







在上一篇文章中,我们介绍了去噪扩散模型之前向扩散和反向去噪,而在过去几年中,扩散模型逐渐成为生成模型领域的核心力量。它们不仅在图像生成任务中取得了与 GANs 相媲美甚至更强的表现,也为学术界和工业界带来了全新的研究方向。本篇文章将围绕扩散模型的性能评估、实际应用示例,以及近年来的一些重要改进方向进行总结与分析,帮助大家快速了解扩散模型在实际生成任务中的表现与演化。
1 DDPM 效果表现
DDPM 能够在多种数据集上生成高质量、多样性的样本,如下图所示。

不过,DDPM 的效果也受限于所使用的数据集。例如在下图中,模型被训练在包含 Shutterstock 图片的数据集上,因此能够“还原”出 Shutterstock 的水印。又如在 LSUN-Beds 的样本中,左下角的图像甚至包含了 Logo,这说明模型从含有 Logo 的图像中学到了类似的内容。

优点与缺点
DDPM 能够生成高质量、多样化的图像样本,不像 Autoencoders 或 VAEs 那样容易生成模糊结果,也不像 GANs 那样会出现模式崩溃(mode collapse)问题。然而,DDPM 的一个明显缺点是采样速度慢,因为它必须一步步完成反向去噪过程。
2 Latent Diffusion
2.1 简介
Latent Diffusion 是一种用来加速扩散过程的方法,Stable Diffusion 模型就是基于该技术。
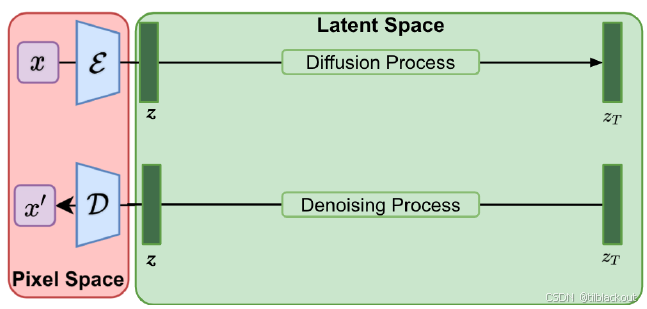
如下图所示,回忆一下自编码器的基本流程:我们首先将输入图像 x x x 编码为潜在表示 z z z,然后再通过解码器将其还原为 x ′ x' x′。

Latent Diffusion 的关键在于:它将扩散和去噪过程放在潜在空间中完成,而不是直接在图像空间操作。这样可以显著提升采样效率。
潜在空间(Latent Space)是原始数据在经过编码后映射到的一个低维抽象空间,它保留了数据的核心特征。
假设你有一张猫的图片,它是 128 × 128 128 \times 128 128×128 像素,RGB 三通道,总共包含 128 × 128 × 3 = 49152 128 \times 128 \times 3 = 49152 128×128×3=49152 个数。
这些像素点虽然详细,但对于理解“这是一只猫”来说,其实信息是冗余的。我们人类可能只需要注意:
- 是猫
- 是橘色的
- 在沙发上
这些抽象的特征就可以用一个更短的向量来表示,比如一个 z ∈ R 256 z \in \mathbb{R}^{256} z∈R256 的向量。这个向量就是在潜在空间中的表示。
具体来说,输入图像 x x x 首先通过编码器 E E E 映射为潜在表示 z z z,然后在 z z z 上添加噪声生成 z T z_T zT,再通过模型去噪还原为 z z z,最终通过解码器 D D D 还原为图像 x ′ x' x′。
由于去噪过程是在更低维的潜在空间中完成的,采样速度也因此大幅提升。
Latent Diffusion 还支持 条件图像生成(Conditional Image Generation)。用户可以提供一条提示(prompt),来描述期望生成的图像,例如文字、其他图像、语义分割图或其他形式的条件输入。
这些条件输入会通过一个编码器
τ
θ
\tau_\theta
τθ 编码后,作为额外信息注入到扩散模型中。这个编码后的向量会在去噪过程的每一个时间步
t
t
t 中,与当前的潜在表示
z
t
z_t
zt 进行多头交叉注意力(cross-attention),以强化对 prompt 的响应。
简单来说,多头注意力会突出那些与 prompt 匹配的特征,随着去噪过程的进行, z t z_t zt 会逐渐变成一个与 prompt 吻合的潜在表示,最终通过解码器生成目标图像。
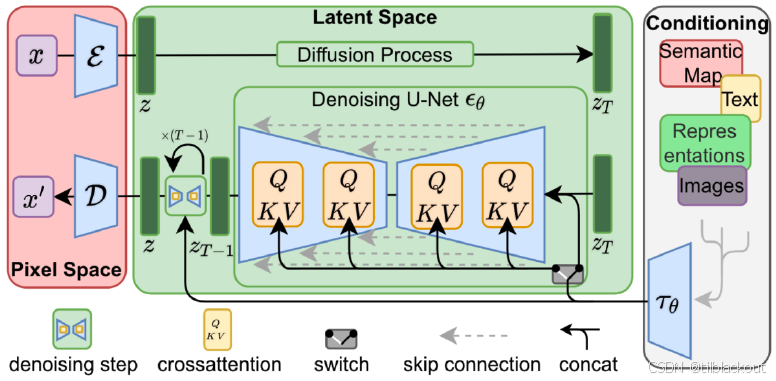
在采样阶段(也就是生成图片时),整个流程可以进一步简化:
- 和 DDPM 一样,我们从标准高斯分布中采样得到初始的 z T ∼ N ( 0 , I ) z_T \sim \mathcal{N}(\mathbf{0}, \mathbf{I}) zT∼N(0,I)
- 如果用户提供了条件 prompt,就会通过编码器得到其表示
- 然后在 T T T 步的去噪过程中,逐步将 z T z_T zT 还原为 z z z
- 最后将 z z z 输入解码器,生成图像 x ′ x' x′
这个机制正是 Stable Diffusion 能够“根据文字生成图像”的核心原理。
2.2 应用
Latent Diffusion 模型不仅能生成高分辨率、多样性的图像,还可以适用于多种任务,例如:
- 文字生成图像(
Text-to-Image) - 语义图生成图像(
Semantic Map to Image) - 图像修复(
Inpainting)等
这主要得益于它在潜在空间中的扩散与去噪操作,既高效又具表现力。
下图展示了 Latent Diffusion 模型在 LSUN-Churches 和 LSUN-Beds 数据集上的图像生成结果:

可以发现,在 LSUN-Churches 样本中,某些图像还保留了训练数据中的水印特征,例如白线或彩色螺旋等。这说明数据集的质量仍会影响最终效果。
条件图像生成:文字转图像(Text-to-Image)
Latent Diffusion 模型支持根据文本 prompt 来生成图像,这种方式被称为 Text-to-Image。
Prompt: A painting of the last supper by Picasso
结果如下图所示:

条件图像生成:语义图(Semantic Map)
语义图是一种将图像划分为不同区域并赋予语义标签的图。例如:
- 红橙色区域表示“天空”
- 灰色区域表示“树木”
Latent Diffusion 可以根据这些语义图生成对应图像,实现从抽象语义结构到真实画面的映射,非常适用于城市街景等任务。
💡 这种方式可以看作是“语义图转图像”(Semantic Map to Image),在自动驾驶场景理解、图像翻译等领域非常实用。

条件图像生成:图像修复(Inpainting)
Inpainting 是指在图像的一部分被遮挡或删除后,模型根据上下文填补该区域,使其看起来像是从未缺失。这项任务在图片修复、背景重建等场景中尤为重要。
下图展示了几个典型示例:
- 前两行中,人像被遮挡,模型自动补全背景,使得整张图自然协调;
- 第三行中,一棵树被遮挡,模型则还原了后面的建筑细节。

3 扩散模型的影响
扩散模型带来了诸多创新和强大能力的同时,也引发了广泛的伦理和社会讨论:
1.数据偏见与输出偏差
扩散模型依赖的大规模训练数据可能包含偏见,例如性别、种族、文化等方面的不均衡,从而导致模型输出也具有偏向性(如只生成特定审美、肤色等)。
这些问题与所有大语言模型类似,是目前生成式 AI 伦理的核心挑战之一。
2.版权问题与法律争议
许多生成图像包含 水印或版权信息,表明模型可能学习了未经授权的数据:
3.工具变革与艺术产业冲击
生成式 AI 正在改变创作流程:
- Adobe 于 2023 年 4 月发布 Firefly 测试版,支持:选区图像替换,视频背景编辑和设计模板生成
虽然这为创作者提供了强大工具,但也意味着传统创作与人工劳动的价值结构正在发生变化。
虽然扩散模型技术令人惊艳,但我们仍需认真思考它所依赖的数据来源、公平性问题、潜在的侵权风险,以及它对社会和创意工作者的长期影响。
4 总结
扩散模型以其强大的生成能力和稳定的训练特性,正在重塑生成模型领域的技术格局。从基础的 DDPM 到后续如 Latent Diffusion 等高效变体,我们看到了扩散模型在质量与效率上的持续突破。
尽管当前仍面临如采样速度较慢等挑战,但伴随着社区对结构、训练方法与潜在空间建模的不断优化,扩散模型的未来仍充满潜力。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











