







在自然语言处理领域,我们经常会接触到各种基础任务,这些任务不仅构成了语言智能系统的底层能力,也在实际应用中扮演着关键角色。本文将介绍NLP中最常见的11个基础任务,涵盖从文本处理(如名词短语提取、情感分析、主题建模)到语音和语义相关的实用应用(如语音转文本、文本转语音、语音翻译)等内容。
1 提取名词短语
名词短语的提取对于分析句子中的“谁”或“什么”非常有帮助。这里使用Spacy库来提取名词短语。
代码:
import spacy
# 加载英文模型
nlp = spacy.load("en_core_web_sm")
# 输入文本
doc = nlp("John is learning natural language processing")
# 提取名词短语(noun chunks)
for np in doc.noun_chunks:
print(np.text)
输出如下:

2 计算文本相似度
假设我们希望比较两段文本或文档的相似度。可以使用以下相似度算法:
- 余弦相似度(Cosine Similarity):计算两个向量夹角的余弦值。
- Jaccard 相似度:计算两个集合交集与并集的比例。
- Levenshtein 距离:将字符串 A 转换为 B 所需的最小编辑次数。
- Hamming 距离:比较两个等长字符串中不同字符的位置数。
- 语音匹配(Phonetic Matching):比较词语在发音层面上的相似度,例如 Soundex 算法。
余弦相似度例子:
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
# 文本数据
documents = (
"I like NLP",
"I am exploring NLP",
"I am a beginner in NLP",
"I want to learn NLP",
"I like advanced NLP"
)
# TF-IDF 向量化
tfidf_vectorizer = TfidfVectorizer()
tfidf_matrix = tfidf_vectorizer.fit_transform(documents)
# 计算第一句话与其他句子的相似度
similarity = cosine_similarity(tfidf_matrix[0:1], tfidf_matrix)
print(similarity)
输出如下:
[[1. 0.17682765 0.14284054 0.13489366 0.68374784]]
第一句与最后一句(都包含 “like NLP”)的相似度最高。
3 词性标注
现在我们希望为句子中的每个单词标注其词性(Part-of-Speech Tagging),如名词、动词、形容词等。
词性标注方法主要包括:
- 规则式(
Rule-based):基于人工制定的规则进行标注。 - 统计式(
Stochastic-based):基于词序列概率建模,如使用隐马尔可夫模型(HMM)。
例子(使用Spacy):
import spacy
from spacy.lang.en.stop_words import STOP_WORDS
# 加载英文模型
nlp = spacy.load("en_core_web_sm")
# 示例文本
text = "I love NLP and I will learn NLP in 2 month"
# 分句 + 分词 + 去除停用词 + 词性标注
doc = nlp(text)
for sent in doc.sents:
print(f"Sentence: {sent.text}")
tokens = [token for token in sent if token.text.lower() not in STOP_WORDS]
tagged = [(token.text, token.pos_) for token in tokens]
print(tagged)
输出如下:
Sentence: I love NLP and I will learn NLP in 2 month
[('love', 'VERB'), ('NLP', 'PROPN'), ('learn', 'VERB'), ('NLP', 'PROPN'), ('2', 'NUM'), ('month', 'NOUN')]
PROPN = Proper Noun
4 从文本中提取实体
现在我们要识别文本中的命名实体,如人名、组织、地点等。
这里我们使用 NLTK 和 spaCy为例进行介绍:
使用NLTK
import nltk
from nltk import ne_chunk, word_tokenize, pos_tag
nltk.download('maxent_ne_chunker_tab')
nltk.download('words')
sent = "John is studying at Stanford University in California"
tree = ne_chunk(pos_tag(word_tokenize(sent)), binary=False)
print(tree)
输出如下:

使用Spacy(推荐)
import spacy
nlp = spacy.load('en_core_web_sm')
doc = nlp("Apple is ready to launch new phone worth $10000 in New York time square")
for ent in doc.ents:
print(ent.text, ent.start_char, ent.end_char, ent.label_)
输出如下:
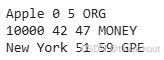
| 实体标签 | 含义 | 示例 |
|---|---|---|
| ORG | Organization(组织) | Apple、Google、UN 等 |
| MONEY | 金额/货币 | 10000(美元、人民币等) |
| GPE | Geo-Political Entity(地理-政治实体) | New York、China、EU 等 |
5 从文本中提取主题
使用 gensim 库结合 LDA(Latent Dirichlet Allocation)模型来完成主题建模。从而从多个文档中自动识别出主要主题关键词,以实现文档聚类或内容分类。
Step 1:准备文本数据
doc1 = "I am learning NLP, it is very interesting and exciting. it includes machine learning and deep learning"
doc2 = "My father is a data scientist and he is nlp expert"
doc3 = "My sister has good exposure into android development"
doc_complete = [doc1, doc2, doc3]
Step 2:文本清洗与预处理
# 导入所需模块
from nltk.corpus import stopwords # 停用词库
from nltk.stem.wordnet import WordNetLemmatizer # 词形还原器
import nltk
import string # 包含所有标点符号
# 下载 NLTK 中的停用词和词形还原资源
nltk.download('stopwords')
nltk.download('wordnet')
# 设置停用词集合(英文)
stop = set(stopwords.words('english'))
# 设置标点符号集合
exclude = set(string.punctuation)
# 初始化词形还原器
lemma = WordNetLemmatizer()
# 文本清洗函数
def clean(doc):
# 1. 小写化并移除停用词
stop_free = " ".join([i for i in doc.lower().split() if i not in stop])
# 2. 移除标点符号
punc_free = "".join(ch for ch in stop_free if ch not in exclude)
# 3. 对每个词做词形还原(如将 "cars" 变为 "car")
normalized = " ".join(lemma.lemmatize(word) for word in punc_free.split())
return normalized
# 对一组文档进行清洗处理,返回的是词列表的列表
doc_clean = [clean(doc).split() for doc in doc_complete]
Step 3:构建词典与文档-词频矩阵
# !pip uninstall -y numpy
# !pip install numpy==1.23.5
# !pip install --upgrade gensim
import gensim
from gensim import corpora
# 使用 gensim 的 Dictionary 对象构建词典(即将词映射为 id)
dictionary = corpora.Dictionary(doc_clean)
# 将清洗后的文档转换为词袋(Bag-of-Words)表示形式
# 每个文档表示为 (单词id, 出现次数) 的列表
doc_term_matrix = [dictionary.doc2bow(doc) for doc in doc_clean]
Step 4:训练LDA模型
# 指定 LDA 模型类
Lda = gensim.models.ldamodel.LdaModel
# 创建并训练 LDA 模型
# 参数说明:
# - doc_term_matrix: 输入的词袋数据
# - num_topics=3: 希望模型识别出 3 个主题
# - id2word=dictionary: 映射词 id 到词本身(用于输出)
# - passes=50: 对整个语料重复训练 50 次,提升模型效果
ldamodel = Lda(doc_term_matrix, num_topics=3, id2word=dictionary, passes=50)
# 输出每个主题及其关键词分布
for topic in ldamodel.print_topics():
print(topic)
输出如下:
(0, '0.129*"sister" + 0.129*"good" + 0.129*"exposure" + 0.129*"development" + 0.129*"android" + 0.032*"nlp" + 0.032*"father" + 0.032*"scientist" + 0.032*"data" + 0.032*"expert"')
(1, '0.233*"learning" + 0.093*"deep" + 0.093*"includes" + 0.093*"interesting" + 0.093*"machine" + 0.093*"exciting" + 0.093*"nlp" + 0.023*"scientist" + 0.023*"data" + 0.023*"expert"')
(2, '0.129*"nlp" + 0.129*"father" + 0.129*"data" + 0.129*"expert" + 0.129*"scientist" + 0.032*"exposure" + 0.032*"good" + 0.032*"development" + 0.032*"android" + 0.032*"sister"')
输出的格式为:
(主题编号, '关键词1权重*"关键词1" + 关键词2权重*"关键词2" + ...')
以第一个输出为例,这表示:
- 这个主题的关键词以 “learning” 为核心(权重最高 0.173)
- 其他关键词也较为重要,例如 “deep”、“machine”、“exciting”
- 它很可能代表一个“学习/技术/课程”相关的主题
6 文本分类
现在我们希望将文本自动分类,比如垃圾邮件识别、情感分类等,我们可以使用 TF-IDF 特征提取 + Naive Bayes 或 Logistic Regression 模型完成分类。
Step 1:加载并清洗数据
import pandas as pd
Email_Data = pd.read_csv("spam.csv", encoding='latin1')
Email_Data = Email_Data[['v1', 'v2']].rename(columns={"v1": "Target", "v2": "Email"})
- 数据集下载:spam.csv
Step 2:预处理文本
from nltk.corpus import stopwords
from nltk.stem import PorterStemmer
from textblob import Word
# 第一步:将所有文本转换为小写(避免同一个词因大小写不同被分开处理)
Email_Data['Email'] = Email_Data['Email'].apply(lambda x: " ".join(x.lower() for x in x.split()))
# 第二步:去除英文停用词(如:the, is, and 等无实际意义的常见词)
stop = stopwords.words('english')
Email_Data['Email'] = Email_Data['Email'].apply(lambda x: " ".join(x for x in x.split() if x not in stop))
# 第三步:进行词干提取(将单词还原为基础形式,如 running → run)
st = PorterStemmer()
Email_Data['Email'] = Email_Data['Email'].apply(lambda x: " ".join([st.stem(word) for word in x.split()]))
# 第四步:词形还原(lemmatization),进一步标准化词形,如 better → good
Email_Data['Email'] = Email_Data['Email'].apply(lambda x: " ".join([Word(word).lemmatize() for word in x.split()]))
Step 3:构建特征并划分训练集
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn import preprocessing
# 将数据集按 75% 训练 / 25% 验证 的比例进行划分
# Email_Data['Email'] 为文本,Email_Data['Target'] 为对应标签
train_x, valid_x, train_y, valid_y = train_test_split(Email_Data['Email'], Email_Data['Target'])
# 初始化标签编码器,将分类标签从字符串转为整数(如 spam → 1, ham → 0)
encoder = preprocessing.LabelEncoder()
train_y = encoder.fit_transform(train_y) # 拟合并转换训练标签
valid_y = encoder.transform(valid_y) # 对验证标签进行相同的转换
# 初始化 TF-IDF 向量器
# 参数含义:
# - analyzer='word': 按词(而非字母或短语)划分
# - token_pattern=r'\w{1,}': 匹配长度 ≥1 的词
# - max_features=5000: 只保留最常见的前 5000 个词
tfidf_vect = TfidfVectorizer(analyzer='word', token_pattern=r'\w{1,}', max_features=5000)
# 用整个文本语料拟合 TF-IDF 词表(计算 IDF)
tfidf_vect.fit(Email_Data['Email'])
# 将训练集文本转换为 TF-IDF 特征矩阵
xtrain_tfidf = tfidf_vect.transform(train_x)
# 将验证集文本转换为 TF-IDF 特征矩阵
xvalid_tfidf = tfidf_vect.transform(valid_x)
Step 4:训练模型并评估
# 导入朴素贝叶斯、逻辑回归模型,以及评价指标模块
from sklearn import naive_bayes, linear_model, metrics
# 定义通用的模型训练函数
def train_model(classifier, feature_vector_train, label, feature_vector_valid):
# 用训练集特征和标签拟合模型
classifier.fit(feature_vector_train, label)
# 使用训练好的模型对验证集进行预测
predictions = classifier.predict(feature_vector_valid)
# 计算并返回验证集上的准确率
return metrics.accuracy_score(predictions, valid_y)
# ---------- 使用模型1:朴素贝叶斯 ----------
# 使用 Multinomial Naive Bayes(多项式朴素贝叶斯)模型进行训练
# alpha=0.2 是平滑系数,用于防止某些词在训练集中出现频率为0
nb_acc = train_model(
naive_bayes.MultinomialNB(alpha=0.2),
xtrain_tfidf,
train_y,
xvalid_tfidf
)
print("Naive Bayes Accuracy:", nb_acc)
# ---------- 使用模型2:逻辑回归 ----------
# 使用默认参数的逻辑回归模型进行训练与预测
lr_acc = train_model(
linear_model.LogisticRegression(),
xtrain_tfidf,
train_y,
xvalid_tfidf
)
print("Logistic Regression Accuracy:", lr_acc)
输出:
Naive Bayes Accuracy: 0.9870782483847811
Logistic Regression Accuracy: 0.9662598707824839
可以尝试更多模型(如 SVM、Random Forest)进一步提升性能。
7 情感分析
现在我们想分析某段文本是积极、消极还是中性情绪。这里我们用Spacy库来实现这个功能。
# 安装依赖(只运行一次)
# !pip uninstall -y numpy
# !pip install numpy==1.23.5 --force-reinstall
# !pip install -q spacy vaderSentiment
# !python -m spacy download en_core_web_sm
# 导入库
import spacy
from vaderSentiment.vaderSentiment import SentimentIntensityAnalyzer
# 加载 spaCy 英文模型
nlp = spacy.load("en_core_web_sm")
# 初始化 VADER 情感分析器
analyzer = SentimentIntensityAnalyzer()
# 示例评论
review1 = "I like this phone. screen quality and camera clarity is really good."
review2 = "This tv is not good. Bad quality, no clarity, worst experience"
# 情感分析函数
def analyze_sentiment(text):
doc = nlp(text) # spaCy 分词 & 预处理
scores = analyzer.polarity_scores(doc.text) # VADER 分析
return scores
# 打印结果
print("Review 1:", analyze_sentiment(review1))
print("Review 2:", analyze_sentiment(review2))
输出如下:
Review 1: {'neg': 0.0, 'neu': 0.517, 'pos': 0.483, 'compound': 0.8122}
Review 2: {'neg': 0.262, 'neu': 0.393, 'pos': 0.345, 'compound': 0.357}
分析:
- Review 1:情感积极(compound=0.8122),正面占比0.483、负面为0.0,中性为0.517,整体评价明显偏正面。
- Review 2:情感轻度正面(compound=0.357),正面占比0.345、负面为0.262,中性为0.393,正负情绪混杂略偏积极。
8 词义消歧
现在我们想判断同一个词在不同语境中表示的不同含义,我们可以使用 Lesk 算法(通过上下文推理词义)来实现。
!pip install pywsd
import nltk
from pywsd.lesk import simple_lesk
nltk.download('averaged_perceptron_tagger_eng')
nltk.download('punkt_tab')
sentence1 = 'I went to the bank to deposit my money'
sentence2 = 'The river bank was full of dead fishes'
sense1 = simple_lesk(sentence1, 'bank')
print(sense1.name(), '→', sense1.definition())
sense2 = simple_lesk(sentence2, 'bank')
print(sense2.name(), '→', sense2.definition())
输出如下:
depository_financial_institution.n.01 → a financial institution that accepts deposits and channels the money into lending activities
bank.n.01 → sloping land (especially the slope beside a body of water)
可以看出:
-
在 句子1 中,
bank指的是 银行,与金钱相关。 -
在 句子2 中,
bank指的是 河岸,与自然环境相关。
9 语音转文本
我们可以使用 SpeechRecognition 和 PyAudio 库将语音输入转换为文本。我现在有一个sample1.wav里面的语音是"Hello I’m Jack",来看一下识别是否正确。
!pip install SpeechRecognition
import speech_recognition as sr
from google.colab import drive
drive.mount('/content/drive', force_remount=True)
# 使用已有音频文件
r = sr.Recognizer()
audio_file = sr.AudioFile('/content/drive/MyDrive/Colab Notebooks/sample1.wav') # 替换为你上传的音频文件
with audio_file as source:
audio = r.record(source)
# 使用 Google API 识别语音
print("识别结果:", r.recognize_google(audio))
输出如下:

要识别其他语言(如印地语):
r.recognize_google(audio, language='hi-IN')
10 文本转语音
我们可以使用 gTTS(Google Text-to-Speech)库将一段文本朗读出来生成音频文件。
!pip install gTTS
from gtts import gTTS
tts = gTTS(text='I like this NLP book', lang='en', slow=False)
tts.save("audio.mp3")
11 语言翻译
你希望将非英文翻译为英文,可以使用 goslate 库。
!pip install goslate
import goslate
gs = goslate.Goslate()
text = "Bonjour le monde"
translated = gs.translate(text, 'en')
print(translated)
# 输出:Hello world
12 总结
本文我们不仅介绍了名词短语提取、文本相似度计算、实体识别、主题建模、文本分类等文本处理技术,也深入了解了情感分析、词义消歧、语音与文本互转以及语言翻译等多模态应用。这些任务是构建智能对话系统、推荐系统、搜索引擎等高级应用不可或缺的部分。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











