







引言:
上一小节对矩形特征和积分图的相关概念作了简要介绍,然后我们要利用积分图对矩形特征的计算进行人脸检测算法中弱分类器的选取。
Haar分类器是一个监督学习分类器。要进行物体的检测,首先要对图像进行直方图均衡化并归一化到同样大小,然后标记里面是否包含要检测的物体,故人脸检测也不例外。
Haar分类器使用AdaBoost算法,但是把它组织为筛选式的级联分类器,每个节点是多个树构成的分类器,且每个节点的正确识别率很高。在任一级计算中,一旦获得“不在类别中”的结论,则计算终止。只有通过分类器中所有级别,才会认为物体被检测到。这样的优点是当目标出现频率较低的时候(即人脸在图像中所占比例小时),筛选式的级联分类器可以显著地降低计算量,因为大部分被检测的区域可以很早被筛选掉,迅速判断该区域没有要求被检测的物体。
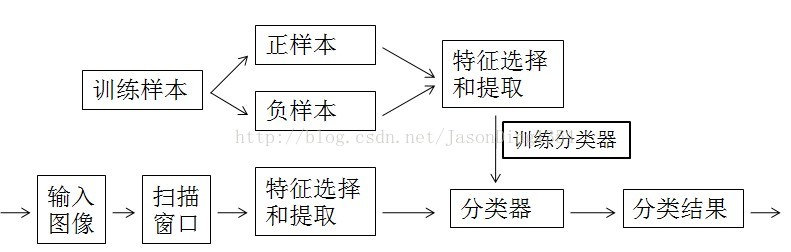
图1 物体检测流程框架图
1、Boosting提升算法简述
Boosting算法涉及到两个重要的概念就是弱学习和强学习,所谓的弱学习,就是指一个学习算法对一组概念的识别率只比随机识别好一点,所谓强学习,就是指一个学习算法对一组概率的识别率很高。Kearns和Valiant提出了弱学习和强学习等价的问题 ,并证明了只要有足够的数据,弱学习算法就能通过集成的方式生成任意高精度的强学习方法。
针对Boosting的若干缺陷,Freund和Schapire于1996年前后提出了一个实际可用的自适应Boosting算法AdaBoost,AdaBoost目前已发展出了大概四种形式的算法,Discrete AdaBoost、Real AdaBoost、LogitBoost、gentle AdaBoost。
2、AdaBoost算法流程
Boosting是一个迭代的过程,用来自适应地改变训练样本的分布,使得基分类器聚焦在那些很难分的样本上。
(1)给定训练样本(x1,y1),...,(xi,yi),...,(xn,yn),其中xi表示第i个样本,yi=0表示为负样本,yi=1表示为正样本。n为训练样本总数。
(2)初始化训练样本的权重
(3)第一次迭代,首先训练一弱分类器,计算弱分类器的错误率;选取合适阈值,使得误差最小;更新样本权重
(4)经过T次循环后,得到T个弱分类器,按照评价每一个弱分类器的重要性的权重进行加权叠加,最终得到强分类器

图1 AdaBoost算法示意图

图2 人脸检测的AdaBoost算法流程图
3、从弱分类器到强分类器的级联
(1)弱分类器
任何单一特征或组合特征都可以有自己的弱分类器,为了使得弱分类器所有正负样本的误差最小化,就需要从所有的弱分类器中找出最佳的弱分类器,为此需要设定一个最佳阈值θ和偏置p,然后将多个弱分类器组合成一个性能优越的强分类器。弱分类器公式为:

图3 弱分类器公式
其中,hj(x)为弱分类器的判断值,值为1则说明图片为人脸,否则非人脸;x表示输入的图片子窗口,fj(x)为x图像上第j个特征的值;θj为分类器阈值;pj为不等号方向,若分类结果大于阈值,则为−1,否则为+1,以保证不等号<方向不变。
注意:
输入x为一幅数字图像;特征fj与弱分类器hj(x)是一一对应的关系;一个弱分类器的训练就是找到最优阈值θj的过程,一轮分类器的训练过程就是找到分类效果最好的弱分类器的过程。
(2)弱分类器的训练
训练一个弱分类器,就是在当前权重分布的情况下,确定f(x)的最优阈值,使得这个弱分类器对所有训练样本的分类误差最低。选取一个最佳弱分类器就是选择那个对所有训练样本的分类误差在所有弱分类器中最低的那个弱分类器。
具体训练过程:
a、对于每个特征 f,计算所有训练样本的特征值,并将特征值排序
b、扫描一遍排好序的特征值,对排好序的表中的每个元素,计算下面四个值:
全部人脸样本的权重的和T1;
全部非人脸样本的权重的和T0;
在此元素之前的人脸样本的权重的和S1;
在此元素之前的非人脸样本的权重的和S0;
c、选取当前元素特征值fi(x),和它前面的一个特征值fi-1(x)之间的值作为阈值,该阈值的分类误差为:
e = min( (S1+(T0-S0) ,(S0+(T1-S1))
通过把这个排序的表从头到尾扫描一遍可以为弱分类器选择使分类误差最小的阈值(即最优阈值)。
(3)建立强分类器
经过T次迭代后,获得T个最佳弱分类器h1(x),...,ht(x),用下面方式组合成一个强分类器:

其中,α = ㏑((1-εt)/εt)。
当这个强分类器对一幅待检测图像时,相当于让构成该强分类器的所有弱分类器投票,再对投票结果按照弱分类器的错误率加权求和,将投票加权求和的结果与平均投票结果比较得出最终的结果。
(4)强分类器的级联
为了提高人脸检测的速度和精度,最终的分类器还需要通过几个强分类器级联得到。在一个级联分类系统中,对于每一个输入图片,顺序通过每个强分类器,前
面的强分类器相对简单,其包含的弱分类器也相对较少,后面的强分类器逐级复杂,只有通过前面的强分类检测后的图片才能送入后面的强分类器检测,比较靠前的几
级分类器可以过滤掉大部分的不合格图片,只有通过了所有强分类器检测的图片区域才是有效人脸区域。

图4 强分类器的级联
转载请标明出处,原文地址:http://blog.csdn.net/jasonding1354/article/details/37558287
参考资料:
《学习OpenCV(中文版)》,清华大学出版社
浅析人脸检测之Haar分类器方法,http://www.cnblogs.com/ello/archive/2012/04/28/2475419.html
基于Adaboost的人脸检测方法及眼睛定位算法研究 龙伶敏
《机器学习实战》,人民邮电出版社
《统计学习方法》,清华大学出版社















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









