







 本文总结了YOLOv1和SSD两种物体检测框架。YOLOv1通过神经网络进行物体检测,但存在网格划分粗糙等问题。SSD通过多尺度convolutional feature layer改进了这一问题,提高了mAP。两者都是End-to-End的检测网络。
本文总结了YOLOv1和SSD两种物体检测框架。YOLOv1通过神经网络进行物体检测,但存在网格划分粗糙等问题。SSD通过多尺度convolutional feature layer改进了这一问题,提高了mAP。两者都是End-to-End的检测网络。
YOLOv1, SSD
今年四月份的时候,在一个研究院实习时学习了YOLOv1, SSD系列Object Detection框架,现在总结一下。关于R-CNN系列框架的总结在上一篇blog。
一. YOLOv1(You Only Look Once)
1.1 框架结构

- 首先将图片调整为 448×448 448 × 448 大小;
- 运行神经网络(其中包括选取region proposal以及target confidence和coordinate输出);
- nms(Non-max Suppression, 非极大值抑制), 用于后续bounding-box的选取(选取置信度高且不重复的方框).

- 系统将输入图片分成 S×S S × S 个grid, 物体中心所在的grid负责检测这个物体. 每一个grid预测B个Bounding-box(边框)和Confidence Scores(置信度). 置信度的定义为:
- 其中的IOU定义为:

每一个Bounding-box包括5个预测数值: 坐标x, y, w, h与置信度confidence.
每一个grid同时预测C种种类的概率 Pr(Classi|Object) P r ( C l a s s i | O b j e c t ) .
最后, 我们把一个grid是C种中的一种的概率和置信度相乘, 可以得到一个grid是特定种类物体的概率:
1.2 神经网络结构

1.3 缺点
YOLOv1 有两个主要明显的缺点:
- 输入图像分割成 S×S S × S , S取7有点粗糙, 导致后续边框回归不太准确;
- 每一个grid只预测一种物体, 不能预测一个grid有多种物体的情况.
针对这些, SSD和后续YOLOv2, YOLOv3有所改进.
二. SSD(Single Shot Multibox Detector)
2.1 框架结构
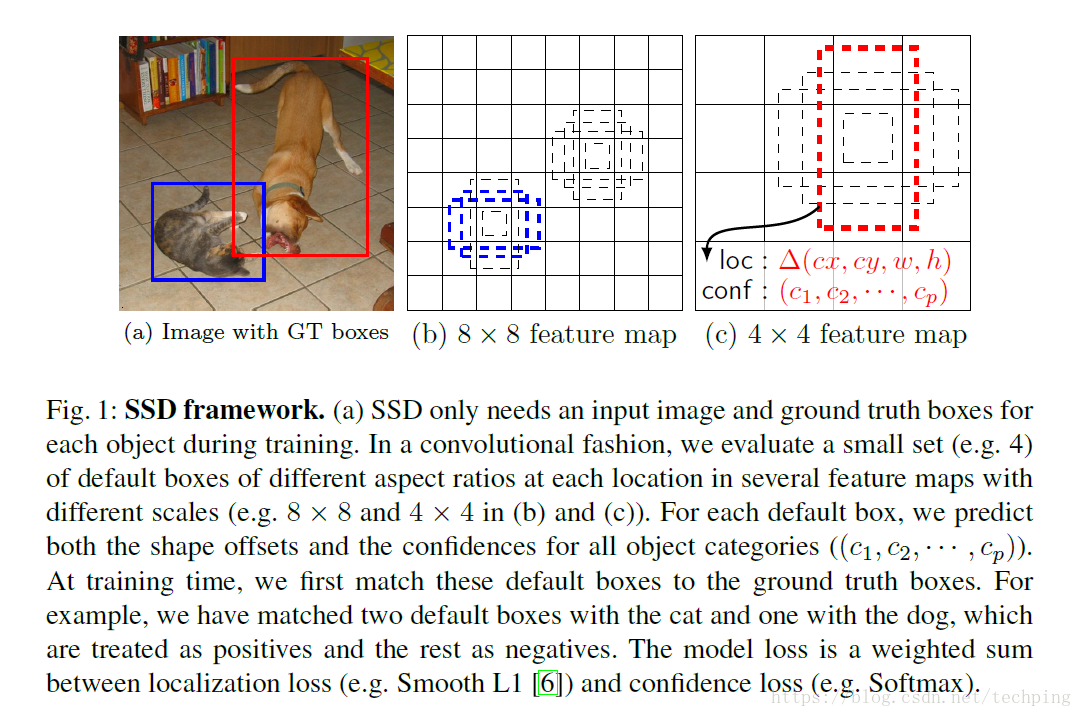
SSD只需要一张输入图片和ground truth框就可以开始训练. 可以把图片分成不同的scale(如 8×8 8 × 8 或者 4×4 4 × 4 ), 然后选取不同的aspect ratio(纵横比). 每一个box预测方块offset和每种类的置信度.
2.2 神经网络结构
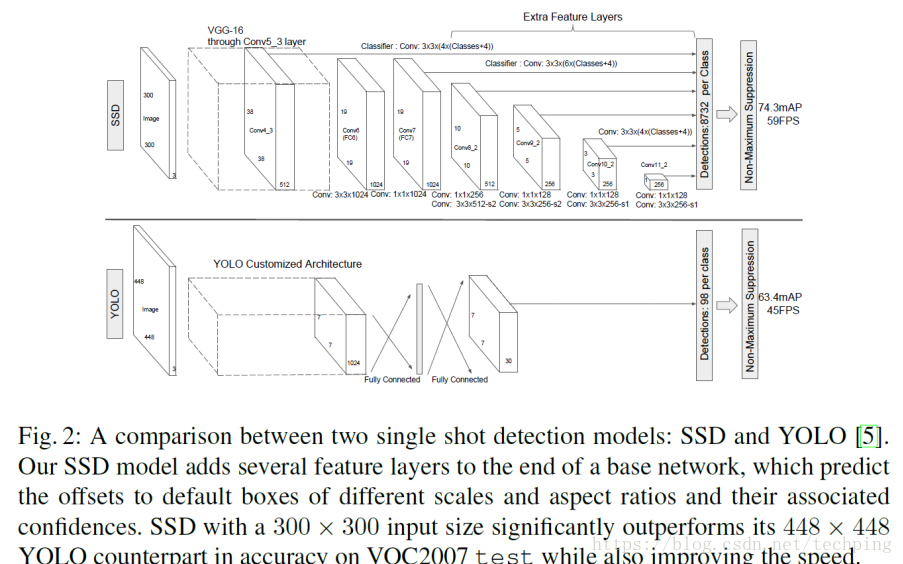
2.2.1 YOLOv1与SSD网络的对比
SSD相比于YOLOv1, 在基本网络后面增加了好几层多尺度convolutional feature layer, 用于定位面积更小的物体, mAP提高了.
三. 总结
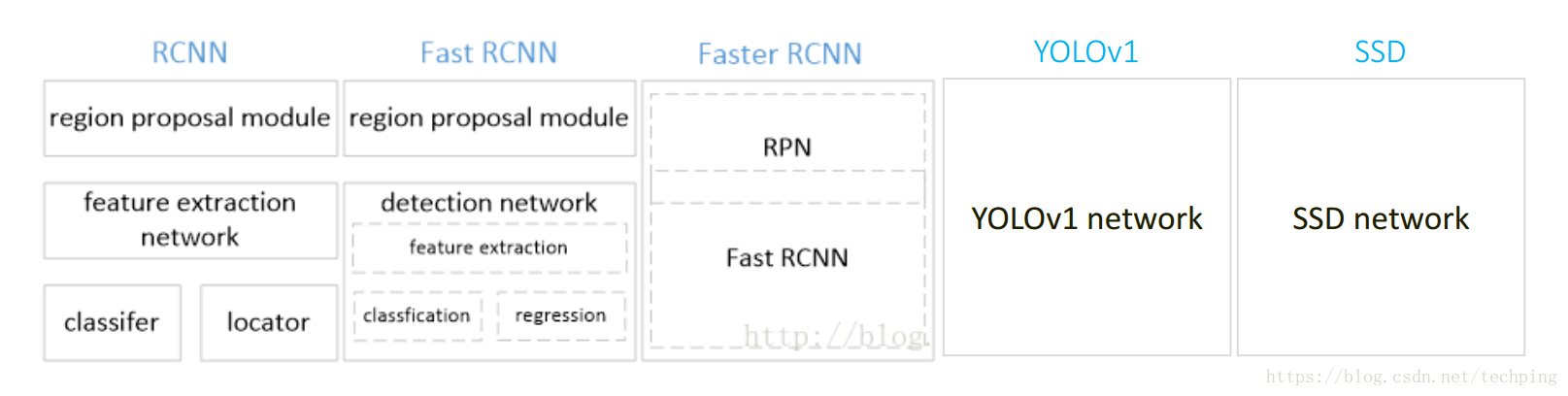
YOLOv1, SSD和Faster R-CNN一样都是End-to-End网络了.
References
[1] Joseph Redmon, Santosh Divvalay, Ross Girshick, Ali Farhadi. (2016). You Only Look Once: Unified, Real-Time Object Detection.
[2] Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, Alexander C. Berg. (2016). SSD: Single Shot MultiBox Detector.

















 2089
2089

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









