






 本文介绍了聚类算法如K-means、混合高斯模型、谱聚类及降维技术如PCA、SVD在数据处理中的应用。讨论了算法原理、实现及评估方法,包括如何选择聚类个数、降维作用及应用场景。
本文介绍了聚类算法如K-means、混合高斯模型、谱聚类及降维技术如PCA、SVD在数据处理中的应用。讨论了算法原理、实现及评估方法,包括如何选择聚类个数、降维作用及应用场景。
聚类
K-means:数据间的欧氏距离度量相似性,用EM算法求解,要求数据各向均质,类别里方差相近
混合高斯模型:用椭圆分类,K-means是混合高斯的特殊情况
谱聚类:可以处理流线型的数据,是对向量化的邻接矩阵求特征向量,然后进行聚类
降维
PCA:线性PCA和kernelPCA,找最佳降维向量,保留最多的信息
SVD(截断奇异值分解):通过矩阵分解进行降维,常用于潜在语义分析和推荐系统
K-means
模型原理
模型的两个假设
- 数据均质
- 类别里方差大致相同
数据之间的相似度与它们欧氏距离成反比,直观上看,K-means聚类是用圆圈住数据,模型损失函数为
收敛过程
K-means损失函数中有两类参数,一类是每个数据的类别,另一类是类别中心
,这两类参数相互依存,用EM算法求解,步骤如下:
- 首先随机生成k个聚类中心
- 根据已有的聚类中心,将数据分k类(E step)
- 根据分类结果,重新计算每个聚类的聚类中心(M step)
- 重复进行这两个步骤,直到聚类中心收敛(聚类中心不再移动)
K-means模型结果不稳定,通常会反复多次使用同一批数据训练模型,并从中选择效果较好的模型参数(其他机器学习模型参数不稳定也是类似的解决方法)
如何选择聚类个数
elbow method:当聚类个数小于真实的类别个数时,聚类结果的误差平方和会下降很快,但是当聚类个数超过真实值时,误差平方和下降速度明显减缓。
silhouette analysis:轮廓分析,其思路是计算聚类中心在多大程度上代表这个类别里所有数据
应用示例
异常检测:从聚类中心里找出明显区别于正常数据的异常值
图像压缩:用聚类中心代替原始像素点
混合高斯模型
原理
当数据有标签时,混合高斯模型就是二次判别分析(QDA),当数据无标签时,是混合高斯模型(GMM)
GMM的参数:
聚类结果:
混合高斯模型是生成式模型,它的参数估算方法是最大期望算法EM,参数估算原则是最大似然估计(M step)。
如果已知模型参数,聚类结果可以由最大后验概率得到(E step)。
模型实现
def trainModel(data, clusterNum):
"""
使用混合高斯对数据进行聚类
"""
model = GaussianMixture(n_components=clusterNum, covariance_type="full")
model.fit(data)
return model定义评估混合高斯模型的技术指标为:BIC(Bayesian information criterion)
其中,n是数据个数,L 是损失函数,k是聚类个数
BIC值最小的聚类个数最优
谱聚类
向量化:用向量有效表示连通图节点
- 定义邻接矩阵:利用高斯核函数定义节点之间边的权重
- 在邻接矩阵基础上定义degree matrix和Laplacian matrix,其中,Laplacian matrix是degree matrix减去邻接矩阵
- 用Laplacian matrix的特征向量表示图中各节点,则连接较为紧密的节点在转换后的欧式空间也离得很近(谱编码)
- 在谱编码的基础上,通常用K-means等方法聚类
Pipeline
一个pipeline由n个模型按顺序组成,其中前n-1个模型被称为transformer,主要作用是对数据进行特征提取,最后一个模型被称为estimator,主要作用是在特征基础上完成最后的模型预测。
从代码层面上来讲,前面n-1个transformer必须实现fit和transformer这两个接口,最后一个estimator则只需实现fit这个接口。
主成分分析(PCA)
模型原理
最佳降维向量的估计公式
其中,是协方差矩阵
主成分分析在降维过程中同时达到两个目的,一是尽可能保留数据间的差异,二是尽可能减少信息损失
模型实现
主成分分析要求数据的中心是原点,对于中心不是原点的数据,需要先进行数据平移(减去数据的中心点),再进行降维,类别数量k的选择同样依据elbow method
kernel PCA
若数据是非线性的,首先通过核函数将数据升到高维空间,然后再使用模型将高维空间里的数据降到所需的维度。
核函数+主成分分析
其中,K是高斯核函数,是拉格朗日对偶中的朗格朗日乘数
def trainKernelPCA(data):
"""
使用带有核函数的主成分分析对数据进行降维
"""
model = KernelPCA(n_components=2, kernel="rbf", gamma=25)
model.fit(data)
return model
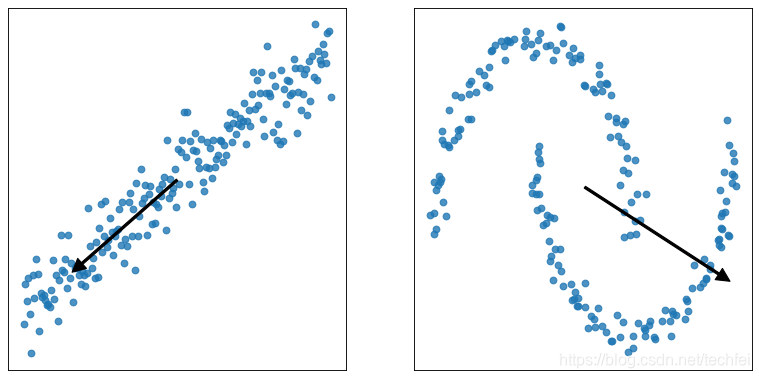
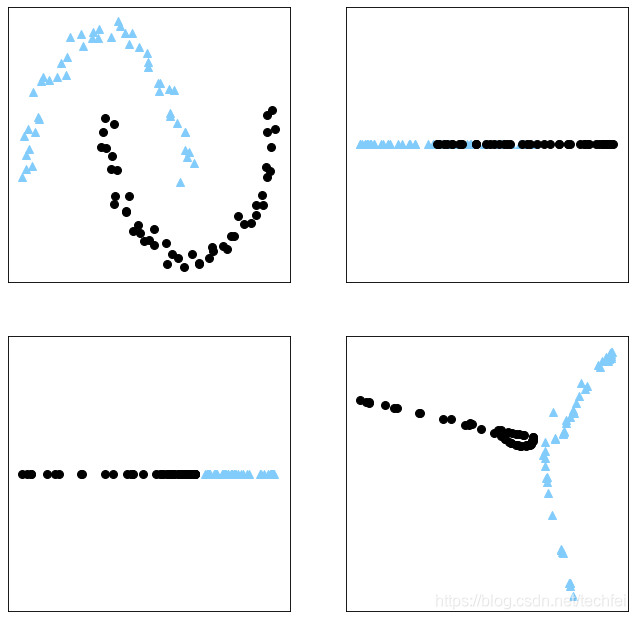
降维的作用
- 可视化数据
- 避免过拟合
- 降低实现难度
- 消除随机扰动
- 压缩图像
奇异值分解(SVD)
是一个矩阵分解定理
U是一个m阶正交矩阵()
是mxn的对角矩阵,对角元素为从大到小顺序排列的奇异值
V是n阶正交矩阵
截断奇异值分解
几乎没有场景需要完整的奇异值分解,我们关注的往往是最大的几个奇异值,选取中最大的k个奇异值得到新的k阶矩阵
就是截断奇异值分解,具体的k值通常用网格搜索方法找到最佳取值
应用场景
潜在语义分析(latent semantic analysis,LSA)
潜在语义分析根据训练文本,将文字和相应的文章转换为向量,并使得这些向量能最大程度的代表文字或文章的语义,即把同义词转换成夹角很小的向量(向量的方向差不多一致),把反义词转换成夹角很大的向量。
假设我们可以用k维向量同时表示文字和文章,向量的每个分量代表一个语义主题,比如表达正面情感的程度,表达意思的复杂程度等,而向量某个分量的数值表示它在这个语义主题上的权重。如果文字和文章在语义上接近,则它们在语义主题上的权重很相似(两个向量的内积很大,且这个内积接近于该文字在这个文章中的权重)。
通过截断奇异值分解,可以从表面的文字权重矩阵,倒推出文字向量和文章向量,步骤如下:
- 根据给定训练集,首先定义相应的文字权重矩阵A,最常见的定义方式为文字加权技术(TF-IDF)
- 选择合适的k值,对权重矩阵A使用截断奇异值分解,得到3个分解矩阵
的行代表文章,列代表语义主题,表示文章与各个语义主题的相关关系。但我们并不知道这k个语义主题具体是什么,体现模型结果不可解释性。
的行代表文字,列代表语义主题,表示文字与语义主题的相关关系。
是对角矩阵,它在对角线上的元素表示相应语义主题的重要程度
- 当建模重点是文章时,比如文本分类,即对文章矩阵的行向量进行聚类,常令
,
- 当建模重点是文字时,比如找同义词,即计算文字矩阵中列向量的夹角,常令
,
大型推荐系统
大型推荐系统通常处理非常庞大的数据集,需要在分布式计算框架下实现模型,这样就可以利用集群力量训练模型,对分布式机器学习(大数据机器学习),开源算法库Spark ML有实现的类 pyspark.ml.recommendation.ALS

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









