







欢迎来到滔滔讲AI。本教程为免费系列教程,感谢关注,以防找不到。
一、说明
大家都知道使用扣子(coze)把一些文本内容转为小红书风格很方便。但每次都是复制粘贴。很麻烦那能不能批量呢?
今天我们就来学习下,使用扣子(coze)平台完成内容的批量转换。
基本思路是读取飞书多维表格的多条记录内容,然后将读取的内容进行小绿书风格转换。接着把转换后的内容重新更新回去飞书多维表格。
涉及的知识点如下(蓝色字体可以点击到相关文章)
- 智能体
- 工作流
- 循环节点
- 飞书多维表格
二、操作
下面我们就来实际操作下
创建多维表格并填写内容
首先我们把创建一个多维表格,并填写以下示例内容和结构。
一共分为三列。第一列是我设置了一个自动编号无实际意义。
第二列old txt纯文本类型这一列存放了原始的文本。
第三列new txt准备存放换为小红书风格之后的文本。

搭建工作流
在扣子(coze)平台上官方提供了大量的高质量且实用的场景,帮助搭建快速实现想法。
所有推荐大家选用官方插件。
使用官方提供的飞书多维表格插件。这个插件下提供了多种工具。我们使用到的有
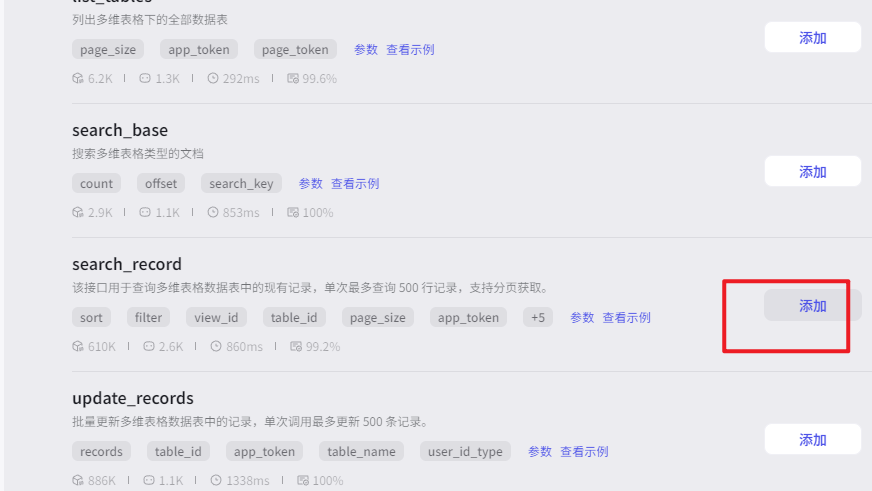
查询多维表格数据表中的记录search_record,
批量更新多维表格数据表中的现有记录update_records
飞书多维表格,支持以下功能:
| 序号 |
功能 |
对应工具 |
| 1 |
创建多维表格 |
create_base |
| 2 |
创建多维表格数据表 |
create_table |
| 3 |
列出多维表格下的全部数据表 |
list_tables |
| 4 |
获取多维表格的元数据 |
get_base_info |
| 5 |
在多维表格数据表中新增多条记录 |
add_records |
| 6 |
根据 record_id 检索多维表格数据表中的记录 |
说的支持这个,但没嘚找到 |
| 7 |
批量更新多维表格数据表中的现有记录 |
update_records |
| 8 |
查询多维表格数据表中的记录 |
search_record |
| 9 |
搜索多维表格类型的文档 |
search base |
第一步,创建工作流。
- 登录扣子(coze)平台。
- 在左侧导航栏中选择工作空间,并在页面顶部空间列表中选择个人空间或团队空间。<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2370
2370

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









