






目录
Semi-supervised Learning
Introduction
半监督学习是基于数据标签不全的深度学习方法。这里面的数据可以分为两大类,有标签的数据和没有标签的数据。而基于这种方法的一般情况都是有标签的数据远小于无标签的数据。
如何处理这些无标签的数据正式半监督学习的要点。

Semi-supervised Generative Model
半监督的生成模型
首先,我们可以利用有标签的数据给无标签的数据打上标签,或者说打上不同标签的几率。这两种标签分别称之为硬标签和软标签。生成模型的是软标签。示例如下。


根据极大似然估计来判断某个值属于不同标签的概率。

Low-density Separation
Introduction
这是属于硬标签的一种方法。利用一条分界线来划分不同类型标签的界限。
Self-training
这是首先让有标签的数据训练出分界线,再利用此来划分无标签数据的标签。

如果要将其放入神经网络中训练,标签必须确定,也就是必须为硬标签。

Entropy-based Regularization
这是训练时候的正则化的方法,L表示loss function。
Semi-supervised SVM

Smoothness Assumption
Introduction
这种方法类似于找相似的点,也就是两个点比较相近的时候,可以认为他们具有相同的标签。但除了相似之外,还有密度这一因素。
这种假设基于数据的密度,简单地说,当一堆数据堆在一块时候,他们地标签都是一样的。如下图所示,数据分成三堆,认为有三个标签。这三堆成为high density region。

这种假设是有好处的,比方说我们比较一下手写数字的相似程度。
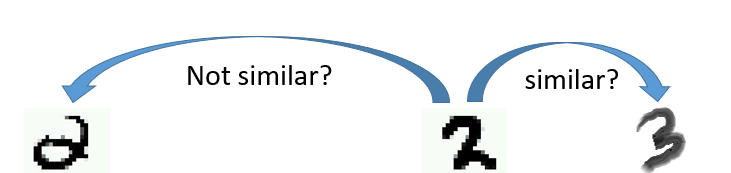
我们看得出,前两个是2,后面的是3。但是但从图像上来看,第二个和第三个是更接近的。所以仅仅只看相似度不行。三如果我们考虑到数据密度。如下所示,是不是机器就会把前两个归类为一个标签了。

Cluster and then Label
基于原数据的标签,我们分类后就能根据原有数据打上标签了。有些类似于无监督学习的办法。

Graph-based Approach
这是另外一钟无监督学习打标签的方法。类似于将这些数据点之间的联系表示出来分组,然后认为他们具有相同的标签。这些联系有时候是可以根据数据类型找出来的,有些则要自己判别。

下面是该方法一些特征的计算,和学习的方法。

















 535
535











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









