







摘要
联邦学习(FL)的性能依赖于有效利用分布式数据集中的知识。传统的FL方法采用“聚合-适应”框架,客户端基于服务器从前一轮训练中聚合的全局模型更新本地模型。这一过程可能导致客户端漂移,尤其是在跨客户端数据异构性显著的情况下,影响模型性能和FL算法的收敛性。为了解决这些挑战,我们提出了FedAF,一种新颖的无聚合FL算法。在该框架中,客户端通过利用对等知识协作学习浓缩数据,服务器随后使用从客户端接收的浓缩数据和软标签训练全局模型。FedAF从根本上避免了客户端漂移问题,在显著的数据异构性中提高了浓缩数据的质量,并提升了全局模型的性能。在多个流行基准数据集上的广泛数值研究表明,FedAF在处理标签偏斜和特征偏斜的数据异构性方面超越了各种最先进的FL算法,实现了更高的全局模型准确性和更快的收敛速度。
1. 引言
联邦学习(FL)算法通常遵循迭代的“聚合-适应”范式,客户端使用其本地私有数据来优化由中央服务器提供的全局模型。这些本地更新的模型随后返回并由服务器聚合,服务器根据预定规则通过平均本地模型来更新全局模型[26]。鉴于FL中客户端数据的去中心化性质,客户端数据分布的显著差异是常见的。这种情况导致客户端之间的非独立同分布(non-IID)数据,通常称为数据异构性。这种异构性对FL算法的收敛性提出了重大挑战,主要是由于客户端之间本地学习路径的显著漂移[15, 30]。这种现象被称为客户端漂移,可能显著降低全局模型的准确性[20, 39, 40]。
大多数现有解决数据异构性挑战的努力要么集中在通过额外的正则化项修改本地模型训练[1, 10, 15, 19, 22],要么集中在利用替代的服务器端聚合或模型更新方案[5, 13, 24, 29, 35, 41]。然而,这些方法仍然受限于传统的“聚合-适应”框架,如图1a所示。在跨客户端非IID数据分布强烈的情况下,全局模型在本地数据上的微调容易受到灾难性遗忘的影响。这意味着客户端在更新模型时往往会忘记在全局模型中学到的知识,并偏离全局学习目标的稳定点[9, 14]。
最近关于数据浓缩的研究[4, 31, 32, 36, 37, 38]提出了一种无聚合范式,有可能克服上述FL中的局限性,同时保持隐私。如图1b所示,在这个新框架中,每个客户端首先为每个类别学习一组紧凑的合成数据(即浓缩数据),然后将学习到的浓缩数据与服务器共享。服务器随后利用接收到的浓缩数据直接更新全局模型。然而,在当前关于无聚合方法的研究中[25, 34],出现了两个关键的开放挑战:首先,显著的跨客户端数据异构性可能会影响本地浓缩数据的质量,从而对全局模型训练产生不利影响。其次,仅依赖浓缩数据进行全局模型训练可能会导致收敛性能和鲁棒性降低,特别是在接收到的浓缩数据质量不佳的情况下。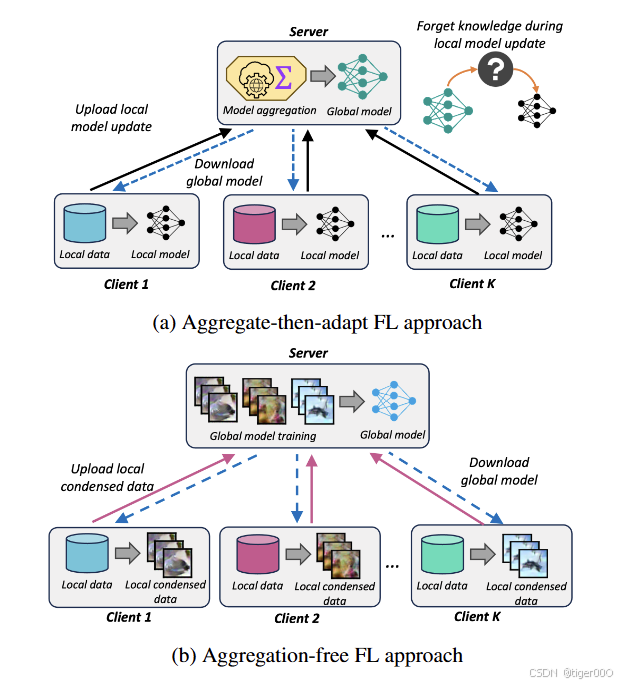
受上述研究空白的启发,本文提出了FedAF,一种新颖的无聚合FL算法,旨在应对数据异构性。我们研究的核心问题是如何最优地利用每个客户端原始数据中的固有知识,以增强本地数据浓缩和全局模型训练。为此,我们首先引入了一种协作数据浓缩方案。在该方案中,客户端通过最小化一个损失函数来浓缩其本地数据集,该损失函数结合了标准分布匹配损失[37]和基于切片Wasserstein距离(SWD)的额外正则化项。这种正则化将本地知识分布与其他客户端的更广泛分布对齐,为个体客户端提供了更全面的数据浓缩视角。此外,为了训练具有卓越性能的全局模型,我们引入了一种本地-全局知识匹配方案。这种方法使服务器不仅能够利用客户端共享的浓缩数据,还能利用从其数据中提取的软标签,从而优化和稳定训练过程。因此,全局模型保留了更多从前几轮中学到的知识,从而提高了整体收敛性能。
广泛的实验表明,FedAF能够持续提供卓越的模型性能和加速的收敛速度,在各种程度的数据异构性下优于多种最先进的FL算法。例如,在CIFAR10上,我们实现了高达25.44%的准确性提升和80%的收敛速度提升,与最先进的方法相比。总之,我们的贡献如下:
-
我们提出了一种新颖的无聚合FL算法,称为FedAF,以应对数据异构性的挑战。与传统的聚合本地模型梯度的方法不同,FedAF使用客户端浓缩数据更新全局模型,从而有效避免了客户端漂移问题。
-
我们引入了一种协作数据浓缩方案,以提高浓缩数据的质量。通过采用基于切片Wasserstein距离的正则化,该方案允许每个客户端利用其他客户端数据中的更广泛知识,这是现有文献中未充分探索的特性。
-
我们进一步提出了一种本地-全局知识匹配方案,使服务器能够利用从客户端数据中提取的软标签来增强全局洞察力。该方案补充了从客户端接收的浓缩数据,从而促进了模型准确性的提高和收敛速度的加快。
2. 背景与相关工作
FL算法用于异构数据。 广泛用于FL的基础FedAvg算法[26]通过平均每个客户端的本地模型来计算全局模型。在其变体中,FedAvgM[13]添加了服务器端Nesterov动量以增强全局模型更新。FedNova[29]根据本地计算量归一化聚合权重。FedBN[23]特别排除了批量归一化层参数进行全局聚合。FedProx[21]在本地训练损失中集成了一个近端项,以缓解客户端漂移问题,而SCAFFOLD[15]采用方差减少和控制变量技术直接解决客户端漂移。FedDyn[1]允许客户端更新其本地训练损失中的正则化,以更紧密地与全局经验损失对齐。相比之下,FedDC[10]提出学习一个漂移变量,以主动缓解本地和全局模型参数之间的差异。MOON[19]使用模型对比正则化来促进全局和本地模型之间特征表示的相似性。同时,FedDF[24]和FedBE[5]分别专注于基于知识蒸馏的模型融合和贝叶斯模型集成,以将知识转移到全局模型中。为了免除对未标记转移数据集的需求,FedGen[41]使服务器能够学习并与客户端共享生成器模型,通过生成的特征表示促进从全局模型到本地模型的知识蒸馏。
数据浓缩。 近年来,数据浓缩(或数据蒸馏)技术兴起。这些方法旨在将大型训练数据集压缩为显著更小的合成数据集,使得在该浓缩数据集上训练的模型能够实现与在原始数据集上训练的模型相当的性能。例如,[32]探索了一种双层学习框架来学习浓缩数据,使得在其上训练的模型能够最小化原始数据的损失。[38]匹配通过训练模型在原始数据和浓缩数据上产生的梯度。这种方法通过[36]进一步增强,后者应用了差分Siamese增强,以学习更具信息性的浓缩数据。与单步梯度匹配不同,[4]建议匹配由原始数据和浓缩数据产生的多步训练轨迹。为了减少早期工作中使用的昂贵双层优化的复杂性,[37]引入了一种分布匹配(DM)协议。在这种方法中,浓缩数据被优化以紧密匹配原始数据在潜在特征空间中的分布。基于DM,[31]进一步发展了这一概念,通过对齐真实数据和浓缩数据之间的逐层特征。
与生成对抗网络(GANs)[11]不同,后者专注于生成逼真的图像,数据浓缩方法的目标是通过创建高度信息化的合成训练样本来提高数据效率。最近的一项研究[8]表明,浓缩数据不仅提供了强大的视觉隐私,还确保在该数据上训练的模型对成员推理攻击具有抵抗力。
浓缩数据的潜力最近引起了FL社区的兴趣,促使人们努力将数据浓缩与FL结合在无聚合框架中。FedDM[34]在客户端实现了基于DM的数据浓缩,服务器使用客户端的浓缩数据来近似FL中的原始全局训练损失。采用[32]中的浓缩方法作为核心,[25]引入了一种本地数据浓缩的动态加权策略,并通过从条件生成器获得的伪数据样本增强了全局模型训练。然而,这两项工作都没有充分研究如何利用其他客户端的知识来提高本地浓缩数据的质量和全局模型的性能。虽然[25]允许客户端之间共享浓缩数据,但它依赖于所有客户端拥有相同类别数据的假设,这在跨客户端数据异构性强烈的情况下可能不成立。

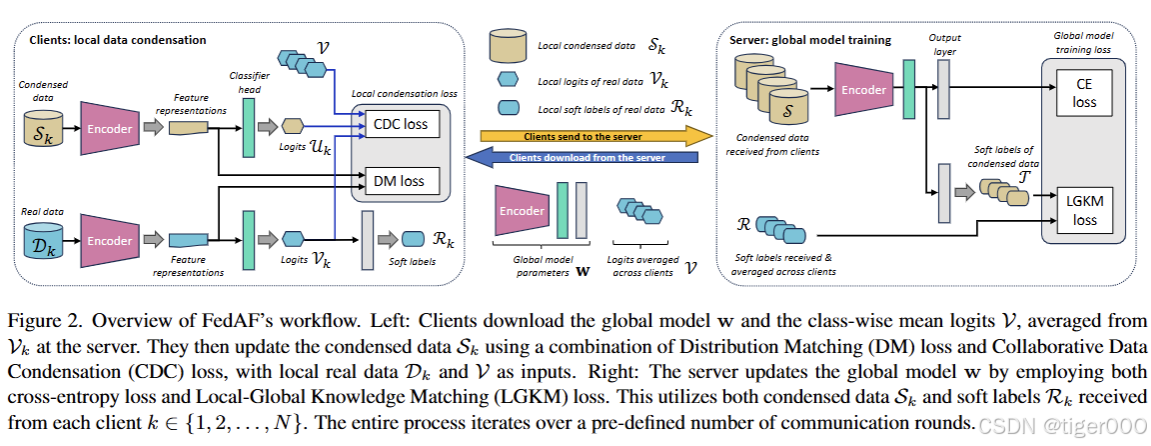




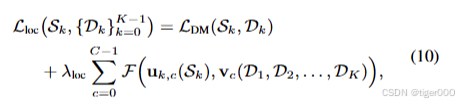




5. 实验
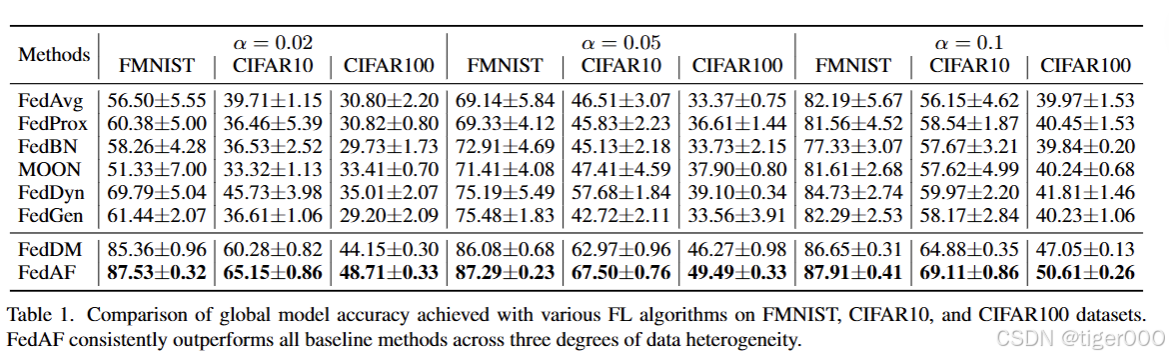
数据集。我们进行了实验,以评估和基准测试我们提出的方法在标签偏斜数据异质性和特征偏斜数据异质性下的性能。对于标签偏斜场景,我们采用了FashionMNIST(FMNIST)[33]、CIFAR10和CIFAR100[18]。FMNIST数据集包含70,000张时尚产品的灰度图像,分为10个类别。CIFAR-10和CIFAR-100数据集都是60,000张彩色图像的集合。CIFAR10图像分为10个类别,每个类别有6,000张图像,而CIFAR100将图像分为100个类别,每个类别有600张图像。对于特征偏斜场景,我们使用了DomainNet[27],它包含600,000张图像,分为六个域:Clipart、Infograph、Painting、Quickdraw、Real和Sketch,每个域包含345个类别的数据。
基线。我们将FedAF与“聚合-适应”基线进行比较,包括典型的FedAvg[26]和各种为处理数据异质性设计的最先进的FL算法:FedProx[21]、FedBN[23]、MOON[19]、FedDyn[1]和FedGen[41]。我们还考虑了同样采用无聚合FL的先前工作,即FedDM[34],以展示我们提出的协作数据浓缩和本地-全局知识匹配方案的有效性。






















 551
551

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









