









光流的概念(Optical Flow)
光流是空间运动物体在观察成像平面上的像素运动的瞬时速度,是利用图像序列中像素在时间域上的变化以及相邻帧之间的相关性来找到上一帧跟当前帧之间存在的对应关系,从而计算出相邻帧之间物体的运动信息的一种方法。一般而言,光流是由于场景中前景目标本身的移动、相机的运动,或者两者的共同运动所产生的。考虑下图(图片来自维基百科):
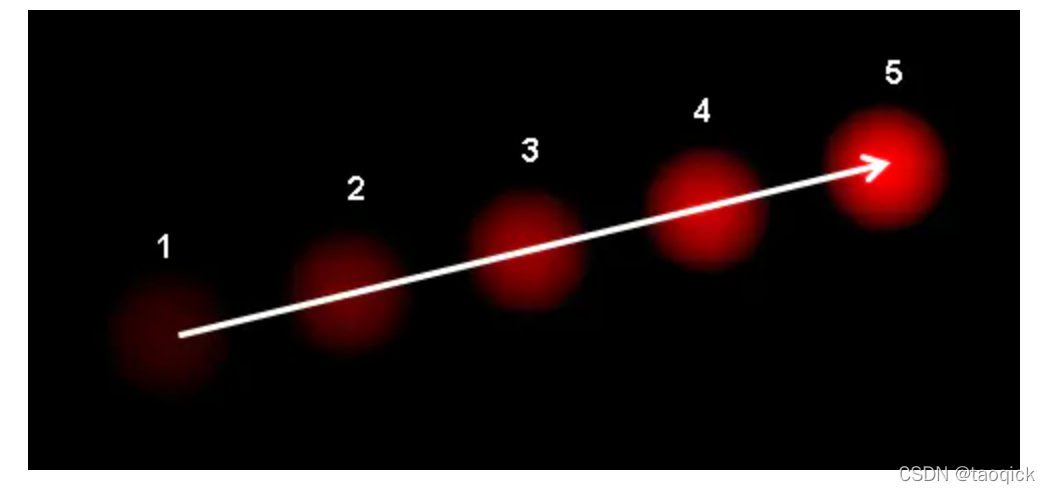
图中表示一个小球在连续5帧图像中的移动,箭头则表示小球的位移矢量。简单来说,光流是空间运动物体在观测成像平面上的像素运动的“瞬时速度”,光流的研究是利用图像序列中的像素强度数据的时域变化和相关性来确定各自像素位置的“运动”,研究光流场的目的就是为了从图片序列中近似得到不能直接得到的现实中的运动场。光流应用于诸多领域:
- 基于运动的三维重建
- 视频压缩
- 视频稳像
- 目标跟踪与行为识别等
在介绍光流的计算法之前有必要了解:光流之所以生效是依赖于这几个假设:
- 物体的像素强度不会在连续帧之间改变;
- 一张图像中相邻的像素具有相似的运动。
其实也很好理解,如果不满足以上条件,那么也找不到该像素在下一帧的位置,自然也无法计算出它的运动。
光流的计算方法
假设第一帧图像中的像素 I(x, y, t) 在时间 dt 后移动到第二帧图像的 (x+dx, y+dy) 处。根据上述第一条假设:灰度值不变,我们可以得到:
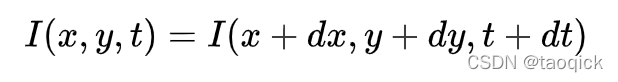
对等号右侧进行泰勒级数展开,消去相同项,两边都除以 dt ,得到如下方程:

其中:
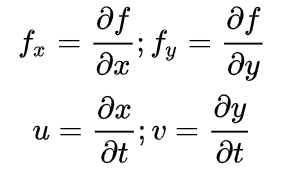
上面的等式叫做光流方程。其中 fx 和 fy 的梯度,同样 ft 是时间方向的梯度。但(u, v) 是不知道的。我们不能在一个等式中求解两个未知数。有几个方法可以帮我们解决这个问题,其中的一个是 Lucas-Kanade 法 。
Lucas-Kanade 法
为了将光流估计进行建模,Lucas-Kanade做了两个重要的假设,分别是亮度不变假设和邻域光流相似假设。
这里就要用到上面提到的第二个假设条件,领域内的所有像素点具有相同的运动。Lucas-Kanade法就是利用一个3x3的领域中的9个像素点具有相同的运动,就可以得到9个点的光流方程(即上述公式),用这些方程来求得(u, v)这两个未知数,显然这是个约束条件过多的方程组,不能解得精确解,一个好的解决方法就是使用最小二乘来拟合。求解过程:
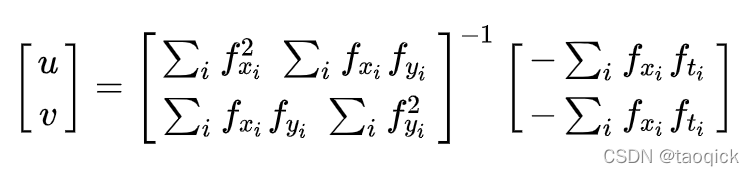
这样我们跟踪一些点就能得到这些点的光流向量,但是这里还存在尺度空间的问题,简单来讲,直到现在我们还只是处理一些很小的运动,如果是大的运动那该怎么办?图像金字塔。在图像金字塔顶层,小的运动被移除,大的运动转换成了小的运动,这样就能跟踪到了原本大的运动,重复计算图像金字塔不同层的图像的光流,我们就得到了在不同尺度空间上的光流。
深度学习方法
ICCV2015提出的FlowNet是最早使用深度学习CNN解决光流估计问题的方法,并且在CVPR2017,同一团队提出了改进版本FlowNet2.0。FlowNet2.0 是2015年以来光流估计邻域引用最高的论文。
3.2.1 FlowNet
作者尝试使用深度学习End-to-End的网络模型解决光流估计问题,如图3-2-1,该模型的输入为待估计光流的两张图像,输出即为图像每个像素点的光流。我们从Loss的设计,训练数据集和网络设计来分析FlowNet。
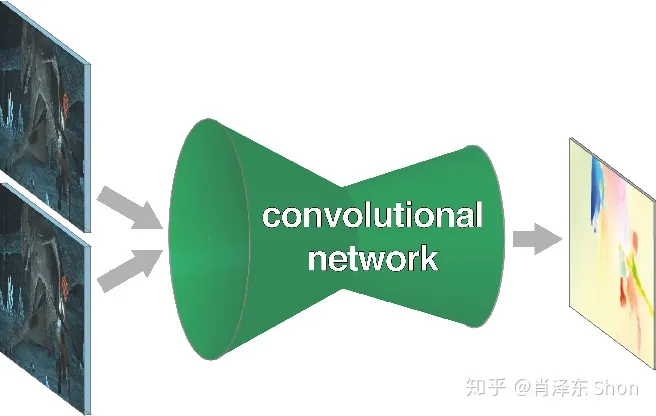
图3-2-1 深度学习End-to-End 光流估计模型
对于Loss的设计,如果给定每个像素groundtruth的光流,那么对于每个像素,loss可以定义为预测的光流(2维向量)和groundtruth之间的欧式距离,称这种误差为EPE(End-Point-Error),如图
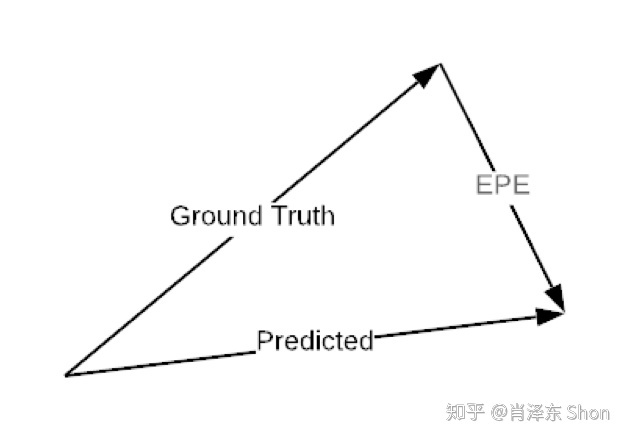
图3-2-2 End Point Error
对于训练数据集,由于稠密光流的groundtruth为图像每个像素的光流值,人工标注光流值几乎不可能。因此,作者设计了一种生成的方式,得到包括大量样本的训练数据集FlyingChairs。其生成方式为对图像做仿射变换生成对应的图像。为了模拟图像中存在多种运动,比如相机在移动,同时图像中的人或物体也在移动。作者将虚拟的椅子叠加到背景图像中,并且背景图和椅子使用不同的仿射变换得到对应的另一张图,如图3-2-3。

FlyingChairs数据集生成
Optical Flow Estimation using a Spatial Pyramid Network-Spynet
摘要:我们通过结合深度学习和经典空间金字塔结构的方式来计算光流。通过使用每个金字塔级别的光流评估warp图像和更新光流,这种方法以一个粗到精的方式评估图像中的大运动。不同于在每个金字塔层级最小化对象函数。我们在每个层级训练网络,以计算光流更新。不像最近的FlowNet光流网络,本网络不需要处理大运动,由网络中的金字塔层级处理大运动。这有几个优点:(1)在模型参数上我们的SpyNet更简单,比FlowNet小96%,这使得网络在嵌入式应用领域非常高效。(2)因为每个层级的光流比较小(小于一个pixel),对一对warp图像应用卷积方法是合适的。(3)不像FlowNet,本网络学习的卷积滤波器与传统的时空滤波器相似,这让我们能够洞察到网络的内部以及如何提升它。在多个数据集上的结果显示我们的方法比FlowNet更加高效。
paper地址:https://arxiv.org/abs/1611.00850
主要贡献点
(1)结合深度学习与传统由粗到精(coarse-to-fine)金字塔结构评估光流;
(2) 提出一个新的模型SpyNet,比FlowNet更快,参数量少96%;
(3)在公共数据集(Sintel, KITTI和MiddleBurry)上,SPyNet实现了比FlowNet更低的错误率。
————————————————
版权声明:本文为CSDN博主「善plusplus」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/u010087277/article/details/111593541
作者:zhenhuic
链接:https://www.jianshu.com/p/e9bf8c11091a
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

















 2034
2034

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









