







第三周深度学习实战猴痘病识别
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍦 参考文章:Pytorch实战 | 第P4周:猴痘病识别
- 🍖 原作者:K同学啊 | 接辅导、项目定制
- 🚀 文章来源:K同学的学习圈子
前言
上周学会了加载本地数据并对数据集进行划分,这周主要学习运用模型进行预测并保存模型
相关函数学习
- torch.squeeze() 是 PyTorch 中的一个函数,它用于移除张量中大小为 1 的维度。在某些情况下,我们创建的张量可能包含不必要的维度,而 squeeze() 就可以帮助我们将这些维度去掉,使张量更加紧凑。
torch.squeeze(input, dim=None, out=None)
参数:
- input:输入的张量。
- dim(可选):要挤压的维度。如果指定了该参数,则只有在指定维度上大小为1时才会被挤压。如果未指定,则挤压所有大小为1的维度。
- out(可选):输出张量。
返回值:
返回一个新的张量,该张量是输入张量去除指定维度上大小为1的结果。
import torch
# 示例张量
x = torch.rand(1, 3, 1, 4)
# 使用squeeze()去除大小为1的维度
y = torch.squeeze(x)
print("原始张量大小:", x.size())
print("去除大小为1的维度后的张量大小:", y.size())
原始张量大小: torch.Size([1, 3, 1, 4])
去除大小为1的维度后的张量大小: torch.Size([3, 4])
- torch.unsqueeze() 是 PyTorch 中的函数,用于在张量的指定维度上插入一个维度,该维度的大小为 1。这个操作的逆操作就是 torch.squeeze()。
torch.unsqueeze(input, dim)
参数:
input:输入的张量。
dim:要在其前插入维度的维度索引。
返回值:
返回一个新的张量,它在指定的维度上插入了一个大小为 1 的维度。
import torch
# 示例张量
x = torch.rand(3, 4)
# 在维度1上插入一个大小为1的维度
y = torch.unsqueeze(x, 1)
print("原始张量大小:", x.size())
print("插入大小为1的维度后的张量大小:", y.size())
原始张量大小: torch.Size([3, 4])
插入大小为1的维度后的张量大小: torch.Size([3, 1, 4])
>>> x = torch.tensor([1, 2, 3, 4])
>>> torch.unsqueeze(x, 0)
tensor([[ 1, 2, 3, 4]])
>>> torch.unsqueeze(x, 1)
tensor([[ 1],
[ 2],
[ 3],
[ 4]])
- torch.max(output, 1) 是 PyTorch 中用于在张量上执行按行(维度1)取最大值的操作
values, indices = torch.max(output, 1)
torch.max(output, 1) 是 PyTorch 中用于在张量上执行按行(维度1)取最大值的操作。让我们详细解释一下这个操作:
-
values, indices = torch.max(output, 1)
output 是一个包含模型预测值的张量,通常是一个神经网络的输出。假设 output 的形状是 (batch_size, num_classes),其中 batch_size 表示批量大小,而 num_classes 表示分类问题中的类别数。 -
torch.max 函数在给定维度上(这里是维度1,表示按行操作)返回输入张量的最大值和最大值所在的索引。
-
values 是包含每行最大值的张量,形状为 (batch_size,)。这个张量包含了每个样本(每一行)的最大值。
-
indices 是包含每行最大值所在索引的张量,形状也是 (batch_size,)。这个张量包含了每个样本的模型预测的类别索引。
import torch
# 模拟模型输出
output = torch.randn(3, 5) # 3个样本,每个样本有5个类别的分数
# 取每行的最大值和对应的索引
values, indices = torch.max(output, 1)
print("模型输出:")
print(output)
print("每行最大值:")
print(values)
print("每行最大值所在的索引:")
print(indices)
_,pred = torch.max(output,1)
torch.max 的第一个返回值是每行的最大值,而第二个返回值是每行最大值所在的索引。通过使用下划线 _,你可能是表明你对最大值本身不感兴趣,只对最大值所在的索引感兴趣,而不想显式地存储最大值。
这种写法常常用在深度学习模型的训练中,特别是在分类任务中。例如,如果 output 是一个模型的输出,表示各个类别的得分,那么 torch.max(output, 1) 将返回每行最大值所在的索引,即模型预测的类别。
具体而言,_ 通常用作一个占位符,表示这个值在后续的代码中不会被使用。在这种情况下,torch.max 函数的第一个返回值被舍弃,而只关注第二个返回值,即每行最大值所在的索引,赋值给变量 pred。
- model.state_dict()
model.state_dict() 是一个 PyTorch 模型对象的方法,它返回一个包含模型所有参数的字典。这个字典的键是每个参数的名称,而值是对应的张量,即参数的权重和偏置。
在 PyTorch 中,模型的状态字典是一个表示模型当前状态的重要组成部分。这个状态字典可以包含模型的所有可学习参数,包括卷积层的权重、全连接层的权重和偏置等。通过保存和加载模型的状态字典,我们可以轻松地存储和恢复模型的参数。
以下是一个简单的例子,演示如何使用 model.state_dict():
import torch
import torch.nn as nn
# 定义一个简单的模型
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.fc1 = nn.Linear(10, 5)
self.fc2 = nn.Linear(5, 2)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = self.fc2(x)
return x
# 创建模型实例
model = SimpleModel()
# 获取模型的状态字典
model_state_dict = model.state_dict()
# 打印模型的状态字典
print(model_state_dict)
OrderedDict([('fc1.weight', tensor([[-0.0757, 0.2349, -0.1076, -0.1993, 0.0381, -0.2411, -0.0318, 0.2482,
-0.2821, 0.0269],
[ 0.1415, 0.1754, 0.2123, 0.1585, -0.2090, 0.1614, -0.3113, -0.1168,
-0.1606, 0.1255],
[-0.3100, 0.0444, 0.0878, -0.2170, 0.2417, -0.2851, -0.0901, 0.2084,
-0.1220, -0.2309],
[-0.1712, -0.0851, 0.2273, -0.1367, -0.1396, 0.0740, -0.2683, -0.2606,
0.0273, -0.2939],
[-0.3094, 0.2245, -0.2648, -0.0514, -0.0512, -0.1542, -0.1901, -0.1240,
0.2224, 0.0908]])), ('fc1.bias', tensor([ 0.2879, -0.0770, 0.0887, 0.2030, 0.1665])), ('fc2.weight', tensor([[ 0.0887, -0.1596, -0.3122, -0.4213, 0.1226],
[-0.0023, -0.0153, -0.1476, 0.2636, 0.3446]])), ('fc2.bias', tensor([-0.4469, -0.4398]))])
- torch.save() 是 PyTorch 中用于将对象保存到文件的函数。通常,它用于保存模型的参数、整个模型、优化器的状态、以及其他 PyTorch 对象。
以下是 torch.save() 的基本用法:
torch.save(obj, file_path)
- obj 是要保存的对象,可以是模型的参数字典 (model.state_dict() 返回的内容)、整个模型、优化器的状态字典 (optimizer.state_dict() 返回的内容) 等等。
- file_path 是保存文件的路径,通常使用 “.pth” 或 “.pt” 作为文件扩展名。
例如,保存模型的参数字典:
import torch
import torch.nn as nn
# 定义一个简单的模型
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.fc = nn.Linear(10, 5)
def forward(self, x):
return self.fc(x)
# 创建模型实例
model = SimpleModel()
# 获取模型的参数字典
model_state_dict = model.state_dict()
# 保存模型的参数字典到文件
torch.save(model_state_dict, 'model_parameters.pth')
如果要保存整个模型,可以使用以下方式:
# 保存整个模型到文件
torch.save(model, 'entire_model.pth')
在保存整个模型时,你可以在加载模型时不必事先定义模型的类,但需要确保加载模型的代码中导入了与模型定义相同的模块。例如:
# 加载整个模型
loaded_model = torch.load('entire_model.pth')
- model.load_state_dict(torch.load(PATH, map_location=device))
torch.load(PATH) 从指定路径加载保存的参数字典。PATH 是你之前用 torch.save() 保存参数字典的文件路径。
map_location 参数用于指定加载到哪个设备上。如果你在保存模型时使用了 GPU (‘cuda’),而加载模型时希望在 CPU 上运行,可以使用 map_location=‘cpu’。这样可以确保模型参数被正确放置在目标设备上。
model.load_state_dict(…) 将加载的参数字典加载到模型中。这确保了模型的权重和偏置等参数被正确设置为保存时的状态。
模型训练和预测
模型训练结果如下图所示
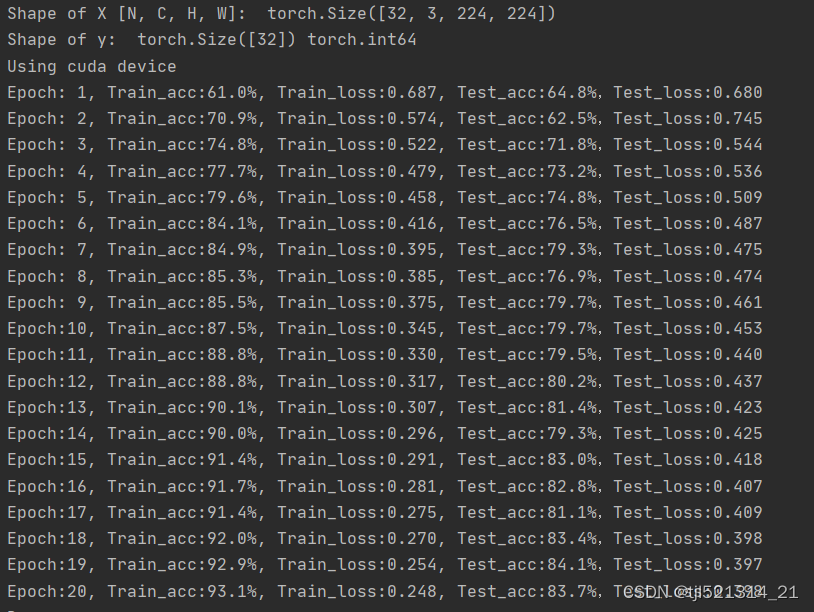
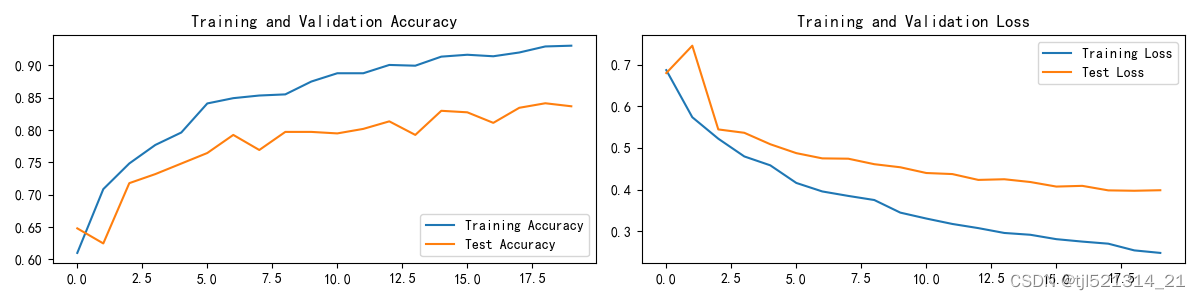
预测
从浏览器随机下载图片

预处理函数
def predict_one_image(image_path, model, transform, classes):
test_img = Image.open(image_path).convert('RGB')
# plt.imshow(test_img) # 展示预测的图片
test_img = transform(test_img)
img = test_img.to(device).unsqueeze(0)
model.eval()
output = model(img)
_, pred = torch.max(output, 1)
pred_class = classes[pred]
print(f'预测结果是:{pred_class}')
# 预测训练集中的某张照片
predict_one_image(image_path='./OIP-C.jpeg',
model=model,
transform=train_transforms,
classes=classes)
结果如下:
预测结果是:Monkeypox
然后保存模型
# 模型保存
PATH = './model.pth' # 保存的参数文件名
torch.save(model.state_dict(), PATH)
# 将参数加载到model当中
model.load_state_dict(torch.load(PATH, map_location=device))
总结
这周主要在上周的基础上学会了如何加载和保存模型。















 1821
1821











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









