






大语言模型RAG-技术概览 (一)
一 RAG概览
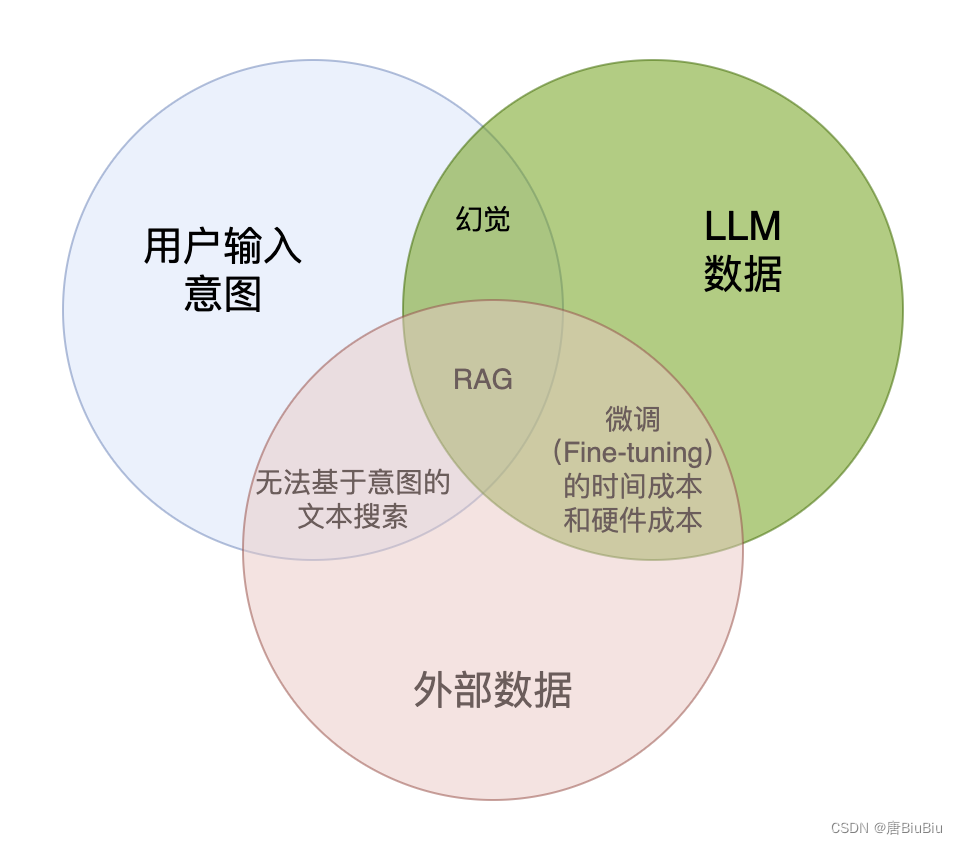
检索增强生成(Retrieval-AugmentedGeneration, RAG)。即大模型在回答问题或生成问题时会先从大量的文档中检索相关的信息,然后基于这些信息进行回答。RAG很好的弥补了传统搜索方法和大模型两类技术的短板。个人认为RAG的核心在于将LLM的底座模型与上层应用进行解耦。 举个例子:GPT的知识停留在模型训练完成的那一刻(GPT4,2023年),但上层应用不得不使用新鲜的数据。RAG就很好的解决了这个问题。
借用Langchain-Chatchat项目的图了解朴素RAG流程的全貌:
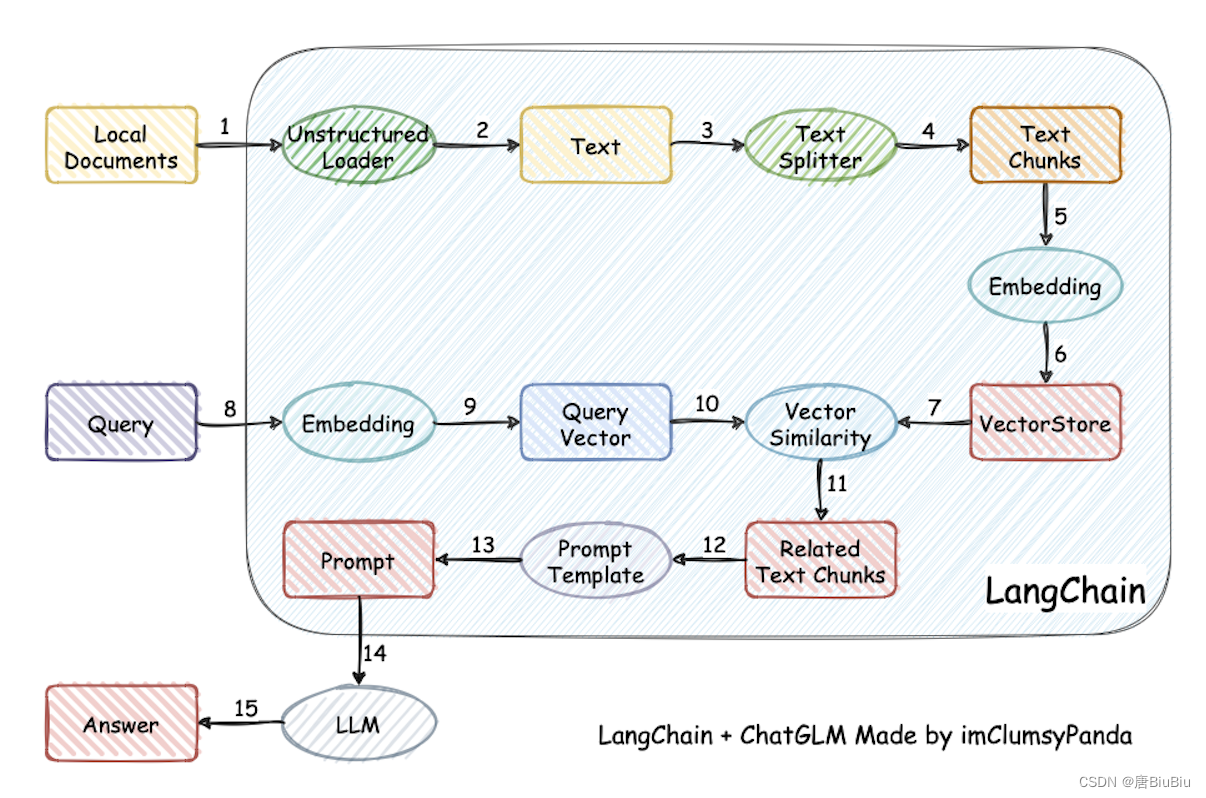
总结如下:
-
RAG接受本地文档和来自用户(或系统)的query作为input,将两类input向量化,通过向量相似度(Vector Similarity)实现召回。
-
基于input的向量库进行提示词工程。一般使用langchain框架。
-
提示词工程输出的prompt作为LLM的输入,最终给出回答。
以上是朴素RAG(Naive RAG)的流程,以此为基础,衍生了Advanced RAG和Modular RAG。
-
Advanced RAG在Naive RAG的基础上增加了检索前优化(对query进行路由、重写、扩展等,在上图箭头10的位置)和检索后优化(对检索到的本地知识排序、总结、融合等,在上图箭头7或11、12的位置)。 -
Modular RAG之所以称为Modular,是因为增加了更多功能的模块。这些模块包括了预测、感知、优化、记忆等等功能。可以把Modular RAG看作是一种更灵活的集成学习,它以LLM为核心提取用户的意图,然后基于意图自动组织各种模型(模块)实现检索问答。
到这里,可以引入Chain的概念了:它是LLM应用的一种方法,允许模型按照一定顺序逐步处理信息或任务,将前一步的输出作为下一步的输入。这种方法有时也被称为“链式推理”或“步骤式推理”。比如用户输入了一张写满了数据的图片,并询问含义。Modular RAG就会分析用户意图,确定了以下流程:OCR算法提取图片数据 -> 代码解释器处理上一步数据 -> 通过知识库解释数据结论 -> 最终给出回答。
Chain强大且灵活,但缺点也不能忽视:首先长链可能需要更多的计算资源,其次是容错率很低,中间步骤的错误可能会影响后续计算。
今年是LLM开源元年,私有化部署的开源RAG模型是人工智能赋能产业发展最有希望的方向之一。它不但极大的提高了企业的生产力,私有化部署还解决了数据安全的问题。在企业中,新来的工程师再也不需要对着厚厚业务手册抓耳挠腮,技术领导也再也不用为了一个数据半夜给员工打电话了。

















 1041
1041

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









