







一 遗传算法
遗传算法(GA)作为一种经典的进化算法,自 Holland提出之后在国际上已经形成了一个比较活跃的研究领域. 人们对 GA 进行了大量的研究,提出了各种改进算法用于提高算法的收敛速度和精确性. 遗传算法采用选择,交叉,变异操作,在问题空间搜索最优解.经典遗传算法首先对参数进行编码,生成一定数目的个体,形成初始种群其中每个个体可以是一维或多维矢量,以二进制数串表示,称为染色体.染色体的每一位二进制数称为基因.根据自然界生物优胜劣汰的选择思想,算法中设计适应度函数作为评判每个个体性能优劣的标准,性能好的个体以一定概率被选择出来作为父代个体参加以后的遗传操作以生成新一代种群.算法中基本的遗传算子为染色体选择,染色体上基因杂交和基因变异.生成新一代种群后算法循环进行适应度评价、遗传操作等步骤,逐代优化,直至满足结束条件.
标准遗传算法的流程如下:
Stepl:初始化群体.
Step2:计算群体上每个个体的适应度值.
Step3:按由个体适应度值所决定的某个规则选择将进入下一代的个体.
Step4:按概率cp 进行杂交操作.
Step5:按概率mp 进行变异操作.
Step6:若满足某种停止条件,则执行 Step7,否则执行 Step2.
Step7:输出种群中适应度值最优的染色体作为问题的满意解.
一般情况下,算法的终止条件包括:1、完成了预先给定的进化代数;2、种群中的最优个体在连续若干代没有改进或平均适应度在连续若干代基本没有改进;3、所求问题最优值小于给定的阈值.
粒子群(PSO)算法是近几年来最为流行的进化算法,最早是由Kenned和Eberhart于1995年提出.PSO 算法和其他进化算法类似,也采用“群体”和“进化”的概念,通过个体间的协作与竞争,实现复杂空间中最优解的搜索.PSO 先生成初始种群,即在可行解空间中随机初始化一群粒子,每个粒子都为优化问题的一个可行解,并由目标函数为之确定一个适应值(fitness value).PSO 不像其他进化算法那样对于个体使用进化算子,而是将每个个体看作是在n 维搜索空间中的一个没有体积和重量的粒子,每个粒子将在解空间中运动,并由一个速度决定其方向和距离.通常粒子将追随当前的最优粒子而运动,并经逐代搜索最后得到最优解.在每一代中,粒子将跟踪两个极值,一为粒子本身迄今找到的最优解 pbest ,另一为全种群迄今找到的最优解 gbest.由于认识到 PSO 在函数优化等领域所蕴含的广阔的应用前景,在 Kenned 和 Eberhart 之后很多学者都进行了这方面的研究.目前已提出了多种 PSO改进算法,并广泛应用到许多领域.
二、差分进化算法
差分进化算法在 1997 年日本召开的第一届国际进化优化计算竞赛(ICEO)]表现突出,已成为进化算法(EA)的一个重要分支,很多学者开始研究 DE 算法,并取得了大量成果.2006年 CEC 国际会议将其作为专题讨论,由此可见 DE 算法已成为学者的研究热点,具有很大的发展空间.
DE算法的基本原理:
DE 算法主要用于求解连续变量的全局优化问题,其主要工作步骤与其他进化算法基本一致,主要包括变异(Mutation)、交叉(Crossover)、选择(Selection)三种操作。算法的基本思想是从某一随机产生的初始群体开始,利用从种群中随机选取的两个个体的差向量作为第三个个体的随机变化源,将差向量加权后按照一定的规则与第三个个体求和而产生变异个体,该操作称为变异。然后,变异个体与某个预先决定的目标个体进行参数混合,生成试验个体,这一过程称之为交叉。如果试验个体的适应度值优于目标个体的适应度值,则在下一代中试验个体取代目标个体,否则目标个体仍保存下来,该操作称为选择。在每一代的进化过程中,每一个体矢量作为目标个体一次,算法通过不断地迭代计算,保留优良个体,淘汰劣质个体,引导搜索过程向全局最优解逼近。
DE算法的求解步骤:
(1)基本参数的设置,包括NP, F, CR
(2)初始化种群
(3)计算种群适应度值
(4)终止条件不满足时,进行循环,依次执行变异、交叉、选择运算,直到终止运算。
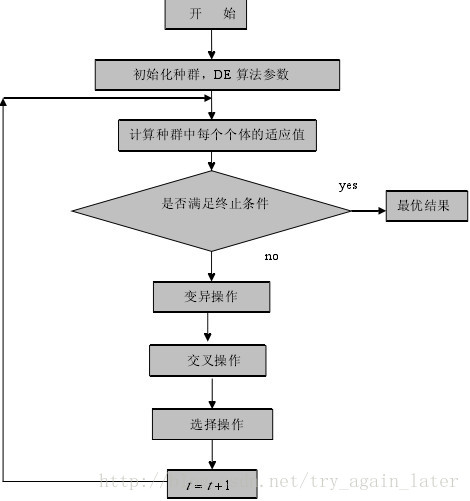
图2.1给出了算法的具体流程:
控制参数对一个全局优化算法的影响是很大的,DE的控制变量选择也有一些经验规则.
(1)种群数量.根据经验,种群数量 NP 的合理选择在5 D 10D之间,必须满足 NP ≥4以确保DE具有足够的不同的变异向量.
(2)变异算子.变异算子 F ∈ [0,2]是一个实常数因数,它决定偏差向量的放大比例.迄今为止的研究表明,小于0.4和大于1的 F 值仅偶尔有效, F = 0.5通常是一个较好的初始选择.若种群过早收敛,那么 F 或 NP 应该增加.
(3)交叉算子.交叉算子CR 是一个范围在[0,1]的实数,它是控制一个试验向量来自随机选择的变异向量而不是原来向量的概率的参数.CR 的一个较好的选择是0.1,但较大的CR 通常加速收敛,为了看是否可能获得一个快速解,可以首先尝试 CR = 0.9或 CR = 1.0.
(4)最大进化代数.它表示DE算法运行到指定的进化代数之后就停止运行,并将当前群体中的最佳个体作为所求问题的最优解输出.一般取值范围为100-200,当然根据问题的需要,可以增大最大进化代数以提高算法的求解精度,不过这样往往使得算法的运行时间过长.
(5)终止条件.除最大进化代数可作为DE的终止条件,还需要其它判定准则.一般当适应度值小于阀值时程序终止,阀值常选为610 .
上述参数中,F ,CR 与 NP 一样,在搜索过程中是常数,一般 F 和CR 影响搜索过程的收敛速度和鲁棒性,它们的优化值不仅依赖于目标函数的特性,还与 NP 有关.通常可通过在对不同值做一些试验之后利用试验和结果误差找到 F ,CR 和 NP 合适值。
参数设置:
种群规模NP:多样性,NP大,增加搜索到最优解的概率,但是计算量加大。
缩放因子F:对基向量扰动程度,F大,扰动大,能够在更大范围寻找解。0.4~1
交叉概率CR:种群多样性,CR大,更多个体改变,利于寻找最优解。0.6~1
区别:不同之处在于遗传算法是根据适应度值来控制父代杂交,变异后产生的子代被选择的概率值,在最大化问题中适应值大的个体被选择的概率相应也会大一些。而差分进化算法变异向量是由父代差分向量生成,并与父代个体向量交叉生成新个体向量,直接与其父代个体进行选择。显然差分进化算法相对遗传算法的逼近效果更加显著。
遗传算法,粒子群算法,差分进化算法都属于进化算法的分枝,很多学者对这些算法进行了研究,通过不断的改进,提高了算法的性能,扩大了应用领域因此很有必要讨论这些算法的特点,针对不同应用领域和算法的适应能力,推荐不同的算法供使用将是十分有意义的工作.在文献中,作者针对广泛使用的 34 个基准函数分别对 DE,EA,PSO 进行了系列实验分析,对各种算法求解最优解问题进行了讨论.通过实验分析,DE 算法获得了最优性能,而且算法比较稳定,反复运算都能收敛到同一个解;PSO 算法收敛速度次之,但是算法不稳定,最终收敛结果容易受参数大小和初始种群的影响;EA 算法收敛速度相对比较慢,但在处理噪声问题方面,EA 能够很好的解决而 DE 算法很难处理这种噪声问题.
通过实验和文献分析,我们对遗传算法、粒子群算法、差分进化算法的一些指标分别进行分析现归纳如下:
(1)编码标准 GA 采用二进制编码,PSO、DE 都采用浮点实数编码,近年来许多学者通过整数编码将GA 算法、PSO 算法应用与求解离散型问题,特别是 0-1 非线性优化为题,整数规划问题、混合整数规划问题,而离散的 DE 算法则研究的比较少,而采用混合编码技术的 DE 算法则研究更少.
(2)参数设置问题 DE 算法主要有三个参数(种群大小NP、缩放因子F、交叉概率CR)要调整,而且参数设置对结果影响不太明显,因此更容易使用.相对于 GA 和 PSO 算法的参数过多,不同的参数设置对最终结果影响也比较大,因此在实际使用中,要不断调整,加大了算法的使用难度.高维问题在实际问题中,由于转化为个体的向量维数非常高,因此算法对高维问题的处理,将是很重要的.只有很好的处理高维问题,算法才能很好的应用于实际问题.
(3)高维问题 GA 对高维问题收敛速度很慢甚至很难收敛,但是 PSO 和 DE 则能很好解决.尤其是DE 算法,收敛速度很快而且结果很精确.
(4)收敛性能 对于优化问题,相对 GA,DE 和 PSO 算法收敛速度比较快,但是 PSO 容易陷入局部最优解,而且算法不稳定.
(5)应用广泛性 由于 GA 算法发明比较早,因此应用领域比较广泛,PSO 算法自从发明以来,已成为研究热点问题,这方面应用也比较多,而 DE 算法近几年才引起人们的关注而且算法性能好,因此应用领域将会增多.
DE缺点:
1、搜索停滞:种群个体较少,且生成新一代个体的适应值比原种群个体适应值差,导致个体难以更新,没有收敛到极值点。
2、早熟收敛:参数设置不当,收敛过快,局部最优问题。
原文网址 点击打开链接














 2058
2058

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









