET_COLOR_SHIFT)+ inset [0])>> INSET_COLOR_SHIFT;
mini [1] =((minColor [1] << INSET_COLOR_SHIFT)+ inset [1])>> INSET_COLOR_SHIFT;
mini [3] =((minColor [3] << INSET_ALPHA_SHIFT)+ inset [3])>> INSET_ALPHA_SHIFT;
maxi [0] =((maxColor [0] << INSET_COLOR_SHIFT) - inset [0])>> INSET_COLOR_SHIFT;
maxi [1] =((maxColor [1] << INSET_COLOR_SHIFT) - inset [1])>> INSET_COLOR_SHIFT;
maxi [3] =((maxColor [3] << INSET_ALPHA_SHIFT) - inset [3])>> INSET_ALPHA_SHIFT;
mini [0] =(mini [0]> = 0)?迷你[0]:0;
mini [1] =(mini [1]> = 0)?迷你[1]:0;
mini [3] =(mini [3]> = 0)?迷你[3]:0;
maxi [0] =(maxi [0] <= 255)?maxi [0]:255;
maxi [1] =(maxi [1] <= 255)?maxi [1]:255;
maxi [3] =(maxi [3] <= 255)?maxi [3]:255;
minColor [0] =(mini [0]&C565_5_MASK)| (mini [0] >> 5);
minColor [1] =(mini [1]&C565_6_MASK)| (mini [1] >> 6);
minColor [3] =迷你[3];
maxColor [0] =(maxi [0]&C565_5_MASK)| (maxi [0] >> 5);
maxColor [1] =(maxi [1]&C565_6_MASK)| (maxi [1] >> 6);
maxColor [3] = maxi [3];
}
'pmullw'指令用于升档值。
与MMX / SSE2移位指令不同,'pmullw'指令允许寄存器中的单个字与不同的值相乘。
乘法器是存储在前两个通道中的CoCg值的(1 << INSET_COLOR_SHIFT)和
存储在阿尔法通道中的Y值的(1 << INSET_ALPHA_SHIFT)。
以同样的方式,通过使用CoCg值的乘法器(1 <<(16 - INSET_COLOR_SHIFT))
和Y值的(1 <<(16 - INSET_ALPHA_SHIFT))来使用'pmulhw'指令向下移动。
除了选择最佳的对角线和用适当的四舍五入对边界进行插值外,
CoCg值也可以实时放大以获得精确度。
以下代码显示了如何将其作为现有实时DXT5编码器的扩展来实现。
void ScaleYCoCg(byte * colorBlock,byte * minColor,byte * maxColor){
int m0 = abs(minColor [0] - 128);
int m1 = abs(minColor [1] - 128);
int m2 = abs(maxColor [0] - 128);
int m3 = abs(maxColor [1] - 128);
if(m1> m0)m0 = m1;
如果(m3> m2)m2 = m3;
如果(m2> m0)m0 = m2;
const int s0 = 128/2 - 1;
const int s1 = 128/4 - 1;
int mask0 = - (m0 <= s0);
int mask1 = - (m0 <= s1);
int scale = 1 +(1&mask0)+(2&mask1);
minColor [0] =(minColor [0] - 128)* scale + 128;
minColor [1] =(minColor [1] - 128)* scale + 128;
minColor [2] =(scale-1)<< 3;
maxColor [0] =(maxColor [0] - 128)* scale + 128;
maxColor [1] =(maxColor [1] - 128)* scale + 128;
maxColor [2] =(scale-1)<< 3;
for(int i = 0; i <16; i ++){
colorBlock [i * 4 + 0] =(colorBlock [i * 4 + 0] - 128)* scale + 128;
colorBlock [i * 4 + 1] =(colorBlock [i * 4 + 1] - 128)* scale + 128;
}
}
为了利用最大并行度,CoCg值最好放大为字节,而不需要更多的位。
这似乎很直接,除了MMX和SSE2指令集中没有指令移位或乘以字节。
此外,128需要从无符号字节中减去,这可能导致负值。
也不能将128表示为有符号字节。
但是,无符号字节可以静默地转换为有符号字节,然后可以添加带符号的字节值-128。
对于正确处理的包装,这将得到与从无符号字节减去128相同的计算结果,
其中结果是有符号字节,如果原始值低于128,则可能会变为负数。
比例因子是2的幂,这意味着比例等
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2679
2679

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









