






Transformer默认是512,在 线性Transformer应该不是你要等的那个模型 中强调对于base版来说,当序列长度不超过1536时,Transformer的复杂度都是近乎线性的;当序列长度超过1536时,Transformer的计算量逐渐以Attention为主,复杂度慢慢趋于二次方,直到长度超过4608,才真正以二次项为主。 今天来梳理下真有更长的Transformer如何做的一些方法:
Sparse Transformer
来自于Generating Long Sequences with Sparse Transformers,以下转载自https://kexue.fm/archives/6853#Sparse%20Self%20Attention:

Longformer: The Long-Document Transformer
来自于 https://arxiv.org/abs/2004.05150

也就是说,从下图实现来看Longformer和Sparse Transformer的思路是一样的,只是这篇的实验更加充分

Big Bird
- Random attention:对每个token随机选取其他的r个token计算attention,
来源于图论中的Erdős–Rényi model:对于一个有N个节点的图,如果其每条边形成的概率为p,那么当p足够大时,就几乎会形成一个完全连通图;类比到Transformer中,不需要对每两个Token都计算attention,只要每个token以较大的概率对其他token做attention,那么整个序列就可以连通起来; - Window attention:和第一篇的local self attention一样;
- Global attention:尽管Random attention已经保证整个序列大概率是联通的,选取一些global token在全局做attention还是会有更好的效果,同时不至于太过增加计算量。这里还分为internal和extended两种方法:a) internal:在序列中随机选取一些token作为global token;extended:在序列外额外补充一些token作为global token(例如[CLS]);

LongNet(LongNet: Scaling Transformers to 1,000,000,000 Tokens)
这篇文章有两张亮炸眼的图:

然后看改进,其实和LongTransformer、Big Bird是一脉相承的,作者管这里叫Dilated Attention

Reformer: The Efficient Transformer
来自于https://arxiv.org/abs/2001.04451,
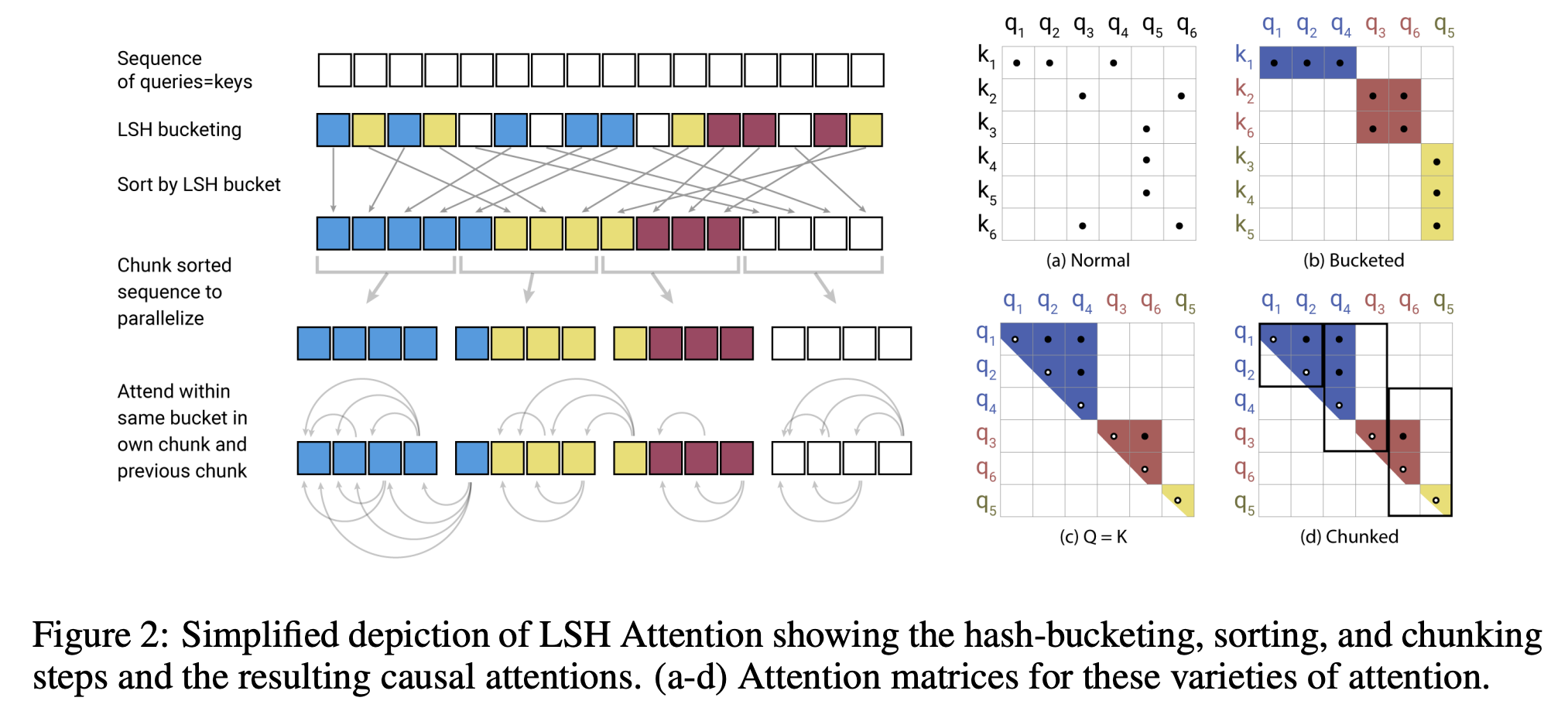
以下转载自 https://kexue.fm/archives/7546
Reformer也是有代表性的改进工作,它将Attention的复杂度降到了𝒪(nlogn)。某种意义上来说,Reformer也是稀疏Attention的一种,只不过它的稀疏Pattern不是事先指定的,而是通过LSH(Locality Sensitive Hashing)技术(近似地)快速地找到最大的若干个Attention值,然后只去计算那若干个值。此外,Reformer通过构造可逆形式的FFN(Feedforward Network)替换掉原来的FFN,然后重新设计反向传播过程,从而降低了显存占用量。
可以来看一下怎么实现的,代码摘自https://github.com/Rick-McCoy/Reformer-pytorch/blob/master/model/attention.py简单来说就是把qk之间的乘法 n 2 d n^2d n2d优化成了 n ∗ b u c k e t _ l e n g t h ∗ d n*bucket\_length*d n∗bucket_length∗d
从
[batch*head, length, dim] * [batch*head, dim, length]->[batch*head, length, length]
变成
reordered_query = [batch * head, length, d_k, rounds]
lookback_key = [batch * head, n_buckets, bucket_length, d_k, rounds]
这俩 '...ijk,...ljk->...ilk'
得到
[batch * head, n_buckets, bucket_length * 2, d_k, rounds]
class LocalitySensitiveHash(nn.Module):
'''
Implements Locality Sensitive Hash
class is used to save random matrix used for hashing
'''
def __init__(self, hp, args):
super(LocalitySensitiveHash, self).__init__()
self.d_k = hp.model.d_model // hp.model.head
self.rounds = hp.model.rounds
self.rand_matrix = None
def forward(self, inp: torch.Tensor, n_buckets=0, random=True):
batch_size = inp.size(0)
length = inp.size(1)
inp = F.normalize(inp, p=2, dim=-1)
# [batch * head, length, d_k]
if random:
self.rand_matrix = torch.randn(
[batch_size, self.d_k, self.rounds, n_buckets // 2],
device=inp.get_device()
)
# [batch * head, d_k, rounds, n_buckets // 2]
self.rand_matrix /= torch.norm(self.rand_matrix, dim=1, keepdim=True)
# [batch * head, d_k, rounds, n_buckets // 2]
matmul = torch.einsum('...ij,...jkl->...ikl', inp, self.rand_matrix)
# [batch * head, length, d_k] * [batch * head, d_k, rounds, n_buckets // 2]
# -> [batch * head, length, rounds, n_buckets // 2]
hashes = torch.argmax(torch.cat([matmul, -matmul], dim=-1), dim=-1).int()
# [batch * head, length, rounds]
arange = hashes.new_empty((1, length, 1))
# [1, length, 1]
hashes = hashes * length + torch.arange(length, out=arange).expand_as(hashes)
# [batch * head, length, rounds]
return hashes
class LSHAttention(nn.Module):
'''
Implements LSHAttention
class is used to save LocalitySensitiveHash
'''
def __init__(self, hp, args):
super(LSHAttention, self).__init__()
self.d_k = hp.model.d_model // hp.model.head
self.rounds = hp.model.rounds
self.dropout = hp.model.dropout
self.bucket_length = hp.model.bucket_length
self.lsh = LocalitySensitiveHash(hp, args)
def forward(self, query, value, seed, random=True):
length = query.size(1)
n_buckets = length // self.bucket_length
sorted_hashes, hash_indice = torch.sort(self.lsh(query, n_buckets, random), dim=1)
# [batch * head, length, rounds]
original_indice = reverse_sort(hash_indice, dim=1)
# [batch * head, length, rounds]
reordered_query = expand_gather(
expand(query, dim=3, num=self.rounds), dim=1,\
index=hash_indice, expand_dim=2, num=self.d_k
)
# [batch * head, length, d_k, rounds]
reordered_query = reordered_query.reshape(
-1, n_buckets, self.bucket_length, self.d_k, self.rounds
)
# [batch * head, n_buckets, bucket_length, d_k, rounds]
lookback_key = F.normalize(look_back(reordered_query), p=2, dim=-2)
# [batch * head, n_buckets, bucket_length * 2, d_k, rounds]
matmul_qk = torch.einsum(
'...ijk,...ljk->...ilk', reordered_query, lookback_key
) / math.sqrt(self.d_k)
# [batch * head, n_buckets, bucket_length, bucket_length * 2, rounds]
sorted_hashes = sorted_hashes.reshape(
-1, n_buckets, self.bucket_length, self.rounds
) // length
# [batch * head, n_buckets, bucket_length, rounds]
matmul_qk.masked_fill_(
mask=(sorted_hashes[..., None, :] != look_back(sorted_hashes)[..., None, :, :]),\
value=-1e9
)
query_indice = hash_indice.reshape(
-1, n_buckets, self.bucket_length, self.rounds
).int()
# [batch * head, n_buckets, bucket_length, rounds]
key_indice = look_back(query_indice)
# [batch * head, n_buckets, bucket_length * 2, rounds]
matmul_qk.masked_fill_(
mask=(query_indice[..., None, :] < key_indice[..., None, :, :]), value=-1e9
)
matmul_qk.masked_fill_(
mask=(query_indice[..., None, :] == key_indice[..., None, :, :]), value=-1e5
)
key_indice = expand(key_indice, dim=2, num=self.bucket_length).flatten(1, 2)
# [batch * head, length, bucket_length * 2, rounds]
key_indice = expand_gather(
key_indice,
dim=1, index=original_indice,
expand_dim=2, num=self.bucket_length * 2
)
# [batch * head, length, bucket_length * 2, rounds]
count_key = get_dup_keys(
key_indice.flatten(-2, -1), self.rounds
).reshape(-1, length, self.bucket_length * 2, self.rounds)
# [batch * head, length, bucket_length * 2, rounds]
count_key = expand_gather(
count_key, dim=1, index=hash_indice, expand_dim=2, num=self.bucket_length * 2
)
# [batch * head, length, bucket_length * 2, rounds]
matmul_qk = matmul_qk.flatten(1, 2)
# [batch * head, length, bucket_length * 2, rounds]
logsumexp_qk = torch.logsumexp(matmul_qk, dim=2)
# [batch * head, length, rounds]
softmax_qk = torch.exp(matmul_qk - count_key.float().log_() - logsumexp_qk[..., None, :])
# [batch * head, length, bucket_length * 2, rounds]
if self.training:
softmax_qk = deterministic_dropout(softmax_qk, seed=seed, dropout=self.dropout)
# [batch * head, length, bucket_length * 2, rounds]
reordered_value = expand_gather(
expand(value, dim=3, num=self.rounds), dim=1,\
index=hash_indice, expand_dim=2, num=self.d_k
)
# [batch * head, length, d_k, rounds]
reordered_value = reordered_value.reshape(
-1, n_buckets, self.bucket_length, self.d_k, self.rounds
)
# [batch * head, n_buckets, bucket_length, d_k, rounds]
softmax_qk = softmax_qk.reshape(
-1, n_buckets, self.bucket_length, self.bucket_length * 2, self.rounds
)
# [batch * head, n_buckets, bucket_length, bucket_length * 2, rounds]
attention = torch.einsum('...ijl,...jkl->...ikl', softmax_qk, look_back(reordered_value))
# [batch * head, n_buckets, bucket_length, d_k, rounds]
attention = attention.flatten(1, 2)
# [batch * head, length, d_k, rounds]
attention = expand_gather(
attention, dim=1, index=original_indice, expand_dim=2, num=self.d_k
)
# [batch * head, length, d_k, rounds]
logsumexp_qk = torch.gather(logsumexp_qk, dim=1, index=original_indice)
# [batch * head, length, rounds]
logsumexp_qk = F.softmax(logsumexp_qk, dim=1)
# [batch * head, length, rounds]
attention = torch.einsum('...ij,...j->...i', attention, logsumexp_qk)
# [batch * head, length, d_k]
return attention
cosFormer
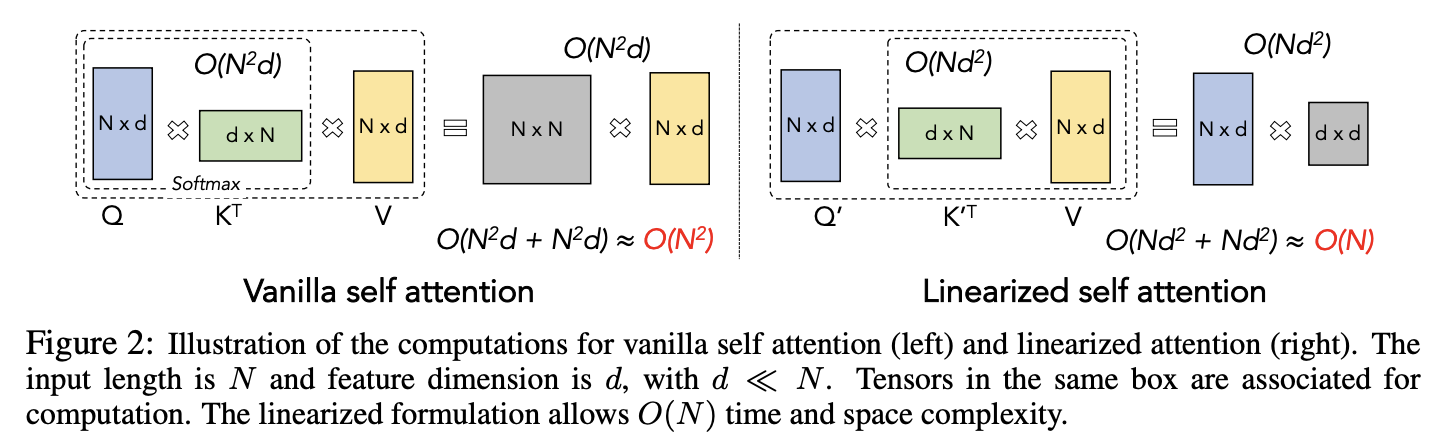
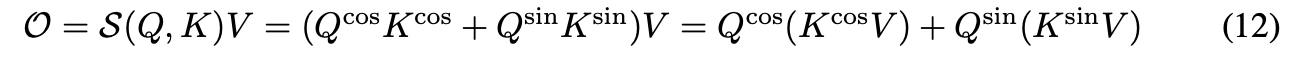
FLASH(Fast Linear Attention with a Single Head)
来自于Google的《Transformer Quality in Linear Time》,简单来说就是GAU+分块融合【FLASH采取了“局部-全局”分块混合的方式,结合了“稀疏化”和“线性化”的优点。首先,对于长度为n的输入序列,我们将它不重叠地划分为n/c个长度为c的块(不失一般性,假设c
能被n整除,论文取c=256)】。更多细节可以参考 https://blog.csdn.net/taoqick/article/details/130543202
RWKV(Receptance Weighted Key Value )
大概搜了一下RWKV和Transformer类模型效果对比,暂时没发现优势,没空了先不看了,以下截图自https://www.zhihu.com/question/602564718/answer/3042600470,

Linear Recurrent Unit
来自Google的Resurrecting Recurrent Neural Networks for Long Sequences(https://arxiv.org/abs/2303.06349),中文版解释参考https://spaces.ac.cn/archives/9554,它是既可以并行又可以串行的极简线性RNN,训练和推断都具备高效的优势,先mark以后再细看
Mamba
Structured State Space sequence model (S4)
来自于Albert Gu的论文Efficiently Modeling Long Sequences with Structured State Spaces
,SSM(state space model)是不带HiPPO算子的序列模型,为了高效的建模长序列,我们基于状态空间模型构建神经网络:

HiPPO的全称是high-order polynomial projection operator,HiPPO算子的核心想法是利用快速傅里叶变化解决长距离依赖的问题
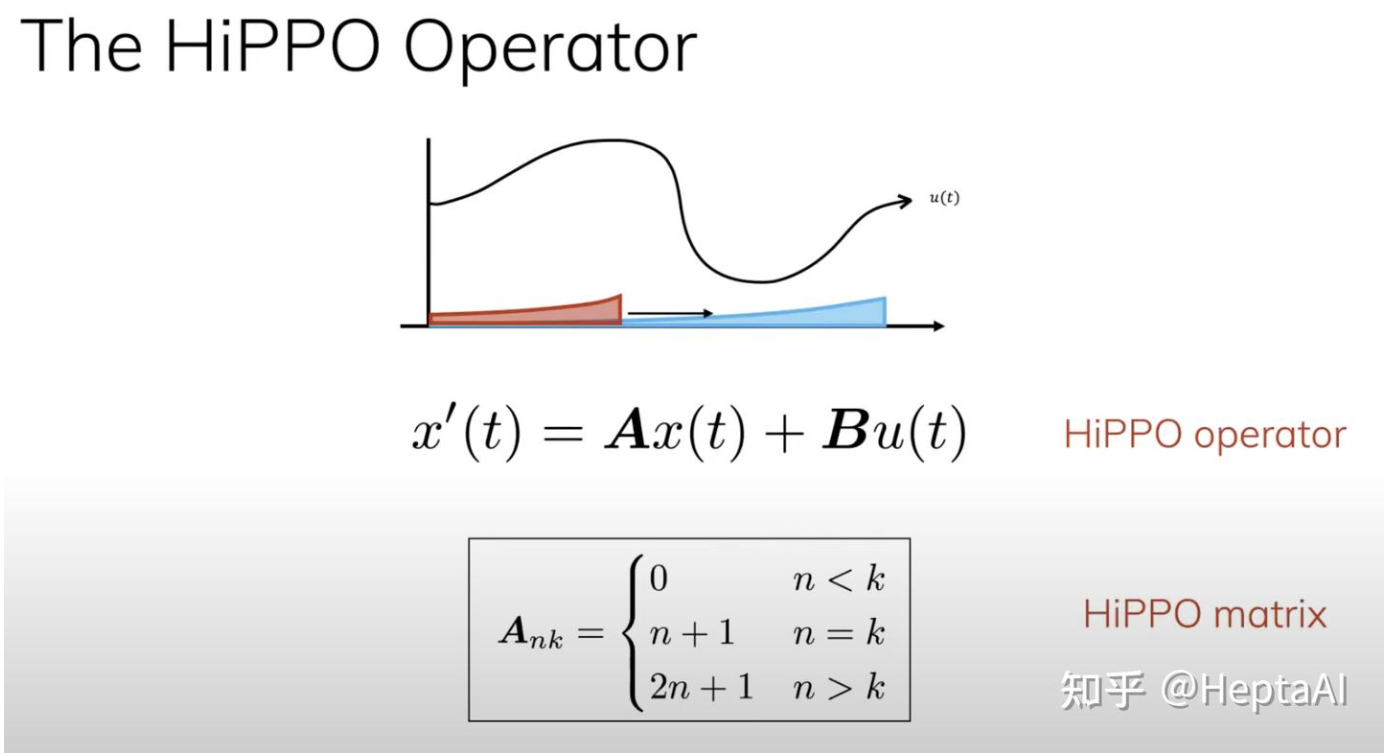
S4 = SSM + HiPPO + Structed Matrix
Mamba=S6
来自于 Mamba: Linear-Time Sequence Modeling with Selective State Spaces,Mamba的结构非常简单,如下图:
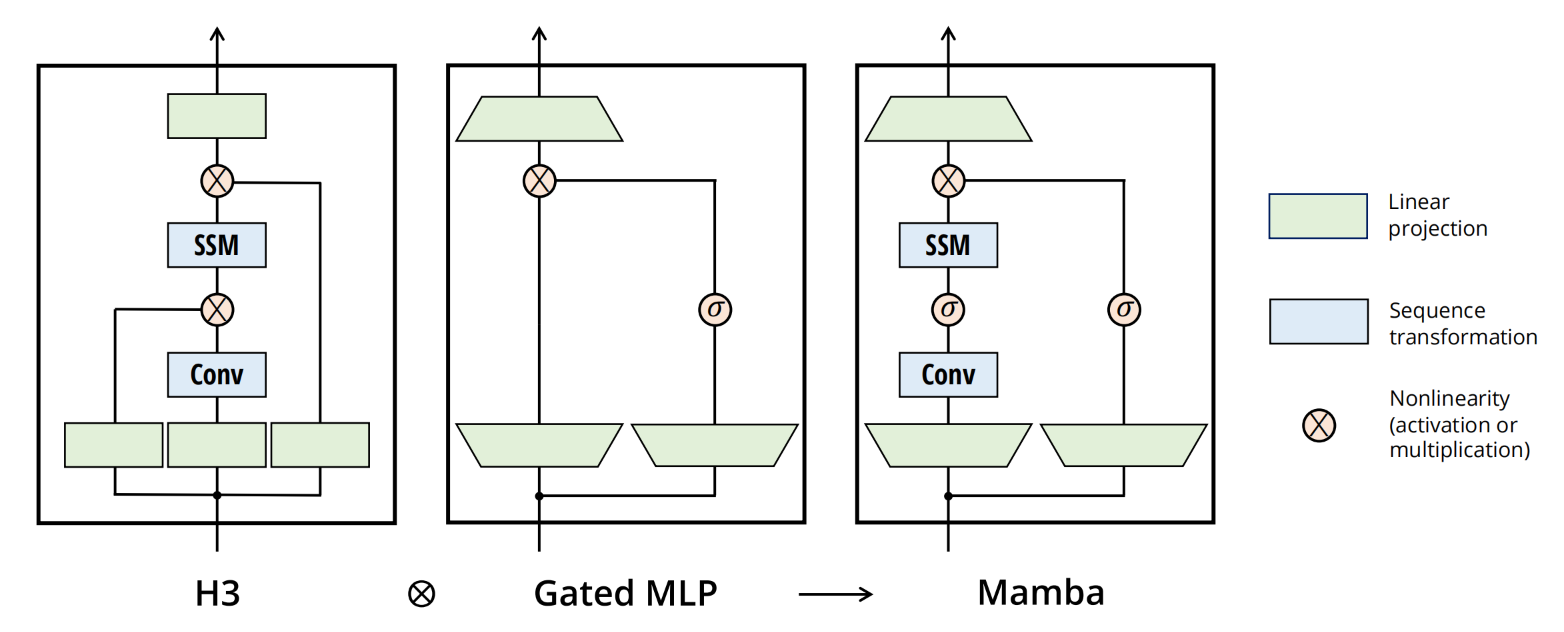
Mamba很大一部分工作在于如何优化计算:

写的比较好的博客,先码后细看:
- https://zhuanlan.zhihu.com/p/670820688
- https://blog.csdn.net/v_JULY_v/article/details/134923301
Mamba2
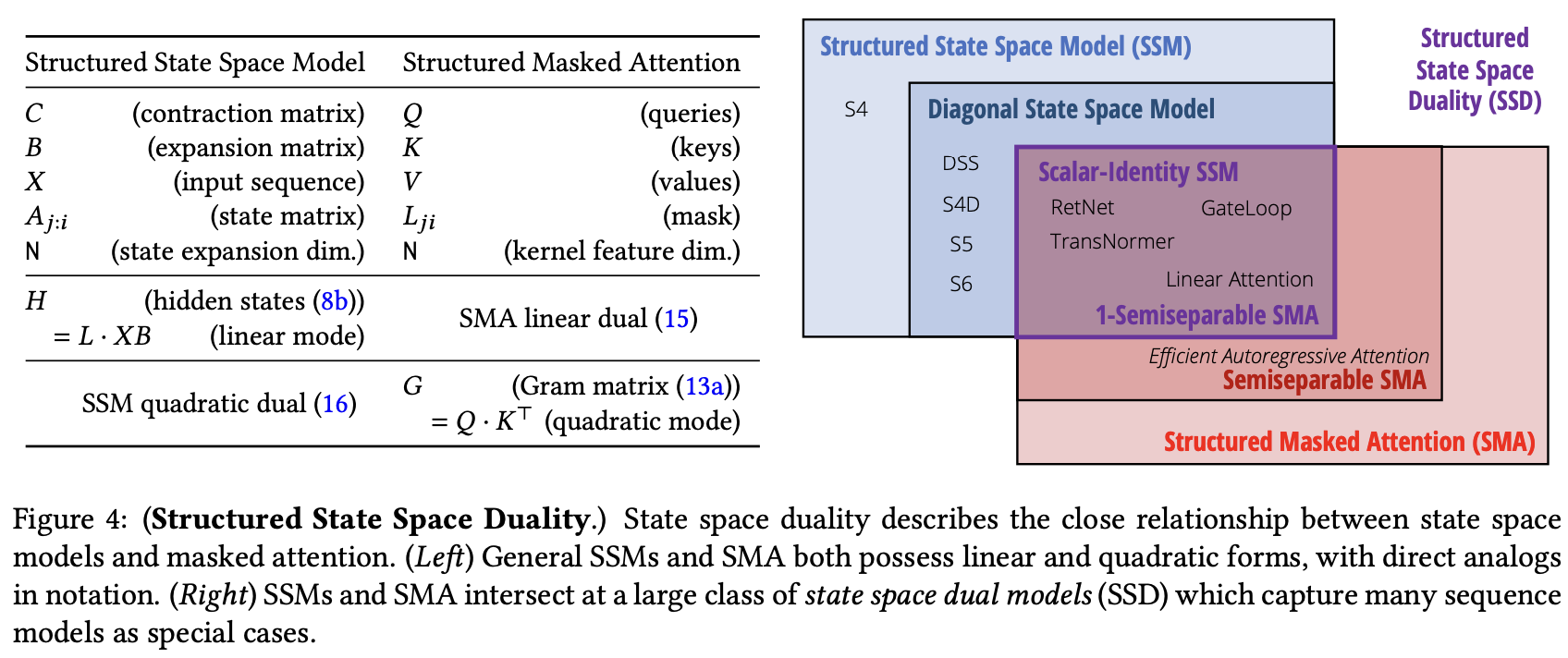
来自Transformers are SSMs: Generalized Models and Efficient Algorithms
Through Structured State Space Duality,Mamba-2比Mamba1,状态空间扩大8倍,训练速度提高50%!团队通过提出一个叫结构化状态空间二元性(Structured State Space Duality,SSD)的理论框架,把这两大模型家族统一了起来。
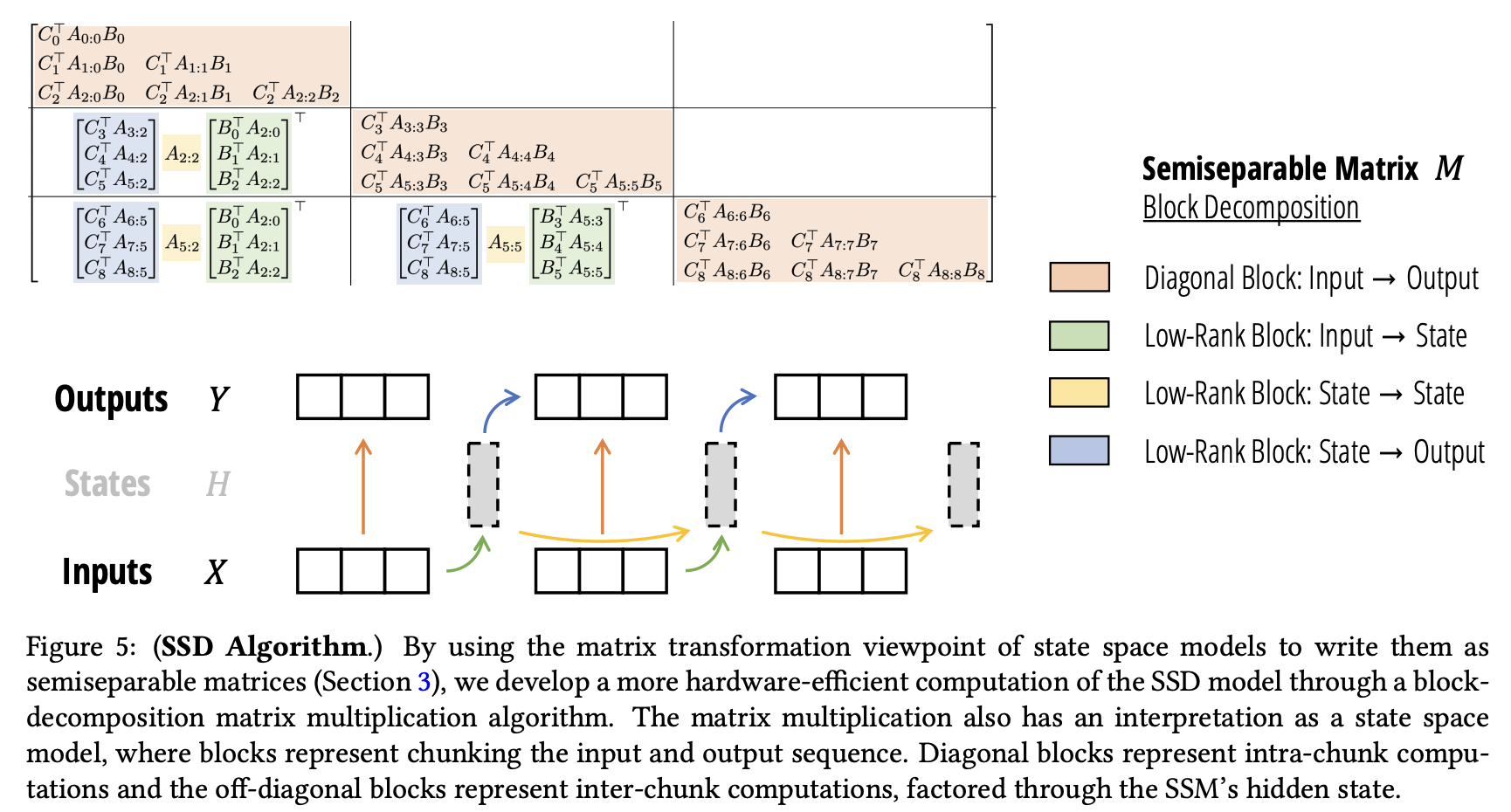
基于SSD思想的新算法,Mamba-2支持更大的状态维度(从16扩大到256),从而学习更强的表示能力。新方法基于块分解矩阵乘法,利用了GPU的存储层次结构,提高训练速度。
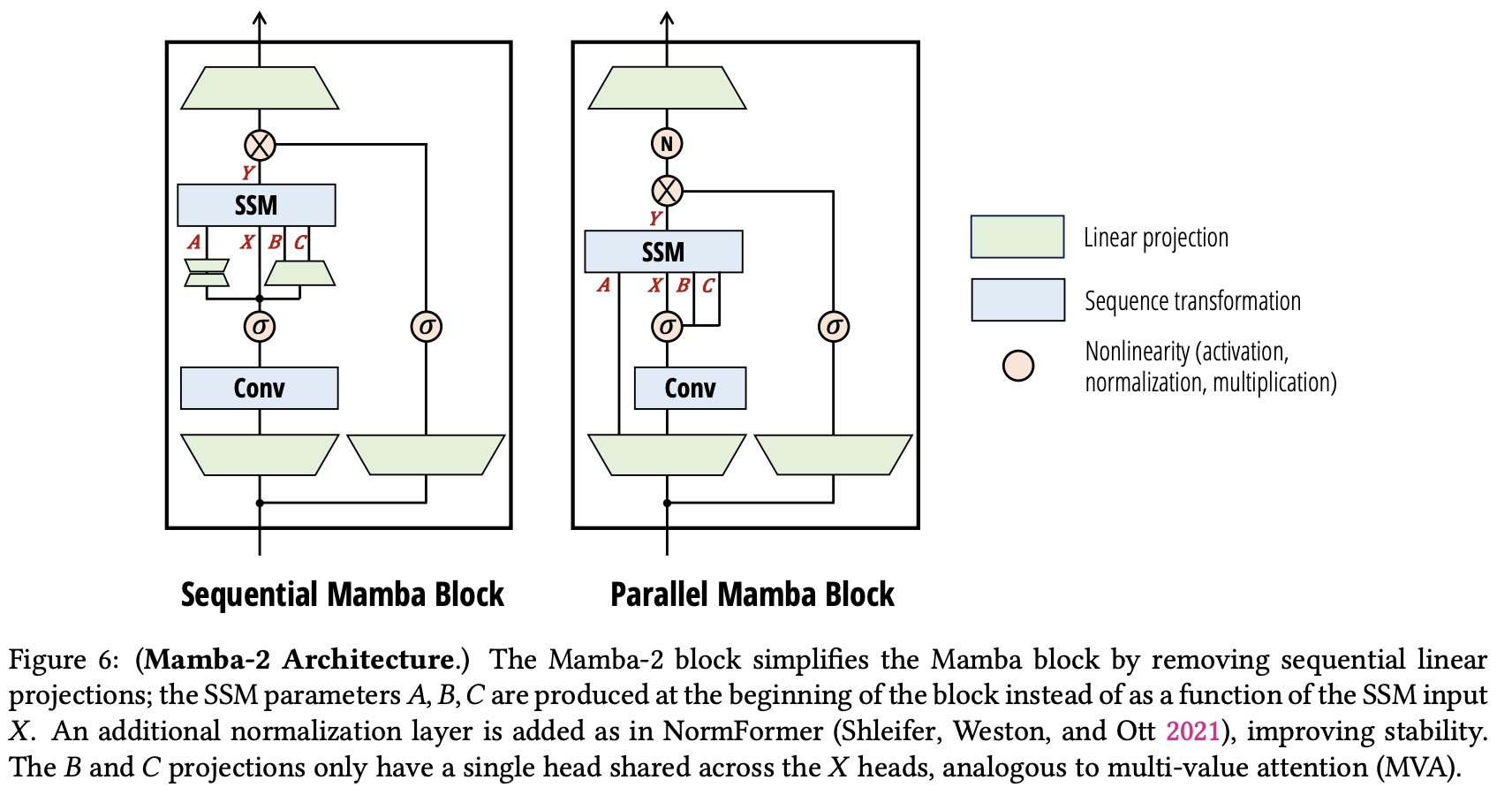
架构设计上,Mamba-2简化了块的设计,同时受注意力启发做出一些改动,借鉴多头注意力创建了多输入SSM。
写的比较好的博客,先码后细看:
- https://mp.weixin.qq.com/s/E9uP0qPfpzv3GOSAci-qbg
Transformer+COT比Mamba要好
两个团队一致证实包括 Sparse Transformer、Linear Transformer、Mamba 在内的许多架构,即使在这些模型上应用思维链,其理论上的能力上限仍无法解决多种实际推理问题,并与标准 Transformer 有本质差距。这些理论结果为高效结构的实用价值蒙上了一层阴影。
论文 1:Do Efficient Transformers Really Save Computation? (发表于 ICML 2024)
论文链接:https://arxiv.org/abs/2402.13934
论文 2:RNNs are not Transformers (Yet): The Key Bottleneck on In-context Retrieval
论文链接:https://arxiv.org/abs/2402.18510
转载自 https://mp.weixin.qq.com/s/9QsjiccHtHkrxZApQbVJ3Q
Hawk和Griffin
在谷歌 DeepMind 近日的一篇论文中,研究者提出了 RG-LRU 层,它是一种新颖的门控线性循环层,并围绕它设计了一个新的循环块来取代多查询注意力(MQA)。
他们使用该循环块构建了两个新的模型,一个是混合了 MLP 和循环块的模型 Hawk,另一个是混合了 MLP 与循环块、局部注意力的模型 Griffin。
部分转载自 https://mp.weixin.qq.com/s/RtAZiEzjRWgqQw3yu3lvcg,继续先mark后看

















 1868
1868

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









