






语义SLAM |voxblox++ :Volumetric Semantic Mapping论文阅读

论文地址:http://arxiv.org/abs/1903.00268
开源代码: https://github.com/ethz-asl/voxblox-plusplus
论文作者及研究团队概述:
苏黎世联邦理工学院:由Roland Siegwart教授领导,Autonomous System Lab于1996年在洛桑联邦理工学院成立,它是机器人和智能系统研究所(IRIS)的一部分。
实验室旨在创造能够在复杂多样的环境中自主运行的机器人和智能系统。设计机电和控制系统,使机器人可以自主适应不同的情况,并应对不确定和动态的日常环境。机器人可以在地面,空中和水中运动,同时具备在复杂环境下自主导航的功能,研究出了包括用于感知,抽象,建图和路径规划的方法和工具。他们还在tango项目上与谷歌合作,负责视觉惯导的里程计,基于视觉的定位和深度重建算法。
内容目录:
1.系统总体架构
voxblox++:是一种基于RGB-D数据的在线体数据实例语义映射SLAM框架。通过对几何和语义线索的联合推理,一种基于帧的分割方法(mask-rcnn)能够推断出关于检测到和识别出的元素的类别信息,并能够发现场景中的新对象(其中利用了贝叶斯语义信息,这些新对象的实例是在之前没有定义的)。将部分分割信息增量融合到全局地图中,得到的目标级语义标注体地图将有利于导航和操纵规划任务。

对于每一个新的帧,传入的RGB图像用Mask R-CNN网络进行处理,以检测对象实例并预测每个经过语义注释的掩码。同时,通过几何分割将深度图像分解为一组三维分段。预测语义掩码用于推断相应该深度段的类别信息。
接下来,使用数据关联策略将当前帧中预测的片段与其在全局映射中的对应实例相匹配,以检索每个映射一致的标签。最后,将来自当前帧的密集几何体和分割信息集成到全局地图体中。
2.part 1:语义实例感知分段细化
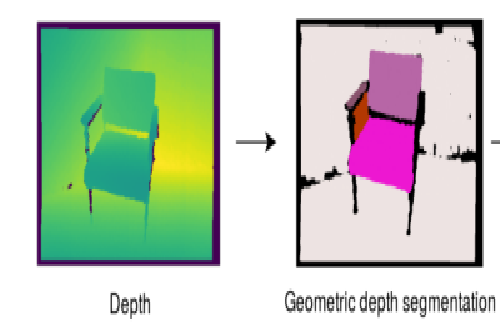
在 假 设 现 实 世 界 中 的 物 体 呈 现 整 体 凸 面 几 何 图 形 的 基 础 上 , 按 照 论 文 I n c r e m e n t a l O b j e c t D a t a b a s e : B u i l d i n g 3 D M o d e l s f r o m M u l t i p l e P a r t i a l O b s e r v a t i o n s 中 提 到 的 方 法 , 在 每 一 帧 t 生 成 当 前 深 度 图 像 中 闭 合 2 D 片 段 r i ∈ R t , 以 及 相 应 预 测 3 D 片 段 的 集 合 s i ∈ S t . 在假设现实世界中的物体呈现整体凸面几何图形的基础上,按照论文Incremental \\Object Database:Building 3D Models from Multiple Partial Observations\\ 中提到的方法,在每一帧t生成当前深度图像中闭合2D片段r_i\in R_t,\\以及相应预测3D片段的集合s_i\in S_t. 在假设现实世界中的物体呈现整体凸面几何图形的基础上,按照论文IncrementalObjectDatabase:Building3DModelsfromMultiplePartialObservations中提到的方法,在每一帧t生成当前深度图像中闭合2D片段ri∈Rt,以及相应预测3D片段的集合si∈St.
以下是上述该参考论文提出的分割方法

在第一步中,我们对深度图像进行矫正,以获得更连续的有效深度值区域。在第二步中,我们检测显示出强烈深度不连续性的边缘。接下来,我们基于一个局部像素邻域计算曲面法线,并使用它们来确定每个像素的局部凸性。在最后一步,我们结合凸性图和深度不连续性来形成闭合区域并提取轮廓,并用标签填充。
经
过
M
a
s
k
−
r
c
n
n
处
理
后
对
于
每
一
个
R
G
B
图
像
,
输
出
都
是
一
个
物
体
实
例
的
集
合
,
在
这
里
面
,
第
k
个
被
检
测
到
的
实
例
使
用
一
个
M
k
和
一
个
物
体
类
别
c
k
所
描
述
。
经过Mask -rcnn处理后对于每一个RGB图像,输出都是一个物体实例的集合,在这里\\面,第k个被检测到的实例使用一个M_k和一个物体类别c_k所描述。
经过Mask−rcnn处理后对于每一个RGB图像,输出都是一个物体实例的集合,在这里面,第k个被检测到的实例使用一个Mk和一个物体类别ck所描述。
重 合 片 段 p ( i , k ) 这 样 定 义 : 在 重 合 的 地 方 的 像 素 数 量 除 以 总 的 像 素 数 量 。 即 : p ( i , k ) = ( r i ∩ M k ) 1 M k 对 于 每 一 个 区 域 r i ∈ R t , 最 高 重 叠 率 p i 和 对 应 掩 膜 M k 的 索 引 标 签 k i 是 由 下 面 的 公 式 来 定 义 的 : p i = m a x p ( i , k ) k i = a r g m a x k p ( i , k ) 如 果 p i ≥ r p ( 阈 值 ) 对 应 的 s i 会 被 分 配 实 例 标 签 o i = k i 和 物 体 类 别 c i = c k 如 果 片 段 s i 没 有 掩 膜 的 话 , 那 么 我 们 对 于 这 个 片 段 对 应 的 实 例 标 签 和 物 体 类 别 赋 值 o i = c i = 0 , 表 示 经 过 m a s k r c n n 处 理 后 我 们 无 法 预 测 它 的 信 息 。 重合片段p(i,k) 这样定义:在 重合的地方的像素数量除以 总的像素数量。\\即:p(i,k)= (r_i \cap M_k) \frac 1M_k 对于每一个区域 r_i \in R_t ,最高重叠率p_i 和对应掩膜M_k 的索\\引标签k_i 是由下面的公式来定义的:\\ p_i=max p(i,k)\\ k_i=argmax_k p(i,k)\\ 如果 p_i \ge r_p(阈值) 对应的s_i会被分配实例标签o_i=k_i 和物体类别 c_i=c_k \\如果片段s_i 没有掩膜的话,那么我们对于这个片段对应的实例标签和物体类别赋值\\o_i=c_i=0 ,表示经过mask rcnn处理后我们无法预测它的信息。 重合片段p(i,k)这样定义:在重合的地方的像素数量除以总的像素数量。即:p(i,k)=(ri∩Mk)M1k对于每一个区域ri∈Rt,最高重叠率pi和对应掩膜Mk的索引标签ki是由下面的公式来定义的:pi=maxp(i,k)ki=argmaxkp(i,k)如果pi≥rp(阈值)对应的si会被分配实例标签oi=ki和物体类别ci=ck如果片段si没有掩膜的话,那么我们对于这个片段对应的实例标签和物体类别赋值oi=ci=0,表示经过maskrcnn处理后我们无法预测它的信息。
part2:数据关联策略
不 同 帧 间 存 储 的 数 据 是 没 有 关 联 属 于 同 一 个 物 体 的 片 段 在 不 同 帧 被 赋 予 了 不 同 的 类 别 信 息 , 从 而 发 生 错 误 ( 因 为 这 些 掩 膜 仅 仅 在 它 们 被 预 测 的 帧 S t 的 范 围 内 有 效 , 同 一 个 部 分 的 物 体 可 能 在 不 同 帧 中 被 赋 予 不 同 的 语 义 类 别 信 息 ) 。 为 了 解 决 这 个 问 题 , 我 们 定 义 了 在 持 续 的 几 何 标 签 的 集 合 L 和 持 续 的 物 体 实 例 标 签 的 集 合 O 。 不同帧间存储的数据是没有关联属于同一个物体的片段在不同帧被赋予了不同的类别信息,\\从而发生错误(因为这些掩膜仅仅在它们被预测的帧S_t的范围内有效,同一个部分的物体可\\能在不同帧中被赋予不同的语义类别信息)。为了解决这个问题,我们定义了在持续的几何\\标签的集合 L和持续的物体实例标签的集合 O。 不同帧间存储的数据是没有关联属于同一个物体的片段在不同帧被赋予了不同的类别信息,从而发生错误(因为这些掩膜仅仅在它们被预测的帧St的范围内有效,同一个部分的物体可能在不同帧中被赋予不同的语义类别信息)。为了解决这个问题,我们定义了在持续的几何标签的集合L和持续的物体实例标签的集合O。
来 自 集 合 S ( 该 集 合 是 每 帧 R G B 图 像 被 分 割 形 成 的 ) 的 每 一 个 片 段 s j 会 通 过 L ( s j ) = l j 被 一 个 特 殊 的 几 何 标 签 来 定 义 , 所 以 在 处 理 每 一 帧 t 的 时 候 , 我 们 通 过 找 到 L t ( s i ) = l j ( 当 s i 与 s v ∈ S ( s v 是 第 t 帧 对 应 的 R G B 图 像 被 分 割 的 片 段 ) ) 重 合 部 分 超 过 设 定 阈 值 便 将 第 t 帧 深 度 图 分 割 产 生 的 3 D 片 段 赋 予 r i ∈ r t 与 l j 产 生 关 联 ) , 将 该 帧 t 中 的 片 段 与 全 局 片 段 S 相 关 联 。 同 理 , 在 一 个 帧 的 范 围 内 , 我 们 去 寻 找 一 个 映 射 I t ( o i ) = o m , o m ∈ O ( o m 取 与 该 片 段 相 关 联 的 l j 映 射 最 多 的 那 个 标 签 值 ) , 来 把 在 当 前 帧 的 物 体 实 例 o i 和 储 存 在 地 图 中 的 持 续 实 例 标 签 O 匹 配 起 来 。 此 数 据 关 联 步 骤 的 结 果 是 一 组 3 D 从 当 前 帧 深 度 图 像 中 分 割 s i ∈ S t , 每 个 片 段 都 被 指 定 一 个 持 久 段 标 签 l j = L ( s i ) 。 此 外 , 相 应 的 对 象 实 例 标 签 与 持 久 标 签 o m = I t ( o i ) 匹 配 。 ( 如 果 在 之 前 没 有 相 应 l j , 和 o m 与 s i ∈ s t 相 对 应 则 我 们 用 新 的 标 签 l n e w 和 o n e w 来 对 他 们 赋 值 ) 来自集合S(该集合是每帧RGB图像被分割形成的)的每一个片段 s_j会通过L(s_j)=l_j 被一\\个特殊的几何标签来定义,所以在处理每一帧t的时候,我们通过找到L_t(s_i)=l_j(当s_i与\\s_v \in S(s_v是第t帧对应的RGB图像被分割的片段))重合部分超过设定阈值 便将第t帧深\\度图分割产生的3D片段赋予r_i \in r_t 与 l_j产生关联) ,将该帧t中的片段与全局片段S相关联。\\ 同理,在一个帧的范围内,我们去寻找一个映射I_t(o_i)=o_m,o_m \in O(o_m 取与该片段相关\\联的l_j映射最多的那个标签值) ,来把在当前帧的物体实例o_i 和储存在地图中的持续实例标签\\O匹配起来。此数据关联步骤的结果是一组3D 从当前帧深度图像中分割si∈St,每个片段\\都被指定一个 持久段标签l_j=L(s_i)。此外,相应的 对象实例标签与持久标签\\om=I_t(o_i)匹配。(如果在之前没有相应l_j,和o_m与s_i \in s_t 相对应则我们用新的标签\\lnew和o new来对他们赋值) 来自集合S(该集合是每帧RGB图像被分割形成的)的每一个片段sj会通过L(sj)=lj被一个特殊的几何标签来定义,所以在处理每一帧t的时候,我们通过找到Lt(si)=lj(当si与sv∈S(sv是第t帧对应的RGB图像被分割的片段))重合部分超过设定阈值便将第t帧深度图分割产生的3D片段赋予ri∈rt与lj产生关联),将该帧t中的片段与全局片段S相关联。同理,在一个帧的范围内,我们去寻找一个映射It(oi)=om,om∈O(om取与该片段相关联的lj映射最多的那个标签值),来把在当前帧的物体实例oi和储存在地图中的持续实例标签O匹配起来。此数据关联步骤的结果是一组3D从当前帧深度图像中分割si∈St,每个片段都被指定一个持久段标签lj=L(si)。此外,相应的对象实例标签与持久标签om=It(oi)匹配。(如果在之前没有相应lj,和om与si∈st相对应则我们用新的标签lnew和onew来对他们赋值)
关于片段最后赋予实例的实例标签和语义类别**
在
最
后
不
断
向
地
图
整
合
信
息
的
时
候
,
我
们
定
义
了
以
下
两
个
值
分
别
表
示
l
j
=
L
(
s
j
)
与
o
m
,
c
i
之
间
的
关
联
,
在
每
整
合
一
个
片
段
之
后
对
其
相
关
的
之
间
的
映
射
计
数
值
,
便
会
每
次
加
一
来
更
新
值
。
Φ
(
l
j
,
o
m
)
=
Φ
(
l
j
,
o
m
)
+
1
Ψ
(
l
j
,
c
j
)
=
Ψ
(
l
j
,
c
j
)
+
1
最
终
对
于
该
片
段
对
应
的
掩
码
标
签
和
物
体
类
别
我
们
这
样
取
值
:
o
m
=
a
r
g
m
a
x
o
Φ
(
l
j
,
o
m
)
c
j
=
a
r
g
m
a
x
Ψ
(
l
j
,
c
j
)
在最后不断向地图整合信息的时候,我们定义了以下两个值分别表示l_j=L(s_j) 与o_m,c_i 之\\间的关联,在每整合一个片段 之后对其相关的 之间的映射计数值 ,便会每次加一来更新值\\。 \Phi(l_j,o_m)=\Phi(l_j,o_m)+1 \\ \Psi(l_j,c_j)=\Psi(l_j,c_j)+1\\ 最终对于该片段对应的掩码标签和物体类别 我们这样取值:\\ o_m=argmax_o \Phi(l_j,o_m)\\ c_j=argmax \Psi(l_j,c_j)
在最后不断向地图整合信息的时候,我们定义了以下两个值分别表示lj=L(sj)与om,ci之间的关联,在每整合一个片段之后对其相关的之间的映射计数值,便会每次加一来更新值。Φ(lj,om)=Φ(lj,om)+1Ψ(lj,cj)=Ψ(lj,cj)+1最终对于该片段对应的掩码标签和物体类别我们这样取值:om=argmaxoΦ(lj,om)cj=argmaxΨ(lj,cj)
part3:地图融合
在当前帧被发现的3D片段是包含了丰富的类和实例信息,为了最终完成SLAM建图的任务,这些片段会被整合到一个全局体积式的地图里面。在使用已知的相机位姿把片段都投影到全局TSDF体积地图里面后。
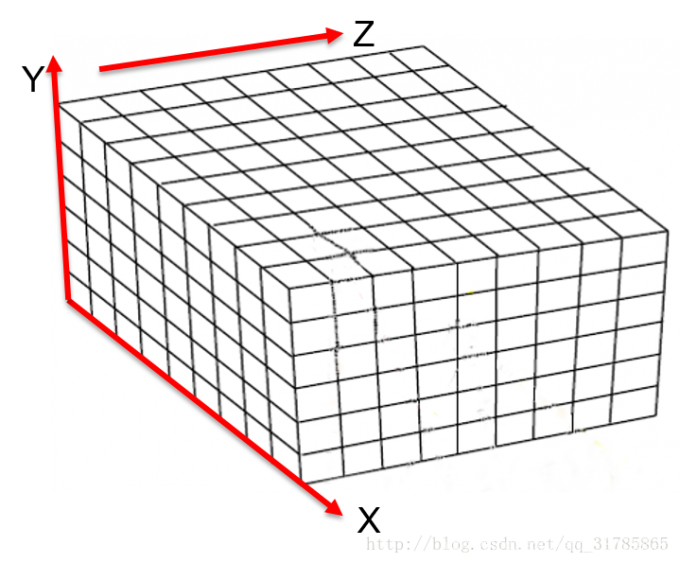
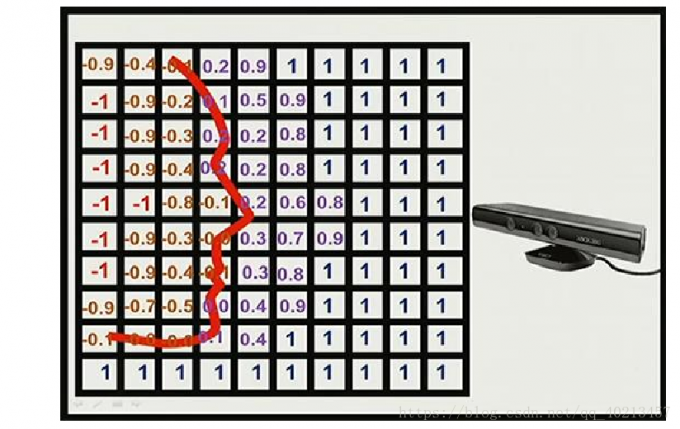
TSDF值的计算
通过将点在世界坐标系的坐标V1(x,y,z)转换到相机坐标系在最后转换到像素坐标系下的深度与坐标系的高度(u,v)作比较。即V1.z与D(u,v)比较(如果D(u,v)>z, 说明此体素距离相机更近,在重建表面的外部;如果D(u,)<z,说明此体素距离相机更远)

这是一个全局数据立方体的二维示意图,网格中的值代表对应体素到重建表面的距离,其中正负交界的位置即是模型表面所在的位置。因此,在全局数据立方体中就隐含了重建出的模型表面信息,只需要遍历所有体素就可以提取出模型点云数据。
3.实验结果分析

通过对评估序列的比较,我们发现最终大多数平均分数(评估的是最终分割结果与一开始掩码的重合程度)会比相对比Pham做的工作要好(这是唯一一个提供了三维分割方面精度具体数据的工作,所以只能提供这一组比对数据)。

由于应用了贝叶斯语义从而能发现没有定义过的语义实例第四行为使用无监督语义分割而发现的系统所没有定义过的语义种类并将它们的轮廓体现出来。
4.论文总结
文章的主要贡献:
1)提出了一个组合的几何-语义分割框架,这个框架能识别检测之前没有见过的,新的物体
2)提出了一个新的数据关联策略:这个策略可以在多帧之间追踪和匹配 预测的实体
3)在公开数据集上进行了本框架的评估较往常方法性能优秀
4.论文总结
文章的主要贡献:
1)提出了一个组合的几何-语义分割框架,这个框架能识别检测之前没有见过的,新的物体
2)提出了一个新的数据关联策略:这个策略可以在多帧之间追踪和匹配 预测的实体
3)在公开数据集上进行了本框架的评估较往常方法性能优秀















 1418
1418











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









