







 R-CNN是一种通用目标检测框架,通过selective search获取候选区域,使用CNN提取特征,SVM进行分类和边框回归提高精度。文章介绍了R-CNN的工作流程,包括Warp和Crop、Bounding box regression、IoU、NMS和Hard negative mining等关键术语。尽管R-CNN较慢,但其引入CNN特征提取是重大创新,为后续的Fast R-CNN和Faster R-CNN奠定了基础。
R-CNN是一种通用目标检测框架,通过selective search获取候选区域,使用CNN提取特征,SVM进行分类和边框回归提高精度。文章介绍了R-CNN的工作流程,包括Warp和Crop、Bounding box regression、IoU、NMS和Hard negative mining等关键术语。尽管R-CNN较慢,但其引入CNN特征提取是重大创新,为后续的Fast R-CNN和Faster R-CNN奠定了基础。
《Rich feature hierarchies for accurate object detection and semantic segmentation》论文解读
作者是Ross B. Girshick,简称RBG,作者主页:
目标检测问题就是从图片中检测出目标的位置并判断目标的类别,比如人脸检测问题。不过人脸检测问题只是一种专门针对人脸的检测问题,而本文提出的R-CNN是通用目标检测问题,针对20类目标的检测。通用目标检测问题只需要进行适当修改就可以应用在人脸检测上。R-CNN检测框架的发展脉络是R-CNN,SPPnet,Fast R-CNN,Faster R-CNN。一些新的方法比如YOLO和SSD以后有时间再解读。
概述
如我前面博客所说,检测问题需要解决三个问题:1、候选区域生成;2、候选区域特征提取;3、目标分类识别。R-CNN对此解答是:selective search,CNN,SVM。
R-CNN
R-CNN目标检测框架如下所示:
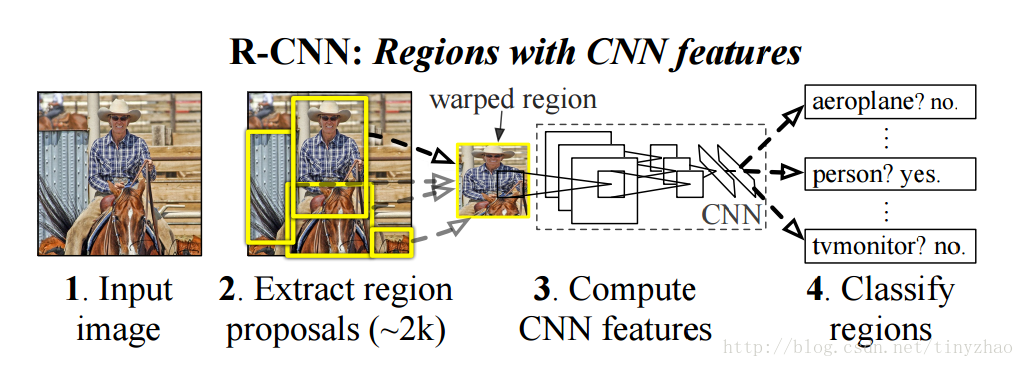
对于输入图片,首先使用selective search方法提取大概2k个候选区域,然后每个候选区域变形缩放到227*227输入到AlexNet中,得到4096维的特征以后,使用SVM进行分类,得到类别以后,还需要使用边框回归(Bounding box regression)提高边框位置精度。
AlexNet如何微调?AlexNet微调时,样本为基准方框中的区块,以及和基准区块重叠比较大的区块(IoU>0.5),这些都归为一类;并把AlexNet最后一层换成21个类别(20类目标+背景)的softmax分类。这样训练出来的CNN最后的softmax分类就不是很准确,但是能够用来提取目标特征。
SVM如何训练?SVM本质是一个二分类器,正样本为包含目标的基准框(ground true),需
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 299
299

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









