







线性注意力机制(Linear Attention)是一类通过降低计算复杂度来优化传统注意力机制的方法,尤其适用于长序列任务。其核心思想是将注意力矩阵的计算复杂度从 O ( N 2 ) O(N^2) O(N2) 降低到 O ( N ) O(N) O(N) 或 O ( N log N ) O(N \log N) O(NlogN),从而显著减少计算和内存开销。以下是几种典型的线性注意力算法:
Linear Transformer
在 Transformer 领域,最经典的线性注意力(Linear Attention)机制 出自 2020 年由 Katharopoulos 等人提出的《Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention》(简称 Linear Transformer)。该工作首次系统性地提出了用线性复杂度近似标准 Softmax 注意力的方法,成为后续线性注意力研究的基石。
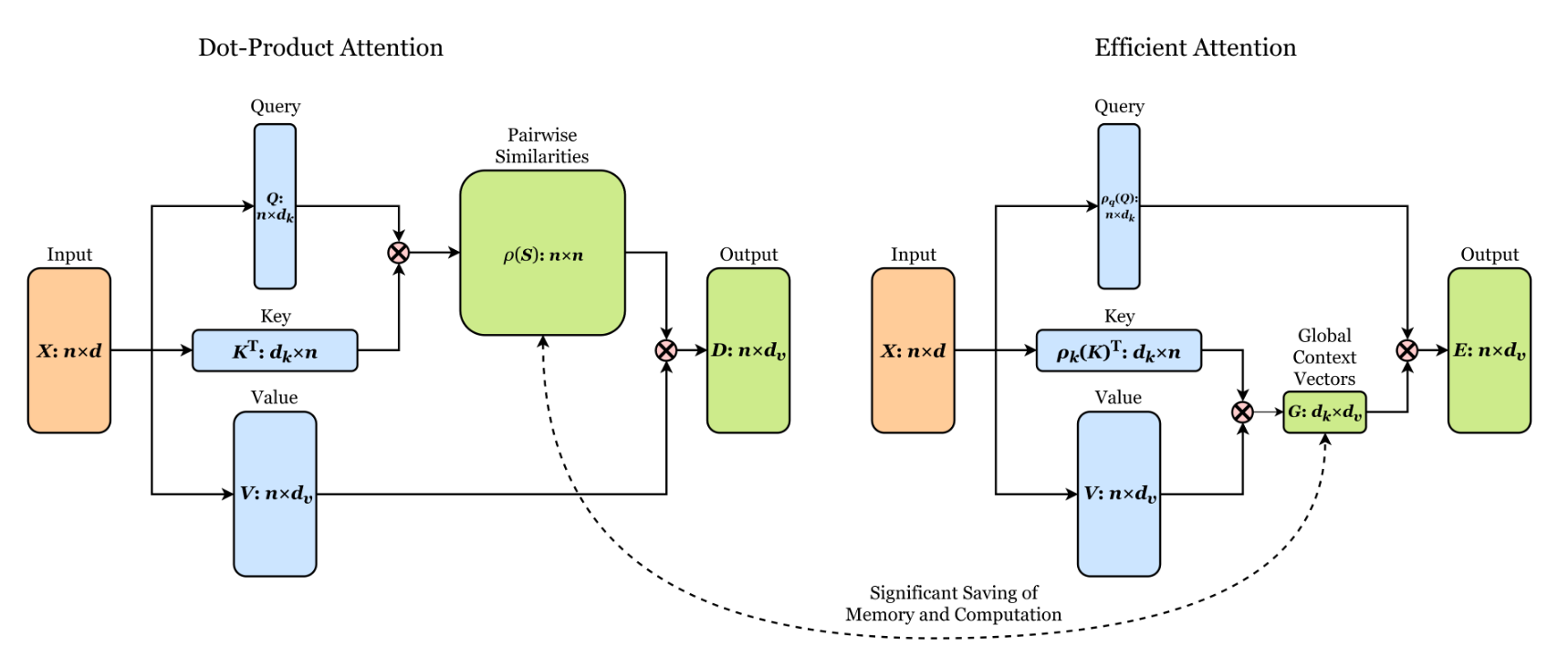
原始的单头注意力机制的计算复杂度:

1. 核心思想
传统 Transformer 的 Softmax 注意力 计算复杂度为 O ( N 2 ) O(N^2) O(N2)( N N N 是序列长度),而 Linear Attention 通过数学重构将复杂度降至 O ( N ) O(N) O(N),关键步骤:
-
分解 Softmax 注意力:
标准注意力公式为:
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dkQKT)V
Linear Attention 将其重写为:
Attention ( Q , K , V ) = ϕ ( Q ) ( ϕ ( K ) T V ) ϕ ( Q ) ( ϕ ( K ) T 1 ) \text{Attention}(Q, K, V) = \frac{\phi(Q)(\phi(K)^T V)}{\phi(Q)(\phi(K)^T \mathbf{1})} Attention(Q,K,V)=ϕ(Q)(ϕ(K)T1)ϕ(Q)(ϕ(K)TV)
其中 ϕ ( ⋅ ) \phi(\cdot) ϕ(⋅) 是一个特征映射函数(如 ϕ ( x ) = elu ( x ) + 1 \phi(x) = \text{elu}(x) + 1 ϕ(x)=elu(x)+1),将 Q Q Q 和 K K K 映射到非负空间。 -
利用结合律优化计算顺序:
先计算 ( ϕ ( K ) T V ) (\phi(K)^T V) (ϕ(K)TV) 和 ( ϕ ( K ) T 1 ) (\phi(K)^T \mathbf{1}) (ϕ(K)T1)(复杂度 O ( N ) O(N) O(N)),再与 ϕ ( Q ) \phi(Q) ϕ(Q) 相乘,避免显式计算 Q K T QK^T QKT( O ( N 2 ) O(N^2) O(N2))。
2. 为什么它成为经典?
- 理论严谨性:首次证明了线性注意力的可行性,并通过数学推导保证近似效果。
- 通用性:适用于自回归和非自回归任务(如文本生成、图像分类)。
- 效率提升:在长序列任务(如 DNA 序列分析、高分辨率图像处理)中显著降低内存和计算成本。
3. 后续发展
Linear Transformer 启发了多种改进方案,例如:
- Performer(2021, Google):使用随机正交特征映射(Random Fourier Features)进一步优化近似效果。
- Linformer(2020, Facebook):通过低秩投影压缩 K K K 和 V V V 的维度。
- Flowformer(2022):引入流模型思想增强线性注意力的表达能力。
5. 适用场景
- 长序列建模:如视频处理、基因组序列分析。
- 资源受限设备:移动端或边缘计算场景。
- 实时应用:需要低延迟的生成任务(如实时语音合成)。
总结
Linear Transformer 是线性注意力领域的开创性工作,通过特征映射和计算顺序优化实现了
O
(
N
)
O(N)
O(N) 复杂度,平衡了效率与性能。尽管后续模型(如 Performer、Linformer)在某些任务上表现更好,但其核心思想仍是当前线性注意力研究的基准。
Linear Transformer 和 Linformer对比
Linear Transformer 和 Linformer 都是旨在降低 Transformer 自注意力计算复杂度的经典方法,但两者的设计思路和实现方式有显著区别。以下是它们的核心对比:
1. 核心目标
- 共同点:将标准 Softmax 注意力的 O ( N 2 ) O(N^2) O(N2) 复杂度降至 线性复杂度 O ( N ) O(N) O(N)( N N N 为序列长度)。
- 差异:
- Linear Transformer:通过数学重构(特征映射+结合律)直接近似 Softmax 注意力。
- Linformer:通过低秩投影压缩 Key 和 Value 的序列长度,间接降低计算量。
2. 方法原理对比
(1) Linear Transformer
-
核心思想:
将 Softmax 注意力分解为线性运算,利用特征映射函数 ϕ ( ⋅ ) \phi(\cdot) ϕ(⋅) 和结合律重写注意力公式:
Attention ( Q , K , V ) = ϕ ( Q ) ( ϕ ( K ) T V ) ϕ ( Q ) ( ϕ ( K ) T 1 ) \text{Attention}(Q, K, V) = \frac{\phi(Q)(\phi(K)^T V)}{\phi(Q)(\phi(K)^T \mathbf{1})} Attention(Q,K,V)=ϕ(Q)(ϕ(K)T1)ϕ(Q)(ϕ(K)TV)- 特征映射:使用简单的非线性函数(如 ϕ ( x ) = elu ( x ) + 1 \phi(x) = \text{elu}(x)+1 ϕ(x)=elu(x)+1)保证非负性。
- 计算顺序:先计算 ϕ ( K ) T V \phi(K)^T V ϕ(K)TV(复杂度 O ( N ) O(N) O(N)),再与 ϕ ( Q ) \phi(Q) ϕ(Q) 相乘。
-
优点:
- 保持自注意力机制的全局交互能力。
- 无需训练额外的投影矩阵,计算更轻量。
(2) Linformer
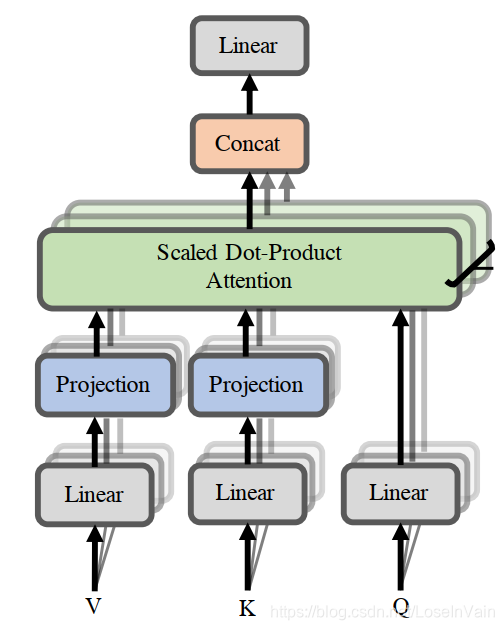
在Q和K的后续添加两个Projection单元,将序列长度n映射到低维的k,作者将这种单元称之为Linformer。
-
核心思想:
假设注意力矩阵是低秩的,通过投影将 K K K 和 V V V 的序列长度从 N N N 压缩到 k k k( k ≪ N k \ll N k≪N):
K ~ = K ⋅ E K , V ~ = V ⋅ E V \tilde{K} = K \cdot E_K, \quad \tilde{V} = V \cdot E_V K~=K⋅EK,V~=V⋅EV
其中 E K , E V ∈ R N × k E_K, E_V \in \mathbb{R}^{N \times k} EK,EV∈RN×k 是可学习的投影矩阵。
注意力计算变为:
Attention ( Q , K ~ , V ~ ) = softmax ( Q K ~ T d k ) V ~ \text{Attention}(Q, \tilde{K}, \tilde{V}) = \text{softmax}\left(\frac{Q \tilde{K}^T}{\sqrt{d_k}}\right) \tilde{V} Attention(Q,K~,V~)=softmax(dkQK~T)V~- 复杂度:从 O ( N 2 ) O(N^2) O(N2) 降至 O ( N ⋅ k ) O(N \cdot k) O(N⋅k)(若 k k k 为常数,则为 O ( N ) O(N) O(N))。
-
优点:
- 直接压缩序列长度,适合超长序列(如文档或高分辨率图像)。
- 保留原始 Softmax 形式,理论近似误差更小。
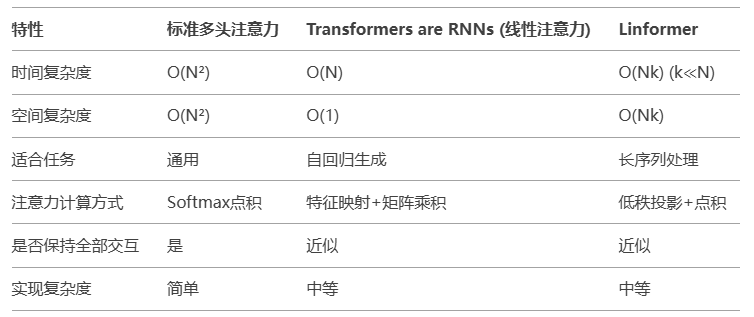
3. 关键区别总结
| 特性 | Linear Transformer | Linformer |
|---|---|---|
| 核心方法 | 特征映射 + 结合律优化 | 低秩投影压缩 K K K 和 V V V |
| 复杂度 | O ( N ) O(N) O(N)(严格线性) | O ( N ⋅ k ) O(N \cdot k) O(N⋅k)(近似线性) |
| 是否保留 Softmax | ❌ 替换为线性近似 | ✅ 保留原始 Softmax |
| 是否需要投影矩阵 | ❌ 无额外参数 | ✅ 需学习 E K , E V E_K, E_V EK,EV |
| 适用场景 | 通用序列任务(生成、分类) | 超长序列(文档、图像) |
| 近似误差 | 较高(依赖特征映射的合理性) | 较低(低秩假设成立时) |
| 开源实现 | GitHub | GitHub |
4. 直观理解
-
Linear Transformer 像“用乘法分配律加速计算”:
Q ⋅ ( K T V ) = ( Q K T ) V Q \cdot (K^T V) = (Q K^T) V Q⋅(KTV)=(QKT)V
左式(Linear)复杂度更低,但近似了右式(标准注意力)的效果。 -
Linformer 像“用降维压缩数据”:
将 K K K 和 V V V 从 N × d N \times d N×d 投影到 k × d k \times d k×d(类似 PCA),直接减少计算量。
5. 代码对比
(1) Linear Transformer 核心代码
def linear_attention(Q, K, V):
phi = lambda x: F.elu(x) + 1 # 特征映射
Q, K = phi(Q), phi(K)
KV = torch.einsum('nkd,nkv->kdv', K, V) # 先计算 K^T V
return torch.einsum('nkd,kdv->nkv', Q, KV)
(2) Linformer 核心代码
class LinformerAttention(nn.Module):
def __init__(self, dim, seq_len, k=256):
super().__init__()
self.E_K = nn.Parameter(torch.randn(seq_len, k)) # 投影矩阵
self.E_V = nn.Parameter(torch.randn(seq_len, k))
def forward(self, Q, K, V):
K = torch.einsum('nkd,nk->kd', K, self.E_K) # 降维
V = torch.einsum('nkd,nk->kd', V, self.E_V)
attn = torch.softmax(Q @ K.T / sqrt(dim), dim=-1)
return attn @ V
6. 如何选择?
-
优先 Linear Transformer:
- 任务需要严格线性复杂度且对近似误差不敏感(如实时生成)。
- 设备资源有限,需减少参数量。
-
优先 Linformer:
- 处理超长序列(如 4K 图像、万词文档)。
- 需保留 Softmax 的精确交互特性(如敏感的分类任务)。
总结
两者均为线性注意力的里程碑工作:
- Linear Transformer 胜在数学简洁,适合轻量级场景;
- Linformer 胜在低秩压缩,适合长序列高精度需求。
后续研究(如 Performer、Nyströmformer)往往结合两者优点进一步优化。
经典模型
1. Performer (2020)
- 核心思想:使用随机特征映射(Random Feature Maps)近似 softmax 核函数,将注意力矩阵分解为低秩形式。
- 优点:计算复杂度为 O ( N ) O(N) O(N),适用于长序列任务。
- 缺点:随机特征映射可能引入近似误差。
- 论文:Rethinking Attention with Performers
2. Linformer (2020)
- 核心思想:通过低秩投影将 Key 和 Value 矩阵的维度从 N × d N \times d N×d 降为 k × d k \times d k×d(其中 k ≪ N k \ll N k≪N),从而将复杂度从 O ( N 2 ) O(N^2) O(N2) 降为 O ( N k ) O(Nk) O(Nk)。
- 优点:简单高效,适合长序列任务。
- 缺点:低秩投影可能丢失部分信息。
- 论文:Linformer: Self-Attention with Linear Complexity
3. Linear Transformer (2020)
- 核心思想:使用核函数(如 RBF 或多项式核)替换 softmax,将注意力矩阵分解为 Q ( K T V ) Q(K^T V) Q(KTV) 的形式,从而将复杂度降为 O ( N ) O(N) O(N)。
- 优点:计算高效,适合长序列任务。
- 缺点:核函数的选择可能影响性能。
- 论文:Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention
4. Reformer (2020)
- 核心思想:结合局部敏感哈希(LSH)和可逆残差层,将注意力限制在局部区域,从而降低计算复杂度。
- 优点:适用于长序列任务,显存占用低。
- 缺点:LSH 可能引入近似误差。
- 论文:Reformer: The Efficient Transformer
5. BigBird (2020)
- 核心思想:使用
稀疏注意力机制,结合全局、局部和随机注意力,将复杂度从 O ( N 2 ) O(N^2) O(N2) 降为 O ( N ) O(N) O(N)。 - 优点:适合长序列任务,性能接近全注意力。
- 缺点:稀疏模式可能影响模型表达能力。
- 论文:BigBird: Transformers for Longer Sequences
6. Longformer (2020)
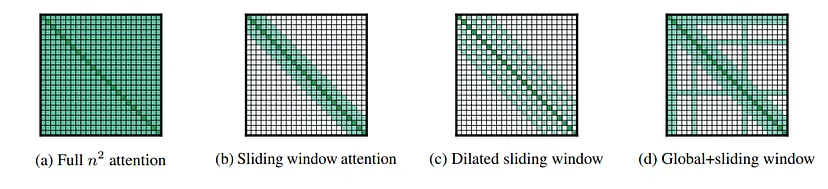
- 核心思想:使用
滑动窗口注意力和全局注意力,将复杂度从 O ( N 2 ) O(N^2) O(N2) 降为 O ( N ) O(N) O(N)。 - 优点:适合长序列任务,显存占用低。
- 缺点:滑动窗口可能限制全局信息的捕捉。
- 论文:Longformer: The Long-Document Transformer
总结
线性注意力机制通过低秩分解、核函数近似、稀疏化、局部注意力等方法,显著降低了传统注意力机制的计算和内存开销。这些方法在长序列任务(如文本、基因组、图像)中表现出色,但需要在计算效率和模型性能之间进行权衡。选择哪种算法取决于具体任务的需求和资源限制。


















 5247
5247

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









