






本文汇总了一些位置编码的工作,大体分为绝对式(训练式、三角式-Google原paper、递归式-用个RNN、相乘式)、相对式(Self-Attention with Relative Position Representations保证位置只和i-j的相对位置有关、XLNet式且从XLNet式起相对位置加在qk上为主、T5式仅仅是在Attention矩阵的基础上加一个可训练的偏置项同时对位置分桶、Deberta式和T5在qk展开项上有变化)、非套路式(CNN式和复数式)三种,从中我们可以看到各种神奇的操作。最后,笔者分享了RoPE
再展开写一下相对位置编码的思路,主要理解下面公式就比较容易:
q
i
=
(
x
i
+
p
i
)
W
Q
k
j
=
(
x
j
+
p
j
)
W
K
v
j
=
(
x
j
+
p
j
)
W
V
a
i
,
j
=
s
o
f
t
m
a
x
(
q
i
k
j
T
)
o
i
=
∑
j
a
i
,
j
v
j
q_i=(x_i+p_i)W_Q \\ k_j=(x_j+p_j)W_K \\ v_j=(x_j+p_j)W_V \\ a_{i,j} = softmax(q_ik_j^T) \\ o_i=\sum_j{a_{i,j}v_j}
qi=(xi+pi)WQkj=(xj+pj)WKvj=(xj+pj)WVai,j=softmax(qikjT)oi=j∑ai,jvj
上面相当于把self attention的公式进行了展开,如果我们进一步把
q
i
k
j
q_ik_j
qikj给展开,很明显结果中存在着4项,将不同位置进行替换、加成可训练参数就是XLNet、T5式、Deberta式的区别
在2022年又出了一篇TRAIN SHORT, TEST LONG: ATTENTION WITH LINEAR BIASES ENABLES INPUT LENGTH EXTRAPOLATION,提出了Alibi,在百川最新的大模型(https://mp.weixin.qq.com/s/UOm4riBrLmulOPJO0h_pew)中用了这种相对位置编码:
- 可学习的参数:这种比较常见,BRET 中就是这么做的,但这种方式弊端很明显,因为位置信息是学习出来的,所以如果训练集里面没有见过覆盖某个长度,推理的效果就无法得到保证。
- 正弦位置编码:这是早期 transformer 使用的位置编码,论文中有尝试做实验,这种编码会随着训练/预测时的文本长度差异增大,(超过 50 个token 后)性能显著下降。
- 旋转编码:论文中提到这种方式是比较不错的,只不过因其在每一层都要做一次向量旋转,从而降低训练和推理的速度。
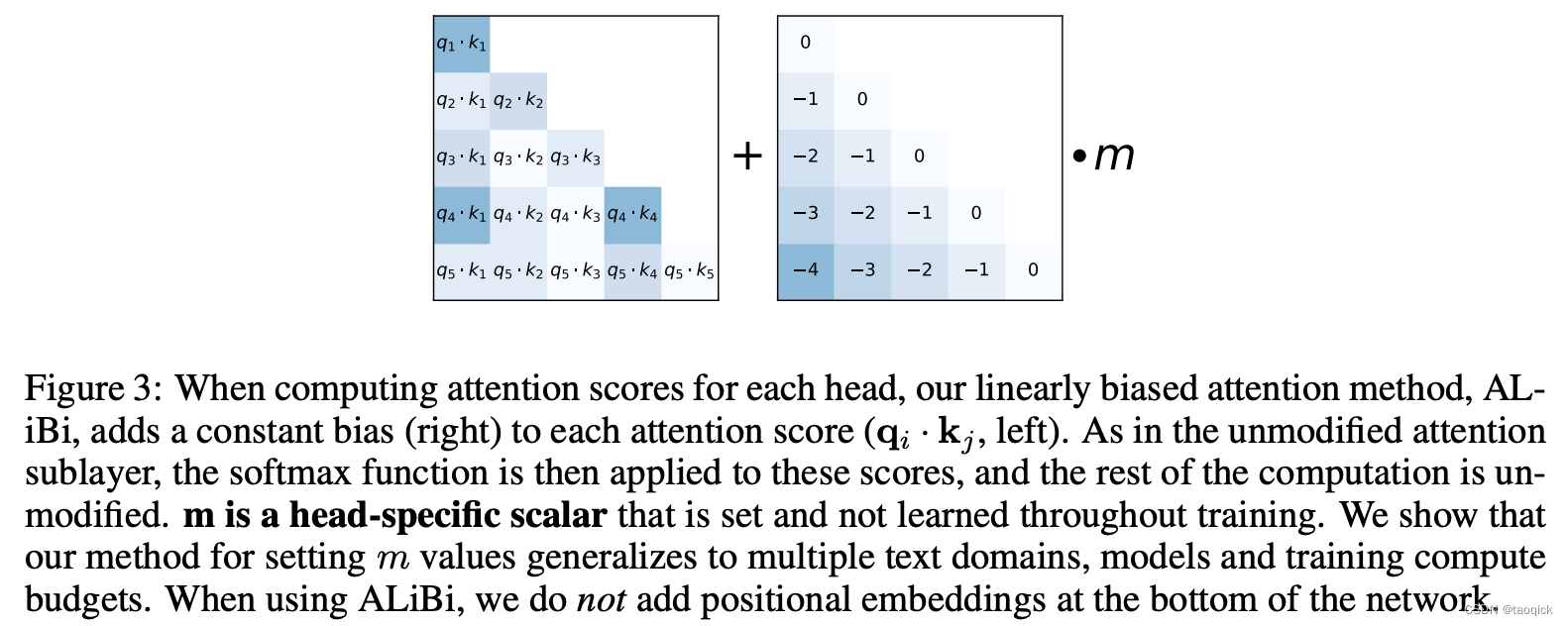

ALiBi 的实现思路很直觉,模型在接收输入时直接去掉 Position Embedding 向量,
而是在 Attention 中计算 query·Key 的值后面加入一个偏置常量(非训练变量),来达到注入位置信息的效果。
而这个常量是一个 事先计算好 的数值,并且每个头(head)的值都有所不同。
sin cos位置编码实现
import torch
def getPositionEncoding(seq_len, d, n=10000):
P = torch.zeros(seq_len, d)
for k in range(seq_len):
for i in torch.arange(d//2):
denominator = n ^ (2*i//d)
P[k, 2*i] = torch.sin(k/denominator)
P[k, 2*i+1] = torch.cos(k/denominator)
return P
P = getPositionEncoding(seq_len=3, d=4)
print(P)
'''
tensor([[0.0000e+00, 1.0000e+00, 0.0000e+00, 1.0000e+00],
[1.0000e-04, 1.0000e+00, 1.0000e-04, 1.0000e+00],
[2.0000e-04, 1.0000e+00, 2.0000e-04, 1.0000e+00]])
'''
RoPE代码实现
import torch
from typing import Tuple
def precompute_freqs_cis(dim: int, seq_len: int, theta: float = 10000.0):
# 计算词向量元素两两分组之后,每组元素对应的旋转角度
freqs = 1.0 / (theta ** (torch.arange(0, dim, 2)[: (dim // 2)].float() / dim))
# 生成 token 序列索引 t = [0, 1,..., seq_len-1]
t = torch.arange(seq_len, device=freqs.device)
# freqs.shape = [seq_len, dim // 2]
freqs = torch.outer(t, freqs).float()
# torch.polar的文档, https://pytorch.org/docs/stable/generated/torch.polar.html
# torch.polar输入参数是abs和angle,abs所有值都一样,abs和angle的shape都一样
# torch.polar输入参数是abs和angle,则freqs_cis = abs*(cos(angle) + sin(angle)i)
freqs_cis = torch.polar(torch.ones_like(freqs), freqs)
return freqs_cis
def apply_rotary_emb(
xq: torch.Tensor,
xk: torch.Tensor,
freqs_cis: torch.Tensor,
) -> Tuple[torch.Tensor, torch.Tensor]:
# xq.shape = [batch_size, seq_len, dim]
# xq_.shape = [batch_size, seq_len, dim // 2, 2]
xq_ = xq.float().reshape(*xq.shape[:-1], -1, 2)
xk_ = xk.float().reshape(*xk.shape[:-1], -1, 2)
# 转为复数域, xq_.shape = [batch_size, seq_len, dim // 2]
xq_ = torch.view_as_complex(xq_)
xk_ = torch.view_as_complex(xk_)
# 应用旋转操作,然后将结果转回实数域
# xq_out.shape = [batch_size, seq_len, dim]
xq_out = torch.view_as_real(xq_ * freqs_cis).flatten(2) #从dim=2维度开始拍平
xk_out = torch.view_as_real(xk_ * freqs_cis).flatten(2)
return xq_out.type_as(xq), xk_out.type_as(xk)
if __name__ == '__main__':
seq_len,dim=3,4
freqs_cis = precompute_freqs_cis(dim=dim, seq_len=seq_len, theta=10000.0)
xq = torch.rand(1, seq_len, dim)
xk = torch.rand(1, seq_len, dim)
res = apply_rotary_emb(xq, xk, freqs_cis)
# res的shape是1, seq_len, dim
'''
class Attention(nn.Module):
def __init__(self, args: ModelArgs):
super().__init__()
self.wq = Linear(...)
self.wk = Linear(...)
self.wv = Linear(...)
self.freqs_cis = precompute_freqs_cis(dim, max_seq_len * 2)
def forward(self, x: torch.Tensor):
bsz, seqlen, _ = x.shape
xq, xk, xv = self.wq(x), self.wk(x), self.wv(x)
xq = xq.view(batch_size, seq_len, dim)
xk = xk.view(batch_size, seq_len, dim)
xv = xv.view(batch_size, seq_len, dim)
# attention 操作之前,应用旋转位置编码
xq, xk = apply_rotary_emb(xq, xk, freqs_cis=freqs_cis)
# scores.shape = (bs, seqlen, seqlen)
scores = torch.matmul(xq, xk.transpose(1, 2)) / math.sqrt(dim)
scores = F.softmax(scores.float(), dim=-1)
output = torch.matmul(scores, xv) # (batch_size, seq_len, dim)
# ......
'''
以下转载自https://kexue.fm/archives/8130#CNN%E5%BC%8F
























 5768
5768

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









