







聚类算法(实战)
实战部分将结合着 理论部分 进行,旨在帮助理解和强化实操(以下代码将基于 jupyter notebook 进行)。
一、不同聚类算法的执行效果和所用时间

二、准备工作(设置 jupyter notebook 中的字体大小样式等)
import numpy as np
import os
%matplotlib inline
import matplotlib
import matplotlib.pyplot as plt
plt.rcParams['axes.labelsize'] = 14
plt.rcParams['xtick.labelsize'] = 12
plt.rcParams['ytick.labelsize'] = 12
import warnings
warnings.filterwarnings('ignore')
np.random.seed(43)
三、Kmeans 算法
1、构建样本数据
# 绘制以一个区域,包含多个簇
from sklearn.datasets import make_blobs
# 构造 5 个点,并以这 5 个点发散出 5 个簇
blob_centers = np.array(
[[-1.5,1.8],
[-0.8,1.6],
[0.1,2.3],
[0.2,1.4],
[0.7,2.7]])
# 选择 0-1 的值,以指示每个中心点发散的大小
blob_std = np.array([0.1,0.2,0.3,0.2,0.1])
# 下面的代码将根据前面指定的参数,返回指定数量的数据点
X, y = make_blobs(n_samples = 2000, centers = blob_centers, cluster_std = blob_std, random_state = 7)
# 查看返回的 X
print("X 中的数据")
print(X)
print()
# 查看返回的 y(由于 Kmeans 是无监督的聚类,所以这里的 y 的取值其实是用不上的,最多当作一个参考)
print("y 中的数据")
print(y)
Out
[[ 0.80176059 2.7454702 ]
[-0.12379505 2.32927249]
[-1.30980719 1.51761694]
...
[ 0.19392915 1.25896231]
[-1.4898566 1.82525777]
[ 0.58576697 2.76863195]]
[4 2 0 ... 3 0 2]
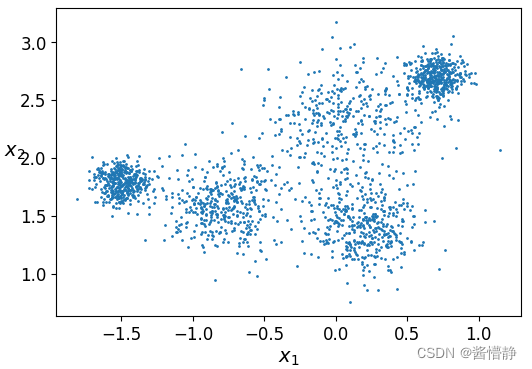
# 定义一个基于二维数据绘制散点图的函数
def plot_clusters(X,y = None) :
# 传递二维数据在两个维度上的值、数据点大小、颜色
plt.scatter(X[:,0], X[:,1], s=1, c=y)
# 设置坐标轴标签
plt.xlabel("$x_1$", fontsize=14)
plt.ylabel("$x_2$", fontsize=14, rotation=0)
# 画图展示
plt.figure(figsize=(6, 4))
plot_clusters(X)
plt.show()
2、基于样本数据构建分类器
# 导入相关包
from sklearn.cluster import KMeans
# 设置最初的簇数(可随机指定,但通过观察上图我们可以认为其可分为 5 簇,因此设置 k = 5 )
k = 5
# 实例化一个 KMeans 聚类工具
kmeans = KMeans(n_clusters = k, random_state = 43)
# fit_predict() 函数将对传入的数据样本进行训练并返回预测结果
y_pred = kmeans.fit_predict(X)
# 展示 (数组中的数字即代表对应数据被划归到的类别)
print(y_pred)
# 上面的结果与调用 kmeans.labels_ 属性的结果是一致的
print(kmeans.labels_)
Out
[3 0 4 ... 2 4 3]
[3 0 4 ... 2 4 3]
# 得到算法结束后,最终各簇的中心点(指定的 k 为多少,这就有多少个元素)
kmeans.cluster_centers_
Out
array([[ 0.00555392, 2.32870063],
[-0.76285141, 1.59224003],
[ 0.19589571, 1.41934638],
[ 0.67865059, 2.67700524],
[-1.48717074, 1.78811617]])
# 接下来就可以用这基于最初构建的数据而建立的分类器对任意数据进行预测
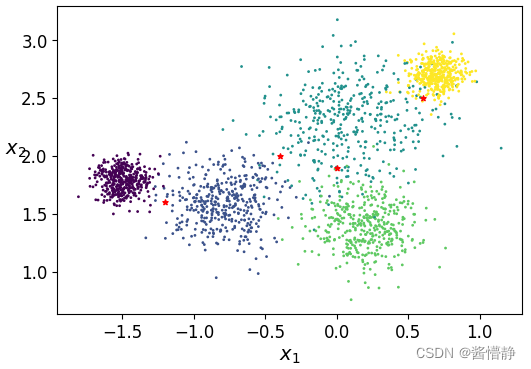
# 构建待预测样本数据
X_new = np.array([[-1.2,1.6],[-0.4,2],[0,1.9],[0.6,2.5]])
# 用图像的方式来直观感受这些点的位置
plt.figure(figsize=(6, 4))
plt.scatter(X[:,0], X[:,1], s=1, c=y)
plt.scatter(X_new[:,0], X_new[:,1], s=15, c='r', marker='*')
plt.xlabel("$x_1$", fontsize=14)
plt.ylabel("$x_2$", fontsize=14, rotation=0)
plt.show()
# 对指定的数据进行预测
kmeans.predict(X_new)
Out
array([4, 0, 0, 3])
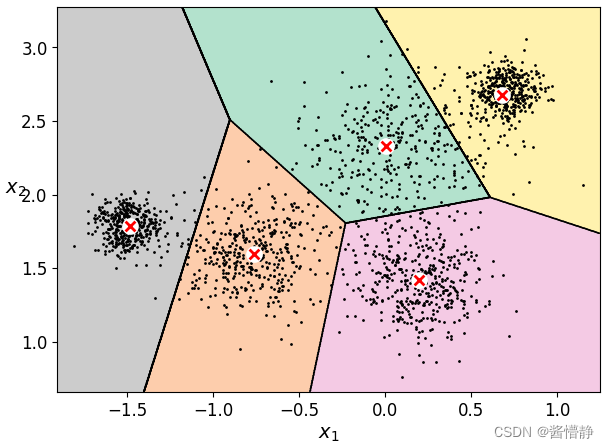
3、绘制决策边界
# 定义函数
# 展示数据
def plot_data(X):
plt.plot(X[:,0], X[:,1], 'k.', markersize = 2)
# 绘制中心点
def plot_centroids(centroids,weights=None, circle_color='w', cross_color='r'):
if weights is not None:
centroids = centroids[weights > weights.max() / 10]
plt.scatter(centroids[:,0],centroids[:,1],
marker = 'o', s = 100, linewidths = 2,
color = circle_color, zorder = 10, alpha = 1)
plt.scatter(centroids[:,0], centroids[:,1],
marker = 'x', s = 50, linewidths = 2,
color = cross_color, zorder = 10, alpha = 1)
# 绘制决策边界
def plot_decision_boundaries(clusterer, X, resolution = 1000, show_centroids=True,
show_xlabels=True, show_ylabels=True):
# 指定棋盘的边界
mins = X.min(axis = 0) - 0.1
maxs = X.max(axis = 0) + 0.1
# 组合边界值构成二维边界
xx, yy = np.meshgrid(np.linspace(mins[0], maxs[0], resolution),
np.linspace(mins[1], maxs[1], resolution))
Z = clusterer.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# 绘制等高线
plt.contourf(Z, extent = (mins[0], maxs[0], mins[1], maxs[1]), cmap="Pastel2")
plt.contour(Z, extent = (mins[0], maxs[0],mins[1], maxs[1]), linewidths=1, colors='k')
# 绘制基本数据点
plot_data(X)
# 是否展示类簇中心点
if show_centroids:
plot_centroids(clusterer.cluster_centers_)
# 是否展示横坐标标签
if show_xlabels:
plt.xlabel("$x_1$", fontsize = 14)
else:
plt.tick_params(labelbottom = 'off')
# 是否展示纵坐标标签
if show_ylabels:
plt.ylabel("$x_2$", fontsize = 14, rotation = 0)
else:
plt.tick_params(labelleft = 'off')
# 绘制图像
plt.figure(figsize = (7,5))
plot_decision_boundaries(kmeans, X)
plt.show()
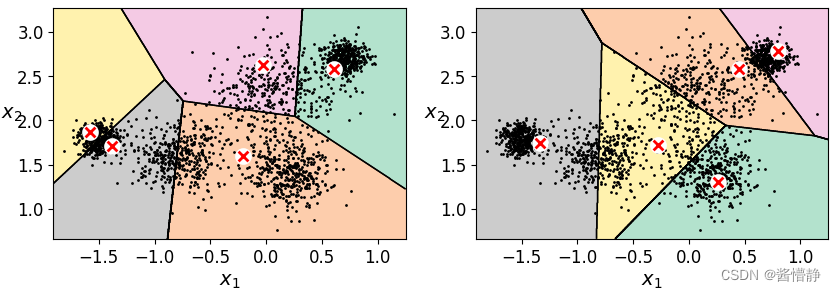
4、演示 k-means 算法的不稳定性
# 定义绘图函数
def plot_cluster_comparison(c1, c2, X):
c1.fit(X)
c2.fit(X)
plt.figure(figsize = (10,3))
plt.subplot(121)
plot_decision_boundaries(c1,X)
plt.subplot(122)
plot_decision_boundaries(c2,X)
# KMeans()函数的参数解释:
# 1、n_clusters 指定最终要分类出的个数
# 2、init 表示算法初始点的位置
# 3、n_init 表示算法会跑几次。在理论部分提到,k-means 算法在选取不同初始点时,最终得到的类簇中心
# 都是不同的。因此, KMeans()函数在设计时会对数据样本默认跑 n_init 次,并选择其中效果最好的
# 那一次作为最终的模型返回
# 4、max_iter 最大迭代次数(接下来的实验分别将这个值设置为 1、2、3 以查看 k-means 的执行流程)
# 5、random_state 随机数种子
c1 = KMeans(n_clusters = k, init = 'random', n_init = 1, max_iter = 1, random_state = 2)
c2 = KMeans(n_clusters = k, init = 'random', n_init = 1, max_iter = 1, random_state = 5)
plot_cluster_comparison(c1, c2, X)
5、演示 k-means 算法的执行流程
kmeans_iter1 = KMeans(n_clusters = k, init = 'random', n_init = 1, max_iter = 1, random_state = 2)
kmeans_iter2 = KMeans(n_clusters = k, init = 'random', n_init = 1, max_iter = 2, random_state = 2)
kmeans_iter3 = KMeans(n_clusters = k, init = 'random', n_init = 1, max_iter = 3, random_state = 2)
kmeans_iter4 = KMeans(n_clusters = k, init = 'random', n_init = 1, max_iter = 4, random_state = 2)
kmeans_iter1.fit(X)
kmeans_iter2.fit(X)
kmeans_iter3.fit(X)
kmeans_iter4.fit(X)

# 对比实验:画图对比不同迭代次数时 KMeans 聚类的效果
plt.figure(figsize = (10,12))
plt.subplot(421)
plot_data(X)
plot_centroids(kmeans_iter1.cluster_centers_, circle_color='r', cross_color='w')
plt.title('Update ClusterCenter')
plt.subplot(422)
plot_decision_boundaries(kmeans_iter1, X, show_xlabels = False, show_ylabels = False)
plt.title('Clustering')
plt.subplot(423)
plot_decision_boundaries(kmeans_iter1, X, show_centroids=False, show_xlabels = False, show_ylabels = False)
plot_centroids(kmeans_iter2.cluster_centers_)
plt.subplot(424)
plot_decision_boundaries(kmeans_iter2, X, show_xlabels = False, show_ylabels = False)
plt.subplot(425)
plot_decision_boundaries(kmeans_iter2, X, show_centroids=False, show_xlabels = False, show_ylabels = False)
plot_centroids(kmeans_iter3.cluster_centers_)
plt.subplot(426)
plot_decision_boundaries(kmeans_iter3, X, show_xlabels = False, show_ylabels = False)
plt.subplot(427)
plot_decision_boundaries(kmeans_iter3, X, show_centroids=False, show_xlabels = False, show_ylabels = False)
plot_centroids(kmeans_iter3.cluster_centers_)
plt.subplot(428)
plot_decision_boundaries(kmeans_iter4, X, show_xlabels = False, show_ylabels = False)
plt.show()
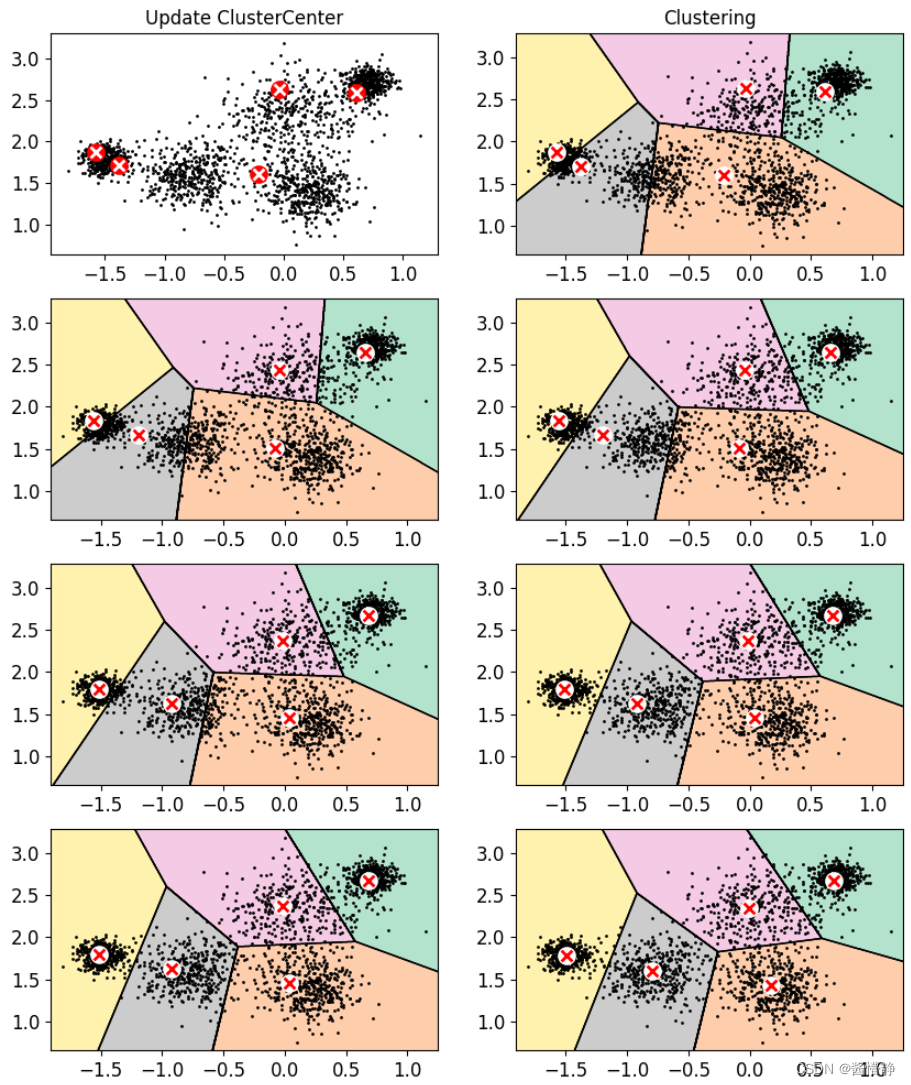
6、评估方法
inertia 指标:每个样本到其簇中心的欧氏距离之和
# 取 2 中基于数据 X 构建好的分类器 kmeans,查看其 inertia_ 值
kmeans.inertia_
Out
123.72148498489219
下面通过 transform() 函数查看数据集 X 中,各个数据点到各类簇中心的欧氏距离,并基于这些数据手动计算 inertia_ 值
# 查看数据集 X 中,各个数据点到各类簇中心的欧氏距离
X_dist = kmeans.transform(X)
print("各个数据点到各类簇中心的欧氏距离:")
print(X_dist)
print()
# 查看数据集 X 中,各个数据点的所属类簇
print("各个数据点的所属类簇:")
print(kmeans.labels_)
print()
# 通过上述两个参数,就能查看每个数据点到其所属类簇的簇中心距离
print("每个数据点到其所属类簇的簇中心距离:")
X_dist[np.arange(len(X_dist)),kmeans.labels_]
Out
各个数据点到各类簇中心的欧氏距离:
[[0.89868901 1.94369506 1.45797004 0.14086704 2.48107503]
[0.12935023 0.97550493 0.96445202 0.87454964 1.46684813]
[1.54532572 0.55202285 1.50890633 2.30177009 0.32346199]
...
[1.08619764 1.01316488 0.16039612 1.49859955 1.7624133 ]
[1.57788065 0.76343554 1.73393337 2.32978479 0.03723859]
[0.72813924 1.78960037 1.40448252 0.13047154 2.29313801]]
各个数据点的所属类簇:
[3 0 4 ... 2 4 3]
每个数据点到其所属类簇的簇中心距离:
array([0.14086704, 0.12935023, 0.32346199, ..., 0.16039612, 0.03723859,
0.13047154])
可进行对比查看:
transform(X)第一行数据 [0.89868901 1.94369506 1.45797004 0.14086704 2.48107503] 中的最小值正好为 0.14086704;
transform(X)第二行数据 [0.12935023 0.97550493 0.96445202 0.87454964 1.46684813] 中的最小值正好为 0.12935023;
transform(X)第三行数据 [1.54532572 0.55202285 1.50890633 2.30177009 0.32346199] 中的最小值正好为 0.32346199;
……
# 接下来计算各个数据点到其所属类簇中心的欧氏距离之和
np.sum(X_dist[np.arange(len(X_dist)), kmeans.labels_]**2)
Out
123.72148498489243
可以看出,计算出的值就等于前面 kmeans.inertia_ 的值
# 还有一种查看 inertia 值的方法,但是这方法返回的值是 inertia 的相反数
kmeans.score(X)
Out
-123.72148498489219
# 查看前面仅执行一次 k-means 聚类的 inertia_ 值
print("c1 的inertia值:",c1.inertia_)
print("c2 的inertia值:",c2.inertia_)
Out
c1 的inertia值: 288.16607006680323
c2 的inertia值: 225.32848318532416
7、如何找到最佳簇数
对于 k-means 算法而言,显然当 k 越大时,得到的 inertia_ 值会越小(考虑极限情况:所有样本都单独作为一个类别,则此时这个分类器的 inertia_ 值为0)。因此,最佳簇数的评判标准一定不能仅靠 inertia_ 值。inertia_ 最好的适用场景是评判 k 值一致时,不同算法的优劣。
下面介绍一些寻找最佳簇数的算法:
方法1:找拐点
注:这里的拐点不是数学中“二阶导异号(或不存在)的点”。 这里的拐点是指,某一点相较其前一单位点而言,数据的变化程度(斜率)降低了很多。若设该点位置为 𝑥 𝑖 𝑥_𝑖 xi,其前一单位点位置为 f ′ ( x i − 1 ) > > f ′ ( x i ) f^{'}(x_{i-1}) >> f^{'}(x_i) f′(xi−1)>>f′(xi) 。
# 构建 9 个进行 k-means 聚类后的分类器,每个分类器的分别将数据划分为 1-9 类
kmeans_per_k = [KMeans(n_clusters = k).fit(X) for k in range(1,10)]
# 将 9 个分类器的 inertia_ 值分别算出并放进一个列表中
inertias = [model.inertia_ for model in kmeans_per_k]
# 查看相关参数
print(len(inertias))
range(len(inertias)-1)
Out
9
range(0, 8)
# 下面算出这 9 个分类器的 inertia_ 差值
inertials_gap = []
for i in range(len(inertias)-1):
inertials_gap.append(inertias[i]-inertias[i+1])
# 将差值最大的那个数据所对应的 k 值(减数)输出
print("找拐点的方法认为,将原数据集划分为 %d 个簇是最合适的。" % (inertials_gap.index(max(inertials_gap))+1) )
# 画图直观观察 9 个分类器在 k 值不同时的 inertia_ 值(以及整体的变化率)
plt.figure(figsize = (6,3))
plt.plot(range(1,len(inertias)+1), inertias, 'bo-')
plt.show()
找拐点的方法认为,将原数据集划分为 1 个簇是最合适的。
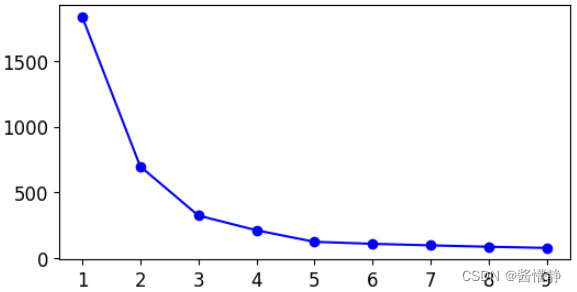
上图中,
f
′
(
1
)
>
>
f
′
(
2
)
f^{'}(1) >> f^{'}(2)
f′(1)>>f′(2) ,因此该算法认为,将数据样本划分为 2 簇是较为合理的。
但是从实际的角度来看,我们知道,该数据被划分为 5 个簇才是最合理的。因此,找拐点的思路还有待进一步地提升。
方法2:轮廓系数
- a i a_i ai:样本的簇内不相似度。计算样本 i 到同簇其他样本的平均距离 a i a_i ai , a i a_i ai 越小说明样本同属一类的可能性越高,故将 a i a_i ai 称为样本的簇内不相似度;
- b i b_i bi:样本的簇间不相似度。计算样本 i 到其他簇 C j C_j Cj 的所有样本的平均距离 b i j b_{ij} bij,称其为样本 i 与簇 C j C_j Cj 的不相似度。由于其他簇 C j C_j Cj 可能有多个,故定义样本的簇间不相似度为 $ b_i = min{b_{i1}, b_{i2}, … ,b_{ik}} $
基于以上定义,可得到轮廓系数定义为:
s
(
i
)
=
b
(
i
)
−
a
(
i
)
m
a
x
{
a
(
i
)
,
b
(
i
)
}
s(i) = \frac{b(i)-a(i)}{max\{a(i), b(i)\}}
s(i)=max{a(i),b(i)}b(i)−a(i)
于是可以得到 $ s(i) $ 的取值为:
s
(
i
)
=
{
1
−
a
(
i
)
b
(
i
)
a
(
i
)
<
b
(
i
)
0
a
(
i
)
=
b
(
i
)
a
(
i
)
b
(
i
)
−
1
a
(
i
)
>
b
(
i
)
s(i)=\begin{cases} 1-\frac{a(i)}{b(i)} & a(i)<b(i) \\ \quad 0 & a(i)=b(i) \\ \frac{a(i)}{b(i)}-1 & a(i)>b(i) \end{cases}
s(i)=⎩
⎨
⎧1−b(i)a(i)0b(i)a(i)−1a(i)<b(i)a(i)=b(i)a(i)>b(i)
- $ s(i) $ 接近 1(此时,$ b(i) $ 远大于 $ a(i) $),则说明样本 i 聚类合理
- $ s(i) $ 接近 -1(此时,$ a(i) $ 远大于 $ b(i) $),则说明样本 i 应该分类到另外的簇
- $ s(i) $ 接近 0(此时,$ a(i) $ 等于 $ b(i) $),则说明样本 i 在两个簇的边界上
注:轮廓系数的计算要求至少要将样本划分为 2 个簇
# 轮廓系数的计算有现成的库函数,可直接引入包调用
from sklearn.metrics import silhouette_score
# silhouette_score() 函数需要两个参数:
# 1、 样本集合
# 2、 分类的结果(可通过调用(已完成分类的)分类器的 labels_ 属性得到)
silhouette_score(X, kmeans.labels_)
Out
0.6021620690114153
接下来通过“轮廓系数”指标来查看将样本数据分为多少个簇才合理。
# 计算前面 8 个分类器的轮廓系数
# 为什么是 8 个?
# 因为轮廓系数的计算要求至少要将数据集划分为 2 个簇,因此这就要求从 kmeans_per_k 中的第 2 个分类器开始计算
silhouette_scores = [silhouette_score(X,model.labels_)for model in kmeans_per_k[1:]]
# 打印这 9 个分类器的轮廓系数
for i in range(0,len(silhouette_scores)):
print("将原数据集划分为 %d 个簇时的轮廓系数为 %.4f" % (i+2,silhouette_scores[i]))
print("轮廓系数的方法认为,将原数据集划分为 %d 个簇是最合适的" % (silhouette_scores.index(max(silhouette_scores))+2))
# 通过画图直观观察 9 个分类器在 k 值不同时的轮廓系数值
plt.figure(figsize = (6,3))
plt.plot(range(2,2+len(silhouette_scores)), silhouette_scores, 'bo-')
plt.show()
将原数据集划分为 2 个簇时的轮廓系数为 0.5457
将原数据集划分为 3 个簇时的轮廓系数为 0.5718
将原数据集划分为 4 个簇时的轮廓系数为 0.5839
将原数据集划分为 5 个簇时的轮廓系数为 0.6022
将原数据集划分为 6 个簇时的轮廓系数为 0.5583
将原数据集划分为 7 个簇时的轮廓系数为 0.5460
将原数据集划分为 8 个簇时的轮廓系数为 0.4855
将原数据集划分为 9 个簇时的轮廓系数为 0.4903
轮廓系数的方法认为,将原数据集划分为 5 个簇是最合适的
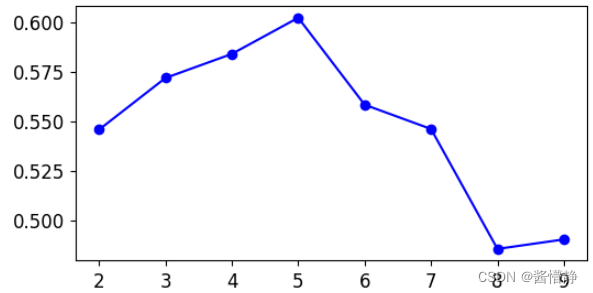
上图中,当 k=5 时,得到最大的轮廓系数,因此该算法认为,将数据样本划分为 5 簇是较为合理的。
而从实际来看,我们知道,该数据被正好被划分为 5 个簇。因此,轮廓系数的思路比较贴切聚类的评估。
注:无论是“找拐点”还是“轮廓系数”,这些评估方法都是基于已分好类的数据来进行的。其次,这些评估方法都只是对分类结果做一个大致的评估,而并不能将其作为一种绝对的评价。
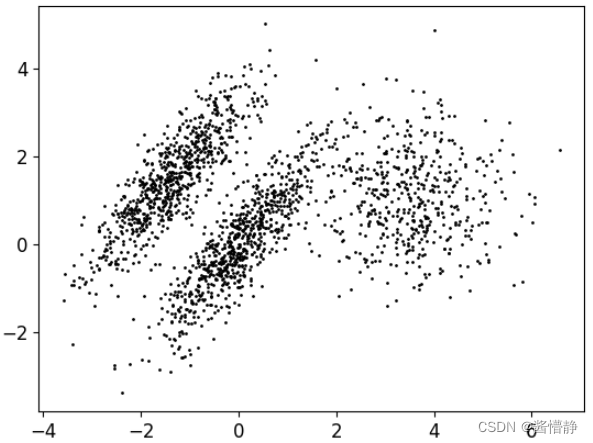
8、查看 k-means 算法对一些较为复杂图像的聚类效果
# 构建一份新的较为复杂的样本数据,大概分为 3 个簇
X1, y1 = make_blobs(n_samples = 1500, centers=((4,-4), (0,0)), random_state = 42)
X1 = X1.dot(np.array([[0.374, 0.95], [0.732, 0.598]]))
X2, y2 = make_blobs(n_samples = 500, centers=1, random_state = 42)
X2 = X2 + [6, -8]
X = np.r_[X1, X2]
y = np.r_[y1, y2]
# 绘制构建的数据
plot_data(X)
# 建立一个比较好的 k-means 分类器(一开始就指定各簇中心的大致位置)
kmeans_good = KMeans(n_clusters = 3, init = np.array([[-2,1.5], [0,0], [4,0.5]]), n_init = 1)
kmeans_good.fit(X)
# 建立一个完全随机的 k-means 分类器
kmeans_bad = KMeans(n_clusters = 3, random_state = 42)
kmeans_bad.fit(X)

接下来查看这两个分类器的分类效果:
# 绘图
plt.figure(figsize = (10,4))
plt.subplot(121)
plot_decision_boundaries(kmeans_good,X)
plt.title('Good - inertia = %.4f' % kmeans_good.inertia_)
plt.subplot(122)
plot_decision_boundaries(kmeans_bad, X)
plt.title('Bad - inertia = %.4f' % kmeans_bad.inertia_)
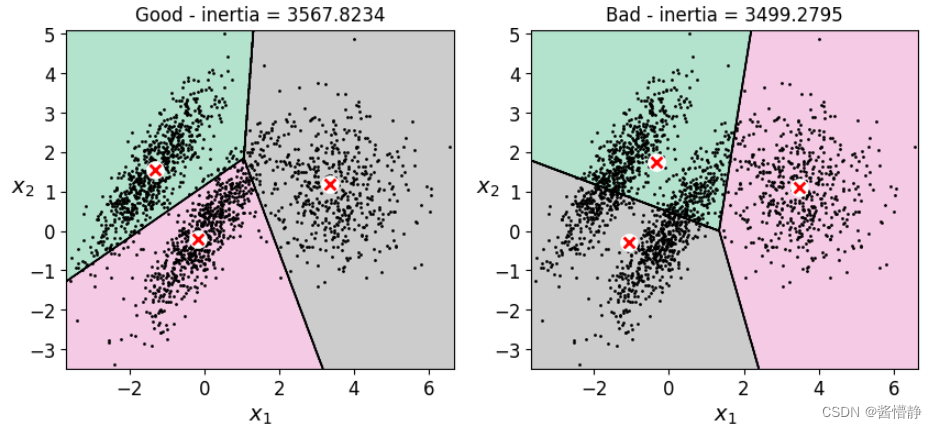
上图中:左图直接指定最好的类簇中心,然后仅进行 1 轮 k-means 聚类;右图完全随机地进行了 10 轮 k-means 聚类,并将其中最好的一次作为最终结果。
从上面两幅图可以看出,尽管第二幅图的 inertia 值更小,但它并不是最合适的分类。因此,对无监督问题而言(如在对聚类进行评估时),很多指标仅仅是起一个参考作用,而不能作为最终评价;与之相对的,有监督问题则因为其有准确的标签,所有能通过一些较为合理的评估方法来对模型进行合理评价。
9、实验:利用 k-means 算法做图像分割
# 调用图像加载函数
from matplotlib.image import imread
# 引入图像资源(采用相对路径引入的本地资源)
image = imread('./resources/imges/Silly.jpg')
# 查看图像资源是否被引入
print(image.shape)
# 取出图像的规格信息
width, height, chanel = image.shape
Out
(1024, 1024, 3)
能出现图像的规格信息就代表导入图像资源成功!
注:该图是一幅彩色的 RGB 图像,因此具有 3 个二维像素矩阵(即一个三维数据)
KMeans() 函数传入的数据集 data 要求其将各特征按列展开。这里我们可进行如下处理:将图像数据在 R、G、B 三个色道上的像素数据视为三个不同特征。这样一来,就只需要将每个二维像素矩阵拉平成为一个一维向量即可。即有:(width, height, chanel) → (width×height, chanel)。因此,下面对 image 数据进行 rehape 操作:
# 将原数据进行 rehape 操作,使其成为一个具有 3 个特征的二维向量
X = image.reshape(-1,chanel)
X.shape
Out
(1048576, 3)
# 开始执行聚类
kmeans = KMeans(n_clusters = 10, random_state = 42).fit(X)
# 查看最终的聚类中心
kmeans.cluster_centers_
Out
array([[183.05771371, 151.0562421 , 136.49840575],
[114.3421285 , 97.90454895, 94.67234282],
[127.50429431, 136.28164067, 153.72829249],
[184.62352515, 184.28648453, 185.66356383],
[ 48.26761893, 21.3597527 , 42.93087839],
[109.10680506, 116.79557457, 131.89202747],
[153.10505369, 122.17185905, 106.57774361],
[ 72.21035874, 52.25273609, 67.02076716],
[ 93.05353229, 76.79154041, 81.59151373],
[196.20500426, 211.17637314, 220.6266581 ]])
接下来可以做这样的处理(视为将某幅图像数据聚为 k 类):将该图中归属于指定类簇的所有像素点都设置为其所属类簇中心的像素值。
# 将图像中的所有像素点都设置为其所属类簇中心点的像素值(这一操作仅限在 numpy.array 结构中)
segmented_img = kmeans.cluster_centers_[kmeans.labels_]
# 查看处理后的数据
print(segmented_img)
# 将处理后的像素数据还原为原始图像的规格
segmented_img.reshape(width, height, chanel)
Out
[[127.50429431 136.28164067 153.72829249]
[127.50429431 136.28164067 153.72829249]
[127.50429431 136.28164067 153.72829249]
...
[153.10505369 122.17185905 106.57774361]
[153.10505369 122.17185905 106.57774361]
[153.10505369 122.17185905 106.57774361]]
array([[[127.50429431, 136.28164067, 153.72829249],
[127.50429431, 136.28164067, 153.72829249],
[127.50429431, 136.28164067, 153.72829249],
...,
[127.50429431, 136.28164067, 153.72829249],
[127.50429431, 136.28164067, 153.72829249],
[127.50429431, 136.28164067, 153.72829249]],
...,
[[ 72.21035874, 52.25273609, 67.02076716],
[ 72.21035874, 52.25273609, 67.02076716],
[ 72.21035874, 52.25273609, 67.02076716],
...,
[153.10505369, 122.17185905, 106.57774361],
[153.10505369, 122.17185905, 106.57774361],
[153.10505369, 122.17185905, 106.57774361]]])
# 基于以上操作,接下来我们将原始图像的类簇个数分别设置为 10,8,6,4,2 并查看聚类后的图像
segmented_imgs = []
n_colors = (10,8,6,4,2)
for n_color in n_colors:
# 进行指定分类个数的 k-means 聚类
kmeans = KMeans(n_clusters = n_color, random_state = 42).fit(X)
# 将数据集的所有像素点都重设为其所属类簇的簇中心像素值
segmented_img = kmeans.cluster_centers_[kmeans.labels_]
# 将数据对象还原为原始图像的规格以便展示
segmented_imgs.append(segmented_img.reshape(width, height, chanel))
# 绘图:将所有处理后的图像显示出来
# 为便于比较,先绘制处原始图像
plt.figure(figsize = (10,7))
plt.subplot(231)
plt.imshow(image)
plt.title('Original image')
# 接下来绘制经过聚类处理后的图像
for idx, n_clusters in enumerate(n_colors):
plt.subplot(232 + idx)
# imshow() 函数的输入:当表示的 RGB 值为 float 类型时,其取值范围为 [0,1];当表示的 RGB 值为 int 类型时,其取值范围为 [0,255]
plt.imshow(segmented_imgs[idx] / 255)
plt.title('{} colors'.format(n_clusters))
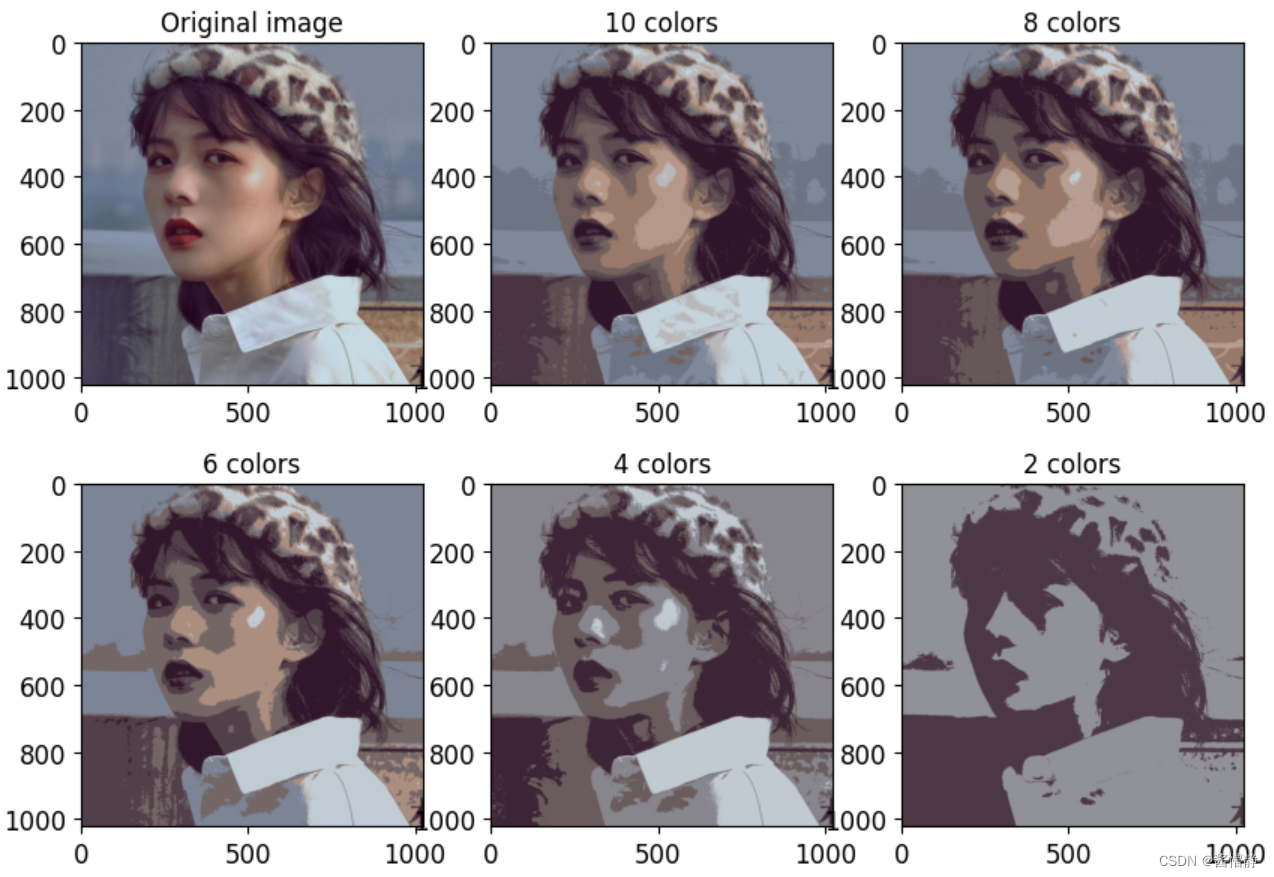
四、DBSCAN 算法
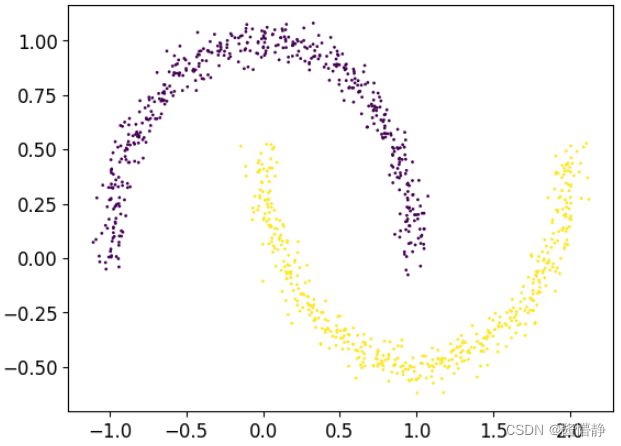
# DBSCAN 聚类算法能发现任意形状的簇,因此接下来我们用一些较为复杂的图来对其进行测试
# 引入相关包
from sklearn.datasets import make_moons
# 生成测试数据
X, y = make_moons(n_samples = 1000, noise = 0.05, random_state = 42)
# 画图直观地展示
plt.scatter(X[:,0], X[:,1], s=1, c=y)
# 导入 DBSCAN 算法所需要的库
from sklearn.cluster import DBSCAN
# DBSCAN 算法最终于的两个参数是半径 eps,和最小样本个数
dbscan = DBSCAN(eps = 0.05, min_samples = 5)
# 训练
dbscan.fit(X)

接下来进行属性展示
# labels_ :指示了样本数据被划分到哪一类中。其中,-1 值表示当前数据被视为离群点。
print("label_ 属性前 20 个数据:",dbscan.labels_[:20])
print()
# core_sample_indices_:核心对象的索引集合
print("core_sample_indices_ 属性前 20 个数据:",dbscan.core_sample_indices_[:20])
print()
# DBSCAN 的类簇个数是算法自动算出的,若需要查看最终将数据集分为了几个簇,可通过以下代码查看
print("DBSCAN 将原数据集划分为 %s 个簇" % np.unique(dbscan.labels_))
Out
label_ 属性前 20 个数据: [ 0 2 -1 -1 1 0 0 0 2 5 2 3 0 2 2 2 4 2 2 4]
core_sample_indices_ 属性前 20 个数据: [ 0 4 5 6 7 8 10 11 12 13 14 16 17 18 19 20 21 22 23 24]
DBSCAN 将原数据集划分为 [-1 0 1 2 3 4 5 6] 个簇
以上就是 DBSCAN 聚类算法的基本使用。
鉴于上面给出的结果(不太理想),下面尝试增大半径能取得怎样的效果
# 增大半径
dbscan2 = DBSCAN(eps = 0.1, min_samples = 5)
dbscan2.fit(X)

# 定义一个绘制 DBSCAN 算法中核心对象、决策边界的函数
def plot_dbscan(dbscan, X, size, show_xlabels = True,show_ylabels = True):
# 1、拿到核心对象数据(的真值数组)
# zeros_like() 函数是继承已知数组/向量a,照猫画虎创建一个子类数组/向量(因此他们的 shape 一致),并把里面的数据全部置为 0 或 1
# 下面的代码将创建一个 shape 和 dbscan.labels_ 完全一致的数组,并将其中所有元素的值都置为 False
core_mask = np.zeros_like(dbscan.labels_, dtype = bool)
# core_sample_indices_ 返回所有的核心对象的 index ,根据它可以将 core_mask 数组中的所有核心对象拿到
core_mask[dbscan.core_sample_indices_] = True
# 2、拿到离群点数据(的真值数组)
# dbscan.labels_ == -1 返回一个指示所有离群点索引的真值数组
anomalies_mask = dbscan.labels_ == -1
# 3、拿到其他数据(除核心对象、离群点以外的所有数据)(的真值数组)
non_core_mask = ~(core_mask | anomalies_mask)
# 取出核心对象、离群点、其他数据(注:dbscan.components_ 是核心样本的副本)
cores = dbscan.components_
anomalies = X[anomalies_mask]
non_cores = X[non_core_mask]
# 下面开始绘图
# 绘制核心对象背景
plt.scatter(cores[:,0], cores[:,1],c = dbscan.labels_[core_mask], marker = 'o', s = size, cmap="Paired")
# 绘制核心对象前景
plt.scatter(cores[:,0], cores[:,1],c = dbscan.labels_[core_mask], marker='*', s=10 )
# 绘制离群点
plt.scatter(anomalies[:,0], anomalies[:,1], c="r", marker="x", s=50)
# 绘制其他数据
plt.scatter(non_cores[:,0], non_cores[:,1], c=dbscan.labels_[non_core_mask],marker=".")
# 是否绘制 x 轴标签
if show_xlabels:
plt.xlabel("$x_1$", fontsize = 14)
else:
plt.tick_params(labelbottom = 'off')
# 是否绘制 y 轴标签
if show_ylabels:
plt.ylabel("$x_2$", fontsize = 14,rotation=0)
else:
plt.tick_params(labelleft = 'off')
# 绘制标题
plt.title("eps={:.2f}, min_samples={}".format(dbscan.eps,dbscan.min_samples), fontsize = 12)
# 设置总的图像大小
plt.figure(figsize=(12,4))
# 绘制第一个子图
plt.subplot(121)
plot_dbscan(dbscan, X, size = 30)
# 绘制第二个子图
plt.subplot(122)
plot_dbscan(dbscan2, X, size = 60,show_ylabels = False)
# 显示
plt.show()

# 将此数据用 k-means 进行聚类(直接给 k-means 赋予最佳 k 值),以进行对比
kmeans_oz = KMeans(n_clusters = 2, random_state = 42).fit(X)
plt.figure(figsize=(6,4))
plot_decision_boundaries(kmeans_oz, X, show_xlabels = False, show_ylabels = False)
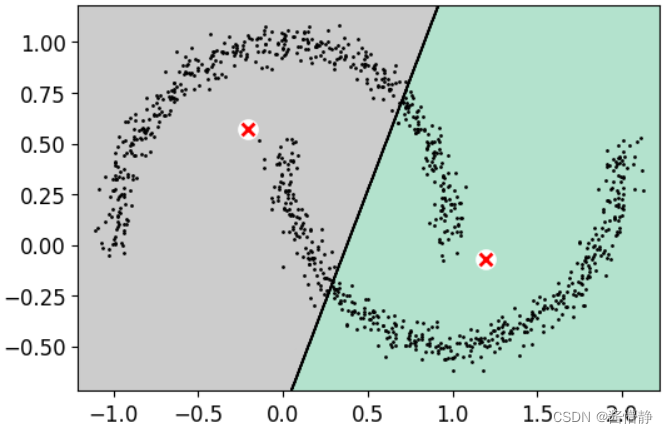
可以看出,在面对略微复杂的数据(如具有一定图案的数据样本)时,k-means 的效果并不理想,而 DBSCAN 则没有这方面的问题,它可以对任意形状的稠密数据集进行聚类,且不需要指定簇的个数。
五、半监督学习
在拥有的数据中,若有一部分数据存在标签,而其余部分没有标签。此时,如果将这些标签信息全部忽略(从而将问题视为一个完全的无监督问题)显得有点浪费,而若将这些数据使用上(作为有监督学习)却又太少。因此,这便产生了半监督学习:指仅有部分数据的标签(而不是全部),然后考虑如何用这些数据来训练出比较好的分类器。
1、方案一:仅用 (50/1347) 个有标签数据来训练逻辑回归模型并查看其效果
# 导入手写数字数据集
from sklearn.datasets import load_digits
# 获取训练数据和标签
X_digits, y_digits = load_digits(return_X_y = True)
# 导入用于数据划分的相关包
from sklearn. model_selection import train_test_split
# 将数据集划分为训练集和测试集
X_train,X_test,y_train,y_test = train_test_split(X_digits,y_digits,random_state = 42)
# 查看导入数据的规格
print("总数据规格为",X_digits.shape)
print("训练集规格为",X_train.shape)
Out
总数据规格为 (1797, 64)
训练集规格为 (1347, 64)
数据解读:说明该数据共有 1797 条,其中每个图像数据都是 8×8 的灰度图像(仅有一个颜色通道)。
# 下面用逻辑回归来测试在仅有 50 个数据标签进行训练时,分类器的效果
from sklearn. linear_model import LogisticRegression
n_labeled = 50
log_reg = LogisticRegression(random_state = 42)
log_reg.fit(X_train[:n_labeled], y_train[:n_labeled])
# 查看分类器的“得分”
log_reg.score(X_test, y_test)
Out
0.8266666666666667
这个结果非常不理想,说明在不完整的训练集中,若仅靠少量的有标签数据来训练分类器,这样的方式不可取。
1、方案二:利用 k-means 选出 (50/1347) 个代表性图像后再对模型进行训练
将每个类簇中,具有典型代表的意义的数据选出(称为代表性图像),并对其手动打上标签,这样一来,就能使得各类簇在聚类时能取得较好的效果。那什么数据才最具典型代表意义呢?当然是最靠近类簇中心的样本数据(注:在对数据进行 k-menas 聚类时,算法最终的类簇中心可理解为经过计算得出的质心,而这个质心并不一定会是某个数据样本。如两个二维样本数据 (0,0) 和 (2,2) 的质心是 (1,1) ,但 (1,1) 这个点并不实际存在)。
因此,我们接下来需要做三件事:
- 1、将样本数据分类为指定个数的簇(本实验中分为 50 个簇)
- 2、计算出所有数据到每个类簇中心的距离
- 3、将这 50 个簇中,距离簇中心最近的那 50 个样本数据都选出来(作为代表性图像)
# 将原始数据聚类为 50 个簇
k = 50
kmeans = KMeans(n_clusters=k, random_state = 42)
# 计算所有样本数据到这 50 个簇中心的欧氏距离
X_digits_dist = kmeans.fit_transform(X_train)
# 查看 X_digits_dist 的规格
X_digits_dist.shape
Out
(1347, 50)
数据解读:这是一个二维表格,X_digits_dist[i][j] 表示第 i 条数据与第 j 个代表性图像的欧氏距离。
有了这个二维表格,接下来就能在其中找出距离簇中心最近的那 50 个样本数据,之后就能根据这些样本进行手动打标签,最后再对这些数据进行学习
# 按列找出 50 个代表性图像:np.argmin() 函数的第一个参数是待寻最值的数据对象,若该数据对象是二维,则第二个参数需要指定是按列查找还是按行查找
representative_digits_idx = np.argmin(X_digits_dist, axis = 0)
# 查看 representative_digits_idx 的规格
print(representative_digits_idx.shape)
# 将这 50 个代表图像单独取出
X_representative_digits = X_train[representative_digits_idx]
# 绘制这些代表图像以便接下来进行手动标记
plt.figure(figsize=(8, 2))
for index,X_representative_digit in enumerate(X_representative_digits):
plt.subplot(k // 10, 10, index + 1)
plt.imshow(X_representative_digit.reshape(8, 8), cmap="binary", interpolation="bilinear")
plt.axis('off')
plt.show()
(50,)

# 基于上图,对这些代表性图像进行手动标记
y_representative_digits = np.array([9,8,1,1,2,6,0,7,5,4,
7,0,3,8,1,2,4,9,9,8,
2,6,0,9,7,5,3,7,9,7,
1,2,1,4,4,5,2,1,5,2,
3,5,8,6,7,4,5,7,8,6])
# 接下来做对比实验:还是只有 50 个有标签数据(但是这 50 个有标签数据是通过 k-means 聚类得到的代表性图像),还是用随机种子为 42 的逻辑回归模型
log_reg = LogisticRegression(random_state = 42)
log_reg.fit(X_representative_digits, y_representative_digits)
# 查看分类器的“得分”
log_reg.score(X_test, y_test)
Out
0.9155555555555556
可以看出,在用 k-means 聚类处理数据样本后(选出代表性数据)再进行逻辑回归的半监督学习取得的效果相较传统方法提升了不少。
3、方案三:利用代表性图像进行标签传播(将标签传播到同一集群中的其他实例),然后再进行学习
将代表性图像和距其较近的图像都置为同一标签,这样一来,就可以把有标签数据的总量增加,此时再利用这些数据来训练模型。
# 标签传播:将标签传播到同一集群中的所有其他实例
# 先将标签置空
y_train_propagated = np.empty(len(X_train),dtype=np.int32)
# 接下来遍历全部的类簇
for i in range (k):
# kmeans.labels_==i 会返回一个类似 array([False, True, False, ..., True, False, False]) 的 array,即类别 i 的真值数组
y_train_propagated[kmeans.labels_==i] = y_representative_digits[i]
# 这时,一个残缺的数据集全部都拥有了标签,此时一个半监督问题就变成了有监督问题
# 接下来利用新的数据集再进行逻辑回归
log_reg = LogisticRegression(random_state = 42)
log_reg.fit(X_train,y_train_propagated)
# 查看新分类器的“得分”
log_reg.score(X_test, y_test)
Out
0.92
# 将全部样本都打上标签并不意味着一定能提高分类的准确率(因为错误也会跟着一起传播)
# 下面尝试只选择每个代表性图像的前 50% 个最近样本并打上标签
percentile_closest = 50
# np.arange(len(X_train)) 返回 array([ 0, 1, 2, ..., 1344, 1345, 1346]):相当于创建了 0-1346 的索引
# kmeans.labels 返回 array([35, 15, 22, ..., 4, 47, 32]):指示了数据集中每个样本点所属类簇
# 因此 X_digits_dist[np.arange(len(X_train)), kmeans.labels_] 实际上是创建了“样本点距离其所属类的簇中心距离数组”
X_cluster_dist = X_digits_dist[np.arange(len(X_train)), kmeans.labels_]
# 接下来遍历全部类别
for i in range (k):
# kmeans.labels_==i 会返回一个类似 array([False, True, False, ..., True, False, False]) 的 array,即类别 i 的真值数组(充当索引的作用)
in_cluster = (kmeans.labels_== i)
# 由上述真值数组,选择出属于当前簇的所有样本(距离所属簇的簇中心距离)
cluster_dist = X_cluster_dist[in_cluster]
# nnmpy.percentile(ary, percentile, axis) 函数会返回一个值,这个值是基于 ary 数组的 percentile 百分比分位数
# ary 是待传入的数组对象(可以是无序的)
# percentile 需要计算的分位值(这个值是一个百分数,如 50 实际上是指找出 ary 数组中能划分出前 50% 的数据的分位值)
# 当数组是二维时,axis 参数用于指定按哪一个轴计算
# 得到 cluster_dist 数组中的前 20% 分位值(作为后面选出前 50% 数据的截断值)
cutoff_distance = np.percentile(cluster_dist, percentile_closest)
# 基于截断值 cutoff_distance 得到一个用于挑选数据的真值数组(但这个数组是包含了所有样本数据的)
above_cutoff = (X_cluster_dist > cutoff_distance)
# in_cluster & above_cutoff 实际上是选出:既要求属于当前类别 i;还要其与所属类的簇中心距离要小于指定的截断距离。
# 为满足这些要求的数据打上标记
X_cluster_dist[in_cluster & above_cutoff] = -1
# 接下来将上面的选出所有数据样本单独选出(此处选出的也是一个真值数组,充当索引的作用)
partially_propagated = (X_cluster_dist != -1)
# 对选出的真值数组(索引),最终再选出对应的训练数据、标签数据
X_train_partially_propagated = X_train[partially_propagated]
y_train_partially_propagated = y_train_propagated[partially_propagated]
# 最后,利用完善的新数据集(将每个代表性图像及其前 50% 个最近样本都打上了标签)再来训练模型
log_reg = LogisticRegression(random_state = 42)
log_reg.fit(X_train_partially_propagated, y_train_partially_propagated)
# 查看新分类器的“得分”
log_reg.score(X_test, y_test)
Out
0.9422222222222222
可以看出,有时候,(在半监督学习中)利用 k-means 对残缺的数据集进行聚类后手动打标签以完善数据信息时,完善全部数据并不一定有完善部分数据取得的效果好。















 2138
2138











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











