







之前的文章中都是给大家写的变量间线性关系的做法,包括回归和广义线性回归,变量间的非线性关系其实是很常见的,今天给大家写写如何拟合论文中常见的非线性关系。包括多项式回归Polynomial regression和样条回归Spline regression。
多项式回归
首先看一个二次项拟合的例子,我现在想探讨苹果内容物apple content和苹果酸度cider acidity的关系,第一步应该是做出apple content和cider acidity关系的散点图,假如是下图:
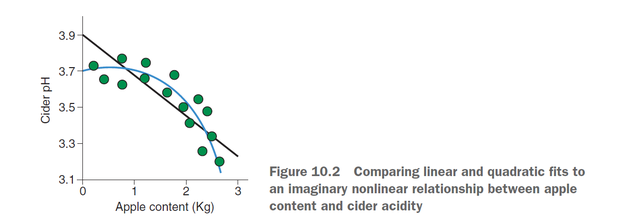
那么我很直观地可以看出来,曲线(二次)对数据的拟合明显是好于线性拟合的。
上面的只是一个2次项拟合的例子,我们其实经常会遇到有可能高次式会把数据拟合的更好,社科论文中其实也常常见到做高次回归的,常见的1次,2次,3次,4次项英文论文中的表达,曲线形状如下:

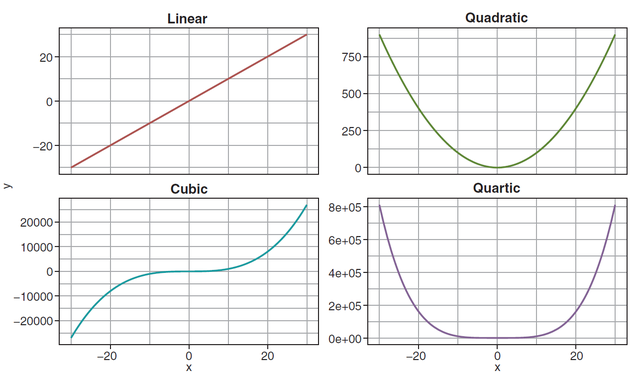
拟合出来的一般模型表达式如下:
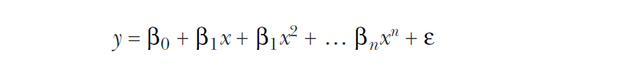
而且通常情况下,模型中所有的低次项都不应该被略去。就是我有了4次项,那么应该3,2,1次项都应该有。
含有二次及以上的模型就叫多项式回归模型。
样条回归
之前在机器学习的文章中有给大家写过拟合,我们做多次项拟合的时候,按道理你可以将项的次数调得很高,总是可以近乎完美的拟合我们的复杂的非线性关系,但是问题就是外推性就没有了,这也并不是我们想看到的结果:
High-degree polynomials allow us to capture complicated nonlinear relationships in the data but are therefore more likely to overfit the training set.
还有就是自变量和因变量之间的关系在自变量的不同取值范围也并非不变的,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2491
2491

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











