






目录
本文是对论文《Deep Deterministic Policy Gradient (DDPG)-Based Resource Allocation
Scheme for NOMA Vehicular Communications》的分析,若需下载原文请依据前方标题搜索,第一作者为YI-HAN XU
一、文章概述
这篇文章中,作者使用强化学习DDPG算法,辅助车载通信系统中的基站、车辆选择载波频段、分配功率值,最终达到最大化车辆与基站间信道容量和速率、最优车辆与车辆间交付概率的效果。
二、系统环境

系统环境如上图所示,车联网系统中,存在V2V(车辆与车辆)和V2I(车辆与基站)间的通信任务,它们之间会产生相互的干扰。
三、系统模型
1.V2I通信(信道容量)

车辆与基站间通信表征为信道容量之和。
2.V2V通信(延迟与可靠性)

车辆与车辆间通信表征为单位时间内的有效载荷。
四、算法分析(强化学习DDPG)
1.输入状态
输入状态主要包括 各载波频段的功率信息、信道状态信息(主要指信道衰落)与车辆处接收信息的缓冲队列长度。
2.输出动作
输出动作为系统内单位对于载波频段的选择与功率分配情况。
3.环境反馈
环境反馈为系统模型中所提到的V2I信道容量与V2V交付概率。
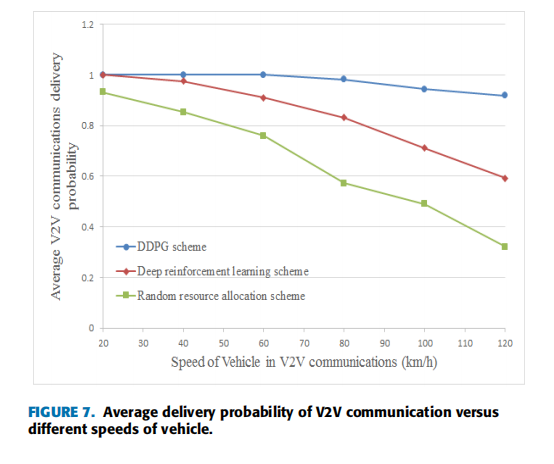
五、性能表征
1.信道容量

2.交付概率(1Mb/s)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











