







一、何为乘积量化
乘积量化(Product Quantization)简称 PQ。是和VLAD算法由法国INRIA实验室一同提出来的,为的是加快图像的检索速度,所以它是一种检索算法。现有的检索算法存在一些弊端,如 kd树不适合维度高的数据,哈希(LSH)适用中小数据集,而乘积量化这类方法,内存占用更小、数据动态增删更方便。
乘积量化的核心思想是分段(划分子空间)和聚类,然后进行最近邻搜索。
二、算法流程
PQ系列的算法流程分三个阶段:训练、量化、查询
2.1 训练
- 分段:假设样本向量维度D=64,PQ算法会先将原始的D维向量分成M段,假设M=8,那么一个原始向量就被分成8段,每段的子维度subD=8。
- 聚类:对训练集的每段分别进行 k-means 聚类,聚成K个类,这里假设K=256。那么每段都会有 256个聚类中心向量,这个中心向量的维度=D/M=8,每个聚类中心用一个 clusterID表示,如0-255。
2.2 量化
上面的训练结束后,对于训练集中的每个样本,已经可以量化成一个 M 维的短向量,其中每个元素是该子段所属的类中心编号,如量化向量=[18, 130, 241, 3, 90, 45, 32, 9]。对于新的待添加的样本向量:
- 进行相同方式的切分,划分成 M 段
- 每段在各自的子空间里寻找最近的类中心,然后用最近的类中心编号进行编码。最终得到一个 M 维的短向量。
最终一个原始向量就可以用每段子向量所属的 M个clusterID来表示,这M个clusterID也叫做码本,其所能表示的样本空间量级为 K M K^M KM,也就是 M 个码本的笛卡尔积,这也是乘积量化中”乘积“的由来。
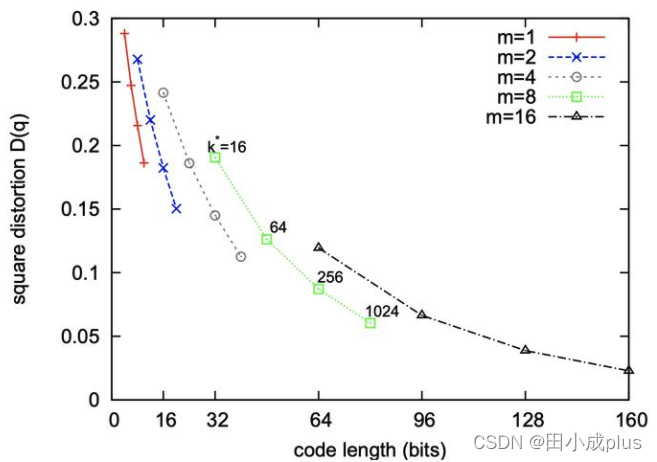
可见这种量化方式可以表示非常大的空间,但具体 K 值和M值如何选择?还要根据具体情况进行平衡。论文中作者也做了相关测试,目前业界更多的采用 M=8,K=256的做法,权衡占用空间以及误差。
这样做相当于对原始向量进行压缩,大大节省了内存空间。假设原来一维向量是256维,每个float是4个字节,则一个向量消耗256*4=1024 个字节空间。现在压缩为8维,每个数字范围是 0-255(假设总共聚成256个类),则每个数字只占一个字节,压缩后的8维向量只需要8个字节空间,和原来相比节省了 1024/8=128 倍的内存空间。
2.3 查询
在查询阶段,PQ同样是在计算查询样本与dataset中各个样本的距离,只不过这种距离的计算转化为间接近似的方法来获得。PQ乘积量化方法在计算距离的时候,有两种距离计算方式,一种是对称距离SDC,另外一种是非对称距离ADC。非对称距离的损失小(也就是更接近真实距离),实际中也经常采用这种距离计算方式。
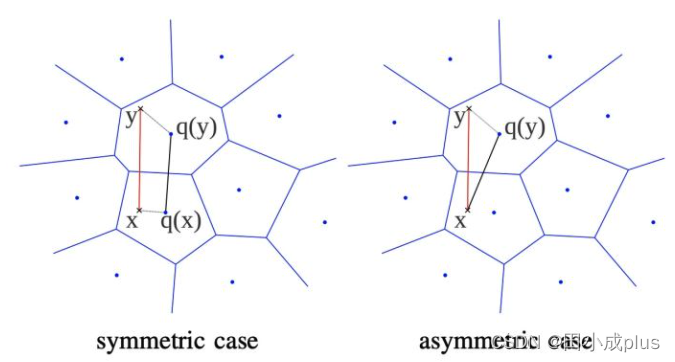
- 对称距离计算:上图中左图是对称距离计算,直接使用两个原始向量 x 和 y 的编码后的短向量 q(x) 和 q(y)进行距离计算。而q(x),q(y)之间的距离可以离线计算,因此可以把q(x),q(y)之间的距离制作成查找表,只要按照压缩向量的索引值进行对应的查找就可以了,所以速度非常快,但同时也放大了误差;
- 非对称距离计算:上图中右图是非对称距离计算,它增加了一些计算开销,但是误差更小更准确,所以通常采用这种方式。具体步骤为:
- 首先将查询向量按相同方式分成 M 段
- 每段分别和该段的 K 个类中心向量计算距离,则一共可以得到 M*K 个距离,简称距离表,其中每行表示 M 个距离
- 遍历样本库中的候选向量,根据距离表,计算与查询向量的距离和
- 根据3算出的距离和,返回 topk 个距离最接近的样本
- 二次搜索,可以根据4返回的 topk 近似样本,再按照 query 和 topk对应的原始向量进行暴力匹配,提高 topk里排序的准确率
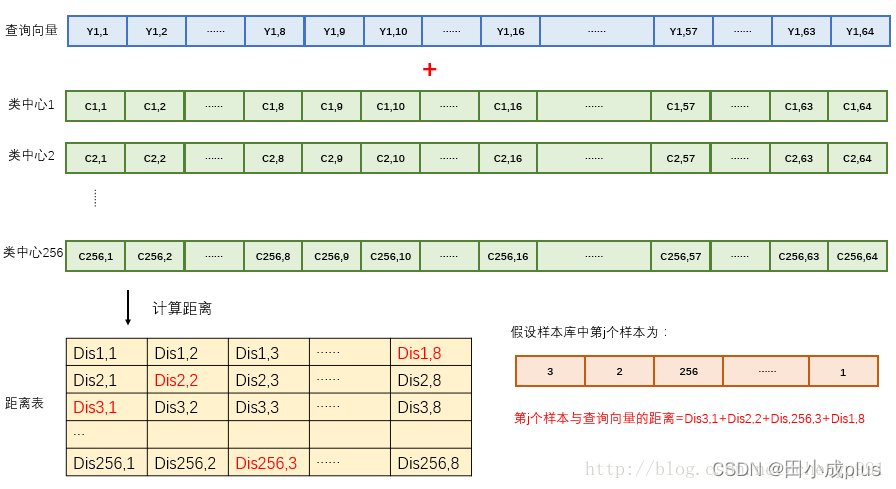
假设候选库中的某个样本编码后的短向量为 doc_i=[3, 2, 256, 3, 90, 45, 32, 1],那么根据距离表,doci和查询向量的距离= Dist3_1 + Dist2_2 + Dist256_3 + … + Dist1_8
2.4 IVFPQ
在PQ的场景下,我们要进行检索找出Top K临近的样本的话,时间复杂度是 O(N * M)
,因为我们还是要计算出当前样本空间下,查询向量X与所有样本Y的距离。PQ只是单纯的压缩算法,检索场景直接用PQ还是复杂度有点高。这时候就需要用到 IVFPQ 了。
上面的查询中是对所有的候选样本进行距离计算,其实是做了非常多的无用功,没有必要遍历所有候选样本,完全可以先筛选出一个有潜力的范围,然后在这个范围里进行遍历计算距离。那么如何选出这个有潜力的范围呢?最常用的做法就是聚类+倒排。聚类过程可以离线进行,通过聚类后构建当前类别下所有样本的倒排,在查询的时候只需要和 K 个聚类中心进行比较即可,先找到最 match的聚类中心,然后再和这个类别下的所有样本进行距离匹配,大大缩小了暴力匹配范围。所谓 IVF 就是 Inverted File System,即倒排系统。
思想上是这样,不过 IVFPQ 在实现上有点不同:
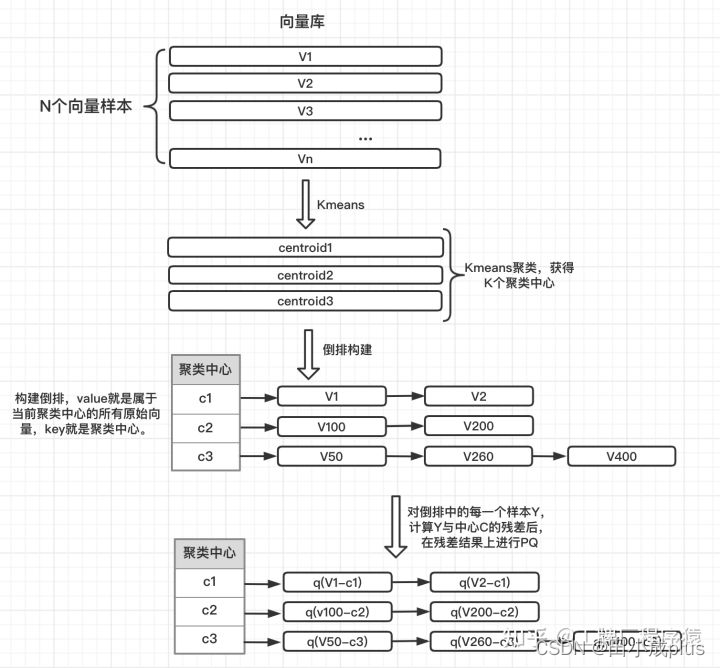
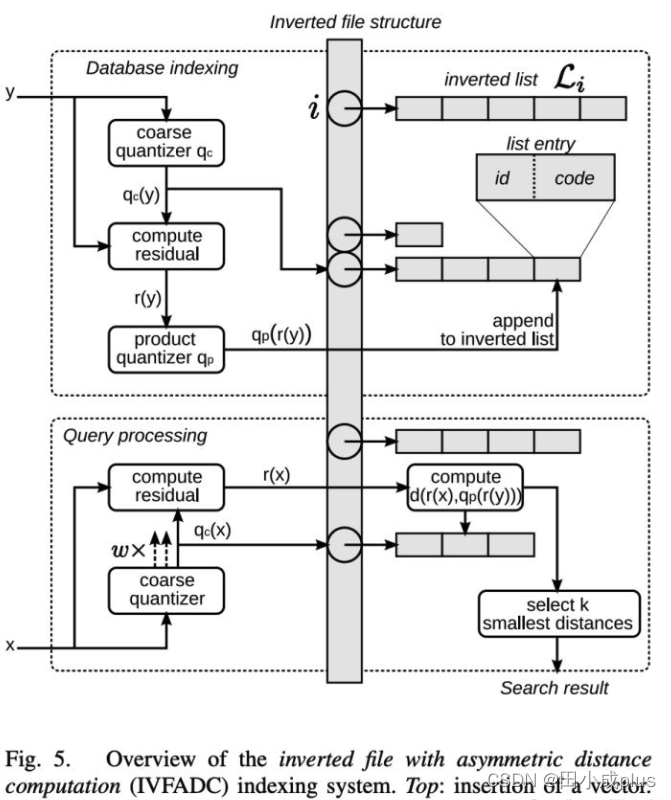
首先们使用kmeans将所有的候选样本,先进行一次粗粒度的聚类,比如聚成K个类,每个类别有一个自己的聚类中心。这时候我们知道每个样本原始向量 y 及它所属的聚类中心向量 C(y),但是量化的时候,不是在原始向量 y 上做量化,而是在 y和 c(y)的残差向量y-c(y)上做量化
为什么用残差向量做量化?仔细想一下,样本y和其所属的聚类中心向量 c(y)肯定是距离比较小的,那么其残差一定是很小的。如原始样本向量y=[8, 9, 10],其聚类中心是[7.5, 8.5, 9.5],则残差就是 y-cy=[0.5, 0.5, 0.5]。不难发现残差向量相比原始向量y,其每个值的值域要小很多,值域小的话量化误差就会更小,因为kmeans聚类时引起的误差会更小。
综上 IVFPQ 的构建过程如下图所示:
在查询的时候,流程就变成了:
- 首先对 query向量 x 计算出其所属的距离中心,比如属于 c1 这个类
- 计算 query 向量 x 和 c1 类中心向量的残差向量
x - c1,然后进行PQ量化,压缩为 M 维的短向量 x’ - 计算 c1 这个类下量化后的向量和 x’ 进行距离计算,计算方式见上面的 ADC非对称距离法。这时候待检索的向量个数就是 c1这个类下的样本数,而不是全量样本空间
- 精确查找:3之后会找出 topk条相似,然后在这 topK里再进行暴力计算,进行精确查找,这时候可以用原始向量进行匹配,找出topM条作为最终结果。具体的 K和M怎么定,要根据业务情况和线上实验结果来定。
下图描述了整个倒排构建和基于 ADC 的检索过程:
参考资料
- https://blog.csdn.net/chenyq991/article/details/78934989
- https://zhuanlan.zhihu.com/p/215870859
- https://zhuanlan.zhihu.com/p/378725270

















 1208
1208

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









