







19.1 计算机概述
之前的很多篇文章已经大量涉及了各种各样的硬件和技术,本篇将更加全面、系统、深入地阐述计算机的硬件组成和体系架构,从而形成自上而下的计算机体知识体系。本篇主要阐述以下内容:
- 计算机基础。
- 电子电路基础。
- 计算机硬件。
- 计算机架构和组织。
- 计算机硬件运行机制。
- 计算机硬件的UE封装和实现。
19.1.1 计算机是什么
计算机(Computer)是什么?计算机是一种通用设备,可以编程处理信息,并产生有意义的结果。它是一种被广泛使用且使我们的工作变得轻松的设备,是被动型机器,需要我们输入指令或任务来执行,从而获得我们需要的结果。

一个基础的计算机。
简单的单处理器计算机如下,提供了传统单处理器计算机内部结构的分层视图。有四个主要结构部件:CPU、主内存、I/O、系统链接。

如下图所示,向用户提供应用程序时使用的硬件和软件可以以分层或分层的方式查看。这些应用程序的用户,即最终用户,通常不关心计算机的架构,因此终端用户根据应用来查看计算机系统。该应用程序可以用编程语言表示,并由应用程序程序员开发,将应用程序开发为一组完全负责控制计算机硬件的处理器指令将是一项极其复杂的任务。为了简化此任务,提供了一组系统程序。

其中一些程序被称为实用程序。这些实现了常用的功能,有助于程序创建、文件管理和I/O设备控制。程序员在开发应用程序时使用这些工具,应用程序在运行时调用实用程序来执行某些功能。最重要的系统程序是操作系统,操作系统向程序员隐藏了硬件的细节,并为程序员提供了使用系统的方便界面。它充当中介,使程序员和应用程序更容易访问和使用这些设施和服务。
硬件之中,最重要的部件是芯片,其制造工艺如下图。从硅锭切片后,将空白晶片经过20至40个步骤,以形成图案化晶片。然后用晶片测试仪对这些图案化的晶片进行测试,并绘制出良好零件的地图。然后将晶片切成小片,在该图中,一个晶片生产了20个管芯,其中17个管芯通过了测试(X表示模具不良)。在这种情况下,好模具的产量为17/20,即85%。然后将这些好的模具粘结到包装中,并在将包装好的零件运送给客户之前再次进行测试。最终测试中发现一个包装不良的零件。

19.1.2 计算机结构
典型的台式计算机有三个主要物理部件——CPU(中央处理器)、主存储器和硬盘。CPU通常也被称为处理器或简单的机器,是计算机的大脑,是计算机的主要部分,将程序作为输入并执行。主存储器用于存储程序在执行过程中可能需要的数据(信息存储),处理器本身的存储空间有限。当电源关闭时,处理器和主存储器会丢失所有数据,但硬盘代表永久存储,程序、数据、照片、视频和文档等数据都存储在硬盘中。

下图显示了三个组件的简化框图。除了这些主要组件之外,还有一系列与计算机相连的外围组件,例如键盘和鼠标连接到计算机。它们从用户处获取输入,并将其传递给处理器上运行的程序。

类似地,为了显示程序的输出,处理器通常将输出数据发送到监视器,监视器可以以图形方式显示结果,也可以使用打印机打印结果。最后,计算机可以通过网络连接到其他计算机。所有外围设备的方框图如下所示。

19.1.3 计算机运行机制
不管底层技术如何,我们需要理解的一个基本概念是,计算机从根本上来说是一台愚蠢的机器。与我们的大脑不同,它没有被赋予抽象的思想、理性和良知。至少在目前,计算机不能自己做出非常复杂的决定,能做的就是执行一个程序。尽管如此,计算机之所以如此强大,是因为它们非常擅长执行程序,每秒可以执行数十亿条基本指令。计算机与人脑的比较如下表所示。
| 特性 | 计算机 | 人脑 |
|---|---|---|
| 智力 | 愚蠢 | 智能 |
| 算力 | 超快 | 慢 |
| 是否疲倦 | 绝不 | 一段时间后 |
| 是否厌倦 | 绝不 | 几乎总是 |
计算机无法理解人类语言,只能理解二进制数据,也就是0和1、True和False、On和Off,这些状态是通过晶体管(transistor)实现的。晶体管是用于存储2个值(1和0或开和关)的微型设备,如果晶体管打开,它的值为 1,如果它关闭,则值为 0。
例如,一个存储芯片包含数亿甚至数十亿个晶体管,每个晶体管都可以单独打开或关闭。当极少量的电流通过晶体管时,它保持状态1,当没有电流时,晶体管的状态为0。具体示例:
1 : 1
2 : 10
3 : 11
a : 01100001
A : 01000001
U : 01010101
Hello : 01001000 01100101 01101100 01101100 01101111
Hello World! : 01001000 01100101 01101100 01101100 01101111 00100000 01010111 01101111 01110010 01101100 01100100 00100001
问题在于,以上二进制代码对于人类而言,太难以理解了,此时需要各类计算机软件做翻译的桥梁作用。软件是一组指令,告诉计算机要做什么、什么时候做以及如何做。下图显示了操作流程。第一步是用高级语言(C或C++)编写程序,第二步涉及编译它,编译器将高级程序作为输入,并生成包含机器指令的程序,该程序通常称为可执行文件或二进制文件。注意,编译器本身是一个由基本机器指令组成的程序。

假设要执行2+2的指令,那么我们必须给计算机指令:
- 第1步:取2个值。
- 第2步:存储该2值。
- 第3步:使用 + 运算符对它们进行相加。
- 第4步:存储结果。
为 + 运算符提供了单独的说明,以便计算机在遇到 + 符号时知道如何进行加法。那么谁来转换这段代码呢?答案是解释器(interpreter),它把我们的语言代码转换成计算机可以理解的机器语言。同理,输入和输出数据也需要依赖特定的软件和解释器。
就像任何语言都有有限的单词一样,处理器可以支持的基本指令/基本命令的数量也必须是有限的,这组指令通常称为指令集(instruction set),基本指令的一些示例是加法、减法、乘法、逻辑或和逻辑非。请注意,每条指令需要处理一组变量和常量,最后将结果保存在变量中。这些变量不是程序员定义的变量,是计算机内的内部位置。
19.1.4 计算机设计准则
计算机设计是组件相互关联的结构。设计者一次处理特定级别的系统,并且在不同级别存在不同类型的问题。在每一层,设计者都关心结构和功能,结构是相互关联的用于通信的各个组件的骨架,功能是系统中涉及的活动。 以下是计算机设计中的问题:
- 无限速度的假设: 不能假设计算机的无限速度,因为假设无限速度是不切实际的,也给设计者的思维带来了问题。
- 内存无限的假设: 就像计算机的速度一样,内存也不能假设为无限的,总是有限的。
- 内存和处理器之间的速度不匹配: 有时内存和处理器的速度可能不匹配,可能是内存速度更快或处理器速度更快。内存和处理器之间的不匹配会导致设计中出现问题。
- 处理错误和错误: 处理缺陷和错误是任何计算机设计者的巨大责任,缺陷和错误会导致计算机系统出现故障,有时这些错误可能更危险。
- 多处理器: 设计具有多个处理器的计算机系统会导致管理和编程的巨大任务,是计算机设计中的一大问题。
- 多线程: 具有多线程的计算机系统总是对设计者构成威胁,具有多个线程的计算机应该能够进行多任务和多处理。
- 共享内存: 如果一次要执行多个进程,则所有进程共享相同的内存空间。应该以特定的方式对其进行管理,以免发生冲突。
- 磁盘访问: 磁盘管理是计算机设计的关键,磁盘访问存在几个问题,系统可能不支持多磁盘访问。
- 更好的性能: 始终是一个问题,设计者总是试图简化系统以获得更好的性能来降低功耗和降低成本。
19.1.5 实用机器架构
下面阐述一下不同类型的实用机器的设计及架构。
- 哈佛架构
哈佛体系架构下图所示,有单独的结构来维护指令表和内存。指令表也被称为指令存储器,因为可以把它看作是专门为只保存指令而设计的专用存储器。内存保存程序所需的数据值,因此被称为数据存储器。处理指令的引擎分为两部分:控制和ALU,控制单元的工作是获取指令、处理指令并协调指令的执行。ALU代表算术逻辑单元,有专门的电路,可以计算算术表达式或逻辑表达式(and/or/NOT等)。

请注意,每台计算机都需要从用户/编程器处获取输入,并最终将结果传回编程器,可通过多种方法实现,例如我们如今使用的键盘和显示器。早期的计算机使用一组开关,最终结果打印在一张纸上。
- 冯诺依曼架构
约翰·冯·诺依曼提出了通用图灵完全计算机的冯·诺伊曼体系结构,实际上,Eckert和Mauchly于1946年基于该架构设计了第一台通用图灵完全计算机(有个小限制),称为ENIAC(电子数字积分器和计算器),该计算机用于计算美国陆军弹道研究实验室的火炮环表,后来在1949年被EDVAC计算机取代,该计算机也被美国陆军的弹道研究实验室使用。
作为ENIAC和EDVAC基础的基本冯·诺依曼架构如下图所示。指令表保存在内存中,图灵机的处理引擎被称为CPU(中央处理单元),包含程序计数器,其工作是获取新指令并执行它们。它有专用的功能单元来计算算术函数的结果,在内存位置加载和存储值,以及计算分支指令的结果。最后,与哈佛体系结构一样,CPU连接到I/O子系统。

这台机器的创新之处在于指令表存储在内存中,使用通常存储在内存中的同一组符号对每条指令进行编码。例如,如果内存存储十进制值,则每条指令都需要编码为十进制数字串。冯·诺依曼CPU需要解码每条指令,这个想法的核心是,指令被视为常规数据(内存值)。这个简单的想法实际上是设计优雅计算系统的一个非常强大的工具,被称为存储程序概念。
存储程序概念(stored program concept):程序存储在内存中,指令被视为常规内存值。
存储程序概念极大地简化了计算机的设计。由于内存数据和指令在概念上是以相同的方式处理的,所以我们可以有一个统一的处理系统和一个以相同方式处理指令和数据的内存系统。从CPU的角度来看,程序计数器指向一个通用内存位置,其内容将被解释为编码指令的内容,很容易存储、修改和传输程序,程序还可以在运行时通过修改自身甚至其他程序来动态更改其行为。这构成了当今复杂编译器的基础,这些编译器将高级C程序转换为机器指令。此外,许多现代系统(如Java虚拟机)动态地修改它们的指令以实现效率。
冯·诺伊曼机器或哈佛机器不像图灵机器那样拥有无限的内存,严格地说,它们并不完全等同于图灵机,对于所有实用的机器都是如此,它们需要足够的资源。然而,科学界已经学会接受这种近似。
19.2 计算机硬件基础
19.2.1 汇编语言
汇编语言可以广泛地定义为机器指令的文本表示。在构建处理器之前,我们需要了解不同机器指令的语义,在这方面,对汇编语言的严格研究将是有益的。汇编语言专用于ISA和编译器框架,因此,汇编语言有许多优点。本节将描述不同汇编语言变体的基本原理,一些通用概念和术语。随后,将描述针对基于ARM的处理器的ARM汇编语言,描述针对Intel/AMD处理器的x86汇编语言。
19.2.1.1 为什么用汇编语言?
先从软件开发者的视角阐述之。
人类懂得自然语言,如中文、英语和西班牙语。通过一些额外的训练,人类还可以理解计算机编程语言,如C或Java。然而,如前面所述,计算机是一台愚蠢的机器,不够聪明,无法理解人类语言(如英语)或编程语言(如C)中的命令,它只能理解零和一。因此,要给计算机编程,必须给它一个0和1的序列。事实上,一些早期的程序员曾经通过打开或关闭一组开关来编程计算机,打开一个开关对应于1,打开它意味着0。对于今天的大规模数百万行程序来说,不是一个可行的解决方案,需要另寻更好的方法。
因此,我们需要一个自动转换器,它可以将用C或Java等高级语言编写的程序转换为一系列0和1,称为机器代码(machine code)。机器代码包含一组称为机器指令的指令,每个机器指令都是由零和一组成的序列,并指示处理器执行特定的操作。可以将用高级语言编写的程序转换为机器代码的程序称为编译器(见下图)。

编译过程。
请注意,编译器是一个可执行程序,通常在应该为其生成机器代码的机器上运行。可能出现的一个自然问题是——谁编写了第一个编译器?
第一,鉴于编译器的普遍存在,几乎所有的程序都是用高级语言编写的,编译器用来将它们转换为机器代码,但这一规则也有重要的例外。请注意,编译器的作用有两方面:首先,它需要正确地将高级语言的程序翻译成机器指令;其次,它需要生成不占用大量空间且速度快的高效机器代码。因此,多年来编译器中的算法变得越来越复杂,但并不总是能够满足这些要求,例如在某些情况下,编译器可能无法生成足够快的代码,或者无法提供程序员期望的某种功能:
- 首先,编译器中的算法受到它们对程序执行的分析量的限制。例如,我们不希望编译过程极其缓慢,编译器领域的许多问题在计算上很难解决,因此很耗时。
- 其次,编译器不知道代码中的广泛模式。例如,某个变量可能只取一组有限的值,在此基础上,可能进一步优化机器代码,编译器很难理解这一点。聪明的程序员有时可以生成比编译器更优化的机器代码,因为他们知道一些广泛的执行模式,可以胜过编译器。
- 处理器供应商也可能在ISA中添加新指令。在这种情况下,用于旧版本处理器的编译器可能无法利用新指令,需要在程序中手动添加它们。流行的编译器(如gcc,GNU编译器集合)是相当通用的,它们不使用处理器在生成机器代码时提供的所有可能的机器指令。通常,操作系统和设备驱动程序(与打印机和扫描仪等设备接口的程序)需要大量遗漏的指令,因为它们需要对硬件的低级别访问,因此系统程序员有强烈的动机偶尔绕过编译器。
在所有这些情况下,程序员都有必要在程序中手动嵌入一系列机器指令。如上所述,这样做的两个主要原因是效率和额外的功能。因此,从系统软件开发人员的角度来看,有必要了解机器指令,以便他们在工作中更有效率。
现在,我们的目标是让现代程序员远离0和1的复杂细节。理想情况下,我们不希望程序员像50年前那样通过手动打开和关闭开关来编程,由此开发了一种称为汇编语言的低级语言。汇编语言是机器代码的一种人类可读形式,每个汇编语言语句通常对应于一条机器指令。此外,它通过不强迫程序员记住编码指令所需的0/1的确切序列,大大减轻了程序员的负担。
- 低级编程语言(low level programming language)使用通常只对应于一条机器指令的简单语句,这些语言是ISA特有的。
- 汇编语言(assembly language)是指一系列特定于每个ISA的低级编程语言,具有由一系列汇编语句组成的泛型结构。通常,每个汇编语句有两部分:
- 一个指令代码,是基本机器指令的助记符。
- 一个操作数列表。
从实际角度来看,可以编写独立的汇编程序,并使用称为汇编器的程序将其转换为可执行程序,也可以在高级语言(如C或C++)中嵌入汇编代码片段,后者更为常见。
汇编器(assembler)是将汇编程序转换为机器代码的可执行程序。
编译器确保能够将组合程序编译为机器代码。汇编语言的好处是多方面的:
- 可读性。因为汇编代码中的每一行对应于一条机器指令,所以它和机器代码一样具有表达力。
- 高效性。由于这种一对一的映射,我们不必通过在汇编中编写程序来提高效率。
- 简化性。它是一种可读的、优雅的文本表示机器代码的形式,大大简化了使用它编写程序的过程,也可以在用C等高级语言编写的软件中清晰地嵌入汇编代码片段,它定义了一个高于实际机器代码的抽象级别。两个处理器可能与同一种汇编语言兼容,但实际上对同一条指令有不同的机器编码。在这种情况下,汇编程序将在这两个处理器上兼容。
再从硬件设计者的视角阐述之。
硬件设计师的职责是设计能够实现ISA中所有指令的处理器。他们的主要目标是设计一个在面积、功率效率和设计复杂性方面最佳的高效处理器,从他们的角度来看,ISA是软件和硬件之间的关键纽带。这回答了他们的基本问题——构建什么?因此,对他们来说,理解不同指令集的精确语义是非常重要的,这样他们就可以为它们设计处理器。将指令仅仅看作一个0和1的序列是很麻烦的,通过查看机器指令的文本表示,他们可以获得很多好处,很清晰地知道是一条怎样的汇编指令。
汇编语言专用于指令集和汇编器。本节使用流行的GNU汇编器的汇编语言格式来解释典型汇编语言文件的语法,请注意,其他系统具有类似的格式,并且概念大致相同。
19.2.1.2 汇编语言基础
机器模型
汇编语言不将指令存储器和数据内存视为不同的实体,假设一个抽象的冯·诺依曼机器增加了寄存器。
有关机器模型的图示,请参见下图。程序存储在主内存的一部分中,中央处理单元(CPU)逐条指令读出程序指令,并适当地执行指令,程序计数器(PC)跟踪CPU正在执行的指令的内存地址,大多数指令都希望从寄存器中获取其输入操作数。回想一下,每个CPU都有固定数量的寄存器(通常<64),然而大量指令也可以直接从内存中获取操作数。CPU的工作是协调主存和寄存器之间的传输,CPU还需要执行所有算术/逻辑计算,并与外部输入/输出设备保持联系。

大多数类型的汇编语言在大多数语句中都采用这种抽象机器模型。但由于使用汇编语言的另一个目的是对硬件进行更细粒度和侵入性的控制,因此有相当多的汇编指令可以识别处理器的内部。
这些指令通常通过改变一些关键内部算法的行为来修改处理器的行为,它们修改内置参数,如电源管理设置,或读/写一些内部数据。最后请注意,汇编语言不区分机器无关指令和机器相关指令。
每台机器都有一组寄存器,这些寄存器对汇编程序员是可见的。ARM有16个寄存器,x86(32位)有8个寄存器,而x86_64(64位)有16个。寄存器有名称,ARM将它们命名为r0、r1、...、r14、r15,x86将它们命名成eax、ebx、ecx、edx、esi、edi、ebp和esp,可以使用这些名称访问寄存器。
在大多数ISA中,返回地址寄存器用于函数调用。让我们假设一个程序开始执行一个函数,它需要记住执行函数后需要返回的内存地址,此地址称为返回地址。在跳转到函数的起始地址之前,我们可以将返回地址的值保存在这个寄存器中。通过将保存在返回地址寄存器中的值复制到PC上,可以简单地实现返回语句。在ARM和MIPS等汇编语言中,程序员可以看到返回地址寄存器,然而x86不使用返回地址寄存器,使用堆栈。
在ARM处理器中,程序员可以看到PC,它是最后一个寄存器(r15)。可以读取PC的值,也可以设置其值,设置PC的值意味着我们希望分支到程序中的新位置。然而x86的PC是隐式的,程序员不可见。
内存视图
内存可以看作是一个大的字节数组,每个字节都有一个唯一的地址,基本上就是它在数组中的位置。第一字节的地址是0,第二字节的地址为1,以此类推。我们没有一种方法来唯一地寻址给定的位,地址在32位机器中是32位无符号整数,在64位机器中则是64位无符号。
在冯·诺依曼机器中,我们假设程序作为字节序列存储在内存中,程序计数器指向将要执行的下一条指令。
假设内存是一个大的字节数组,如果我们所有的数据项都只有一个字节长,那么就可以了,像C和Java这样的语言有不同大小的数据类型:char(1字节)、short(2字节)、integer(4字节)和long integer(8字节)。对于多字节数据类型,必须在内存中为其创建一个表示,在内存中表示多字节数据类型有两种可能的方式——小端和大端。其次,我们还需要找到表示内存中数据数组或列表的方法。
- 小端和大端表示
让我们考虑在位置0-3存储整数的问题。让整数为0x87654321,它可以分为四个字节:87、65、43和21。一个选项是将最重要的字节87存储在最低的内存地址0中,下一个位置可以存储65、43、21,这被称为大端(big endian)表示,因为我们从最大字节的位置开始。相比之下,我们可以先将最小的字节保存在位置0,然后继续将最大的字节存储在位置3,这种表示方式称为小端(big endian)。下图显示了差异。

大端和小端表示。
因此,没有理由选择一种代表而不是另一种代表,例如,x86处理器使用little-endian格式。早期版本的ARM处理器曾经是小端的,然而,现在它们是双端的,意味着ARM处理器可以根据用户设置同时作为小端和大端机器工作。传统上,IBM POWER处理器和Sun SPARC处理器都是大端的。
- 表示数组
数组是一组线性有序的对象,其中对象可以是简单的数据类型(如整数或字符),也可以是复杂的数据类型。
int a[100];
char c[100];
让我们考虑一个简单的整数数组a。如果数组有100个条目,那么内存中数组的总大小等于100 4=400字节。如果数组的起始内存位置为loc,然后将[0]存储在位置(loc + 0)、(loc + 1)、(loc + 2)、(loc + 3)中。请注意,有大端和小端两种方法保存数据。下一个数组条目a[1]保存在位置(loc + 4) ... (loc + 7)中,依此类推,我们注意到条目a[i]保存在(loc + 4 x i) ... (loc + 4 x i + 3)中。
大多数编程语言都定义以下形式的多维数组:
int a[100][100];
char c[100][100];
它们通常在内存中表示为规则的一维数组,多维数组中的位置与等效的一维数组之间存在映射函数,我们可以扩展该方案以考虑维度大于2的多维数组。
我们观察到,通过以行优先(row major)方式保存二维数组,可以将其保存为一维数组,意味着数据按行保存。我们保存第一行,然后保存第二行,以此类推。同样,也可以以列优先(column major)的方式保存多维数组,其中保存第一列,然后再保存第二列,依此类推。
行优先(row major):数组按行保存在内存中。
列优先(column major):数组按列保存在内存中。
19.2.1.3 汇编语言语法
汇编文件的确切语法取决于汇编程序,不同的汇编程序可以使用不同的语法,尽管它们可能在基本指令及其操作数格式上达成一致。本节将解释GNU系列汇编语言的语法,它们是为GNU汇编程序设计的,是GNU编译器集合(gcc)的一部分。与所有GNU软件一样,该汇编程序和相关编译器可免费用于大多数平台,汇编程序可在gnu.org上找到。请注意,其他汇编程序(如NASM、MASM)都有自己的格式,但总体结构在概念上与本节描述的没有太大区别。
汇编文件结构
程序集文件是一个常规文本文件,后缀是.s。如果安装了GNU编译器gcc,则可以通过发出以下命令快速生成C程序的汇编文件,当然也可以使用在线GCC。
gcc -S test.c
生成的程序集文件将命名为test.s。GNU程序集的结构非常简单,如下图所示。不同部分的示例包括文本(实际程序)、数据(具有初始化值的数据)和bss(初始化为0的通用数据)。每个段(section)以节标题开头,这是以“.”开头的节的名称符号,例如,文本部分以“.text”行开头。接着是汇编语言语句列表,每条语句通常以换行符结尾,同样,数据部分包含数据值列表。
汇编文件以包含格式为“.file <文件名>”的行的文件段开头。当我们使用gcc编译器从C程序生成程序集文件时,.file部分中的文件名通常与我们的原始C程序(test.C)相同。文本段是必填的,其余段是可选的,可能有一个或多个数据段,也可以使用.section指令定义新的节。本节我们主要关注文本部分,因为对学习指令集的本质感兴趣。

汇编语言文件结构。
汇编基本语句
一条基本的汇编语言语句指定了一条汇编指令,有两部分:指令及其操作数列表,如下图所示。该指令是实际机器指令的文本标识符,操作数列表包含每个操作数的值或位置。操作数的值是一个数值常量,也被称为立即值(immediate value),操作数位置可以是寄存器位置或内存位置。

汇编语言语句。
在计算机架构中,指令中指定的常数值也称为立即数(immediate)。
假设有以下语句:
add r3, r1, r2
在这个ARM汇编语句中,add指令指定了我们希望将两个数字相加并将结果保存在某个预先指定的位置的事实。在这种情况下,加法指令的格式如下:<指令><目标寄存器><操作数寄存器1><操作数寄存器2>。指令的名称为add,目标寄存器为r3,操作数寄存器为r1和r2。指令的详细步骤如下:
1.读取寄存器r1的值。让我们将该值称为v1。
2.读取寄存器r2的值。让我们将该值称为v2。
3.计算v3=v1+v2。
4.将v3保存在寄存器r3中。
现在让我们再举一个以类似方式工作的两条指令的示例:
sub r3, r1, r2
mul r3, r1, 3
sub指令减去存储在寄存器中的两个数,mul指令将存储在寄存器r1中的一个数乘以数值常数3,这两条指令都将结果保存在寄存器r3中,它们的操作模式与加法指令类似。此外,算术指令(如add、sub和mul)也称为数据处理指令。还有其他几类指令,例如从内存加载或存储值的数据传输指令,以及实现分支的控制指令。
通用语句结构
汇编语句的一般结构如下图所示,它由三个字段组成:标签(指令的标识符)、键(汇编指令或汇编程序指令)和注释。这三个字段都是可选的,但是,任何汇编语句都需要至少具有其中一个。

汇编语句的通用结构。
语句可以选择以标签开头,标签是语句的文本标识符,换句话说,标签在汇编中唯一地标识汇编语句。请注意,我们不允许在同一汇编文件中重复标签,标签在执行分支指令时非常有用。
下面的示例代码中显示了一个标签的示例,这里标签的名称是“label1”,后面是冒号。在标签之后,我们编写了一条汇编指令,并给它一个操作数列表。标签可以由有效的字母数字字符[a-z] [A-Z] [0-9] 以及符号“.”、“_”和“$”。通常,我们不能以数字作为标签的开头。在指定标签之后,我们可以将该行保持为空,也可以指定键(汇编语句的一部分)。如果键以“.”开头,那么它是一个汇编程序指令,对所有计算机都有效,它指示汇编程序执行某个操作,此操作可以包括启动新节或声明常量。该指令还可以采用参数列表,如果键以字母开头,则它是一条常规的汇编指令。
label1: add r1, r2, r3
在标签、汇编指令和操作数列表之后,可以选择插入注释。GNU汇编程序支持两种类型的注释,我们可以在插入类似C或Java风格的注释。在ARM汇编中,通过在注释前面加上“@”字符,也可以有一个小的单行注释。
label1: add r1, r2, r3 @ Add the values in r2 and r3
label2: add r3, r4, r5 @ Add the values in r4 and r5
add r5, r6, r7 /* Add the values in r6 and r7 */
汇编语句可能只包含标签,而不包含键。在这种情况下,标签本质上指向一个空语句,不是很有用。因此,汇编程序假定在这种情况下,标签指向最近的包含键的后续汇编语句。
19.2.1.4 指令类型
按功能分类
按功能,可分为四种主要类型,说明如下:
- 数据处理指令:数据处理指令通常是算术指令,如加法、减法和乘法,或按位或、异或计算的逻辑指令,比较指令也属于这个类型。
- 数据传输指令:这些指令在两个位置之间传输值,位置可以是寄存器或内存地址。
- 分支指令:分支指令帮助处理器的控制单元根据操作数的值跳转到程序的不同部分,在实现for循环和if-then-else语句时很有用。
- 异常生成指令:这些专用指令有助于将控制权从用户级程序转移到操作系统。
我们将介绍数据处理、数据传输和控制指令。
按操作数分类
GNU汇编程序中的所有汇编语言语句都具有相同的结构,它们以指令的名称开头,后面是操作数列表。我们可以根据指令所需的操作数对其进行分类,如果一条指令需要n个操作数,那么通常称它是n地址格式,例如,不需要任何操作数的指令是0地址格式指令,如果它需要3个操作数,则它是3地址格式指令。
如果一条指令需要n个操作数(包括源和目标),那么我们称其为n地址格式指令。
在ARM中,大多数数据处理指令采用3地址格式,数据传输指令采用2地址格式。然而,在x86中,大多数指令都是2地址格式。我们想到的第一个问题是,3地址格式指令与2地址格式指令的逻辑是什么?这里一定有一些权衡。
让我们阐述一些一般的经验法则。如果一条指令有更多的操作数,那么它将需要更多的位来表示该指令,因此需要更多的资源来存储和处理指令。然而,这一论点有另一面,拥有更多的操作数也会使指令更加通用和灵活,将使编译器编写者和汇编程序员的生活变得更加轻松,因为使用更多操作数的指令可以做更多的事情。反向逻辑适用于占用较少操作数的指令,占用更少的存储空间,也不那么灵活。
让我们考虑一个例子。假设我们试图将两个数字3和5相加,得到结果8。用于添加的ARM指令如下所示:
add r3, r1, r2
此指令将寄存器r1(3)和r2(5)的内容相加,并将其保存在r3(8)中。然而,x86指令如下所示:
add edx, eax
此处假设edx包含3,eax包含5,执行加法,结果8存储回edx。因此,在这种情况下,x86指令采用2地址格式,因为目标寄存器与第一源寄存器相同。
19.2.1.5 操作数类型
现在让我们看看不同类型的操作数,在汇编语句中指定和访问操作数的方法称为寻址模式。
在汇编语句中指定和访问操作数的方法称为寻址模式(addressing mode)。
指定操作数的最简单方法是将其值嵌入指令中,大多数汇编语言允许用户将整数常量的值指定为操作数,这种寻址模式被称为立即寻址模式(immediate addressing mode),此方法对于初始化寄存器或内存位置或执行算术运算非常有用。
一旦必需的常数集被加载到寄存器和内存位置,程序就需要通过对寄存器和内存进行操作来继续,这个空间有几种寻址模式。在介绍它们之前,让我们以寄存器转移符号(register transfer notation)的形式介绍一些额外的术语。
寄存器转移符号
这个符号允许我们指定指令和操作数的语义,让我们看看表示指令基本动作的各种方法:
r1←r2r1←r2
此表达式有两个寄存器操作数r1和r2,r1是目标寄存器,r2是源寄存器,我们正在将寄存器r2的内容转移到寄存器r1。我们可以用一个常数指定一个加法运算,如下所示:
r1←r2+4r1←r2+4
我们还可以使用此符号指定寄存器上的操作,将r2和r3的内容相加,并将结果保存在r1中:
r1←r2+r3r1←r2+r3
也可以使用此符号表示内存访问:
r1←[r2+4]r1←[r2+4]
上述语句中,内存地址等于寄存器r2的内容加4,然后从该内存地址的内容开始提取整数,并将其保存在寄存器r1中。
操作数的通用寻址模式
让我们将操作数的值表示为V。在随后的讨论中,我们使用了V←r1V←r1等表达式,并不意味着我们有一个新的称为V的存储位置,意味着操作数的数值由RHS指定(右侧)。让我们通过示例简要地看一下一些最常用的寻址模式:
- 立即:V←immV←imm。使用常量imm作为操作数的值。
- 寄存器:V←r1V←r1。在此寻址模式下,处理器使用寄存器中包含的值作为操作数。
- 寄存器间接:V←[r1]V←[r1]。寄存器保存包含该值的内存位置的地址。
- 基准偏移量:V←[r1+offset]V←[r1+offset]。offset是一个常数,处理器从r1获取基本内存地址,将常量offset添加到该地址,然后访问新的内存位置以获取操作数的值。offset也称为位移。
- 基址变址:V←[r1+r2]V←[r1+r2]。r1是基址寄存器,r2是索引寄存器,存储器地址等于(r1+r2)。
- 基址变址偏移:V←[r1+r2+offset]V←[r1+r2+offset]。包含该值的内存地址为(r1+r2+offset),其中offset为常数。
- 内存直接:V←addrV←addr。该值从地址addr开始包含在内存中,addr是一个常数。在这种情况下,存储器地址直接嵌入指令中。
- 内存间接:V←[[r1]]V←[[r1]]。该值存在于存储器位置中,其地址包含在内存位置M中,M的地址包含在寄存器r1中。
- PC相关:V←[PC+offset]V←[PC+offset]。offset量是一个常数,内存地址计算为PC+offset,其中PC表示PC中包含的值。此寻址模式对分支指令很有用,注意此处的PC是指程序计数器。
让我们通过考虑基偏移寻址模式来引入一个称为有效内存地址(effective memory address)的新术语。内存地址等于基址寄存器的内容加上偏移量,计算出的内存地址称为有效内存地址。在内存操作数的情况下,我们可以类似地为其他寻址模式定义有效地址。

多种寻址模式。

x86寻址模式计算。
19.2.1.6 常见指令说明
本小节将以ARM为基准,阐述常见的RISC指令用法。
数据传输指令
数据传输指令包含以下几类:
- LDR和STR
可加载寄存器和存储寄存器,包含32位字、8位无符号字节、半字、无符号字节、双字等。
LDR和STR都有四种可能的形式:零偏移量、预索引偏移、程序相关、后索引偏移。四种形式的语法顺序相同,分别为:
op{cond}{B}{T} Rd, [Rn]
op{cond}{B} Rd, [Rn, FlexOffset]{!}
op{cond}{B} Rd, label
op{cond}{B}{T} Rd, [Rn], FlexOffset
以上是针对32位字或8位无符号字节,如果需要双字则B改成D:
op{cond}D Rd, [Rn]
op{cond}D Rd, [Rn, Offset]{!}
op{cond}D Rd, label
op{cond}D Rd, [Rn], Offset
半字、有符号字节语法如下:
op{cond} type Rd, [Rn]
op{cond} type Rd, [Rn, Offset]{!}
op{cond} type Rd, label
op{cond} type Rd, [Rn], Offset
示例:
; 示例1
SUB R1, PC, #4 ; R1 = address of following STR instruction
STR PC, [R0] ; Store address of STR instruction + offset,
LDR R0, [R0] ; then reload it
SUB R0, R0, R1 ; Calculate the offset as the difference
; 示例2
LDRD r6,[r11]
LDRMID r4,[r7],r2
STRD r4,[r9,#24]
STRD r0,[r9,-r2]!
LDREQD r8,abc4
; 示例3
LDREQSH r11,[r6] ; (conditionally) loads r11 with a 16-bit halfword from the address in r6. Sign extends to 32 bits.
LDRH r1,[r0,#22] ; load r1 with a 16 bit halfword from 22 bytes above the address in r0. Zero extend to 32 bits.
STRH r4,[r0,r1]! ; store the least significant halfword from r4 to two bytes at an address equal to contents(r0) plus contents(r1). Write address back into r0.
LDRSB r6,constf ; load a byte located at label constf. Sign extend.
- LDM和STM
LDM、STM加载和存储多个寄存器,寄存器r0到r15的任何组合都可以被传送。语法如下:
op{cond}mode Rn{!}, reglist{^}
示例:
LDMIA r8,{r0,r2,r9}
STMDB r1!,{r3-r6,r11,r12}
STMFD r13!,{r0,r4-r7,LR} ; Push registers including the stack pointer
LDMFD r13!,{r0,r4-r7,PC} ; Pop the same registers and return from subroutine
- PLD
PLD缓存预加载。语法:
PLD [Rn{, FlexOffset}]
示例:
PLD [r2]
PLD [r15,#280]
PLD [r9,#-2481]
PLD [r0,#av*4] ; av * 4 must evaluate, at assembly time, to an integer in the range -4095 to +4095
PLD [r0,r2]
PLD [r5,r8,LSL 2]
- SWP
在寄存器和存储器之间交换数据,使用SWP实现信号量。语法:
SWP{cond}{B} Rd, Rm, [Rn]
通用数据处理指令
此类指令又包含以下几种:
- 灵活第二操作数
大多数ARM通用数据处理指令都有一个灵活的第二操作数,在每条指令的语法描述中显示为Operand2。语法有两种形式:
#immed_8r
Rm{, shift}
示例:
ADD r3,r7,#1020 ; immed_8r. 1020 is 0xFF rotated right by 30 bits.
AND r0,r5,r2 ; r2 contains the data for Operand2.
SUB r11,r12,r3,ASR #5 ; Operand2 is the contents of r3 divided by 32.
MOVS r4,r4, LSR #32 ; Updates the C flag to r4 bit 31. Clears r4 to 0.
- ADD、SUB、RSB、ADC、SBC和RSC
此类指令的语法如下:
op{cond}{S} Rd, Rn, Operand2
示例:
ADD r2,r1,r3
SUBS r8,r6,#240 ; sets the flags on the result
RSB r4,r4,#1280 ; subtracts contents of r4 from 1280
ADCHI r11,r0,r3 ; only executed if C flag set and Z flag clear
RSCLES r0,r5,r0,LSL r4 ; conditional, flags set
- AND、ORR、EOR和BIC
逻辑操作,语法如下:
op{cond}{S} Rd, Rn, Operand2
示例:
AND r9,r2,#0xFF00
ORREQ r2,r0,r5
EORS r0,r0,r3,ROR r6
BICNES r8,r10,r0,RRX
- MOV、MVN、CMP、CMN、TST、TEQ、CLZ
移动、对比、测试、计数前导零指令,语法如下:
MOV{cond}{S} Rd, Operand2
MVN{cond}{S} Rd, Operand2
CMP{cond} Rn, Operand2
CMN{cond} Rn, Operand2
TST{cond} Rn, Operand2
TEQ{cond} Rn, Operand2
CLZ{cond} Rd, Rm
示例:
MOV r5,r2
MVNNE r11,#0xF000000B
MOVS r0,r0,ASR r3
CMP r2,r9
CMN r0,#6400
CMPGT r13,r7,LSL #2
TST r0,#0x3F8
TEQEQ r10,r9
TSTNE r1,r5,ASR r1
CLZ r4,r9
CLZNE r2,r3
算术指令
算术指令包含大量的乘法指令,乘法的指令较多较复杂。常见算术指令如下表所示:
| 指令 | 语法 | 说明 |
|---|---|---|
| MUL、MLA | MUL{cond}{S} Rd, Rm, Rs MLA{cond}{S} Rd, Rm, Rs, Rn | 乘法和乘法累加(32位乘32位,取底部32位结果) |
| UMULL、UMLAL、SMULL、SMLAL | Op{cond}{S} RdLo, RdHi, Rm, Rs | 无符号和有符号长乘法和乘法累加(32位乘32位,64位累加或结果)。 |
| SMULxy、SMLAxy、SMULWy、SMLAWy、SMLALxy | SMLA{cond} Rd, Rm, Rs, Rn SMULW{cond} Rd, Rm, Rs SMLAW{cond} Rd, Rm, Rs, Rn | 有符号乘法(16、32位乘16、32位,结果是32位或64位,部分指令有累积)。 |
| MIA、MIAPH、MIAxy | MIA{cond} Acc, Rm, Rs MIA{cond} Acc, Rm, Rs | XScale协处理器0指令。 |
示例:
MUL r10,r2,r5
MLA r10,r2,r1,r5
MULS r0,r2,r2
MULLT r2,r3,r2
MLAVCS r8,r6,r3,r8
UMULL r0,r4,r5,r6
UMLALS r4,r5,r3,r8
SMLALLES r8,r9,r7,r6
SMULLNE r0,r1,r9,r0 ; Rs can be the same as other registers
SMLAWB r2,r4,r7,r1
SMLAWTVS r0,r0,r9,r2
MIA acc0,r5,r0
MIALE acc0,r1,r9
MIAPH acc0,r0,r7
MIAPHNE acc0,r11,r10
MIABB acc0,r8,r9
MIABT acc0,r8,r8
MIATB acc0,r5,r3
MIATT acc0,r0,r6
MIABTGT acc0,r2,r5
分支指令
分支语句的描述如下表:
| 指令 | 语法 | 说明 |
|---|---|---|
| B、BL | B/BL {cond} label | 分支和带链接的分支 |
| BX | BX{cond} Rm | 分支和交换指令集 |
| BLX | BLX{cond} Rm BLX label | 使用Link分支,并可选地交换指令集。本说明有两种可选形式: 1、链接到程序相对地址的无条件分支 2、与寄存器中保存的绝对地址链接的条件分支。 |
示例:
B loopA
BLE ng+8
BL subC
BLLT rtX
BX r7
BXVS r0
BLX r2
BLXNE r0
BLX thumbsub
条件执行
几乎所有ARM指令都可以包含可选条件代码。这在语法描述中显示为{cond}。只有当CPSR中的条件代码标志满足指定条件时,才执行带有条件代码的指令。可以使用的条件代码如下表所示(部分)。
| 后缀 | 标记 | 含义 |
|---|---|---|
| EQ | Z设置 | = |
| NE | Z清除 | != |
| CS、HS | C设置 | >=(无符号) |
| CC、LO | C清除 | =(无符号) |
| MI | N设置 | 负数 |
| PL | N清除 | 非负数 |
| VS | V设置 | 溢位 |
| VC | V清除 | 无溢位 |
| HI | C设置且Z清除 | >(无符号) |
| LS | C清除或Z设置 | <=(无符号) |
| GE | N和V一样 | >=(有符号) |
| LT | N和V不一样 | <(有符号) |
| GT | Z清除且N和V一样 | >(有符号) |
| LE | Z设置或N和V不一样 | <=(有符号) |
| AL | 任意 | 总是(通常省略) |
几乎所有ARM数据处理指令都可以根据结果选择性地更新条件代码标志。要使指令更新标志,请包含S后缀,如指令的语法描述所示。
有些指令(CMP、CMN、TST和TEQ)不需要S后缀,它们的唯一功能是更新标志,总是更新标志。
标志将保留到更新,未执行的条件指令对标志没有影响,一些指令更新标志的子集,其他标志不受这些指令的影响。详细信息在说明说明中指定。可以根据另一条指令中设置的标志,有条件地执行指令,或者:
- 紧接在更新标志的指令之后。
- 在没有更新标志的任何数量的介入指令之后。
示例:
ADD r0, r1, r2 ; r0 = r1 + r2, don't update flags
ADDS r0, r1, r2 ; r0 = r1 + r2, and update flags
ADDCSS r0, r1, r2 ; If C flag set then r0 = r1 + r2, and update flags
CMP r0, r1 ; update flags based on r0-r1.
其它指令
ARM还有协调处理器、伪指令、杂项指令等其它指令,本文限于篇幅就不接受了。更多详情参见:
19.2.2 二进制位
计算机不像人类那样理解单词或句子,只理解0和1的序列,存储、检索和处理数十亿个0和1非常容易。其次,使用硅晶体管(silicon transistor)实现计算机的现有技术与处理0和1的概念非常兼容。基本硅晶体管是一种开关,可以根据输入将输出设置为逻辑0或1,硅晶体管是我们今天拥有的所有电子计算机的基础,从手机的处理器到超级计算机的处理器。十九世纪末制造的一些早期计算机处理十进制数字,本质上大多是机械的。首先让我们明确定义一些简单的术语:
位(bit):可以有两个值的变量:0或1。
字节(byte):8个位的序列。
19.2.2.1 逻辑操作
二进制变量(0或1)最早由乔治·布尔(George Boole)于1854年描述,他使用这些变量及其相关运算来描述数学意义上的逻辑,他设计了一个完整的代数,由简单的二元变量、一组新的运算符和基本运算组成。为了纪念乔治·布尔,二进制变量也称为布尔变量(Boolean variable),布尔变量的代数系统称为布尔代数(Boolean algebra)。逻辑位操作如下:
- NOT
逻辑补码(logical complement)称为NOT运算符,任何布尔运算符都可以通过真值表来表示,真值表列出了所有可能的输入组合的运算符输出,NOT运算符的真值表如下表所示。
| 原始值 | NOT操作后 |
|---|---|
| 0 | 1 |
| 1 | 0 |
- OR
OR运算符表示任一操作数等于1的事实。例如,如果A=1或B=1,则A或B等于1。OR运算符的真值表如下所示。
| A | B | A OR B |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 1 |
- AND
AND运算符的操作是所有操作数为1,则结果才为1,其它则为0。例如,当A和B都为1时,A和B等于1。AND运算符的真值表如下所示。
| A | B | A AND B |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 0 |
| 1 | 0 | 0 |
| 1 | 1 | 1 |
- NAND、NOR
另外的两个简单的运算符,即NAND和NOR非常有用。NAND是AND的逻辑补码,NOR是OR的逻辑补。它们的真值表如下所示。
| A | B | A NAND B | A NOR B |
|---|---|---|---|
| 0 | 0 | 1 | 1 |
| 0 | 1 | 1 | 0 |
| 1 | 0 | 1 | 0 |
| 1 | 1 | 0 | 0 |
NAND和NOR是非常重要的运算符,因为它们被称为通用运算符,我们可以只使用它们来构造任何其他运算符。
- XOR
XOR是异或运算符,当A和B相等时,值为0,否则为1。真值表如下所示。
| A | B | A XOR B |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
19.2.2.2 布尔代数
让我们来看看NOT运算符的一些规则:
- 定义:¯¯¯0=1, 且 ¯¯¯1=00¯=1, 且 1¯=0,即NOT运算符的定义。
- 双重否定:¯¯¯¯¯¯¯¯A=AA¯¯=A,非A的非等于A本身。
OR和AND运算符:
- 恒等式:A+0=A,A.1=A,亦即如果计算布尔变量A与0的OR或与1的AND,结果等于A。
- 相消性:A+1=1,A.0=0,亦即如果计算A OR 1,那么结果总是等于1。类似地,A AND 0总是等于0,因为第二个操作数的值决定了最终结果。
- 幂等性:A+A=A,A.A=A,亦即计算A与自身的OR或AND的结果为A。
- 互补性:A+¯¯¯¯AA¯=1,A.¯¯¯¯AA¯=0,亦即A=1或¯¯¯¯AA¯=1。在任何一种情况下,A+¯¯¯¯AA¯都有一个项,它是1,因此结果是1。同样,A.¯¯¯¯AA¯中的一个项是0,因此结果为0。
- 交换性:A.B=B.A,A+B=B+A,亦即布尔变量的顺序无关紧要。
- 关联性:A+(B+C) = (A+B)+C,以及A.(B.C)=(A.B).C。
- 分配性:A.(B+C) = A.B+A.C,A+B.C=(A+B).(A+C),亦即可以使用这个定律来打开括号并简化表达式。
我们可以使用这些规则以各种方式操作包含布尔变量的表达式,下面看看布尔代数中的一组基本定理。
- 摩根定律(De Morgan's Laws)
有两个摩根定律可以通过构造LHS和RHS的真值表来验证。
¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯A+B=¯¯¯¯A.¯¯¯¯B¯¯¯¯¯¯¯¯AB=¯¯¯¯A+¯¯¯¯BA+B¯=A¯.B¯AB¯=A¯+B¯
- 逻辑门(Logic Gate)
现在让我们尝试实现电路来实现复杂的布尔公式,“逻辑门”定义为实现布尔函数的器件,可以由硅、真空管或任何其他材料制成。
逻辑门是实现布尔函数的设备。
给定一组逻辑门,我们可以设计一个电路来实现任何布尔函数,不同逻辑门的符号如下图所示。

逻辑门列表。
19.2.3 晶体管
硅是周期表中的第14种元素,有四个价电子,虽然与碳和锗属于同一组,但其化学反应性不如后两者。
90%以上的地壳由硅基矿物组成,二氧化硅是沙子和石英的主要成分,它供应充足,而且制造起来相当便宜。硅具有一些有趣的特性,使其成为设计电路和处理器的理想衬底。让我们考虑一下硅的分子结构,它有一个致密的结构,每个硅原子都与其他四个硅原子相连,紧密相连的一组硅原子结合在一起形成一个强晶格,其他材料(尤其是金刚石)具有类似的晶体结构。因此,硅原子比大多数金属更紧密。
由于缺乏自由电子,硅没有很好的导电性能,介于良导体和绝缘体之间,因此被称为半导体(semiconductor)。通过可控的方式添加一些杂质,可以稍微改变其性质,这个过程被称为掺杂(doping)。
19.2.3.1 掺杂
通常,向硅中添加两种杂质以改变其特性:n型和p型。n型杂质通常由周期表中的V族元素组成,磷是最常见的n型掺杂剂,偶尔也会使用砷。添加具有价电子的V族掺杂剂的效果是,额外的电子从晶格中分离出来,并可用于传导电流。这种掺杂过程有效地提高了硅的导电性。
同样,可以向硅中添加III族元素,如硼或镓,以产生p型掺杂硅,会产生相反的效果,会在晶格中创建一个空隙,此空隙也称为孔(hole),孔表示没有电子。像电子一样,孔可以自由移动,也有助于传导电流。电子带负电荷,孔在概念上与正电荷相关。
现在我们已经制作了两种半导体材料:n型和p型,下面看看如果连接它们形成p-n结会发生什么。
19.2.3.2 P-N结
让我们考虑一个p-n结,如下图所示。p型区有过量的孔,n型区有过剩的电子。在结处,一些孔交叉并移动到n区,因为它们被电子吸引。类似地,一些电子越过并聚集在p区一侧。孔和电子的这种迁移称为扩散,见证这种迁移的交界处周围的区域被称为耗尽区。然而,由于电子和孔的迁移,在耗尽区中产生了与迁移方向相反的电场,这个电场感应出一种称为漂移电流的电流。在稳态下,漂移电流和扩散电流相互平衡,因此实际上没有电流流过结。

如果将p侧连接到正端子,将n侧连接到负端子,则这种配置称为正向偏置。在这种情况下,孔从结的p侧流向n侧,电子则反向流动。因此,该结传导电流。
如果我们将p侧连接到负端子,将n侧连接到正端子,则这种配置称为反向偏置。在这种情况下,孔和电子被拉离结。因此,没有电流流过结,并且在这种情况下p-n结不导电。所描述的简单p-n结被称为二极管(diode),它只在一个方向传导电流,即当它处于正向偏置时。
二极管(diode)是一种典型地由单个p-n结制成的电子器件,其仅在一个方向上传导电流。
19.2.3.3 NMOS晶体管
现在,让我们将两个p-n结相互连接,如下图(a)所示,这种结构被称为NMOS(负金属氧化物半导体)晶体管。在这张图中,有一个p型掺杂硅的中心衬底。两侧有两个小区域含有n型掺杂硅,这些区域分别被称为漏极和源极。注意,由于结构是完全对称的,这两个区域中的任何一个都可以被指定为源极或漏极,源极和漏极中间的区域称为通道。在沟道的顶部有一个通常由二氧化硅(SiO2)制成的薄绝缘层,它由金属或多晶硅基导电层覆盖,就是所谓的门(gate)。

因此,典型的NMOS晶体管有三个端子:源极、漏极和栅极,它们中的每一个都可以连接到电压源。我们现在有两个栅极电压选项——逻辑1(VddVdd伏)或逻辑0(0伏)。如果栅极处的电压为逻辑1(Vdd伏),则沟道中的电子被吸引到栅极。事实上,如果栅极处的电压大于某个阈值电压(在当前技术中通常为0.15V),则由于电子的积累,在漏极和源极之间形成低电阻导电路径。因此,电流可以在漏极和源极之间流动。如果沟道的有效电阻是R沟道,那么我们有Vdrain=IRchannel+VsourceVdrain=IRchannel+Vsource。如果流经晶体管的电流量低,则由于低沟道电阻(R沟道),VdrainVdrain大致等于VsourceVsource。因此,我们可以将NMOS晶体管视为开关(见上图b)。当栅极电压为1时,它被打开。
现在,如果我们将栅极电压设置为0,那么由电子组成的导电路径就无法在沟道中形成。因此,晶体管将不能传导电流,将处于o状态。在这种情况下,开关关闭。
NMOS晶体管的电路符号如上图(c)所示。
19.2.3.4 PMOS晶体管
像NMOS晶体管一样,我们可以有一个PMOS晶体管,如下图(a)所示,源极和漏极是由p型硅构成的区域,晶体管操作的逻辑与NMOS晶体管的逻辑完全相反。在这种情况下,如果栅极处于逻辑0,则空穴被吸引到沟道并形成导电路径。然而,如果栅极处于逻辑1,则孔被沟道排斥,不形成导电路径。
PMOS晶体管也可以被视为开关(图b),当栅极电压为0时,它打开,当栅极处的电压为逻辑1时,它关闭。PMOS晶体管的电路符号如图(c)所示。

19.2.3.5 NAND和NOR门
下图显示了如何在CMOS技术中构建NAND门。两个输入端A和B连接到每个NMOS-PMOS对的栅极,如果A和B都等于1,则PMOS晶体管将关断,NMOS晶体管将导通,将输出设置为逻辑0。但是,如果其中一个输入等于0,则其中一个NMOS晶体管将关闭,其中一个PMOS晶体管将打开。因此,输出将设置为逻辑1。
请注意,我们使用AND运算的运算符“.”,这种符号在表示布尔公式时被广泛使用。同样,对于OR运算,使用“+”符号。

下图显示了如何构建NOR门。在这种情况下,两个输入端A和B也连接到每个NMOS-PMOS对的栅极。然而,与NAND门相比,拓扑结构有所不同。如果其中一个输入为逻辑1,则其中一个NMOS晶体管将导通,其中一个PMOS晶体管将截止,输出将设置为0。如果两个输入都等于0,则两个NMOS晶体将截止,两个PMOS晶体将导通,输出将等于逻辑1。

NAND门的一些用途如下:

NOR门的一些用途如下:

19.2.4 组合逻辑电路
19.2.4.1 XOR门
让我们实现异或(XOR)的逻辑函数,使用运算符进行XOR运算,如果两个输入不相等,则异或操作返回1,否则返回0。已知A⊕B=A⋅¯¯¯¯B+¯¯¯¯A⋅BA⊕B=A⋅B¯+A¯⋅B,则真值表和实现异或门的电路如下所示。

基本逻辑门如下所示:

19.2.4.2 多路复用器和信号分离器
多路复用器(Multiplexer)的框图如下图左所示,采用n个输入位和log(n)个选择位,并根据选择位的值,选择一个输入作为输出(参见图中带箭头的线)。多路复用器在处理器设计中大量使用,我们需要从一组输入中选择一个输出。多路复用器也称为多路复用器。
信号分离器将log(n)位二进制数作为输入,1位输入,并将输入传输到n条输出线中的一条,参见下图右。多路分解器用于存储单元的设计,其中输入必须精确地反映在一条输出线中。

左:单个多路复用器结构图。中:4输入的多路复用器。右:信号分离器。

多路复用器输入至程序计数器。
19.2.4.3 编码器和解码器
解码器将log(n)位二进制数作为输入,并具有n个输出。根据输入,它将其中一个输出设置为1。
解码器的设计如下图左所示,具有两个输入和四个输出的2x4解码器的设计。假设输入是A和B。我们生成所有可能的组合:¯¯¯¯¯¯¯¯AB,¯¯¯¯AB,A¯¯¯¯B,ABAB¯,A¯B,AB¯,AB。这些布尔组合是通过计算A和B的逻辑“非”,然后将这些值路由到一组“与”门来生成的。
现在让我们考虑一个与解码器逻辑相反的电路,其框图如下图右所示。该电路有n个输入和log(n)个输出,n个输入中的一个假定为1,其余假定为0,输出位提供等于1的输入二进制编码。例如,在8输入、3输出编码器中,如果第f行等于1,则输出等于100(计数从0开始)。

左:2x4解码器的设计。右:n位编码器框图。
现在我们假设我们不存在只有一个输入行可以等于1的限制,假设有多个输入可以等于1。在这种情况下,我们需要报告具有最高索引(优先级)的输入行的二进制编码。例如,如果是第3行和第5行,那么我们需要报告第5行的二进制编码,和上图右一样。此外,4-2位编码器的电路图如下图所示。

用解码器实现解复用器:

时钟SR锁存器(下图左)和D锁存器(下图右):

J–K锁存器:

基本锁存器的比较:

19.2.5 时序逻辑电路
前面已经研究了在比特上计算不同函数的组合逻辑电路,本小节将讨论如何保存位以供以后使用,这些结构被称为顺序逻辑元件(sequential logic element),因为输出取决于过去的输入,这些输入在事件序列中较早出现。逻辑门的基本思想是修改输入值以获得所需的输出,在组合逻辑电路中,如果输入被设置为0,那么输出也被重置。为了确保电路存储一个值并在处理器通电时保持该值,需要设计一种具有某种“内置存储器”的不同类型的电路。让我们从制定一组要求开始:
1、电路应能自我维持,并在外部输入复位后保持其值。不应依赖外部信号来维持其存储的元件。
2、应该有一种方法来读取存储的值而不破坏它。
3、应该有一种方法将存储值设置为0或1。
确保电路保持其值的最佳方法是创建反馈路径,并将输出连接回输入,先看看最简单的逻辑电路:SR锁存器(SR latch)。
19.2.5.1 SR锁存器
下图显示了SR锁存器。有两个输入S(设置)和R(重置),有两个输出Q及其补码Q,包含了两个交叉耦合NAND门的电路。请注意,如果与非门的一个输入为0,则输出保证为1。然而,如果其中一个输入是1,另一个输入则为a,则输出为a。

用NOR门实现的SR锁存器:

19.2.5.2 时钟和信号
一个典型的处理器包含数百万或可能数十亿个逻辑门和数千个锁存器,不同的电路需要不同的时间,例如多路复用器可能需要1ns,解码器可能需要0.5ns。电路完成计算后,就可以转发输出了。如果没有全局时间的概念,很难在不同的单元之间同步通信,尤其是那些具有可变延迟的单元,导致难以设计、操作和验证处理器。由此需要时间概念,例如可以说加法器需要两个时间单位,在两个单元结束时,预期数据将在锁存器X中找到,其他单元可以在两个时间单元后从锁存器中获取值并继续计算。
考虑一个需要向打印机发送一些数据的处理器的例子。为了传输数据,处理器通过一组铜线发送一系列比特,打印机读取这些比特,然后打印数据。问题是,处理器什么时候发送数据?计算完成后,需要发送数据。我们可以问的下一个问题是,处理器如何知道计算何时结束?它需要知道不同单元的确切延迟,一旦计算的总持续时间过去,可以将输出数据写入锁存器,并设置用于通信的铜线的电压。因此,处理器确实需要时间概念。其次,设计者需要告诉处理器不同子单元所需的时间。与处理2.34ns和1.92ns等数字相比,处理1、2和3等整数要简单得多。这里的1、2、3表示时间单位,时间单位可以是任何数字,例如0.9333ns。
时钟信号(clock signal):发送到大型电路或处理器的每个部分的周期性方波。
时钟周期(clock cycle):时钟信号的周期。
时钟频率(clock frequency):时钟周期的倒数。
因此,大多数数字电路与时钟信号同步,该时钟信号在完全相同的时间向处理器的每个部分发送周期性脉冲。时钟信号为方波,如下图所示,大多数时间,时钟信号是由主板上的专用单元从外部生成的。让我们考虑时钟信号从1转变到0(向下/负边缘)的点作为时钟周期的开始,从时钟的一个向下沿到下一个向下边缘测量时钟周期,时钟周期的持续时间也称为时钟周期,时钟周期的倒数被称为时钟频率。

一个时钟信号。
电脑、笔记本电脑、平板电脑或移动电话通常会在其规格中列出频率。例如,规范可能会说处理器运行在3GHz,这个数字是指时钟频率。
典型的计算模型是:电路中执行所有基本动作所需的时间是按照时钟周期来测量的,如果生产者单元占用n个时钟周期,那么在n个时钟循环结束时,它将其值写入锁存器。其他用户单元知道此延迟,并且在第(n+1)个时钟周期开始时,它们从锁存器读取值。由于所有单元都与时钟明确同步,并且处理器知道每个单元的延迟,因此很容易对计算进行排序、与I/O设备通信、避免竞争条件、调试和验证电路。我们想向打印机发送数据的简单示例可以通过使用时钟轻松解决。
19.2.5.3 时钟SR锁存器
下图显示了SR锁存器,其增加了两个与非门,时钟作为输入之一,另外两个输入分别是S位和R位。如果时钟为0,则交叉耦合NAND门的两个输入都为1,将保持先前的值。如果时钟为1,则交叉耦合NAND门的输入分别为S和R,这些输入与基本SR锁存器相同。请注意,时钟锁存器通常称为触发器(flip-flop)。

时钟SR锁存器图例。
触发器(flip-flop)是一个时钟锁存器,可以保存一位(0或1)。
通过使用时钟,我们部分解决了输入和输出同步的问题。在这种情况下,当时钟为0时,输出不受输入的影响。当时钟为1时,输出受输入影响。这种锁存器也称为电平敏感锁存器(level sensitive latch)。
电平敏感锁存器(level sensitive latch)取决于时钟信号的值:0或1。通常,它只能在时钟为1时读取新值。
在电平敏感锁存器中,电路有半个时钟周期来计算正确的输出(当时钟为0时)。当时钟为1时,输出可见。最好有一个完整的时钟周期来计算输出,这需要一个边缘敏感锁存器(edge sensitive latch),边缘敏感锁存器仅在时钟的向下边缘反映输出端的输入。
边缘敏感锁存器(edge sensitive latch)仅在固定的时钟边缘(例如向下边缘,从1到0的转换)反映输出端的输入。
19.2.5.4 边缘敏感SR触发器
下图显示了边缘敏感SR触发器的结构图,连接了两个边缘敏感SR触发器,唯一的区别是第二个触发器使用了时钟信号组合。第一个触发器为主(master),而第二个为从(slave)。这种触发器也被称为主-从SR触发器。这就是这个电路的工作原理。

除了主从SR触发器,还有其它各种类型的触发器,如JK触发器、D触发器、主从D触发器等。

从上到下:JK触发器、D触发器、主从D触发器。
19.2.5.5 寄存器
我们可以通过使用一组n个主从D触发器来存储n位数据,每个D触发器连接到输入线,其输出端连接到输出线,这种n位结构被称为n位寄存器。我们可以并行加载n位,也可以在每个负时钟边沿并行读取n位。因此,这种结构被称为并行输入——并行输出寄存器。其结构如下图所示。

现在让我们考虑一个串行输入-并行输出寄存器,如下图所示,有一个输入被馈送到最左边的D触发器, 每个周期,输入都会移动到右侧的相邻触发器。因此,要加载n位将需要n个周期。 第一位将在第一个周期被加载到最左边的触发器中,它需要n个周期才能到达最后一个触发器。 到那时,其余的n - 1触发器将加载其余的n - 1位,然后我们可以并行读取所有 n 位(类似于并行并行输出寄存器)。 该寄存器也称为移位寄存器,用于实现高速I/O总线中使用的电路。

8位并行寄存器的结构图如下:

5位移位寄存器:

行波计数器:

19.2.6 内存
19.2.6.1 静态内存(SRAM)
SRAM是指静态随机存取存储器,基本SRAM单元包含两个交叉耦合的反相器,如下图所示。相比之下,基本SR触发器或D触发器包含交叉耦合的NAND门。设计如下所示。

SRAM单元的核心包含4个晶体管(每个反相器中有2个),这种交叉耦合布置足以节省单个比特(0或1)。然而,我们需要一些额外的电路来读取和写入值。此时,在锁存器中使用交叉耦合反相器到底是不是一个坏主意,它们毕竟需要更少的晶体管。我们将看到,实现用于读取和写入SRAM单元的电路的开销是非常重要的,开销不足以证明以SRAM单元为核心制作锁存器的合理性。
交叉耦合的反相器连接到每一侧(W1、W2)上的晶体管,W1和W2的栅极连接到被称为字线的相同信号,两个反相器W1和W2中的四个晶体管构成SRAM单元,它总共有六个晶体管。现在,如果字线上的电压低,则W1和W2关断,不可能读取或写入SRAM单元。然而,如果字线上的信号为高,则W1和W2导通,可以访问SRAM单元。
下图显示了一个典型的SRAM阵列,SRAM单元被布置为二维矩阵。一行中的所有SRAM单元共享字线,一列中的所有SRAM单元共享一对位线。要激活某个SRAM单元,必须打开其相关的字线,由解码器完成,获取地址位的子集,并打开适当的字线。一行SRAM单元可能包含100多个SRAM单元,通常,我们会对32个SRAM单元(在32位机器上)的值感兴趣。在这种情况下,列复用器/解复用器选择属于感兴趣的SRAM单元的位线,使用地址中的位的子集作为列选择位。这种设计方法也称为2.5D存储器组织。

SRAM单元阵列。
19.2.6.2 内容寻址内存(CAM)
下图是10晶体管CAM单元,如果SRAM单元中存储的值V不等于输入位AiAi,那么我们希望将匹配线的值设置为0。在CAM单元中,上半部分是具有6个晶体管的常规SRAM单元,下半部有4个额外的晶体管。现在让我们考虑晶体管T1,它连接到全局匹配线,晶体管T2。T1由存储在SRAM单元中的值V控制,T2由¯¯¯¯¯¯AiAi¯控制。假设V=¯¯¯¯¯¯AiAi¯,如果两者都为1,则晶体管T1和T2处于导通状态,并且匹配线和地之间存在直接导电路径。因此,匹配线的值将设置为0。然而,如果V和¯¯¯¯¯¯AiAi¯都为0,则通过T1和T2的路径不导通。但是,在这种情况下,通过T3和T4的路径变得导通,因为这些晶体管的栅极分别连接到¯¯¯¯VV¯和AiAi。两个栅极的输入都是逻辑1,因此匹配线将被下拉到0。读取器可以反过来验证,如果V=AiAi,则不形成导通路径。因此,如果存储的值与输入位AiAi不匹配,则CAM单元将匹配线驱动到逻辑0。

10晶体管CAM单元。
下图显示了CAM单元阵列。该结构主要类似于SRAM阵列。我们可以通过索引寻址一行,并执行读/写访问,此外可以将CAM单元的每一行与输入A进行比较。如果任何行与输入匹配,则相应的匹配线的值将为1。可以计算所有匹配线的逻辑OR,并确定CAM阵列中是否匹配,此外可以将CAM阵列的所有匹配线连接到优先级编码器,以查找与数据匹配的行的索引。

CAM单元阵列。
19.2.6.3 动态内存(DRAM)
现在来看看一种只使用一个晶体管来节省一点时间的存储器技术,它非常密集、面积大,而且能效高,但比SRAM和锁存器慢得多,适用于大型片外存储器。
基本DRAM(动态内存)单元如下图所示。单个晶体管的栅极连接到字线,从而启用或禁用它,其中一个端子连接到存储电荷的电容器。如果存储的位是逻辑1,则电容器带电,否则不带电。

一个动态内存的单元。

DRAM和SRAM单元的对比图。
因此,读取和写入值非常容易。我们需要首先设置字线,以便可以访问电容器。为了读取该值,需要感测位线上的电压。如果它处于地电位,则单元存储0,否则如果它接近电源电压,则存储1。类似地,要写入值,我们需要将位线(BL)设置为适当的电压,并设置字线,电容器将相应地充电或放电。
然而,就DRAM而言,并非一切都是免费的。让我们假设电容器被充电到等于电源电压的电压,实际上,电容器将通过电介质和晶体管逐渐泄漏一些电荷。该电流很小,但在长时间内电荷的总损失可能很大,最终会使电容器放电。为了防止这种情况,有必要定期刷新DRAM单元的值,亦即需要读取并写回数据值。这也需要在读取操作之后完成,因为电容器在对位线充电时会损失一些电荷。现在让我们尝试制作一个DRAM单元阵列。
我们可以用创建SRAM单元阵列的方法构建DRAM单元阵列(下图),有三点不同:
- 存在一条位线而不是两条位线。
- 有一个连接到位线的专用刷新电路。这在读取操作后使用,也会定期调用。
- 在这种情况下,感测放大器出现在列复用器/解复用器之前。读出放大器还为整个DRAM行(也称为DRAM页)缓存数据。它们确保对同一DRAM行的后续访问是快速的,因为它们可以直接从读出放大器进行服务。

DRAM单元阵列。
接下来简述现代DRAM的时序方面。在过去的好日子里,DRAM内存是异步访问的,意味着DRAM模块没有做出任何时序保证。但现在每个DRAM操作都与系统时钟同步,因此,如今的DRAM芯片是同步DRAM芯片(SDRAM芯片)。
截至目前,同步DRAM存储器通常使用DDR4或DDR5标准,DDR代表双倍数据速率,使用最早标准DDR1的设备在时钟的上升沿和下降沿向处理器发送8字节的数据包,DDR也被称为双峰(double pump)操作。DDR1的峰值数据速率为1.6 GB/s,后续的DDR世代通过以更高的频率传输数据来扩展DDR1,例如,DDR2的数据速率是DDR1设备的两倍(3.2 GB/s),DDR3通过使用更高的总线频率将峰值传输速率进一步提高了一倍,自2007年开始使用(峰值速率为6.4GB/s)。
19.2.6.4 只读内存(ROM)
只读内存可分为普通ROM和PROM(可编程ROM),下面分别是它们的单元图例。

(a) 存储逻辑0的ROM单元;(b) 存储逻辑1的ROM单元。

PROM单元。
19.2.6.5 可编程逻辑阵列
事实证明,我们可以很容易地用类似于PROM单元的存储单元制作组合逻辑电路,这种器件被称为可编程逻辑阵列或PLA。PLA在实践中用于实现由数十或数百个小项(minterm)组成的复杂逻辑函数,相对于由逻辑门组成的硬连线电路的优势在于它是灵活的,我们可以在运行时更改PLA实现的布尔逻辑,相比之下,由硅制成的电路永远不会改变其逻辑。其次,PLA的设计和编程更简单,而且有很多软件工具可以设计和使用PLA。最后,PLA可以有多个输出,因此可以很容易地实现多个布尔函数。这种额外的灵活性是有代价的,代价是性能。
下图(a)所示的PLA单元原则上类似于基本PROM单元。如果栅极处的值(E)等于1,则NMOS晶体管处于导通状态。因此,NMOS晶体管的源极和漏极端子之间的电压差非常小。换句话说,可以简单地假设结果线的电压等于信号的电压,X. If (E = 0),NMOS晶体管处于截止状态。结果线是浮动的,并保持其预充电电压。在这种情况下,我们建议推断逻辑1。
现在让我们构建一行PLA单元,其中每个PLA单元在其源极端子处连接到输入线,如图(b)所示。输入编号为X1…Xn,所有NMOS晶体管的漏极连接到结果线,PLA单元的晶体管的栅极连接到一组使能信号E1…En。如果任何一个使能信号等于0,则该特定晶体管被禁用,我们可以将其视为从PLA阵列中逻辑移除。

一个PLA单元。
现在让我们创建一个PLA单元格数组,如下图所示,每行对应一个minterm。对于我们的3变量示例,每行由6列组成,每个变量有2列(原始和补充),例如,前两列分别对应于A和¯¯¯¯AA¯。在任何一行中,这两列中只有一列包含PLA单元,因为A和¯¯¯¯AA¯不能同时为真。在第一行,计算最小项¯¯¯¯¯¯¯¯¯¯¯¯ABCABC¯的值,因此第一行包含对应于¯¯¯¯AA¯、¯¯¯¯BB¯和¯¯¯¯CC¯的列中的PLA单元。我们在其余行中为剩余的minterm进行类似的连接,PLA阵列的这一部分被称为AND平面,因为我们正在计算变量值(原始值或补码值)的逻辑AND。PLA阵列的AND平面独立于我们希望计算的布尔函数,给定输入,它计算所有可能的最小项的值。

PLA单元阵列。

典型的内存封装引脚和信号。

256 KB内存组织。

1MB内存组织。

DDR代次演进图。

非易失性RAM技术。


上:简化的DRAM读取时序;下:Signetics 7489 SRAM的脉冲串。
19.2.7 计算机算术
本节将设计算术运算的硬件算法,先阐整数运算的算法,如两个二进制数相加的基本算法,有很多方法可以完成这些基本操作,每种方法都有自己的优缺点。注意,二进制减法的问题在概念上与2的补码系统中的二进制加法相同。因此,我们不需要单独对待它。随后,我们将看到,n个数的相加问题与乘法问题密切相关,而且这是一个硬件上的快速操作。遗憾的是,整数除法并不存在非常有效的方法。然而,我们将考虑两种用于划分正二进制数的流行算法。
整数算术之后,我们将研究浮点(带小数点的数字)算术的方法,大多数整数算法稍作修改后都可以移植到浮点数领域。与整数除法相比,浮点除法可以非常有效地完成。
19.2.7.1 加法
让我们看看将两个1位数字a和b相加的问题,a和b都可以取两个值:0或1,因此,a和b有四种可能的组合,它们的二进制和可以是00、01或10。当a和b均为1时,它们的和将是10,两个1位数字的总和可能有两位长。让我们将结果的LSB称为和,将MSB称为进位,例如,把8和9相加,和是7,进位是1。
可以将和和进位的概念扩展到加三个1位数字。如果我们将三个1位数字相加,那么结果的范围是二进制的00到11之间。
和(sum):总和是两个或三个1位数字相加结果的LSB。
进位(carry):进位是两个或三个1位数字相加结果的MSB。
对于可以将两个1位数字相加的加法器,将有两个输出位:和s和进位c,将两个位相加的一个加法器称为半加法器(half adder)。半加法的真值表如下表所示。
| a | b | s | c |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
| 0 | 1 | 1 | 0 |
| 1 | 0 | 1 | 0 |
| 1 | 1 | 0 | 1 |

半加法器。
可以加3位的加法器称为全加法器(full adder),它的电子构造如下:

n位加法器被称为纹波进位加法器(ripple carry adder),其设计如下所示:

考虑将两个数字A和B相加的问题,首先将比特集划分为4比特的块,如下图所示,每个块包含一个a片段和一个B片段。通过考虑块的输入进位将这两个片段相加,并生成一组和位和一个进位,此进位是后续块的输入进位。

此外,还有超前进位加法器(Carry Lookahead Adder),其分为两个阶段,每个阶段都拥有复杂的电子构造。
19.2.7.2 乘法
现与加法类似,先看看两个十进制数相乘的最简单的方法,不妨尝试将13乘以9。在这种情况下,13被称为被乘数(multiplicand),9被称为乘数(multiplier),117是乘积(product)。
下图(a)显示了十进制的乘法,(b)显示了二进制的乘法。请注意,两个二进制数相乘的方法与十进制数完全相同。我们需要考虑乘数从最小显著位置到最大显著位置的每一位。如果该位为1,那么我们将被乘数的值写在该行下方,否则我们将写0。对于每个乘数位,我们将被乘数向左移动一位。其原因是每个乘数位代表2的更高幂。我们将每个这样的值称为部分和(见图7.10(b))。如果乘法器有m位,那么我们需要将m个部分和相加以获得乘积。在这种情况下,乘积是十进制117,二进制1110101。读者可以验证它们实际上表示相同的数字。为了便于以后的表示,让我们定义另一个称为部分积的术语。它是部分和的连续序列的和。

(a)十进制乘法;(b)二进制乘法。
常规的乘法器是O(n2)O(n2),而改进版的Booth乘法器或Wallace树形乘法器(下图)可以做到O(log(n))O(log(n))的算法复杂度。

Wallace树形乘数。
19.2.7.3 除法
现在让我们看看整数除法。不幸的是,与加法、减法和乘法不同,除法是一个明显较慢的过程。任何除法运算都可以表示如下:
N=DQ+RN=DQ+R
N是被除数,D是除数,Q是商,R是余数。假定除数和被除数为正,除法过程需要满足以下属性:
- R<DR<D且R≥0R≥0。
- Q是满足上述等式的最大正整数。
如果我们想除掉负数,那么首先将它们转换成正数,进行除法,然后调整商和余数的符号,部分ISA试图确保余数始终为正。在这种情况下,需要将商减1,并将除数与余数相加,使其为正。
实现除法的方式有迭代除法、佘数恢复除法(Restoring Division)、非余数恢复除法(Non-Restoring Division)等。本文忽略这些算法的具体描述,有兴趣的童鞋可以自行查阅资料。
19.2.7.4 浮点数运算
浮点加法和减法的问题实际上是同一问题的不同方面。A-B可以用两种方式解释,可以说正在从A中减去B,也可以说在将-B加到A中。因此,与其单独看减法,不如将其视为加法的特例。浮点数的二进制表示、属性和特殊含义可以参见:17.2.2 浮点数。
下图显示了一个示例,说明了如何将有效位解压缩,并将其放入普通浮点数的寄存器中。在32位IEEE 754格式中,尾数有23位,小数点前有0或1。因此,有效位需要24位,如果我们希望添加前导符号位(0),那么我们需要25位存储。让我们把这个号码保存在一个寄存器中,并称之为W。

展开有效位并放入寄存器。

IEEE 754格式。
浮点数的运算涉及舍入等考量,下图显示了两个浮点数相加的算法,考虑了0值。

累加两个浮点值的流程图。
浮点数相乘算法与泛型加法算法的形式完全相同,只需几步。让我们尝试乘以A x B以获得乘积C,乘法的流程图如下图所示。在乘法的情况下,我们不必对齐指数,如下初始化算法,将B的符号和装入寄存器W,W的宽度等于操作数大小的两倍,就可以容纳乘积。E寄存器初始化为EA+EB−biasEA+EB−bias,因为在乘法的情况下,指数相加,减去bias以避免重复计数,计算结果的符号很简单。

两个浮点值相乘的流程图。
此外,还有Goldschmidt除法以及Newton-Raphson除法。

Newton-Raphson方法。
19.3 计算机架构和组织
19.3.1 计算机层级
计算机系统级层次结构是将计算机与用户连接起来并使用计算机的不同级别的组合,还描述了如何在计算机上执行计算活动,并显示了在不同级别的系统中使用的所有元素。通用的计算机系统级层次结构由7个级别组成:
| 层级 | 功能 | 举例 | 解析 |
|---|---|---|---|
| 层6 | 用户 | 可执行程序 | 包含用户和可执行程序。 |
| 层5 | 高级语言 | C++、Java | 高级语言包括 C++、Java、FORTRAN和许多其他语言,是用户发出命令的语言。 |
| 层4 | 汇编语言 | 汇编代码 | 汇编语言是计算机系统的下一个层次。机器只理解汇编语言,因此按照顺序,所有高级语言都在汇编语言中进行了更改,汇编代码是为它编写的。 |
| 层3 | 系统软件 | 操作系统 | 系统软件种类繁多,主要帮助操作进程,并建立硬件和用户界面之间的连接,可能包括操作系统、库代码等。 |
| 层2 | 机器 | 指令集架构(ISA) | 在计算机系统中使用不同类型的硬件来执行不同类型的活动,包含指令集架构。 |
| 层1 | 控制层 | 微码(microcode) | 控制是系统中使用微码的级别,控制单元包括在这一级别的计算机系统中。 |
| 层0 | 数字逻辑 | 电路、门 | 数字逻辑是数字计算的基础,提供了对计算机内电路和硬件如何通信的基本理解,由各种电路和门等组成。 |
当然,也存在另一种层级划分,从上到下分别是:游戏应用、游戏引擎、图形API、操作系统、设备驱动、硬件设备。

下图是更加详细的层级模块,其中操作系统(OS)处于图形API等第三方SDK和驱动之间,充当着承上启下的重要作用和通讯桥梁,是整个计算机层级架构极其重要的组成部分。

在底层,计算机硬件由处理器、内存和I/O组件组成,每种类型有一个或多个模块。这些组件以某种方式互连,以实现计算机的主要功能,即执行程序。有四个主要结构要素:
- 处理器:控制计算机的操作并执行其数据处理功能。当只有一个处理器时,它通常被称为中央处理单元(CPU)。
- 主存储器:存储数据和程序。易丢失,当计算机关闭时,内存中的内容会丢失。相反,即使计算机系统关闭,磁盘内存的内容也会保留。主存储器也称为实存储器或主存储器。
- I/O模块:在计算机及其外部环境之间移动数据外部环境由各种设备组成,包括辅助存储器设备(如磁盘)、通信设备和终端。
- 系统总线:提供处理器、主存储器和I/O模块之间的通信。

19.3.2 架构vs组织
计算机架构(Computer Architecture)是对计算机各个部分的需求和设计实现的功能描述,处理计算机系统的功能行为。在设计计算机时,它出现在计算机组织之前。
计算机组织(Computer Organization)出现在计算机体系架构之后,是操作属性如何链接在一起并有助于实现架构规范的方式,处理的是结构关系。
简单而言,架构是呈现给软件设计师的计算机视图,组织是计算机在硬件上的实际实现。

计算机的层级设计、硬件、软件和架构、组织的关系图。

数字计算机方框图。
计算机体系架构和计算机组织之间的详细区别如下表:
| 计算机架构 | 计算机组织 | |
|---|---|---|
| 1 | 描述计算机的功能。 | 描述计算机是如何做到的。 |
| 2 | 处理计算机的功能行为。 | 处理计算机的结构关系。 |
| 3 | 在上图,很明显它处理的是高层级的设计问题。 | 在上图,也很明显它处理的是低层级的设计问题。 |
| 4 | 表明硬件。 | 表明性能。 |
| 5 | 作为程序员,可以将架构视为一系列指令、寻址模式和寄存器。 | 架构的实现称为组织。 |
| 6 | 对于设计一台计算机,它的架构是固定的。 | 为了设计一台计算机,它的组织根据其架构而定。 |
| 7 | 也被称为指令集架构 (ISA)。 | 通常被称为微体系架构(microarchitecture)。 |
| 8 | 包括逻辑功能,例如指令集、寄存器、数据类型和寻址模式。 | 由电路设计、外围设备和加法器等物理单元组成。 |
| 9 | 架构类别:冯诺依曼、Harvard、ISA、系统设计。 | CPU组织根据地址字段的数量分为三类:单累加器组织、通用寄存器组织、堆栈组织。 |
| 10 | 使计算机的硬件可见。 | 提供了有关计算机性能的详细信息。 |
| 11 | 协调系统的硬件和软件。 | 处理系统中的网络段。 |
| 12 | 软件开发人员意识到它。 | 它逃脱了软件程序员的检测。 |
| 13 | 示例:Intel和AMD创建了x86处理器,Sun Microsystems和其他公司创建了SPARC处理器,Apple、IBM和摩托罗拉创建了PowerPC。 | 组织质量包括程序员看不到的硬件元素,例如计算机和外围设备的接口、内存技术和控制信号。 |
19.3.3 冯·诺伊曼架构
历史上有两种类型的计算机:
- 固定程序计算机:它们的功能非常具体,不能重新编程,例如计算器。
- 存储程序计算机:可以被编程以执行许多不同的任务,应用程序存储在它们上面,因此得名。
现代计算机基于John Von Neumann(约翰·冯·诺依曼)引入的存储程序概念。在这种存储程序的概念中,程序和数据存储在称为存储器的单独存储单元中,并被同等对待,意味着用这种架构构建的计算机将更容易重新编程。 其基本结构是这样的:

有着输入、处理、输出等概念和组成的计算机模型称为冯·诺伊曼架构,它是一种将程序指令存储器和数据存储器合并在一起的电脑设计概念结构,是一种实现通用图灵机的计算设备,以及一种相对于并行计算的序列式结构参考模型(referential model)。冯·诺伊曼隐式指导了将存储设备与中央处理器分开的概念,也被称为ISA(指令集架构)计算机。

冯·诺依曼1947年出版的《电子计算仪器问题的规划和编码》中的流程图。
冯·诺依曼结构的抽象组成如下:

更进一步地,它约定了用二进制进行计算和存储,还定义计算机基本结构为5个部分,分别是中央处理器(CPU)、内存、输入设备、输出设备、总线。

结合上图,各部分结构的具体描述如下:
-
存储器:代码跟数据在RAM跟ROM中是线性存储, 数据存储的单位是一个二进制位,最小的存储单位是字节。
-
总线:总线是用于 CPU 和内存以及其他设备之间的通信,总线主要有三种:
-
地址总线:用于指定 CPU 将要操作的内存地址。
-
数据总线:用于读写内存的数据。
-
控制总线:用于发送和接收信号,比如中断、设备复位等信号,CPU收到信号后响应,这时也需要控制总线。
-
-
输入/输出设备:输入设备向计算机输入数据,计算机经过计算后,把数据输出给输出设备。比如键盘按键时需要和CPU进行交互,这时就需要用到控制总线。
-
CPU:中央处理器,类比人脑,作为计算机系统的运算和控制核心,是信息处理、程序运行的最终执行单元。它的结构如下所示:

- 控制单元(CU):处理所有处理器控制信号,指导所有输入和输出流,获取指令代码,并控制数据在系统中的移动方式。
- 算术逻辑单元 (ALU) :处理CPU可能需要的所有计算(如加法、减法、比较),执行逻辑运算、位移运算和算术运算。
- 主存储器单元(寄存器):CPU用寄存器存储计算时所需数据,寄存器一般有以下几种:
- 累加器(Accumulator):存储ALU的计算结果。
- 程序计数器(PC):跟踪要处理的下一条指令的内存位置,然后PC将下一个地址传递给内存地址寄存器 (MAR)。
- 内存地址寄存器(MAR):存储需要从内存中取出或存储到内存中的指令的内存位置。
- 内存数据寄存器(MDR):存储从内存中获取的指令或任何要传输到内存并存储在内存中的数据。
- 指令寄存器(IR):可分为两种:
- 当前指令寄存器(CIR):在等待编码和执行时存储最近获取的指令。
- 指令缓冲寄存器(IBR):不立即执行的指令放在指令缓冲寄存器IBR中。
- 通用寄存器(GPR):存放需要进行运算的数据,比如需进行加法运算的两个数据。
在冯诺伊曼体系下计算机指令执行的简要过程如下:
- CPU读取程序计数器获得指令内存地址,CPU控制单元操作地址总线从内存地址拿到数据,数据通过数据总线到达CPU被存入指令寄存器。
- CPU分析指令寄存器中的指令,如果是计算类型的指令交给逻辑运算单元,如果是存储类型的指令交给控制单元执行。
- CPU 执行完指令后程序计数器的值通过自增指向下个指令,比如32位CPU会自增4。
- 自增后开始顺序执行下一条指令,不断循环执行直到程序结束。
冯诺依曼瓶颈(Von Neumann bottleneck)是无论做什么来提升性能,都无法摆脱这样一个事实,即一次只能执行一条指令,并且只能按顺序执行,这两个因素都阻碍了CPU的能力。我们可以为冯诺依曼处理器提供更多缓存、更多RAM或更快的组件,但如果要在CPU性能方面取得原始收益,则需要对CPU配置进行有影响力的检查。 这种架构非常重要,用于PC乃至超级计算机。
19.3.4 多核结构
下图是典型多核计算机主要部件的简化视图。大多数计算机,包括智能手机和平板电脑中的嵌入式计算机,以及个人计算机、笔记本电脑和工作站,都安装在主板上。印刷电路板(PCB)是一种刚性的平板,用于固定和互连芯片和其他电子部件,该电路板由通常为两到十层的层组成,这些层通过蚀刻到电路板中的铜路径将组件互连。计算机中的主要印刷电路板称为系统板或主板,而插入主板插槽的较小的印刷电路板则称为扩展板。主板上最突出的元素是芯片,芯片是一块半导体材料,通常是硅,在其上制造电子电路和逻辑门,所得产品称为集成电路。

多核计算机主要元件的简化视图。
下图左是IBM zEnterprise EC12大型计算机处理器芯片的照片,有27.5亿个晶体管,有六个内核(处理器),还有两个标记为L3缓存的大区域,由所有六个处理器共享,L3控制逻辑控制L3高速缓存和内核之间以及L3高速缓存与外部环境之间的流量。此外,在核心和L3缓存之间还有存储控制(SC)逻辑,内存控制器(MC)功能控制对芯片外部内存的访问,GX I/O总线控制访问I/O的通道适配器的接口。下图右则展示了单个核的内部结构,只是构成单个处理器芯片的硅表面区域的一部分。

晶片(Wafer)、芯片(Chip)和门(Gate)之间的关系如下:

QPI(QuickPath Interconnect)是Intel于2008年推出的点对点互连方法,QPI和其他点对点互连方案的重要特征是多个直接连接、分层协议架构和分组数据传输。
下图说明了QPI在多核计算机上的典型使用。QPI链路(由图中的绿色箭头对表示)形成了一个交换结构,使数据能够在整个网络中移动,可以在每对核心处理器之间建立直接QPI连接。如果图中的核心A需要访问核心D中的内存控制器,则它通过核心B或C发送请求,后者必须将该请求转发到核心D的内存控制器。同样,具有八个或更多处理器的大型系统可以使用具有三个链路的处理器构建,并通过中间处理器路由流量。

使用QPI的多核配置。

QPI层示意图。

不同的芯片组织。

多核组织备选方案。
19.3.5 嵌入式系统
术语嵌入式系统是指在产品中使用电子设备和软件,而不是通用计算机,如平板电脑或台式机系统。每年售出数百万台电脑,包括笔记本电脑、个人电脑、工作站、服务器、大型机和超级计算机,相比之下,每年生产数十亿个嵌入大型设备的计算机系统。如今,许多(也许是大多数)使用电力的设备都有嵌入式计算系统,在不久的将来,几乎所有这样的设备都将具有嵌入式计算系统。
具有嵌入式系统的设备类型几乎太多,无法列出,样例包括手机、数码相机、摄像机、计算器、微波炉、家庭安全系统、洗衣机、照明系统、恒温器、打印机、各种汽车系统(如变速器控制、巡航控制、燃油喷射、防抱死制动和悬挂系统)、网球拍、牙刷以及自动化系统中的多种类型的传感器和致动器。
通常,嵌入式系统与其环境紧密耦合,导致与环境交互的需要所施加的实时约束。约束条件(如所需的运动速度、所需的测量精度和所需的持续时间)决定了软件操作的时间,如果必须同时管理多个活动,会带来更复杂的实时约束。
下图概括地显示了嵌入式系统组织,除了处理器和内存之外,还有许多元素与典型的台式机或笔记本电脑不同:

嵌入式系统的可能组织。
- 可能存在多种接口,使系统能够测量、操作和以其他方式与外部环境交互。嵌入式系统通常通过传感器和致动器与外部世界交互(感知、操纵和通信),因此通常是反应系统,反应系统与环境持续交互,并以该环境确定的速度执行。
- 人机界面可以像闪光灯一样简单,也可以像实时机器人视觉一样复杂。在许多情况下,没有人机界面。
- 诊断端口可用于诊断所控制的系统,而不仅仅用于诊断计算机。
- 可使用专用现场可编程(FPGA)、专用(ASIC)或甚至非数字硬件来提高性能或可靠性。
- 软件通常具有固定的功能,并且特定于应用程序。
- 效率对于嵌入式系统至关重要。需针对能量、代码尺寸、执行时间、重量、体积以及成本进行了优化。
与通用计算机系统也有几个值得注意的相似之处:
- 即使使用名义上固定功能的软件,现场升级以修复错误、提高安全性和添加功能的能力对于嵌入式系统来说也变得非常重要,而不仅仅是在消费类设备中。
- 一个相对较新的发展是支持多种应用的嵌入式系统平台,良好例子是智能手机和音频/视频设备(如智能电视)。
19.3.5.1 微处理器与微控制器
早期的微处理器芯片包括寄存器、ALU和某种控制单元或指令处理逻辑。随着晶体管密度的增加,有可能增加指令集架构的复杂性,最终增加内存和多个处理器,现代微处理器芯片包括多个内核和大量的高速缓存。
微控制器芯片对可用的逻辑空间进行了实质上不同的使用,下图概括地显示了微控制器芯片上常见的元件。微控制器是包含处理器、用于程序的非易失性内存(ROM)、用于输入和输出的易失性内存(RAM)、时钟和I/O控制单元的单个芯片。微控制器的处理器部分具有比其他微处理器低得多的硅面积和高得多的能量效率。

也被称为“芯片上的计算机”,每年数十亿个微控制器单元被嵌入到从玩具到家电到汽车的各种产品中,比如单个车辆可以使用70个或更多个微控制器。通常,特别是对于更小、更便宜的微控制器,它们被用作特定任务的专用处理器,比如微控制器在自动化过程中被大量使用。通过提供对输入的简单反应,它们可以控制机器、打开和关闭风扇、打开和闭合阀门等,是现代工业技术的组成部分,是生产能够处理极其复杂功能的机械的最廉价的方法之一。
微控制器具有多种物理尺寸和处理能力,处理器的范围从4位到32位架构。微控制器往往比微处理器慢得多,通常工作在MHz范围,而不是微处理器的GHz速度。微控制器的另一个典型特征是它不提供人机交互,被编程用于特定任务,嵌入其设备中,并在需要时执行。
19.3.5.2 嵌入式与深度嵌入式系统
嵌入式系统的一个子集,以及相当多的子集,被称为深度嵌入式系统(Deeply embedded system)。尽管这个术语在技术和商业文献中被广泛使用,但你会在互联网上无法明确地寻找一个直截了当的定义。通常,我们可以说,一个深度嵌入式系统有一个处理器,其行为很难被程序员和用户观察到。深度嵌入式系统使用微控制器而不是微处理器,一旦设备的程序逻辑被烧录到ROM(只读存储器)中,就不可编程,并且与用户没有交互。
深度嵌入式系统是专用的、单用途的设备,可以检测环境中的某些东西,执行基本级别的处理,然后对结果进行处理。深度嵌入式系统通常具有无线能力,并以联网配置出现,例如部署在大面积(例如,工厂、农业领域)上的传感器网络,物联网在很大程度上依赖于深度嵌入式系统。典型地,深度嵌入式系统在内存、处理器大小、时间和功耗方面具有极端的资源限制。
19.3.6 ARM架构
ARM架构是指从RISC设计原则演变而来的处理器架构,用于嵌入式系统。本节将简述之。
ARM指令集是高度规则的,旨在高效实现处理器和高效执行。所有指令均为32位长,遵循常规格式,使得ARM ISA适合在广泛的产品上实现。
增强基本ARM ISA的是Thumb指令集,是ARM指令集的重新编码子集。Thumb旨在提高使用16位或更窄内存数据总线的ARM实现的性能,并允许比ARM指令集提供的代码密度更好的代码密度。Thumb指令集包含记录为16位指令的ARM 32位指令集的子集。前些年定义的版本是Thumb-2。
ARM Holdings许可了许多专用微处理器和相关技术,但其产品线的大部分是Cortex系列微处理器架构。有三种Cortex架构,方便地用缩写A、R和M标记。
-
Cortex-A和Cortex-A50:是应用处理器,适用于智能手机和电子书阅读器等移动设备,以及数字电视和家庭网关(如DSL和有线互联网调制解调器)等消费设备。这些处理器以更高的时钟频率(超过1GHz)运行,并支持内存管理单元(MMU),是全功能操作系统(如Linux、Android、MS Windows和移动操作系统)所需的。MMU是通过将虚拟地址转换为物理地址来支持虚拟内存和分页的硬件模块。这两种架构同时使用ARM和Thumb-2指令集,主要区别在于Cortex-A是32位机器,而Cortex-A50是64位机器。
-
Cortex-R:设计用于支持实时应用程序,其中需要通过对事件的快速响应来控制事件的定时。它们可以在相当高的时钟频率(例如200MHz到800MHz)下运行,并且具有非常低的响应延迟。Cortex-R包括对指令集和处理器组织的增强,以支持深度嵌入式实时设备。这些处理器中的大多数没有MMU,有限的数据需求和有限数量的同时处理消除了对虚拟内存的复杂硬件和软件支持的需求。Cortex-R确实具有专为工业应用设计的内存保护单元(MPU)、缓存和其他内存功能。MPU是一种硬件模块,它禁止内存中的一个程序意外访问分配给另一个活动程序的内存。使用各种方法,在程序周围创建一个保护边界,并且禁止程序内的指令引用该边界之外的数据。使用Cortex-R的嵌入式系统包括汽车制动系统、大容量存储控制器、网络和打印设备。
-
Cortex-M:主要是为微控制器领域开发的,在微控制器领域,快速、高确定性中断管理的需求与极低门计数和最低可能功耗的需求相结合。与Cortex-R系列一样,Cortex-M架构有一个MPU,但没有MMU。Cortex-M仅使用Thumb-2指令集,其市场包括物联网设备、工厂和其他企业使用的无线传感器/致动器网络、汽车车身电子设备等。Cortex-M系列包含Cortex-M0、Cortex-M0+、Cortex-M3、Cortex-M4等版本。下图是基于Cortex-M3的典型单片机芯片:

19.3.7 云计算
尽管云计算的一般概念可以追溯到20世纪50年代,但云计算服务在2000年代初首次出现,尤其是针对大型企业。从那时起,云计算已经扩展到中小型企业,最近还扩展到了消费者。苹果的iCloud于2012年推出,在推出一周内就拥有2000万用户,2008年推出的基于云的笔记和归档服务Evernote在不到6年的时间内就接近了1亿用户。本节将简要概述。
在许多组织中,越来越突出的趋势是将大部分甚至所有信息技术(IT)运营转移到称为企业云计算的互联网连接基础设施。与此同时,个人电脑和移动设备的个人用户越来越依赖云计算服务来备份数据、同步设备和使用个人云计算进行共享。NIST在NIST SP-800-145(NIST云计算定义)中对云计算的定义如下:
云计算(Cloud computing):是一种模型,用于实现对可配置计算资源(例如,网络、服务器、存储、应用程序和服务)的共享池的无处不在、方便的按需网络访问,这些资源可以通过最小的管理工作量或服务提供商交互快速调配和发布。
基本上,通过云计算,可以获得规模经济、专业网络管理和专业安全管理,这些功能对大小公司、政府机构以及个人电脑和移动用户都有吸引力。个人或公司只需支付所需的存储容量和服务费用,无论是公司还是个人,用户都无需设置数据库系统、获取所需的硬件、进行维护和备份数据,所有这些都是云服务的一部分。
理论上,使用云计算存储数据并与其他人共享数据的另一大优势是云提供商负责安全。客户并不总是受到保护,云提供商之间出现了许多安全故障,例如Evernote在2013年初成为头条新闻,当时它告诉所有用户在发现入侵后重置密码。
云网络是指必须具备的网络和网络管理功能,以支持云计算。大多数云计算解决方案都依赖于互联网,但这只是网络基础设施的一部分。云网络的一个示例是在提供商和订户之间提供高性能和/或高可靠性网络,在这种情况下,企业和云之间的部分或全部流量绕过互联网,使用云服务提供商拥有或租用的专用专用网络设施。更一般地说,云联网是指访问云所需的网络能力的集合,包括利用互联网上的专门服务、将企业数据中心链接到云,以及在关键点使用防火墙和其他网络安全设备来强制执行访问安全政策。
我们可以将云存储视为云计算的一个子集,本质上,云存储由远程托管在云服务器上的数据库存储和数据库应用程序组成,使小型企业和个人用户能够利用可根据其需求扩展的数据存储,并利用各种数据库应用程序,而无需购买、维护和管理存储资产。
云计算的基本目的是提供方便的计算资源租赁,云服务提供商(CSP)维护通过互联网或专用网络可用的计算和数据存储资源,客户可以根据需要租用这些资源的一部分。实际上,所有云服务都是使用三种模型之一提供的(下图):SaaS、PaaS和IaaS。

替代信息技术架构。

云计算元素。

云服务模型。
19.4 ISA
19.4.1 ISA定义
就像任何语言都有有限的单词一样,处理器可以支持的基本指令/基本命令的数量也必须是有限的,这组指令通常称为指令集(instruction set),基本指令的一些示例是加法、减法、乘法、逻辑或和逻辑非。请注意,每条指令需要处理一组变量和常量,最后将结果保存在变量中,这些变量不是程序员定义的变量,是计算机内的内部位置。我们将指令集架构定义为:
指令集架构(instruction set architecture,ISA)是处理器支持的所有指令的语义,包括指令本身及其操作数的语义,以及与外围设备的接口。
指令集架构是软件感知硬件的方式,我们可以将其视为硬件输出到外部世界的基本功能列表。Intel和AMD CPU使用x86指令集,IBM处理器使用PowerPC R指令集,HP处理器使用PA-RISC指令集,ARM处理器使用ARMR指令集(或其变体,如Thumb-1和Thumb-2)。因此,不可能在基于ARM的系统上运行为Intel系统编译的二进制文件,因为指令集不兼容,但在大多数情况下,可以重用C/C++程序。要在特定架构上运行C/C++程序,我们需要为该特定架构购买一个编译器,然后适当地编译C/C++程序。
19.4.2 基础指令
基本计算机具有16位指令寄存器 (IR),可以表示内存引用或寄存器引用或输入输出指令。一种简单的指令格式可以是如下形式:

基础指令可分为以下几类:
- 内存引用
这些指令将内存地址称为操作数,另一个操作数总是累加器。下图为直接和间接寻址指定12位地址、3位操作码(111除外)和1位寻址模式。

示例:IR寄存器内容是0001XXXXXXXXXXXX,即ADD指令取指译码后发现是ADD操作的内存引用指令,因此:
DR ← M[AR]
AC ← AC + DR, SC ← 0
- 寄存器引用
这些指令对寄存器而不是内存地址执行操作。下图的IR(14 – 12) 为 111(将其与内存引用区分开),IR(15) 为 0(将其与输入/输出指令区分开),其余12位指定寄存器操作。

示例:IR寄存器内容是0111001000000000,即CMA在取指和解码周期后发现它是补码累加器的寄存器引用指令,因此:
AC ← ~AC
- 输入/输出
这些指令用于计算机和外部环境之间的通信。下图的IR(14 – 12) 为 111(将其与内存引用区分开来),IR(15) 为 1(将其与寄存器引用指令区分开),其余 12 位指定 I/O 操作。

示例:IR寄存器内容是1111100000000000,即INP经过取指和解码循环后发现它是用于输入字符的输入/输出指令。因此,来自外围设备的INPUT字符。
包含在16位IR寄存器中的指令集是:
- 算术、逻辑和移位指令(与、加、补、左循环、右循环等)。
- 将信息移入和移出内存(存储累加器,加载累加器)。
- 带有状态条件的程序控制指令(分支、跳过)。
- 输入输出指令(输入字符、输出字符)。
指令具体的描述如下表:
| 符号 | 16进制码 | 描述 |
|---|---|---|
| AND | 0xxx、8xxx | 与任意字到AC |
| ADD | 1xxx、9xxx | 累加任意字到AC |
| LDA | 2xxx、Axxx | 加载内存字到AC |
| STA | 3xxx、Bxxx | 存储AC字到内存 |
| BUN | 4xxx、Cxxx | 无条件分支 |
| BSA | 5xxx、Dxxx | 分支并保存返回地址 |
| ISZ | 6xxx、Exxx | 如果为0,则递增并跳过 |
| CLA | 7800 | 清理AC |
| CLE | 7400 | 清除E(溢出位) |
| CMA | 7200 | 补充AC |
| CME | 7100 | 补充E |
| CIR | 7080 | 右循环AC和E |
| CIL | 7040 | 左循环AC和E |
| INC | 7020 | 递增AC |
| SPA | 7010 | 如果AC>0,跳过下一条指令 |
| SNA | 7008 | 如果AC<0,跳过下一条指令 |
| SZA | 7004 | 如果AC=0,跳过下一条指令 |
| SZE | 7002 | 如果E=0,跳过下一条指令 |
| HLT | 7001 | 停止计算机 |
| INP | F800 | 输入字符到AC |
| OUT | F400 | 输出字符到AC |
| SKI | F200 | 跳过输入标志 |
| SKO | F100 | 跳过输出标志 |
| ION | F080 | 中断开启 |
| IOF | F040 | 中断关闭 |
19.4.3 指令集设计准则
现在让我们开始为处理器设计指令集的艰难过程,可以将指令集视为软件和硬件之间的法律合同,双方都需要履行各自的合同。软件部分需要确保用户编写的所有程序都能成功有效地转译成基本指令,同样,硬件需要确保指令集中的所有指令都是有效实现的。双方都需要做出合理的假设,ISA需要具有一些必要的特性和一些有效性所需的特性。
-
完整。ISA应能够实现所有用户程序,是绝对必要的要求,我们希望ISA能够代表用户为其编写的所有程序。例如,如果我们有一个ISA,只有一条ADD指令,那么我们将无法减去两个数字。为了实现循环,ISA应该有一些方法来一遍遍地重新执行同一段代码。如果没有这种对和while循环的支持,C程序中的循环将无法工作。
请注意,对于通用处理器,我们正在查看所有可能的程序。然而,许多用于嵌入式设备的处理器功能有限,例如执行字符串处理的简单处理器不需要支持模拟点数(带小数点的数字)。我们需要注意的是,不同的处理器被设计用于做不同的事情,因此它们的ISA可能不同。然而,底线是任何ISA都应该是完整的,因为它应该能够用机器代码表达用户打算为其编写的所有程序。
-
简明。指令集的有限大小,最好不要有太多的指示。实现一条指令需要相当多的硬件,执行大量指令将不必要地增加处理器中晶体管的数量并增加其复杂性。因此,大多数指令集都有64到1000条指令。例如,MIPS指令集包含64条指令,而截至2012年,Intel x86指令集大约有1000条指令。请注意,对于ISA中的指令数量,1000条被认为是相当大的数字。
-
通用。指令应捕获通用案例,程序中的大多数常见指令都是简单的算术指令,如加法、减法、乘法、除法。最常见的逻辑指令是逻辑和、或、异或、和非。因此,为这些常见操作中的每一个指定一条指令是有意义的。
很少使用的计算的指令不是一个好主意。例如,实现计算sin−1(x)sin−1(x)的指令可能没有意义,可以提供使用现有的数学技术(如泰勒级数展开)实现的专用库函数来计算sin−1(x)sin−1(x)。由于大多数程序很少使用此函数,因此如果此函数执行时间相对较长,它们不会受到不利影响。
-
简单。指令应该尽量简单。假设有很多添加数字序列的程序,为了设计专门针对此类程序定制的处理器,我们有几个关于add指令的选项。我们可以实现一条将两个数字相加的指令,也可以实现一个可以获取操作数列表并生成列表和的指令。这里的复杂性显然存在差异,不能说哪种实现更快。前一种方法要求编译器生成更多指令,但是,每个添加操作都执行得很快。后一种方法生成的指令数量更少,但是,每条指令执行的时间更长。前一种类型的ISA称为精简指令集(Reduced Instruction Set),后一种ISA称为复杂指令集(Complex Instruction Set)。
精简指令集计算机(reduced instruction set computer,RISC)实现具有简单规则结构的简单指令,指令的数量通常很小(64到128)。示例:ARM、IBM PowerPC、HP PA-RISC。
复杂指令集计算机(complex instruction set computer,CISC)实现高度不规则的复杂指令,采用多个操作数,并实现复杂功能。其次,指令的数量很大(通常为500+)。示例:Intel x86、VAX。
直到90年代末,RISC与CISC的争论一直是一个非常有争议的问题。然而,从那时起,设计师、程序员和处理器供应商一直倾向于RISC设计风格,共识似乎是采用少量相对简单的、具有规则结构和格式的指令。值得注意的是,这一点仍有争议,因为CISC指令有时更适合某些类型的应用。现代处理器通常使用混合方法,其中既有简单的指令,也有一些复杂的指令。然而,在底层,CISC指令被转译成RISC指令。因此,我们认为行业稍微偏向RISC指令,认为有简单的指示是一种可取的特性。
ISA需要完整、简洁、通用和简单,且必须完整,而其余属性是可取的(但附有争议)。
19.4.4 图灵机和指令完整性
如何验证ISA的完整性?这是一个非常有趣、困难且理论上深刻的问题。确定给定ISA对于给定程序集是否完整的问题是一个相当困难的问题,一般情况要有趣得多。我们需要回答这个问题:给定ISA,它能代表所有可能的程序吗?
假设有一个ISA,其中包含基本的加法和乘法指令,我们能用这个ISA运行所有可能的程序吗?答案是否定的,因为我们不能用现有的基本指令减去两个数字。如果我们将减法指令添加到指令库中,我们可以计算一个数的平方根吗?即使我们可以,是否可以保证我们可以进行所有类型的计算?要回答这些令人烦恼的问题,我们需要首先设计一台通用机器。
通用机器(universal machine)是可以执行任何程序的机器。
它是一台可以执行所有程序的机器,可以把这台机器的每一个基本动作都当作一条指令。通用机器的一组动作就是它的ISA,而这个ISA是完整的。当说ISA是完整的时,相当于说可以专门基于给定的ISA构建通用机器,可以通过解决通用机器的设计问题来解决ISA的完整性问题。它们是双重问题,就通用机器而言,推理更容易。
20世纪初,计算机科学家开始思考通用机器的设计,他们想知道什么是可计算的,什么不是,以及不同类别机器的能力。其次,能够计算所有可能程序结果的理论机器的形式是什么?计算机科学的这些基本结果构成了当今现代计算机体系结构的基础。
阿兰·图灵(Alan Turing)是第一个提出一种极其简单和强大的通用机器的人,这台机器恰如其分地以他的名字命名,被称为图灵机器(Turing machine)。这只是一个理论实体,通常用作数学推理工具,可以创建图灵机的硬件实现,然而极为困难,并且需要不成比例的资源。尽管如此,图灵机构成了当今计算机的基础,而现代ISA是从图灵机的基本动作中派生出来的。因此,非常有必要研究它的设计。
下图显示了图灵机的一般结构,它包含一个内部磁带,磁带是一个单元阵列,每个单元格可以包含有限字母表中的符号,有一个特殊符号$用作特殊标记,一个专用的磁带头指向磁带中的一个单元。在一组状态中,有一小块存储器可以保存当前状态,该存储元件称为状态寄存器。

图灵机的操作非常简单。在每一步中,磁带头从状态寄存器中读取当前单元中的符号及其当前状态,并查找一个表,该表包含每个符号和状态组合的操作集,这个专用表称为转换函数表或动作表。这个表中的每个条目都说明了三件事——是否将磁带头向左或向右移动一步、下一个状态及应写入当前单元格的符号。因此,在每一步中,磁带头都可以覆盖单元格的值,改变状态寄存器中的状态,并移动到新单元格。唯一的限制是新单元格必须位于当前单元格的最左边或最右边。形式上,它的格式为:
(state, symbol)→({L,R}, new_state, new_symbol)(state, symbol)→({L,R}, new_state, new_symbol)
其中LL代表左边,RR代表右边。
示例:设计一个图灵机来判断字符串的形式是否为aaa...abb...bb。答案:让我们定义两个状态(Sa,Sb)(Sa,Sb)和两个特殊状态——exit和error。如果状态等于退出或错误,则计算停止。图灵机可以开始从右向左扫描输入,开始于状态(Sb)(Sb)。动作表如下:
(Sb,b)→(L,Sb,b)(Sb,a)→(L,Sa,a)(Sb,$)→(L, error ,$)(Sa,b)→(L, error ,b)(Sa,a)→(L,Sa,a)(Sa,$)→(L, exit,$)(Sb,b)→(L,Sb,b)(Sb,a)→(L,Sa,a)(Sb,$)→(L, error ,$)(Sa,b)→(L, error ,b)(Sa,a)→(L,Sa,a)(Sa,$)→(L, exit,$)
以上只是图灵机的简单应用案例,但实际场景中,复杂程度远远不止于此。我们可以立即得出结论,为即使是简单的问题设计图灵机也是不可能的。因为动作表会包含很多状态,并且很快就会超出大小,但基线是可以用这个简单的设备解决复杂的问题。事实上,这台机器可以解决各种问题,如天气建模、金融计算和微分方程的求解!
Church-Turing论文捕捉到了这一观察结果,该论文说,任何物理计算设备都可以计算的所有函数都可以由图灵机计算。用外行的话说,任何可以在人类已知的任何计算机上用确定性算法计算的程序,也可以用图灵机计算。
这篇论文在过去的半个世纪里一直坚定不移。到目前为止,研究人员还无法找到比图灵机器更强大的机器,意味着没有程序可以由图灵机之外的另一种机器计算。有一些程序可能需要很长时间才能在图灵机上进行计算,但它们也会占用所有其他计算机上的无限时间。我们可以用所有可能的方式扩展图灵机,可以考虑多个磁带、多个磁带头或每个磁带中的多个磁道。可以看出,这些机器中的每一个都像一个简单的图灵机一样强大。
上面描述的图灵机不是通用机器,因为它包含一个动作表,该动作表特定于机器正在计算的函数。一个真正的通用机器将具有相同的动作表、符号以及每个功能的相同状态集。如果我们能设计一个能模拟另一个图灵机的图灵机,我们就能制造一个通用图灵机——通用且不会特定于正在计算的函数。
让被模拟的图灵机被称为M,通用图灵机则被称为U。让我们首先为M的动作表创建一个通用格式,并将其保存在U磁带上的指定位置,每个动作都需要5个参数——旧状态、旧符号、方向(左或右)、新状态、新符号。我们可以使用一组常见的基本符号,可以是10位十进制数字(0-9),如果一个函数需要更多的符号,那么我们可以考虑将一个符号包含在一组由特殊分隔符划分的连续单元中。让这样的符号称为模拟符号。同样,模拟动作表中的状态也可以编码为十进制数。对于方向,我们可以使用0表示左侧,1表示右侧。因此,单个动作表条目可能看起来像(@1334@34@0@1335@10@),其中“@”是分隔符,该条目表示,如果遇到符号34,我们将从状态1334移动到1335。我们向左移动(0),并写一个值10。因此,我们找到了一种对用于计算某个函数的图灵机的动作表、符号集和状态进行编码的方法。
类似地,我们可以指定磁带的一个区域来包含M的状态寄存器,称之为模拟状态寄存器。让M的磁带在U的磁带中有一个专用的空间,我们把这个空间称为工作区(work area)。这种组织如下图所示。

通用图灵机的布局。
磁带因此分为三部分,第一部分包含模拟动作表,第二部分包含模拟状态寄存器,最后一部分包含包含一组模拟符号的工作区。通用图灵机(U)有一个非常简单的动作表和一组状态,其思想是在模拟动作表中查找与模拟状态寄存器中的值和磁带头下的模拟符号相匹配的正确条目。然后,通用图灵机需要通过移动到新的模拟状态来执行相应的动作,并在需要时覆盖工作区中的模拟符号。为了做每一个基本动作,U需要做几十次磁带头运动。然而,结论是我们可以构造一个通用的图灵机。
可以构造一个通用的图灵机,它可以模拟任何其他的图灵机器。
自20世纪50年代以来,研究人员设计了更多类型的具有自己的状态和规则集的假想机器,这些机器中的每一台都已被证明至多与图灵机一样强大。所有机器和计算系统都有一个通用名称,它们都像图灵机一样具有表达力和功能。这种系统可以说是图灵完整的(Turing complete)。因此,任何通用机器和ISA都是图灵完整的。
任何等同于图灵机的计算系统都被称为图灵机。
因此,如果ISA是图灵完整的,我们需要证明ISA是完整的或通用的。
现在考虑一个更适合实际实现的通用图灵机的变体(下图),让它具有以下特性。请注意,这样的机器已经被证明是图灵完整的。

一种改进的通用图灵机
1、磁带为半无限(semi-infinite,仅在一个方向上延伸至无限)。
2、模拟状态是指向模拟动作表中的条目的指针。
3、每个状态的模拟动作表中有一个唯一的条目。在查找模拟动作表时,我们不关心磁带头下的符号。
4、一个动作指示磁带头访问工作区中的一组位置,并根据它们的值使用简单的算术函数计算一个新值。它将此新值写入工作区中的新位置。
5、默认的下一个状态是动作表中的后续状态。
6、如果磁带上某个位置的符号小于某个值,动作也可以任意改变状态,意味着模拟磁带头将开始从模拟动作表中的新区域提取动作。
这台图灵机建议采用以下形式的机器组织。有大量指令(动作表),这个指令数组通常被称为程序。有一个状态寄存器,用于维护指向数组中当前指令的指针,称为程序计数器,可以更改程序计数器以指向新指令。有一个大的工作区,可以存储、检索和修改符号,此工作区也称为数据区。指令表(程序)和工作区(数据)保存在我们改进的图灵机的磁带上。在实际的机器中,有限磁带可被看作内存。存储器是一个大的存储单元阵列,其中存储单元包含一个基本符号。内存的一部分包含程序,另一部分包含数据。
此外,每条指令都可以读取内存中的一组位置,计算它们上的一个小算术函数,并将结果写回内存,还可以根据内存中的值跳转到任何其他指令。有一个专用单元来计算这些算术函数,写入内存,并跳转到其他指令,被称为CPU(中央处理单元)。下图显示了该机器的概念组织。

基本指令处理器。
上面我们已经捕获了图灵机的所有方面:状态转换、磁带头的移动、重写符号以及基于磁带头下符号的决策。这种机器与冯·诺依曼机器非常相似,后者构成了当今计算机的基础。
现在,让我们尝试为改进的图灵机设计一个ISA,有可能有一个只包含一条指令的完整ISA,考虑一个与改进的图灵机兼容并且已经被证明是图灵完备的指令。
sbn a, b, c
sbn表示减法,如果为负数则分支,此指令从a中减去b(a和b是存储器位置),将结果保存在a中。如果a<0,则跳转到指令表中位置c处的指令,否则,控制转移到下一条指令。例如,我们可以使用此指令将保存在位置a和b中的两个数字相加。请注意,退出是程序末尾的一个特殊位置。
1: sbn temp, b, 2
2: sbn a, temp, exit
这里假设内存位置temp已经包含值0。第一条指令将−b−b保存在temp中,不管结果的值如何,它都跳到下一条指令。请注意,标识符(数字:)是指令的序列号。在第二条指令中,计算a=a+b=a−(−b)a=a+b=a−(−b)。因此,成功地相加了两个数字,现在可以使用这段基本代码将数字从1加到10。我们假设变量计数器初始化为9,索引初始化为10,一初始化为1,和初始化为0。
1: sbn temp, temp, 2 // temp = 0
2: sbn temp, index, 3 // temp = -1 * index
3: sbn sum, temp, 4 // sum += index
4: sbn index, one, 5 // index -= 1
5: sbn counter, one, exit // loop is finished, exit
6: sbn temp, temp, 7 // temp = 0
7: sbn temp, one, 1 // (0 - 1 < 0), hence goto 1
我们观察到,这个小的操作序列运行for循环。退出条件在第5行,循环返回发生在第7行。在每一次迭代中,它都计算−sum+=index−sum+=index。
有许多类似的单指令ISA已经被证明是完整的,例如,如果小于等于,则进行减法和分支,如果借用(borrow),则进行反向减法和跳过,以及具有通用内存移动操作的计算机。
用一条指令编写一个程序是非常困难的,而且程序往往很长。没有理由吝啬指令的数量,通过考虑大量的指令,可以使复杂程序的实现变得更加轻松。让我们尝试将基本的sbn指令分解为几个指令:
- 算术指令。可以有一组算术指令,如加法、减法、乘法和除法。
- 移动指令。可以有移动指令,在不同的内存位置移动值,允许将常量值加载到内存位置。
- 分支指令。需要根据计算结果或存储在内存中的值来改变程序计数器以指向新指令的分支指令。
记住这些基本原则,我们可以设计许多不同类型的完整ISA。需要注意的是,我们只需要三种类型的指令:算术(数据处理)、移动(数据传输)和分支(控制)。
在任何指令集中,至少需要三种类型的指令:
1、需要算术指令来执行加法、减法、乘法和除法等运算。大多数指令集也有这类专门的指令来执行逻辑运算,如逻辑OR和NOT。
2、需要数据传输指令,可以在内存位置之间传输值,并可以将常量加载到内存位置。
3、需要能够根据指令操作数的值在程序中的不同点开始执行指令的分支指令。
寄存器机(register machine)是指包含无限数量的命名存储位置,这些存储位置称为寄存器。寄存器可以随机访问,所有指令都使用寄存器名作为操作数。CPU访问寄存器,获取操作数,然后处理它们。还存在混合机器,它们可以增加存储空间带有寄存器的标准Von Neumann机器。寄存器是可以保存符号的存储位置。
存储器通常是非常大的结构,在现代处理器中,整个内存可以包含数十亿个存储位置,这种大小的内存的任何实际实现在实践中都相当缓慢。硬件中有一个一般的经验法则,大则慢,小则快。因此,为了实现快速操作,每个处理器都有一组可以快速访问的寄存器,寄存器的数量通常在8到64之间。算术和分支操作中的大多数操作数都存在于这些寄存器中,由于程序倾向于在任何时间点重复使用一小组变量,因此使用寄存器可以节省许多内存访问。然而,有时需要将内存位置引入寄存器或将寄存器中的值写回内存位置。在这些情况下,我们使用专用的加载和存储指令,在内存和寄存器之间传输值。大多数程序都有大多数纯寄存器指令,加载和存储指令的数量通常约为已执行指令总数的三分之一。
假设我们要将数字的3次方加到存储位置b和c中,并将结果保存在存储位置a中。带有寄存器的机器需要以下指令,假设r1、r2和r3是寄存器的名称,没有使用任何特定的(通用的、概念性的)ISA。
1: r1 = mem[b] // load b
2: r2 = mem[c] // load c
3: r3 = r1 * r1 // compute b^2
4: r4 = r1 * r3 // compute b^3
5: r5 = r2 * r2 // compute c^2
6: r6 = r2 * r5 // compute c^3
7: r7 = r4 + r6 // compute b^3 + c^3
4: mem[a] = r7 // save the result
mem是表示内存的数组,需要首先将值加载到寄存器中,然后执行算术计算,然后将结果保存回内存。上面的代码通过使用寄存器来节省内存访问,如果增加计算的复杂性,将节省更多的内存访问,因此,使用寄存器的执行速度会更快。最终的处理器组织如下图所示。

很明显,安排计算在堆栈上工作是不可取的,将有许多冗余负载和存储。尽管如此,对于打算计算长数学表达式的机器,以及程序大小是一个问题的机器,通常会选择堆栈。很少有基于堆栈的机器的实际实现,如Burroughs Large Systems、UCSD Pascal和HP 3000(经典)。Java语言在编译过程中假设一台基于堆栈的机器,由于基于堆栈的机器很简单,Java程序实际上可以在任何硬件平台上运行。当我们运行编译后的Java程序时,Java虚拟机(JVM)会动态地将Java程序转换为另一个可以在带有寄存器的机器上运行的程序。
基于累加器的机器使用一个寄存器,称为累加器(accumulator)。每条指令都将单个内存位置作为输入操作数,例如,加法运算将累加器中的值与存储器地址中的值相加,然后将结果存储回累加器。早期无法容纳寄存器的机器曾经有累加器,累加器能够减少内存访问的次数并加速程序。
累加器的某些方面已经渗透到英特尔x86处理器组中,这些处理器是2012年台式机和笔记本电脑最常用的处理器。对于大数的乘法和除法,这些处理器使用寄存器eax作为累加器。对于其他通用指令,任何寄存器都可以指定为累加器。
19.4.5 常见ISA
目前市面上流行的指令集包含ARM指令集和x86指令集。ARM是高级RISC机器(Advanced RISC Machines),是一家总部位于英国剑桥的标志性公司,截至2012年,包括苹果iPhone和iPad在内的大约90%的移动设备都运行在基于ARM的处理器上。同样,截至2012年超过90%的台式机和笔记本电脑运行在基于Intel或AMD的x86处理器上。ARM是RISC指令集,x86是CISC指令集。
还有许多其他为各种处理器量身定制的指令集,移动计算机的另一个流行指令集是MIPS指令集,基于MIPS的处理器也用于汽车和工业电子中的各种处理器。
对于大型服务器,通常使用IBM(PowerPC)、Sun(如今的Oracle,UltraSparc)或HP(PA-RISC)处理器。每个处理器系列都有自己的指令集,这些指令集通常是RISC指令集,大多数ISA共享简单的指令,如加法、减法、乘法、移位和加载/存储指令。除了这个简单的集合,他们使用了大量更专业的指令。在ISA中选择正确的指令集取决于处理器的目标市场、工作负载的性质以及许多设计时间限制,下表显示了流行的指令集列表。
| ISA | 类型 | 年份 | 厂商 | 位数 | 字节顺序 | 寄存器数 |
|---|---|---|---|---|---|---|
| VAX | CISC | 1977 | DEC | 32 | little | 16 |
| SPARC | RISC | 1986 | Sun | 32 | bi | 32 |
| SPARC | RISC | 1993 | Sun | 64 | bi | 32 |
| PowerPC | RISC | 1992 | Apple, IBM, Motorola | 32 | bi | 32 |
| PowerPC | RISC | 2002 | Apple, IBM | 64 | bi | 32 |
| PA-RISC | RISC | 1986 | HP | 32 | big | 32 |
| PA-RISC | RISC | 1996 | HP | 64 | big | 32 |
| m68000 | CISC | 1979 | Motorola | 16 | big | 16 |
| m68000 | CISC | 1979 | Motorola | 32 | big | 16 |
| MIPS | RISC | 1981 | MIPS | 32 | bi | 32 |
| MIPS | RISC | 1999 | MIPS | 64 | bi | 32 |
| Alpha | RISC | 1992 | DEC | 64 | bi | 32 |
| x86 | CISC | 1978 | Intel, AMD | 16 | little | 8 |
| x86 | CISC | 1985 | Intel, AMD | 32 | little | 8 |
| x86 | CISC | 2003 | Intel, AMD | 64 | 64 little | 16 |
| ARM | RISC | 1985 | ARM | 32 | bi (little default) | 16 |
| ARM | RISC | 2011 | ARM | 64 | bi (little default) | 31 |
19.4.6 指令实现机制
有一小组基本逻辑组件,可以以各种方式组合起来存储二进制数据,并对该数据执行算术和逻辑运算。如果要执行特定的计算,则可以构造专门为该计算设计的逻辑组件的配置。我们可以将以所需配置连接各种组件的过程视为编程的一种形式。生成的“程序”是硬件形式的,称为硬连线程序(hardwired program)。
现在考虑这个替代方案。假设我们构造了算术和逻辑函数的通用配置,这组硬件将根据施加到硬件的控制信号对数据执行各种功能。在定制硬件的原始情况下,系统接受数据并产生结果(下图a)。使用通用硬件,系统接受数据和控制信号并产生结果,因此程序员只需要提供一组新的控制信号,而不是为每个新程序重新布线硬件。

硬件和软件方法。
如何提供控制信号?答案很简单,但很微妙。整个程序实际上是一系列步骤,在每个步骤中,对一些数据执行一些算术或逻辑运算。对于每个步骤,都需要一组新的控制信号。让我们为每一组可能的控制信号提供一个唯一的代码,并在通用硬件中添加一个可以接受代码并生成控制信号的段(上图b)。
编程现在更容易了。我们需要做的是提供一个新的代码序列,而不是为每个新程序重新布线硬件。实际上,每个代码都是一条指令,部分硬件解释每个指令并生成控制信号。为了区分这种新的编程方法,一系列代码或指令被称为软件。
19.4.6.1 存储指令
让我们考虑加载指令:ld r1, 12[r2],此处将内存地址计算为r2和数字12的内容之和。ld指令访问此内存地址,获取存储的整数并将其存储在r1中。假设计算的内存地址指向整数的第一个存储字节(即小端表示),所以内存地址包含LSB。详情如下图(a)所示。存储操作则相反,将r1的值存储到存储器地址(r2+12)中,如下图(b)所示。

19.4.6.2 函数
回顾一下实现一个简单函数的基本要求。假设地址为A的指令调用函数foo,在执行函数foo之后,需要立即返回A处指令之后的指令,该指令的地址为A+4(如果我们假设A处的指令长度为4字节)。这个过程被称为从函数返回,地址(a+4)被称为返回地址。
返回地址(Return address)是进程在执行函数后需要分支到的指令的地址。
因此,实现函数有两个基本方面:1、调用或调用函数的过程;2、涉及从函数返回。
函数本质上是一块汇编代码,调用一个函数本质上是让PC指向这段代码的开头。我们可以将标签与每个函数相关联,标签应该与函数中的第一条指令相关联,调用函数就像分支到函数开头的标签一样简单。然而,这只是故事的一部分,我们还需要实现返回功能。因此,我们不能使用无条件分支指令来实现函数调用。
因此,让我们提出一个专用的函数调用指令,它分支到函数的开头,同时保存函数需要返回的地址(称为返回地址)。让我们考虑下面的C代码,并假设每个C语句对应于一行汇编代码。
a = foo(); /* Line 1 */
c = a + b; /* Line 2 */
在这个小代码片段中,我们使用函数调用指令来调用foo函数,返回地址是第2行中指令的地址。调用指令必须将返回地址保存在专用存储位置,以便以后可以检索。大多数RISC指令集都有一个专用寄存器,称为返回地址寄存器(不妨称为ra),用于保存返回地址,返回地址寄存器由函数调用指令自动填充。当我们需要从函数返回时,我们需要分支返回地址寄存器中包含的地址。
如果foo调用另一个函数会发生什么?在这种情况下,ra中的值将被覆盖。我们稍后将讨论这个问题。现在让我们考虑将参数传递给函数并返回返回值的问题。
假设函数foo调用函数foobar。foo被称为调用者(caller),foobar被称为被调用者(callee)。请注意,调用方与被调用方的关系是不固定的。foo可以调用foobar,foobar也可以在同一个程序中调用foo。根据哪个函数调用另一个函数来决定单个函数调用的调用者和被调用者。
调用者和被调用者都看到相同的寄存器视图。因此,我们可以通过寄存器传递参数,同样也可以通过寄存器来传递返回值。然而,正如我们在下面列举的,在这个简单的想法中有几个问题(假设我们有16个寄存器)。
1、一个函数可以接受16个以上的参数,比我们现有的通用寄存器数量还要多,因此需要添加额外的空间来保存参数。
2、函数可以返回大量数据,例如C中的大型结构。这段数据可能不可能在寄存器中存储。
3、被调用者可能会覆盖调用者将来可能需要的寄存器。
因此,我们观察到,通过寄存器传递参数和返回值只适用于简单的情况,不是一个非常灵活和通用的解决方案。尽管如此,我们的讨论提出了两个要求:
- 空间问题。我们需要额外的空间来发送和返回更多的参数。
- 覆盖问题。我们需要确保被调用方不会覆盖调用方的寄存器。
为了解决这两个问题,需要更深入地了解函数是如何工作的。可以将函数foo想象成一个黑匣子,它接受一系列参数并返回一组值。要执行它的工作,foo可以花费一纳秒、一周甚至一年的时间。foo可以调用其他函数来完成它的工作、将数据发送到I/O设备以及访问内存位置。下图是函数foo的可视化。

总而言之,通用函数处理参数,根据需要从内存和I/O设备读取和写入值,然后返回结果。关于内存和I/O设备,目前我们并不特别关心,有大量可用内存,空间不是主要限制,读写I/O设备通常也与空间限制无关。主要问题是寄存器,因为它们供不应求。
让我们先解决空间问题,可以通过寄存器和内存传输值。为了简单起见,如果我们需要传输少量数据,我们可以使用寄存器,否则我们可以通过内存传输它们。类似地,对于返回值,我们可以通过内存传输值。如果我们使用内存传输数据,那么我们不受空间限制。然而,这种方法缺乏灵活性,因为调用者和被调用者之间必须就要使用的内存位置达成严格的协议。请注意,我们不能使用一组固定的内存位置,因为被调用方可以递归调用自己。
void foobar()
{
...
foobar();
...
}
精明的读者可能会认为,被调用方可以从内存中读取参数并将其转移到内存中的其他临时区域,然后调用其他函数。然而,这种方法既不优雅,也不十分有效。稍后将研究更优雅的解决方案。
因此可以得出结论,我们已经部分解决了空间问题。如果需要在调用者和被调用者之间传输一些值,或者反之亦然,可以使用寄存器。但是,如果参数/返回值不在可用寄存器集中,那么需要通过内存传输它们。对于通过内存传输数据,我们需要一个优雅的解决方案,它不需要调用者和被调用者之间就用于传输数据的内存位置达成严格的协议。
将寄存器保存在内存中并随后恢复的概念称为寄存器溢出(register spilling)。
要解决覆盖问题,有两种解决方案:1、调用者可以将所需的寄存器集保存在内存中的专用位置,可以在被调用方完成后检索其寄存器集,并将控制权返回给调用方。2、让被调用方保存和恢复它需要的寄存器。这两种方法都如下图所示。这种将寄存器值保存在内存中,然后再检索的方法称为溢出。

调用方保存和被调用方保存的寄存器。
我们又遇到了同样的问题,即调用者和被调用者都需要就需要使用的内存位置达成严格的协议。现在让我们一起努力解决这两个问题。
我们简化了向函数传递参数和从函数传递参数,以及使用内存中的专用位置保存/恢复寄存器的过程。然而,该解决方案被发现是灵活的,对于大型现实世界程序来说,实现起来可能相当复杂。为了简化这个想法,让我们在函数调用中定义一个模式。
典型的C或Java程序从主函数开始。然后,该函数调用其他函数,这些函数可能反过来调用其他函数。最后,当主函数退出时,执行终止。每个函数定义一组局部变量,并对这些变量和函数参数执行计算,它还可以调用其他函数。最后,函数返回一个值,很少返回一组值(C中的结构)。请注意,函数终止后,不再需要局部变量和参数。因此,如果其中一些变量或参数保存在内存中,我们需要回收空间。其次,如果函数溢出了寄存器,那么这些内存位置也需要在它退出后释放。最后,如果被调用方调用另一个函数,则需要将返回地址寄存器的值保存在内存中,还需要在函数退出后释放此位置。
最好将所有这些信息连续保存在一个内存区域中,被称为函数的激活块(activation block),下图显示了激活块的内存映射。

激活块包含参数、返回地址、寄存器溢出区(对于调用方保存和被调用方保存的方案)和局部变量。一旦函数终止,就可以完全摆脱激活块。一个函数如果想要返回一些值,那么可以使用寄存器这样做,但是它如果想要返回一个大的结构,那么就可以将其写入调用方的激活块中,调用方可以在其激活块中提供一个可以写入该数据的位置。后面有可能更优雅地做到这一点,在解释如何做到这一点之前,需要了解如何在内存中安排激活块。
我们可以有一个存储区域,其中所有的激活块都存储在相邻的区域中。考虑一个例子,假设函数foo调用函数foobar,foobar又调用foobarbar。下图显示了4个内存状态:(a)在调用foobar之前,(b)在调用foobarbar之前,(c)在调用foobarbar之后,(d)在foobarar返回之后。

在这个内存区域中有一个后进先出的行为,最后调用的函数是要完成的第一个函数,这种后进先出的结构传统上被称为计算机科学中的堆栈(stack),因此专用于保存激活块的存储区域称为堆栈。传统上,堆栈被认为是向下增长的(向更小的内存地址增长),意味着主功能的激活块从非常高的位置开始,新的激活块被添加到现有激活块的正下方(朝向较低的地址)。堆栈的顶部实际上是堆栈中最小的地址,而堆栈的底部是最大的地址。堆栈的顶部表示当前正在执行的函数的激活块,堆栈的底部表示初始主函数。
堆栈(stack)是保存程序中所有激活块的内存区域,一般情况是向下增长的。在调用函数之前,我们需要将其激活块推送到堆栈中,当函数完成执行时,需要将其激活块弹出到堆栈中。
堆栈指针寄存器(stack pointer register)保存指向堆栈顶部的指针。
大多数架构将指向堆栈顶部的指针保存在一个称为堆栈指针的专用寄存器中,常被称为sp。请注意,对于许多架构,堆栈是纯软件结构。对于他们来说,硬件不知道堆栈。但对于某些架构(如x86),硬件知道堆栈并使用它来推送返回地址或其他寄存器的值。即使在这种情况下,硬件也不知道每个激活块的内容,结构由程序集程序员或编译器决定。在所有情况下,编译器都需要显式添加汇编指令来管理堆栈。
为被调用方创建新的激活块涉及以下步骤。
1、将堆栈指针减小激活块的大小。
2、复制参数的值。
3、如果需要,通过写入相应的内存位置来初始化任何局部变量。
4、如果需要,溢出任何寄存器(存储到激活块)。
从函数返回时,必须销毁激活块,可以通过将激活块的大小添加到堆栈指针来完成。
通过使用堆栈,我们解决了所有问题。调用方和被调用方不能覆盖彼此的局部变量,局部变量保存在激活块中,两个激活块不重叠。除了变量之外,还可以通过在激活块中显式插入保存寄存器的指令来阻止被调用方重写调用方的寄存器。实现这一点有两种方法:调用者保存的方案和被调用方保存的方案。其次,无需就将用于传递参数的内存区域达成明确协议,堆栈可以用于此目的,调用者可以简单地将参数推送到堆栈上,这些参数将被推送到被调用方的激活块中,被调用方可以轻松使用它们。同样,当从函数,被调用方可以通过堆栈传递返回值,需要先通过减少堆栈指针来销毁其激活块,然后才能将返回值推送到堆栈上。调用方将知道被调用方的语义,因此在被调用方返回后,可以假定其激活块已被被调用方有效地放大,返回值占用了额外的空间。
ARM使用B/BL/BX/BLX等语句调用函数和返回函数,而x86使用call等指令调用函数,此外,x86和ARM都可使用ret指令返回地址。下面是ARM的函数调用示例代码:
.globl main
.extern abs
.extern printf
.text
output_str:
.ascii "The answer is %d\n\0"
@ returns abs(z)+x+y
@ r0 = x, r1 = y, r2 = z
.align 4
do_something:
push {r4, lr}
add r4, r0, r1
mov r0, r2
bl abs ; 调用abs
add r0, r4, r0
pop {r4, pc}
main:
push {ip, lr}
mov r0, #1
mov r1, #3
mov r2, #-4
bl do_something ; 调用do_something
mov r1, r0
ldr r0, =output_str
bl printf
mov r0, #0
pop {ip, pc}
有趣的指令是pushpop和bl,只需获取提供的寄存器列表并将其推到堆栈上,或者将其弹出并放入提供的寄存器中。bl只不过是带链接的分支,分支后的下一条指令的地址被加载到链接寄存器lr中。
一旦我们正在调用的例程被执行,lr就可以被复制回pc,将使CPU能够在bl指令之后从代码中继续。在do_someting中,我们将链接寄存器推送到堆栈,这样就可以再次将其弹出返回,即使对abs的调用将覆盖链接寄存器的原始内容。程序存储r4,因为Arm过程调用标准规定在函数调用之间必须保留r4-r11(下图),并且被调用的函数负责该保留,意味着do_someting需要将r0+r1的结果保存在一个不会被abs破坏的寄存器中,并且我们还必须保存用于保存该结果的任何寄存器的内容。当然,在这种特殊情况下,我们可以只使用r3,但是需要考虑的。我们推送并弹出寄存器,尽管我们不必保留它,因为过程调用标准要求堆栈64位对齐。这在使用堆栈操作时提供了性能优势,因为它们可以利用CPU内的64位数据路径。

我们可以直接压入高地址的值,毕竟如果abs需要注册,那么这就是它保存值的方式。推送r4而不是我们知道需要的值有一个小的性能问题,但最有力的论点可能是,在函数的开始和结束时只推送/弹出所需的任何寄存器,就可以减少错误发生的可能性,提高代码的可读性。此外,“main”函数还压入和弹出lr的内容,因为虽然主代码可能是我的代码中要执行的第一件事,但它不是加载程序时要执行的第二件事。编译器将在调用main之前插入对一些基本设置函数的调用,并在退出时进行一些最终清理调用。
现在让我们尝试将每条指令编码为32位值。假设有0、1、2和3地址格式的指令,其次,有些指令采用即时值,因此需要将32位划分为多个字段。假设有21条指令,则需要5位来编码指令类型,常规指令中的每个指令的代码如下表所示。我们可以使用32位字段中最重要的位来指定指令类型,指令的代码也称为操作码(opcode)。
| 指令 | 二进制码 |
|---|---|
| add | 00000 |
| sub | 00001 |
| mul | 00010 |
| div | 00011 |
| mod | 00100 |
| cmp | 00101 |
| and | 00110 |
| or | 00111 |
| not | 01000 |
| mov | 01001 |
| lsl | 01010 |
| lsr | 01011 |
| asr | 01100 |
| nop | 01101 |
| ld | 01110 |
| st | 01111 |
| beq | 10000 |
| bgt | 10001 |
| b | 10010 |
| call | 10011 |
| ret | 10100 |
现在,让我们尝试从0地址指令开始对每种类型的指令进行编码。
我们拥有的两条0地址指令是ret和nop。操作码由五个最重要的位指定,在这种情况下,ret等于10100,b等于10010(参见上表)。它们的编码如下图所示,我们只需要在MSB位置指定5位操作码,其余27位不需要。

编码ret指令。
我们拥有的1地址指令是call、b、beq和bgt,它们将标签作为参数。在编码指令时,我们需要指定标签的地址作为参数,标签的地址与它所指向的指令的地址相同。如果标签后的行为空,那么我们需要考虑下一条包含指令的汇编语句。
这四条指令的操作码需要5位,剩余的27位可用于地址。请注意,内存地址是32位长,不能用27位覆盖地址空间,但可以进行两个关键的优化。首先,可以假设PC相对寻址,可以假设27位指定了相对于当前PC的偏移量(正负)。现代程序中的分支语句是因为for/while循环或if语句而生成的,对于这些构造,分支目标通常在几百条指令的范围内。如果有27位来指定偏移量,并且假设它是2的补码,那么任何方向(正或负)的最大偏移量都是226,对于几乎所有的程序来说已足够。
还有另一个重要的观察。一条指令需要4个字节。如果假设所有指令都与4字节边界对齐,那么指令的所有起始内存地址都将是4的倍数,因此地址的至少两个有符号二进制数字将是00,没有理由在试图指定它们时浪费比特,可以假设27位指定包含指令的内存字(以4字节内存字为单位)地址的偏移量。通过这种优化,从PC的字节偏移量变为29位,即使是最大的程序,这个数字也应该足够。以防万一有极端的例子,其中分支目标距离超过228个字节,那么汇编程序需要将分支链接起来,这样一个分支将调用另一个分支,以此类推。这些指令的编码如下图所示。

1地址指令的编码(分支格式)。
请注意,1地址指令格式禁止使用0地址格式中未使用的位,可以将ret指令的0地址格式视为1地址格式的特例,1地址格式称为分支格式。以这种格式命名字段,将格式的操作码部分称为op,将偏移量称为offset。操作字段包含位置28-32的位,偏移字段包含位置1-27的位。
接下来考虑3地址指令:add、sub、mul、div、mod和或、lsl、lsr和asr。
考虑一个通用的3地址指令,它有一个目标寄存器、一个输入源寄存器和一个可以是寄存器或立即数的第二个源操作数。如果第二个源操作数是寄存器或立即数,需要将一位输入和输出。将其称为I位,并在指令中的操作码之后指定它。如果I=1,则第二个源操作数是立即数,如果I=0,则第二个源操作数是寄存器。
现在考虑将第二个源操作数作为寄存器(I=0)的3地址寄存器的情况。因为有16个寄存器,所以需要4位来唯一地指定每个寄存器。寄存器ri可以编码为i的无符号4位二进制等价物。因此,要指定目标寄存器和两个输入源寄存器,需要12位。结构如下图所示,此指令格式称为寄存器格式。像分支格式一样,不妨命名不同的字段:op(操作码,位:28-32)、I(立即数,位:27)、rd(目的寄存器,位:23-26)、rs1(源寄存器1,位:19-22)和rs2(源寄存器2,位:15-18)。

假设第二个源操作数是立即数,那么需要将I设置为1,接下来计算指定立即数所剩的位数。现在已经为操作码投入了5位,为I位投入了1位,为目标寄存器投入了4位,为第一个源寄存器投入了四位,总共花费了14位。因此,在32位中,剩下18位,可以使用它们来指定立即数。
建议将18位分为两部分:2位(修改器)+16位(立即数的常数部分),两个修改位可以取三个值:00(默认值)、01(“u”)和10(“h”)。当使用默认修改器时,剩余的16位用于指定16位2的补码数。对于u和h修改器,假设立即字段中的16位常量是无符号数。假设立即字段为18位长,具有修改部分和常量部分,处理器根据修改器将立即数内部扩展为32位值。
此编码如下图所示,可将此指令格式称为立即数格式。像分支格式一样,不妨命名不同的字段:op(操作码,位:28-32)、I(立即数,位:27)、rd(目标寄存器,位:23-26)、rs1(源寄存器1,位:19-22)和imm(立即数:1-18)。

用类似的方式,可以用下图所示的方式编码cmp、not和mov指令:

而加载指令的实现如下图:

19.4.7 ARM指令编码
ARM有四种类型的指令:数据处理(加/减/乘/比较)、加载/存储、分支和其他,需要2位来表示这些信息,这些位决定了指令的类型。下图显示了ARM中指令的通用格式。

对于数据处理指令,类型字段等于00,其余26位需要包含指令类型、特殊条件和寄存器。下图显示了数据处理指令的格式。


第26位称为I(立即数)位,类似于前面所述的I位。如果将其设置为1,则第二个操作数是立即数,否则是寄存器。由于ARM有16条数据处理指令,需要4位来表示它们,该信息保存在第22-25位。第21位保存S位,如果打开,则指令将设置CPSR。
其余20位保存输入和输出操作数。由于ARM有16个寄存器,需要4位来编码一个寄存器。第17-20位保存第一个输入操作数(rs)的标识符,要求是一个寄存器。第13-16位保存目标寄存器(rd)的标识符。
位1-12用于保存立即数或移位器操作数,下面看看如何最好地利用这12位。
ARM支持32位立即数,然而实际上只有12位来编码它们。不可能对所有232232个可能的值进行编码,需要从中选择一个有意义的子集,想法是使用12位对32位值的子集进行编码,硬件预计将解码这12位,并在处理指令时将其扩展到32位。
现在,12位是一个相当不灵活的值,既不是1字节,也不是2字节。有必要想出一个非常巧妙的解决方案,想法是将12位分为两部分:4位常量(rot)和8位有效载荷(payload),参见下图。

假设12位中编码的实际数字为n,有:
n=payload ror (2⋅rot)n=payload ror (2⋅rot)
其中ror是右旋操作。通过将有效载荷右旋2倍于rot字段中的值,获得实际数字n。现在试着理解这样做的逻辑。
数字n是32位值。一个天真的解决方案是使用12位来指定n的最小符号位,高阶位可以是0。然而,程序员倾向于以字节为单位访问数据和内存,因此1.5个字节对我们毫无用处。更好的解决方案是使用1字节的有效载荷,并将其放置在32位字段中的任何位置,其余4位用于此目的,它们可以对0到15之间的数字进行编码。ARM处理器将该值加倍,以考虑0到30之间的所有偶数,将有效载荷向右旋转该量。这样做的好处是可以对更广泛的数字集进行编码,对于所有这些数字,有8位对应于有效载荷,其余24位均为零。rot位仅确定32位字段中的哪8位被有效载荷占用。
同样地,通过合理地思考,可以得到以下的位移指令格式图:

此外,加载、存储指令格式如下:

而分支指令如下:

ARM Endian支持使用E-Bit加载/存储字:

19.4.8 x86指令编码
x86是真正的CISC指令集,其编码过程更为规律,几乎所有的指令都遵循标准格式。其次,x86中的操作码通常有多种模式和前缀。先看看编码机器指令的广泛结构,下图显示了二进制编码指令的结构。

x86二进制指令格式。

x86指令格式细节。
第一组1-4字节用于编码指令的前缀,rep前缀就是其中一个例子,还有许多其他类型的前缀可以在第一组1-4字节中编码。
接下来的1-3个字节用于对操作码进行编码,整个x86 ISA有数百条指令,操作码还编码操作数的格式。例如,加法指令可以将其第一个操作数作为内存操作数,也可以将其第二个操作数用作内存操作数。此信息也是操作码的一部分。
接下来的两个字节是可选的。第一个字节被称为ModR/M字节,用于指定源寄存器和目标寄存器的地址,第二个字节被称作SIB(标度索引基)字节,该字节记录基本缩放索引和基本缩放索引偏移寻址模式的参数,存储器地址可以可选地具有32位的位移(在本书中也称为偏移量)。因此,我们可以选择在一条指令中多4个字节来记录位移值。最后,一些x86指令接受立即数作为操作数,立即数也可以大到32位,因此,最后一个字段(也是可选的)用于指定立即数操作数。
ModR/M字节有三个字段,如下图所示:

SIB字节的结构如下图所示:

x86数字数据格式如下:

x86 EFLAGS寄存器:

x86控制寄存器:

MMX寄存器到浮点寄存器的映射:

19.5 处理器
19.5.1 指令处理概览
我们可以将处理器的操作大致分为五个阶段,如下图所示。

指令处理的五个阶段:指令获取、操作数获取、执行、内存访问、寄存器写入。

指令的多时钟周期管线图。图中时间从左到右在页面上前进,指令从页面的顶部到底部前进。管线阶段的表示沿指令轴放置在每个部分,占据适当的时钟周期。图中显示了每个阶段之间的管线寄存器,数据路径以图形方式表示管线的五个阶段,但命名每个管线阶段的矩形也同样有效。
第1步是从内存中获取指令。机器的底层组织并不重要,该机器可以是冯·诺依曼机器(共享指令和数据存储器),也可以是哈佛机器(专用指令存储器)。提取阶段有逻辑元件来计算下一条指令的地址,如果当前指令不是分支,那么需要将当前指令的大小(4字节)添加到存储在PC中的地址。但如果当前指令是分支,那么下一条指令的地址取决于分支的结果和目标。此信息从处理器中的其他单元获得。
第2步是解码“指令并从寄存器中取出操作数。不同指令类型所需的处理非常不同,例如加载存储指令使用专用的存储单元,而算术指令则不使用。为了解码指令,处理器有专用的逻辑电路,根据指令中的字段生成信号,这些信号随后被其他模块用来正确处理指令。像Intel处理器这样的商用处理器有非常复杂的解码单元,解码x86指令集非常复杂。不管解码的复杂程度如何,解码过程通常包括以下步骤:
- 提取操作数的值,计算嵌入的立即数并将其扩展到32或64位,以及生成关于指令处理的附加信息。
- 生成关于指令的更多信息的过程包括生成处理器专用信号。例如,可以为加载/存储指令生成“启用内存单元”形式的信号,对于存储指令,可以生成一个禁用寄存器写入功能的信号。
第3步是执行算术和逻辑运算。它包含一个能够执行所有算术和逻辑运算的算术和逻辑单元(ALU),ALU还需要计算加载存储操作的有效地址,通常情况下处理器的这一部分也计算分支的结果。
ALU(算术逻辑单元)包含用于对数据值执行算术和逻辑计算的元素,通常包含加法器、乘法器、除法器,并具有计算逻辑位运算的单元。
第4步包含用于处理加载存储指令的存储单元。该单元与存储器系统接口,并协调从存储器加载和存储值的过程。典型处理器中的内存系统相当复杂,其中一些复杂性是在处理器的这一部分中实现的。
第5步是将ALU计算的值或从存储器单元获得的加载值写入寄存器文件。
单个指令所需的处理称为指令周期。使用前面给出的简化的两步描述,指令周期如下图所示,这两个步骤被称为获取周期和执行周期。只有在机器关闭、发生某种不可恢复的错误或遇到使计算机停止的程序指令时,程序执行才会停止。

基本指令周期。
考虑一个使用假设机器的简单示例,该机器包括下图中列出的特性。处理器包含一个称为累加器(AC)的数据寄存器,指令和数据都是16位长,因此使用16位字组织内存是方便的。指令格式为操作码提供4位,因此可以有多达24=1624=16个不同的操作码,并且可以直接寻址多达212=4096212=4096(4K)个字的内存。

假想机器的特性。
下图说明了部分程序执行,显示了内存和处理器寄存器的相关部分。所示的程序片段将地址940处的存储字的内容添加到地址941处的内存字的内容,并将结果存储在后一位置。需要三条指令,可以描述为三个获取和三个执行周期:
1、PC包含300,即第一条指令的地址。该指令(十六进制值1940)被加载到指令寄存器IR中,PC递增。注意,此过程涉及使用内存地址寄存器和内存缓冲寄存器。为了简单起见,这些中间寄存器被忽略。
2、IR中的前4位(第一个十六进制数字)表示要加载AC,剩余的12位(三个十六进制数字)指定要加载数据的地址(940)。
3、从位置301获取下一条指令(5941),并且PC递增。
4、添加AC的旧内容和位置941的内容,并将结果存储在AC中。
5、从位置302取出下一条指令(2941),并且PC递增。
6、AC的内容存储在位置941中。

程序执行示例(内存和寄存器的内容为十六进制)。
特定指令的执行周期可能涉及对内存的不止一次引用。此外,指令可以指定I/O操作,而不是内存引用。考虑到这些额外的考虑因素,图下图提供了基本指令周期的更详细的视图,该图采用状态图的形式。对于任何给定的指令周期,某些状态可能为空,而其他状态可能被访问多次。


指令周期状态图。
状态描述如下:
- 指令地址计算(iac):确定要执行的下一条指令的地址,通常需要在前一条指令的地址上添加一个固定的数字,例如如果每条指令的长度为16位,并且内存被组织为16位字,则在前一个地址上加1。相反,如果内存被组织为可单独寻址的8位字节,则在前一个地址上加2。
- 指令获取(if):将指令从其内存位置读入处理器。
- 指令操作解码(iod):分析指令以确定要执行的操作类型和要使用的操作数。
- 操作数地址计算(oac):如果操作涉及对内存中的操作数的引用或通过I/O可用的操作数,则确定操作数的地址。
- 操作数获取(of):从内存中获取操作数或从I/O中读取操作数。
- 数据操作(do):执行指令中指示的操作。
- 操作数存储(os):将结果写入内存或输出到I/O。
下图显示了包括中断周期处理的修订指令周期状态图:

下图左是非直接时钟周期,右是中断时钟周期:

下图通过指出每种模块类型的主要输入和输出形式,说明了所需的交换类型:

微处理器寄存器组织示例:

19.5.2 处理器结构
19.5.2.1 处理器单元
处理器内部包含了诸多单元,诸如获取单元、数据路径和控制单元、操作数获取单元、执行单元(分支单元、ALU)、内存访问单元、寄存器回写单元等等。
下图显示了获取单元电路的实现。在一个周期中需要执行两个基本操作:1、下一个PC(程序计数器)的计算;2、获取指令。

电路中有两种元件:
- 第一类元件是寄存器、存储器、算术和逻辑电路,用于处理数据值。
- 第二类元素是决定数据流方向的控制单元。处理器中的控制单元通常生成信号以控制所有多路复用器(multiplexer),被称为控制信号(control signal),因为其作用是控制信息流。
因此,我们可以从概念上认为处理器由两个不同的子系统组成:
- 数据路径(data path)。它包含存储和处理信息的所有元素。例如,数据存储器、指令存储器、寄存器文件和ALU(算术逻辑单元)是数据路径的一部分。内存和寄存器存储信息,而ALU处理信息,例如,它将两个数字相加,并产生和作为结果,或者它可以计算两个数字的逻辑函数。
- 控制路径(control path)。它通过生成信号来引导信息的正确流动,生成一个信号,指示多路复用器在分支目标和默认下一个PC之间进行选择。在这种情况下,多路复用器由信号
isBranchTaken控制。
我们可以将控制路径和数据路径视为电路的两个不同元件,就像城市的交通网络一样。道路和红绿灯类似于数据路径,控制交通灯的电路构成了控制路径,控制路径决定灯光转换的时间。在现代智慧城市中,控制城市中所有交通灯的过程通常是集成的。如果有可能智能控制交通,使汽车绕过交通堵塞和事故现场。类似地,处理器的控制单元相当智能,它的工作是尽可能快地执行指令。现代处理器的控制单元已经非常复杂。
数据路径(data path):数据路径由处理器中专用于存储、检索和处理数据的所有元素组成,如寄存器、内存和ALU。
控制路径(control path):控制路径主要包含控制单元,其作用是生成适当的信号来控制数据路径中指令和数据的移动。

数据路径和控制路径之间的关系。
现在看看执行指令。首先将指令分为两种类型:分支和非分支。分支指令由计算分支结果和最终目标的专用分支单元处理,非分支指令由ALU(算术逻辑单元)处理。分支单元的电路如下图所示:

使用多路复用器在返回地址(op1)的值和指令中嵌入的branchT目标之间进行选择。isRet信号控制多路复用器,如果它等于1就选择op1,否则选择分支目标。多路复用器branchPC的输出被发送到提取单元。
下图显示了包含ALU的执行单元部分。ALU的第一个操作数(A)始终为op1(从操作数获取单元获得),但第二个操作数(B)可以是寄存器或符号扩展立即数,由控制单元生成的isImmediate信号决定,isImmediate信号等于指令中立即数位的值,如果是1,则图中的多路复用器选择immx作为操作数,如果为0,则选择op2作为操作数。ALU将一组信号作为输入,统称为aluSignals,aluSignals由控制单元生成,并指定ALU操作的类型。ALU的结果称为aluResult。

下图显示了ALU的一种设计。ALU包含一组模块,每个模块计算单独的算术或逻辑函数,如加法或除法。其次,每个模块都有一个启用或禁用它的专用信号,例如,当我们想执行简单的加法时,没有理由启用除法器。有几种方法可以启用或禁用单元,最简单的方法是为每个输入位使用一个传输门(transmission gate,见下下图),如果信号(S)打开,则输出反映输入值。否则,它将保持其以前的值。因此,如果启用信号关闭,则模块不会看到新的输入。因此,它不会耗散功率,并被有效禁用。

ALU。

传输门。
总之,下图展示了执行单元(分支单元和ALU)的完整设计。要设置输出(aluResult),需要一个多路复用器,可以从ALU中的所有模块中选择正确的输出,没有在图中显示此多路复用器。

执行单元(分支和ALU单元)。
下图显示了内存访问单元。它有两个输入{数据和地址,地址由ALU计算,它等于ALU的结果(aluResult),加载和存储指令都使用这个地址,地址保存在传统上称为MAR(内存地址寄存器)的寄存器中。

内存单元。
通过连接所有部分来形成整体。到目前为止,已经将处理器分为五个基本单元:指令获取单元(IF)、操作数获取单元(OF)、执行单元(EX)、内存访问单元(MA)和寄存器写回单元(RW)。是时候把所有的部分结合起来,看看统一的图片了(下图,省略了详细的电路,只关注数据和控制信号的流动)。

一个基础处理器。
19.5.2.2 控制单元
一个简单处理器的硬接线控制单元可以被认为是一个黑盒子,它以6位作为输入(5个操作码位和1个立即数位),并产生22个控制信号作为输出。如下图所示。

硬接线控制单元的抽象。

控制单元的结构图。
硬接线控制单元快速高效,这就是今天大多数商用处理器使用硬接线控制单元的原因,但硬接线控制单元并不十分灵活,例如在处理器出厂后,不可能更改指令的行为,甚至不可能引入新指令。有时如果功能单元中存在错误,需要更改指令的执行方式,例如如果乘法器存在设计缺陷,那么理论上可以使用加法器和移位单元运行布斯乘法算法。然而,我们需要一个非常复杂的控制单元来动态地重新配置指令的执行方式。
支持灵活的控制单元还有其他更实际的原因。某些指令集(如x86)具有重复指令给定次数的rep指令,它们还具有复杂的字符串指令,可以处理大量数据,支持此类指令需要非常复杂的数据路径。原则上,我们可以通过精心设计的控制单元来执行这些指令,而这些控制单元又有简单的处理器来处理这些指令,这些子处理器可以生成用于实现复杂CISC指令的控制信号。

数据路径和控制信号。

带内部总线的CPU。
19.5.2.3 基于微程序的处理器
前面已经研究了带有硬接线控制单元的处理器,设计了一个包含处理和执行指令所需的所有元素的数据路径。在输入操作数之间有选择的地方,添加了一个多路复用器,它由来自控制单元的信号控制。控制单元将指令的内容作为输入,并生成所有控制信号。现代高性能处理器通常采用这种设计风格。请注意,效率是有代价的,成本是灵活性。我们可能需要添加更多的多路复用器,并为每个新指令生成更多的控制信号。其次,在处理器交付给客户后,不可能向处理器添加新指令。有时候,我们渴望这样的灵活性。
通过引入将ISA中的指令转换为一组简单微指令的转换表,可以引入这种额外的灵活性。每个微指令都可以访问处理器的所有锁存器和内部状态元素。通过执行一组与指令关联的微指令,我们可以实现该指令的功能,这些微指令或微代码保存在微代码表中。通常可以通过软件修改该表的内容,从而改变硬件执行指令的方式。有几个原因需要这种灵活性,允许我们添加新指令或修改现有指令的行为。其中一些原因如下:
- 处理器在执行某些指令时有时会出现错误。因为设计师在设计过程中犯下的错误,或者是由于制造缺陷,其中一个著名的例子是英特尔奔腾处理器中的除法错误,英特尔不得不召回它卖给客户的所有奔腾处理器。如果可以动态地更改除法指令的实现,那么就不必调用所有处理器。因此可以得出结论,处理器的某种程度的可重构性有助于解决在设计和制造过程的各个阶段可能引入的缺陷。
- 英特尔奔腾4等处理器,以及英特尔酷睿i3和英特尔酷睿i7等更高版本的处理器,通过执行存储在内存中的一组微指令来实现一些复杂的指令。通常使用微码来实现数据串或指令的复杂操作,这些操作会导致一系列重复计算,意味着英特尔处理器在内部将复杂指令替换为包含简单指令的代码段,使得处理器更容易实现复杂的指令。我们不需要对数据路径进行不必要的更改,添加额外的状态、多路复用器和控制信号来实现复杂的指令。
- 当今的处理器只是芯片的一部分,有许多其他元件,被称为片上系统(system-on-chip,SOC)。例如,手机中的芯片可能包含处理器、视频控制器、相机接口、声音和网络控制器。处理器供应商通常会硬连线一组简单的指令,而与视频和音频控制器等外围设备接口的许多其他指令都是用微码编写的。根据应用程序域和外围组件集,可以定制微码。
- 有时使用一组专用微指令编写自定义诊断例程。这些例行程序在芯片运行期间测试芯片的不同部分,报告故障并采取纠正措施。这些内置自检(BIST)例程通常是可定制的,并以微码编写。例如,如果我们希望高可靠性,那么我们可以修改在CPU上执行可靠性检查的指令的行为,以检查所有组件。但是,为了节省时间,可以压缩这些例程以检查更少的组件。
因此,我们观察到,有一些令人信服的理由能够以编程方式改变处理器中指令的行为,以实现可靠性、实现附加功能并提高可移植性。因此,现代计算系统,尤其是手机和平板电脑等小型设备使用的芯片依赖于微码。这种微码序列通常被称为固件。
现代计算系统,尤其是手机、调制解调器、打印机和平板电脑等小型设备,使用的芯片依赖于微码。这种微码序列通常被称为固件(firmware)。
因此,让我们设计一个基于微程序的处理器,即使在处理器被制造并发送给客户之后,它也能为我们提供更大的灵活性来定制指令集。需要注意,常规硬接线处理器和微编程处理器之间存在着基本的权衡。权衡是效率与灵活性,不能指望有一个非常灵活的处理器,它既快速又省电。
19.5.2.4 微编程数据路径
让我们为微程序处理器设计数据路径,修改处理器的数据路径。处理器有一些主要单元,如提取单元、寄存器文件、ALU、分支单元和内存单元。这些单元是用导线连接的,只要有可能有多个源操作数,我们就在数据路径中添加一个多路复用器。控制单元的作用是为多路复用器生成所有控制信号。
问题是多路复用器的连接是硬接线的,不能建立任意连接,例如,不能将存储单元的输出发送到执行单元的输入。因此我们希望有一个组件之间没有固定互连的设计,理论上任何单位都可以向任何其他单位发送数据。
最灵活的互连是基于总线的结构。总线是一组连接所有单元的普通铜线,支持一个写入,在任何时间点支持多个读者。例如,单元A可以在某个时间点写入总线,所有其他单元都可以获得单元A写入的值。如果需要,可以将数据从一个单元发送到另一个单元,或从一个装置发送到一组其他单元。控制单元需要确保在任何时间点,只有一个单元写入总线,需要处理正在写入的值的单元从总线读取值。
现在让我们继续设计我们为硬连线处理器引入的所有单元的简化版本,这些简化版本可以适当地用于我们的微程序处理器的数据路径。
让我们从解释微程序处理器的设计原理开始。我们为每个单元添加寄存器,这些寄存器存储特定单元的输入数据,专用输出寄存器存储单元生成的结果,这两组寄存器都连接到公共总线。与硬连线处理器不同的是,在不同的单元之间存在大量的耦合,微程序处理器中的单元是相互独立的。他们的工作是执行一组操作,并将结果返回总线。每个单元就像编程语言中的一个函数,它有一个由一组寄存器组成的接口,用于读取数据,通常需要1个周期来计算其输出,然后该单元将输出值写入输出寄存器。
根据上述原理,下图中展示了提取单元的设计,它有两个寄存器:pc(程序计数器)和ir(指令寄存器)。pc寄存器可以从总线读取其值,也可以将其值写入总线,没有将ir连接到总线,因为没有其他单位对指令的确切内容感兴趣,其他单位只对指令的不同字段感兴趣。因此,有必要解码指令并将其分解为一组不同的字段,由解码单元完成。
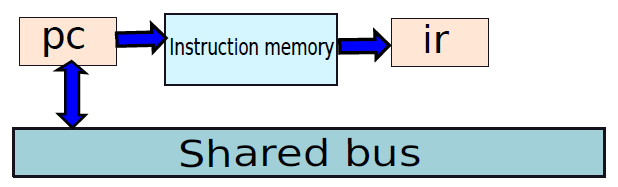
微程序处理器中的提取单元。
解码单元在功能上类似于操作数获取单元,但我们不在该单元中包含寄存器文件,而将其视为微程序处理器中的一个独立单元。下图显示了操作数获取单元的设计。
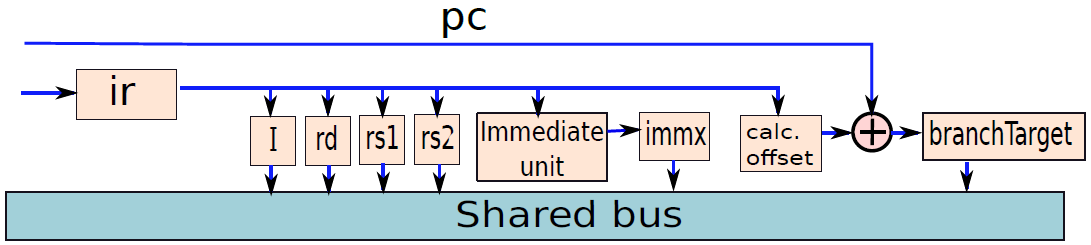
微程序处理器中的解码单元。
我们将解码单元和寄存器文件组合成一个单元,称为硬连线处理器的操作数获取单元,但更期望在微程序处理器中保持寄存器文件独立,因为在硬连线处理器中,它在解码指令后立即被访问。然而,微程序处理器可能不是这样——在指令执行期间,可能需要多次访问它。

微程序处理器中的寄存器文件。
ALU的结构如下图所示,有两个输入寄存器,A和B。ALU对寄存器A和B中包含的值执行操作,操作的性质由args值指定。例如,如果指定了加法运算,则ALU将寄存器A和B中包含的值相加。如果指定了减法运算,那么将从A中包含的数值减去B中的值,对于cmp指令,ALU更新标志。使用两个标志来指定相等和大于条件,分别保存在寄存器标志flags.E和标志flags.GT中,然后ALU运算的结果保存在寄存器aluResult中。此处还假设ALU在总线上指定args值后需要1个周期才能执行。
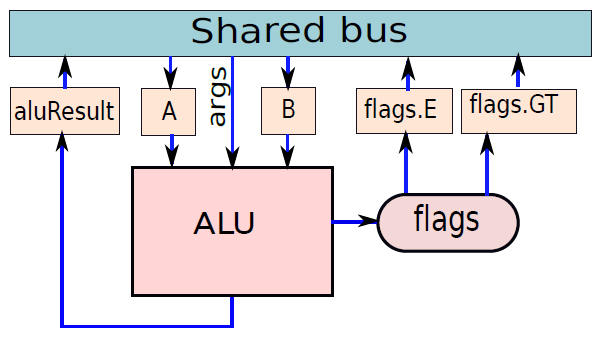
微程序处理器中的ALU。
内存单元如下图所示。与硬连线处理器一样,它有两个源寄存器:mar(内存地址寄存器)和mdr(内存数据寄存器),mar缓冲内存地址,mdr缓冲需要存储的值。还需要一组参数来指定内存操作的性质:加载或存储,加载操作完成后,ldResult寄存器中的数据可用。
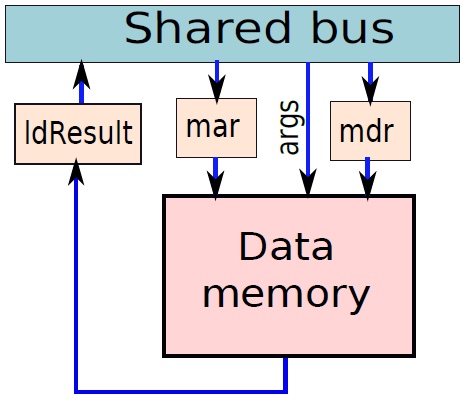
微程序处理器中的存储单元。
综上,微程序处理器中的数据路径总览如下:

19.5.3 管线处理器
19.5.3.1 管线概述
假设前面介绍的硬连线处理器需要一个周期来获取、执行和将指令的结果写入寄存器文件或内存。在电气层面上,是通过从提取单元经由其他单元流到寄存器写回单元的信号来实现的,而电信号从一个单元传播到另一个单元需要时间。
例如,从指令存储器中获取指令需要一些时间。然后需要时间从寄存器文件读取值,并用ALU计算结果。内存访问和将结果写回寄存器文件也是相当耗时的操作。需要等待所有这些单独的子操作完成,然后才能开始处理下一条指令,意味着电路中有大量的空闲,当操作数获取单元执行其工作时,所有其他单元都处于空闲状态。同样,当ALU处于活动状态时,所有其他单元都处于非活动状态。如果我们假设五个阶段(IF、OF、EX、MA、RW)中的每一个都需要相同的时间,那么在任何时刻,大约80%的电路都是空闲的!这代表了计算能力的浪费,空闲资源绝对不是一个好主意。
如果能找到一种方法让芯片的所有单元保持忙碌,那么就能提高执行指令的速度。
管线流程
不妨类比一下前面讨论的简单单周期处理器中的空闲问题。当一条指令在EX阶段时,下一条指令可以在OF阶段,而后续指令可以在IF阶段。事实上,如果在处理器中有5个阶段,简单地假设每个阶段花费的时间大致相同,可以假设同时处理5条指令,每条指令在处理器的不同单元中进行处理。类似于流水线中的汽车,指令在处理器中从一个阶段移动到另一个阶段。此策略确保处理器中没有任何空闲单元,因为处理器中的所有不同单元在任何时间点都很忙。
在此方案中,指令的生命周期如下。它在周期n中进入IF阶段,在周期n+1中进入OF阶段,周期n+2中进入EX阶段,循环n+3中进入MA阶段,最后在周期n+4中完成RW阶段的执行。这种策略被称为流水线(pipelining,又名管线、管道),实现流水线的处理器被称为流水处理器(pipelined processor)。五个阶段(IF、OF、EX、MA、RW)的顺序在概念上一个接一个地布置,称为流水线(pipeline,类似于汽车装配线)。下图显示了流水线数据路径的组织。

流水线数据路径。
上图中,数据路径分为五个阶段,每个阶段处理一条单独的指令。在下一个周期中,每条指令都会传递到下一个阶段,如图所示。
性能优势
现在,让我们考虑流水线处理器的情况,假设阶段是平衡的,意味着执行每个阶段需要相同的时间,大多数时候,处理器设计人员都会尽可能最大程度地实现这个目标。因此可以将r除以5,得出执行每个阶段需要r/5纳秒的结论,可以将循环时间设置为r/5。循环结束后,流水线每个阶段中的指令进入下一阶段,RW阶段的指令移出流水线并完成执行,同时,新指令进入IF阶段。如下图所示。
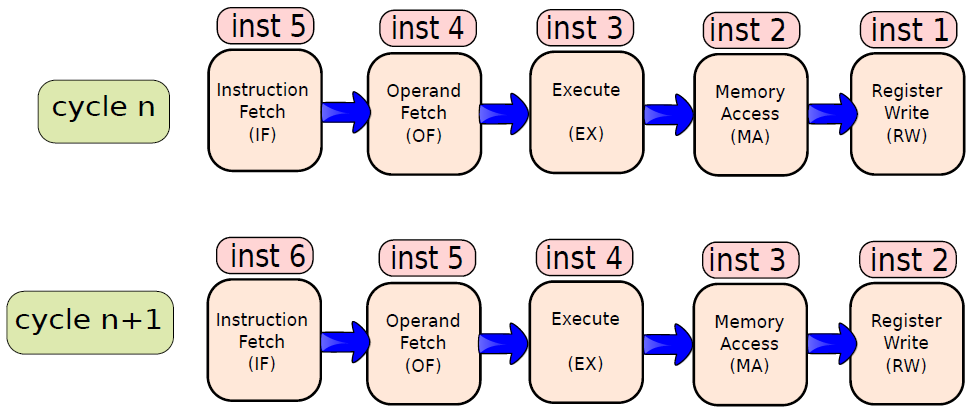
流水线中的指令。
如果我们可以用5阶段流水线获得5倍的优势,那么按照同样的逻辑,应该可以用100阶段流水线得到100倍的优势。事实上,可以不断增加阶段的数量,直到一个阶段只包含一个晶体管。但情况并非如此,流水线处理器的性能存在根本性的限制,不可能通过增加流水线阶段的数量来任意提高处理器的性能。在一定程度上,增加更多的阶段会适得其反。
下图a描述了不使用流水线的指令序列的时序,显然是一个浪费的过程,即使是非常简单的流水线也可以大大提高性能。下图b显示了两阶段流水线方案,其中两个不同指令的I级和E级同时执行。流水线的两个阶段是指令获取阶段和执行指令的执行/内存阶段,包括寄存器到内存和内存到寄存器的操作,因此我们看到第二条指令的指令提取阶段可以与执行/存储阶段的第一部分并行执行。然而,第二条指令的执行/存储阶段必须延迟,直到第一条指令清除流水线的第二阶段。该方案的执行率可以达到串行方案的两倍,两个问题阻碍了实现最大加速。首先,我们假设使用单端口内存,并且每个阶段只能访问一个内存,需要在某些指令中插入等待状态。第二,分支指令中断顺序执行流,为了以最小的电路来适应这种情况,编译器或汇编器可以将NOOP指令插入到指令流中。
通过允许每个阶段进行两次内存访问,可以进一步改进流水线,产生了下图c所示的序列。现在最多可以重叠三条指令,其改进程度为3倍,同样,分支指令会导致加速比达不到可能的最大值,请注意数据依赖性也会产生影响。如果一条指令需要被前一条指令更改的操作数,则需要延迟,同样可以通过NOOP实现。
由于RISC指令集的简单性和规则性,分为三个或四个阶段的设计很容易完成。下图d显示了4阶段管线的结果,一次最多可以执行四条指令,最大可能的加速是4倍。再次注意,使用NOOP来解释数据和分支延迟。

19.5.3.2 管线阶段
流水线处理器使用的电子构造有所不同,下面是不同阶段的一种设计:
流水线处理器中的IF阶段。
流水线处理器中的OF阶段。

流水线处理器中的EX阶段。
流水线处理器中的MA阶段。
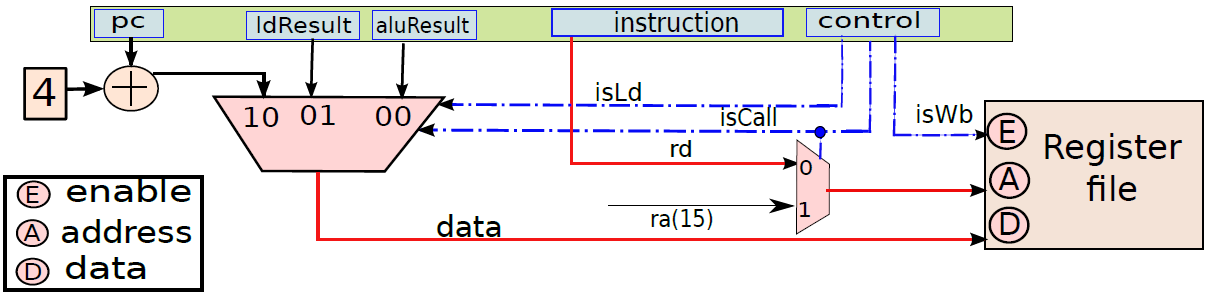
流水线处理器中的RW阶段。
现在通过下图显示的带有流水线寄存器的数据路径来总结关于简单流水线的讨论。注意,我们的处理器设计已经变得相当复杂,图表大小已经达到了一页,不想引入更复杂的图表。

流水线数据路径。
下图显示了流水线数据路径的抽象。该图主要包含不同单元的框图,并显示了四个流水线寄存器。我们将使用该图作为讨论先进流水线的基线。回想一下,rst寄存器操作数可以是指令的rs1字段,也可以是ret指令的返回地址寄存器。在ra和rs1之间选择多路复用器是基线流水线设计的一部分,为了简单起见,没有在图中显示它,假设它是寄存器文件单元的一部分。类似地,选择第二寄存器操作数(在rd和rs2之间)的多路复用器也被假定为寄存器文件单元的一部分,因此图中未示出,只显示选择第二个操作数(寄存器或立即数)的多路复用器。
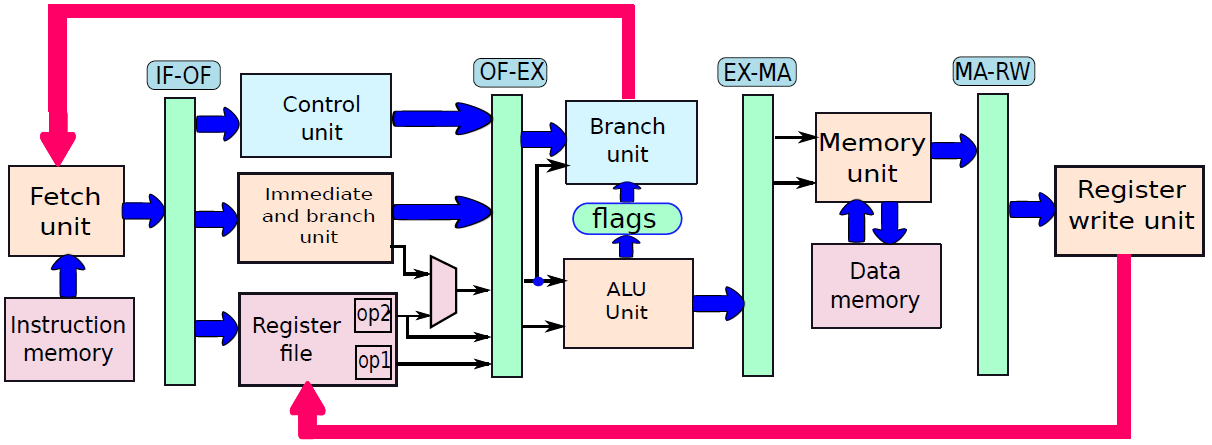
下图显示了三条指令通过管道时的流水线图,每一行对应于每个流水线阶段,列对应于时钟周期。在示例代码中,有三条相互之间没有任何依赖关系的指令,将这些指令分别命名为:[1]、[2]和[3]。最早的指令[1]在第一个周期进入流水线的IF阶段,在第五个周期离开流水线。类似地,第二条指令[2]在第二个周期中进入流水线的IF阶段,在第六个周期中离开流水线。这些指令中的每一条都会在每个循环中前进到流水线的后续阶段,流水线图中每条指令的轨迹都是一条朝向右下角的对角线。请注意,在考虑指令之间的依赖性之后,这个场景将变得相当复杂。
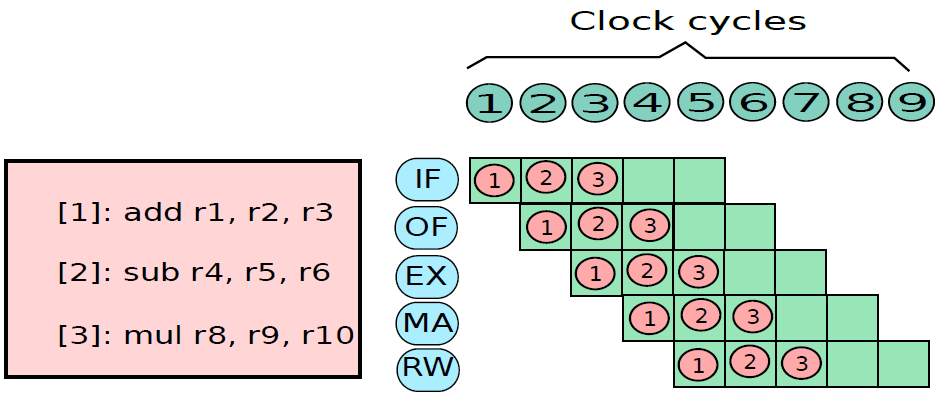

流水线示意图。
下面是构建流水线图的规则:
- 构建一个单元网格,该网格有5行和N列,其中N是希望考虑的时钟周期总数,每5行对应于一个流水线阶段。
- 如果指令([k])在周期m中进入流水线,那么在第一行的第m列中添加一个与[k]对应的条目。
- 在第(m+1)个周期中,指令可以停留在同一阶段(因为流水线可能会停顿,稍后将描述),也可以移动到下一行(OF阶段)。在网格单元中添加相应的条目。
- 以类似的方式,指令按顺序从IF级移动到RW级,它从不后退,但可以在连续的周期中保持在同一阶段。
- 一个单元格中不能有两个条目。
- 在指令离开RW阶段后,最终将其从流水线图中删除。
根据以上规则举个简单的例子,假设有以下代码:
add r1, r2, r3
sub r4, r2, r5
mul r5, r8, r9
为上述代码段构建的流水线图如下(假设第一条指令在周期1中进入流水线):
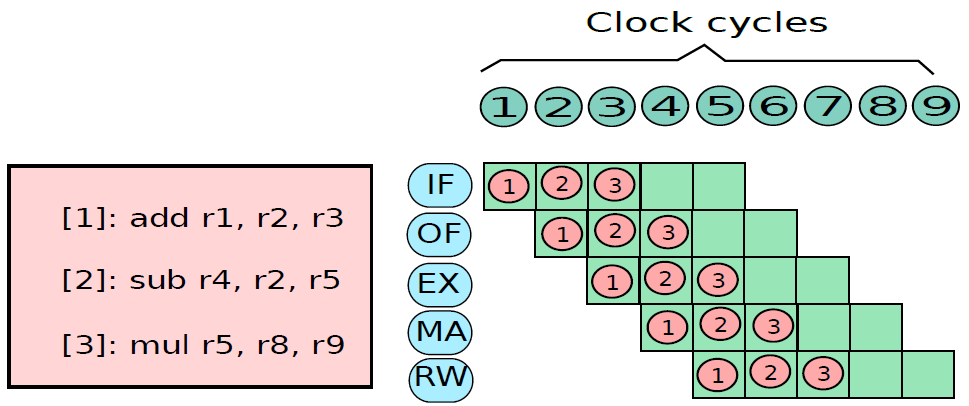
条件分支对指令流水线操作的影响:
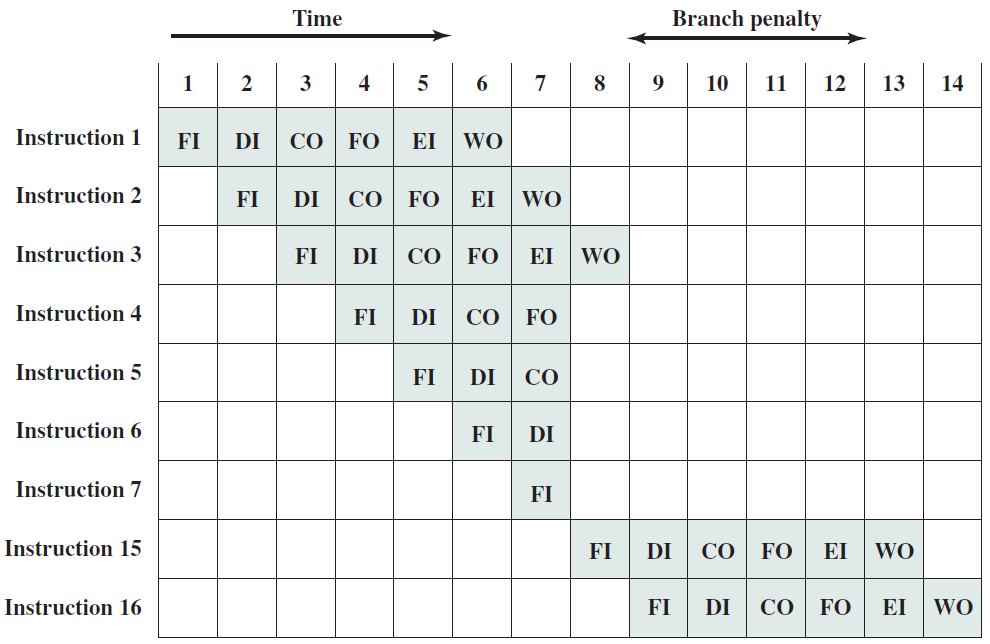
6阶段的CPU指令管线:

一个备选的管线描述:
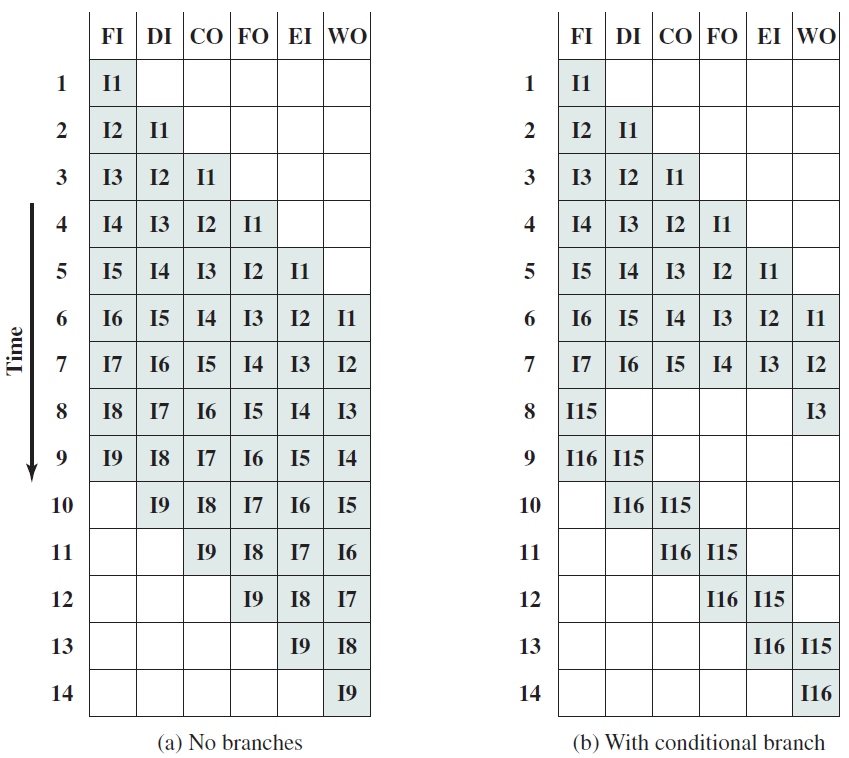
下图a将加速因子绘制为在没有分支的情况下执行的指令数的函数。正如可能预期的,在极限(n趋近正无穷),有k倍的加速。图b显示了作为指令管道中级数函数的加速因子。在这种情况下,加速因子接近可以在没有分支的情况下馈送到管道中的指令数。因此,管线阶段数越大,加速的可能性越大。然而,作为一个实际问题,额外管线阶段的潜在收益会因成本增加、阶段之间的延迟以及遇到需要刷新管线的分支而抵消。
19.5.3.3 管线冲突
让我们考虑下面的代码片段:
add r1, r2, r3
sub r3, r1, r4
此处的加法指令生成寄存器r1的值,子指令将其用作源操作数,这些指令构建一个流水线图如下所示。

显示RAW(写入后读取)危险的流水线图。
显示了有一个问题。指令1在第f个周期中写入r1的值,指令2需要在第3个周期中读取其值。这显然是不可能的,我们在两条指令的相关流水线阶段之间添加了一个箭头,以指示存在依赖关系。由于箭头向左(时间倒退),我们无法在管道中执行此代码序列,被称为数据冲突(亦称数据危险,data hazard),冲突被定义为流水线中错误执行指令的可能性,这种特殊情况被归类为数据冲突,除非采取适当措施,否则指令2可能会得到错误的数据。
冲突(hazard)被定义为流水线中错误执行指令的可能性,表示由于无法获得正确的数据而导致错误执行的可能性。
这种特定类型的数据危险被称为RAW(写入后读取)冲突。上面语句的减法指令试图读取r1,需要由加法指令写入。在这种情况下,读取会在写入之后。
请注意,这不是唯一一种数据冲突,另外两种类型的数据危害是WAW(写入后写入)和WAR(读取后写入)冲突,这些冲突在我们的流水线中不是问题,因为我们从不改变指令的顺序,前一条指令总是在后一条指令之前。相比之下,现代处理器具有以不同顺序执行指令的无序(out-of-order)流水线。
在有序流水线(如我们的流水线)中,前一条指令总是在流水线中的后一条指令之前。现代处理器使用无序(out-of-order)流水线来打破这一规则,并且可以让后面的指令在前面的指令之前执行。
让我们看看下面的汇编代码段:
add r1, r2, r3
sub r1, r4, r3
指令1和指令2正在写入寄存器r1。按照顺序,流水线r1将以正确的顺序写入,因此不存在WAW危险。然而,在无序流水线中,我们有在指令1之前完成指令2的风险,因此r1可能会以错误的值结束。这便是WAW冲突的一个例子。读者应该注意,现代处理器通过使用一种称为寄存器重命名(register renaming)的技术确保r1不会得到错误的值。
让我们举一个潜在WAR冲突的例子:
add r1, r2, r3
add r2, r5, r6
指令2试图写入r2,而指令1将r2作为源操作数。如果指令2先被执行,那么指令1可能会得到错误的r2值。实际上,由于寄存器重命名等方案,这在现代处理器中不会发生。我们需要理解,冲突是发生错误的理论风险,但不是真正的风险,因为采取了足够的措施来确保程序不会被错误地执行。
本文将主要关注RAW危害,因为WAW和WAR危害仅与现代无序处理器相关。让我们概述一下解决方案的性质,为了避免RAW危险,有必要确保流水线知道它包含一对指令,其中一条指令写入寄存器,另一条指令按程序顺序稍后从同一寄存器读取。它需要确保使用者指令正确地从生产者指令接收操作数(在本例中为寄存器)的值,我们将研究硬件和软件方面的解决方案。
现在看看当我们在流水线中有分支指令时会出现的另一种危险,假设有下面的代码片段:
[1]: beq .foo
[2]: mov r1, 4
[3]: add r2, r4, r3
...
...
.foo:
[100]: add r4, r1, r2
下图展示了前三条指令的流水线图:
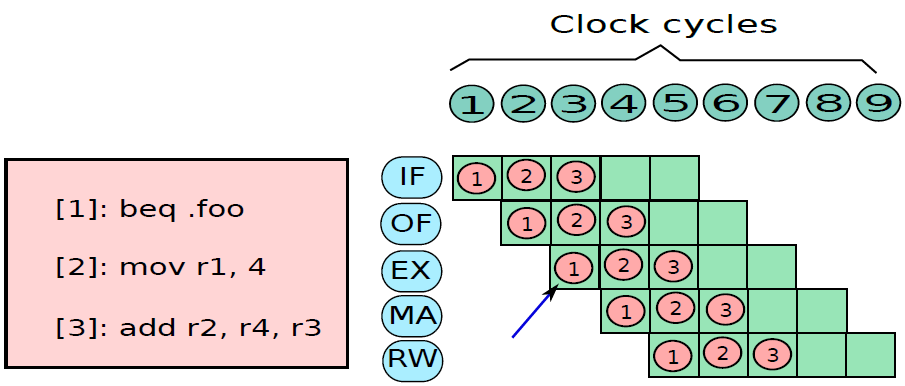
此处,分支的结果在循环3中被确定,并被传送到提取单元,提取单元从周期4开始提取正确的指令。如果执行了分支,则不应执行指令2和3。可悲的是,在周期2和周期3中,无法知道分支的结果。因此,这些指令将被提取,并将成为流水线的一部分。如果执行分支,则指令2和3可能会破坏程序的状态,从而导致错误,指令2和指令3被称为错误路径中的指令。这种情况称为控制冲突(control hazard)。如果分支的结果与其实际结果不同,则会执行的指令被认为是错误的。例如,如果执行分支,则程序中分支指令之后的指令路径错误。
控制冲突(control hazard)表示流水线中错误执行的可能性,因为分支错误路径中的指令可能会被执行并将结果保存在内存或寄存器文件中。
为了避免控制冲突,有必要识别错误路径中的指令,并确保其结果不会提交到寄存器文件和内存。应该有一种方法使这些指令无效,或者完全避免它们。
当不同的指令试图访问同一个资源,而该资源不能允许所有指令在同一周期内访问它时,就会出现结构冲突。让我们举个例子。假设我们有一条加法指令,可以从内存中读取一个操作数,它可以具有以下形式:
add r1, r2, 10[r3]
结构冲突(structural hazard)是指由于资源限制,指令可能无法执行。例如,当多个指令试图在同一周期内访问一个功能单元时,可能会出现这种情况,并且由于容量限制,该单元无法允许所有感兴趣的指令继续执行。在这种情况下,冲突中的一些指令需要暂停执行。
此处,有一个寄存器源操作数r2和一个内存源操作数10[r3],进一步假设流水线在OF阶段读取内存操作数的值。现在让我们来看一个潜在的冲突情形:
[1]: st r4, 20[r5]
[2]: sub r8, r9, r10
[3]: add r1, r2, 10[r3]
请注意,这里没有控制和数据冲突,尽管如此,让我们考虑流水线图中存储指令处于MA阶段时的一点。此时,指令2处于EX阶段,指令3处于OF阶段。请注意,在此循环中,指令1和3都需要访问存储单元。但如果我们假设内存单元每个周期只能服务一个请求,那么显然存在冲突情况,其中一条指令需要暂停执行。这种情况是结构冲突的一个例子。
由于具有典范性,后面我们把重点放在努力消除RAW和控制冲突上。
19.5.3.4 管线冲突解决
软件方案
现在,让我们找出一种避免RAW冲突的方法,假设有以下代码:
[1]: add r1, r2, r3
[2]: sub r3, r1, r4
指令2要求OF级中的r1值。然而,此时,指令1处于EX阶段,它不会将r1的值写回寄存器文件,因此不能允许指令2在流水线中继续。一个简单的软件解决方案是聪明的编译器可以分析代码序列并意识到存在RAW冲突,它可以在这些指令之间引入nop指令,以消除任何RAW冲突。考虑以下代码序列:
[1]: add r1, r2, r3
[2]: nop
[3]: nop
[4]: nop
[5]: sub r3, r1, r4
当子指令到达OF阶段时,加法指令将写入其值并离开流水线,因此子指令将获得正确的值。请注意,添加nop指令是一个成本高昂的解决方案,因为我们实际上是在浪费计算能力。在这个例子中,添加nop指令基本上浪费了3个周期。然而,如果考虑更长的代码序列,那么编译器可能会重新排序指令,这样就可以最小化nop指令的数量。任何编译器干预的基本目标都必须是在生产者和消费者指令之间至少有3条指令。
举个具体的例子,重新排序以下代码段,并添加足够数量的nop指令,以使其在流水线上正确执行:
add r1, r2, r3 ; 1
add r4, r1, 3 ; 2
add r8, r5, r6 ; 3
add r9, r8, r5 ; 4
add r10, r11, r12 ; 5
add r13, r10, 2 ; 6
答案是:
add r1, r2, r3 ; 1
add r8, r5, r6 ; 3
add r10, r11, r12 ; 5
nop
add r4, r1, 3 ; 2
add r9, r8, r5 ; 4
add r13, r10, 2 ; 6
我们需要理解这里的两个重要点:第一个是nop指令的能力,第二个是编译器的能力,编译器是确保程序正确性和提高性能的重要工具。在这种情况下,我们希望以这样一种方式重新排序代码,即引入最小数量的nop指令。
接下尝试使用相同的技术解决控制冲突。
如果再次查看流水线图,就会发现分支指令和分支目标处的指令之间至少需要两条指令,这是因为在EX阶段结束时得到分支结果和分支目标。此时,流水线中还有两条指令。当分支指令分别处于OF和EX阶段时,这些指令已被提取,它们可能执行错了路径。在EX阶段确定分支目标和结果之后,我们可以继续在IF阶段获取正确的指令。
现在考虑当不确定分支结果时提取的这两条指令。如果分支的PC等于p1,则它们的地址分别为p1+4和p1+8。如果不采取行动,它们不会执行错误路径。但是,如果执行分支,则需要从管道中丢弃这些指令,因为它们位于错误的路径上。
让我们看看一个简单的软件解决方案,其中硬件假设分支指令之后的两条指令没有在错误的路径上,这两条指令的位置称为延迟时隙(delay slot)。通常可以通过在分支后插入两条nop指令来确保延迟间隙中的指令不会引入错误,但这样做不会获得任何额外的性能,可以取而代之地对在分支指令之前执行的两条指令进行绑定,并将它们移动到分支之后的两个延迟时隙中。
请注意,我们不能随意将指令移动到延迟时隙,不能违反任何数据依赖约束,还需要避免RAW冲突,另外,我们不能将任何比较指令移动到延迟时隙中。如果没有适当的指令可用,那么我们总是可以返回到普通的解决方案并插入nop指令。也有可能我们只需要找到一条可以重新排序的指令,然后只需要在分支指令之后插入一条nop指令。延迟分支方法是一种非常有效的方法,可以减少需要添加以避免控制冲突的nop指令的数量。
在简单流水线数据路径中,分支后获取的两条指令的PC分别等于p1+4和p1+8(p1是分支指令的PC)。由于编译器确保这些指令始终在正确的路径上,而不管分支的结果如何,因此我们不会通过获取它们来提交错误。在确定分支的结果之后,如果不执行分支,则获取的下一条指令的PC等于p1+12,或者如果执行分支,PC等于分支目标。因此,在这两种情况下,在确定分支的结果后都会获取正确的指令,可以得出结论,软件解决方案在流水线版本的处理器上正确执行程序。
总之,软件技术的关键是延迟时隙的概念。在分支之后需要两个延迟时隙,因为不确定后续的两条指令,它们可能在错误的路径上。然而,使用智能编译器,可以设法将执行的指令移动到延迟时隙,而不管分支的结果如何。因此可以避免在延迟时隙中放置nop指令,从而提高性能。这种分支指令被称为延迟分支指令(delayed branch instruction)。
如果处理器假定在其结果确定之前获取的所有后续指令都在正确的路径上,则分支指令称为延迟分支(delayed branch)。如果处理器在提取分支指令的时间与确定其结果之间提取n条指令,那么我们就说我们有n个延迟时隙。编译器需要确保正确路径上的指令占用延迟时隙,并且不会引入额外的控制或RAW冲突。编译器还可以在延迟时隙中引入nop指令。
现在举个例子。重新排序下面的汇编代码,以便在具有延迟分支的流水线处理器上正确运行,假设每个分支指令有两个延迟时隙。
add r1, r2, r3 ; 1
add r4, r5, r6 ; 2
b .foo ; 3
add r8, r9, r10 ; 4
答案:
b .foo ; 3
add r1, r2, r3 ; 1
add r4, r5, r6 ; 2
add r8, r9, r10 ; 4
硬件方案
上面研究了消除RAW和控制冲突的软件解决方案,但编译器方法不是很通用,原因是:
- 首先,程序员总是可以手动编写汇编代码,并尝试在处理器上运行它。在这种情况下,错误的可能性很高,因为程序员可能没有正确地重新排序代码以消除冲突。
- 其次,还有可移植性问题。为一条流水线编写的一段汇编代码可能无法在遵循相同ISA的另一条流水线上运行,因为它可能具有不同数量的延迟时隙或不同数量的阶段。如果我们的汇编程序不能在使用相同ISA的不同机器之间移植,那么引入汇编程序的主要目标之一就失败了。
让我们尝试在硬件层面设计解决方案,硬件应确保无论汇编程序如何,都能正确运行,输出应始终与单周期处理器产生的输出相匹配。为了设计这样的处理器,需要确保指令永远不会接收错误的数据,并且不会执行错误的路径指令。可以通过确保以下条件成立来实现:
- 数据锁定(Data-Lock)。我们不能允许指令离开OF阶段,除非它从寄存器文件接收到正确的数据,意味着需要有效地暂停IF和OF阶段,并让其余阶段执行,直到OF阶段中的指令可以安全地读取其操作数。在此期间,从OF阶段传递到EX阶段的指令需要是nop指令。
- 分支锁定(Branch-Lock)。我们从不在错误的路径上执行指令,要么暂停处理器直到结果已知,要么使用技术确保错误路径上的指令不能将其更改提交到内存或寄存器。
在流水线的纯硬件实现中,有时需要阻止新指令进入流水线阶段,直到某个条件停止保持。停止流水线阶段接受和处理新数据的概念称为流水线暂停(pipeline stall)或流水线互锁(pipeline interlock)。其主要目的是确保程序执行的正确性。
如果我们确保数据锁定和分支锁定条件都成立,那么流水线将正确执行指令。请注意,这两种情况都要求管道的某些阶段可能需要暂停一段时间,这些暂停也称为流水线互锁。换言之,通过保持流水线空闲一段时间,可以避免执行可能导致错误执行的指令。下表是纯软件和硬件方案实现流水线的整个逻辑的利弊。请注意,在软件解决方案中,我们尝试重新排序代码,然后插入最小数量的nop指令,以消除冲突的影响。相比之下,在硬件解决方案中,我们动态地暂停部分流水线,以避免在错误的路径中执行指令,或使用错误的操作数值执行指令。暂停流水线相当于让某些阶段保持空闲,并在其他阶段插入nop指令。
| 属性 | 软件 | 硬件(互锁) |
|---|---|---|
| 可移植性 | 仅限于特定处理器 | 程序可以在任何处理器上运行 |
| 分支 | 通过使用延迟时隙,可能没有性能损失 | 本文需要暂停流水线2个周期 |
| RAW冲突 | 可以通过代码调度消除它们 | 需要暂停流水线 |
| 性能 | 高度依赖于程序的特性 | 带联锁的流水线的基本版本会比软件慢 |
我们观察到,软件解决方案的效率高度依赖于程序的性质,可以对某些程序中的指令重新排序,以完全隐藏RAW冲突和分支的有害影响。然而,在某些程序中,我们可能没有找到足够的可以重新排序的指令,因此被迫插入大量nop指令,会降低性能。相比之下,一个遵守数据锁和分支锁条件的纯硬件方案,只要检测到可能错误执行的指令,就会暂停流水线。这是一种通用方法,比纯软件解决方案慢。
现在可以将硬件和软件解决方案结合起来,重新排序代码,使其尽可能对流水线友好,然后在带有互锁的流水线上运行它。注意,在这种方法中,编译器不保证正确性,只是将生产者指令和消费者指令尽可能分开,并在支持它们的情况下利用延迟分支。这减少了我们需要暂停流水线的次数,并确保了两全其美。在设计带互锁的流水线前,下面借助流水线图来研究互锁的性质。
现在绘制带有互锁的流水线图,考虑下面的代码片段。
add r1, r2, r3
sub r4, r1, r2
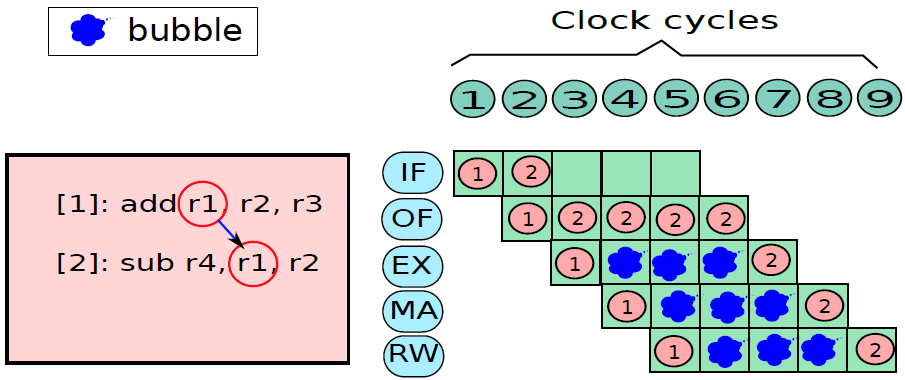
带气泡的流水线图。
指令[1]写入寄存器r1,指令[2]从r1读取,显然存在RAW依赖关系。为了确保数据锁定条件,我们需要确保指令[2]仅在读取了指令[1]写入的r1值时才离开OF阶段,仅在循环6中可行(上图),然而指令[2]在周期3中到达OF阶段。如果没有冲突,则理想情况下它会在周期4中进入EX阶段。由于我们有互锁,指令[2]也需要在周期4、5和6中保持在OF阶段中。问题是,当EX阶段在周期4、5和6中没有处理有效指令时,它会做什么?类似地,MA阶段在周期5、6和7中不处理任何有效的指令。我们需要有一种方法来禁用流水线阶段,这样我们就不会执行多余的工作,标准方法是将nop指令插入阶段。
再次参考上图。在循环3结束时,知道需要引入互锁,因此在周期4中,指令[2]保留在OF阶段,将nop指令插入EX阶段,该nop指令在周期5中移动到MA级,在周期6中移动到RW级。该nop命令称为流水线气泡。气泡是由互锁硬件动态插入的nop指令,在类似于正常指令的流水线阶段中移动。同样,在循环5和6中,我们需要插入管线气泡。最后,在周期7中,指令[2]可以自由地进入EX和后续阶段。气泡不起任何作用,因此当阶段遇到气泡时,没有任何控制信号打开。要注意的另一个微妙的点是,不能在同一个周期内对同一个寄存器进行读写,需要优先选择写入,因为它是较早的指令,而读取需要暂停一个周期。
实现气泡有两种方法:
- 可以在指令包中有一个单独的气泡位。每当位为1时,该指令将被解释为一个气泡。
- 可以将指令的操作码更改为nop的操作码,并将其所有控制信号替换为0。这种方法更具侵入性,但可以完全消除电路中的冗余工作。在前一种方法中,控制信号将打开,由其激活的单元将保持运行。硬件需要确保气泡不能对寄存器或内存进行更改。
流水线气泡(pipeline bubble)是由互锁硬件动态插入流水线寄存器中的nop指令,气泡以与正常指令相同的方式在流水线中传播。
总之,通过在流水线中动态插入气泡,可以避免数据冲突。
接下来阐述div和mod指令等慢指令的问题。在大多数流水线中,这些指令很可能需要n(n>1)个周期才能在EX阶段执行。在n个周期的每个周期中,ALU完成div或mod指令的部分处理。每个这样的循环被称为T状态(T State),通常一个阶段具有1T状态,但慢指令的EX阶段有许多T状态。因此,为了正确实现慢指令,需要暂停IF和OF阶段(n-1)个周期,直到操作完成。
为了简单起见,我们将不再讨论这个问题,相反,继续进行简单的假设,即所有流水线阶段都是平衡的,并且需要1个周期来完成它们的操作。现在看看控制冲突,首先考虑以下代码片段。
[1]: beq .foo
[2]: add r1, r2, r3
[3]: sub r4, r5, r6
....
....
.foo:
[4]: add r8, r9, r10
如果分支被执行,可以在流水线中插入气泡,而不是使用延迟分支,否则不需要做任何事情。假设分支被去掉,这种情况下的流水线图如下所示。

在这种情况下,指令[1]的分支条件的结果在循环3中决定。此时,指令[2]和[3]已经在流水线中(分别在IF和of阶段)。由于分支条件求值为take,我们需要取消指令[2]和[3],否则它们将被错误执行。因此将它们转换为气泡,如上图所示,指令[2]和[3]在循环4中转换为气泡。其次,在循环4从正确的分支目标(.foo)中提取,因此指令[4]进入流水线。两个气泡都经过所有流水线阶段,最后分别在循环6和7中离开流水线。
因此可以通过在流水线中动态引入气泡来确保这两个条件(数据锁定和分支锁定)。下面更详细地看看这些方法。
为了确保数据锁定条件,需要确保OF阶段中的指令与后续阶段中的任何指令之间没有冲突,冲突被定义为可能导致RAW冲突的情况。换句话说,如果后续阶段的指令写入由OF阶段的指令读取的寄存器,则存在冲突。因此需要两个硬件来实现数据锁定条件,第一步是检查是否存在冲突,第二步是确保流水线停止。
首先看看冲突检测硬件。冲突检测硬件需要将OF阶段中的指令的内容与其他三个阶段(即EX、MA和RW)中的每个指令的内容进行比较,如果与这些指令中的任何一条发生冲突,可以声明有冲突。让我们关注检测冲突的逻辑,简要介绍一下冲突检测电路的伪代码,设OF阶段中的指令为[A],后续阶段中的一条指令为[B]。检测冲突的算法伪代码如下所示:
Data: Instructions: [A] and [B]
Result: Conflict exists (true), no conflict (false)
1 if [A].opcode 2 (nop,b,beq,bgt,call) then
/* Does not read from any register */
2 return false
3 end
4 if [B].opcode 2 (nop, cmp, st, b, beq, bgt, ret) then
/* Does not write to any register */
5 return false
6 end
/* Set the sources */
7 src1 [A]:rs1
8 src2 [A]:rs2
9 if [A].opcode = st then
10 src2 [A]:rd
11 end
12 if [A].opcode = ret then
13 src1 ra
14 end
/* Set the destination */
15 dest [B]:rd
16 if [B].opcode = call then
17 dest ra
18 end
/* Check if the first operand exists */
19 hasSrc1 true
20 if [A].opcode 2 (not,mov) then
21 hasSrc1 false
22 end
/* Check the second operand to see if it is a register */
23 hasSrc2 true
24 if [A].opcode =2 (st) then
25 if [A]:I = 1 then
26 hasSrc2 false
27 end
28 end
/* Detect conflicts */
29 if (hasSrc1 = true) and (src1 = dest) then
30 return true
31 end
32 else if (hasSrc2 = true) and (src2 = dest) then
33 return true
34 end
35 return false
用硬件实现上述算法很简单,只需要一组逻辑门和多路复用器,大多数硬件设计者通常用硬件描述语言(如Verilog或VHDL)编写类似于上述算法的电路描述,并依靠智能编译器将描述转换为实际电路。
我们需要三个冲突检测器(OF↔EX,OF↔MA,OF↔RWOF↔EX,OF↔MA,OF↔RW)。如果没有冲突,则指令可以自由地进入EX阶段,但如果至少有一个冲突,则需要暂停IF和OF阶段。一旦指令通过OF阶段,它就保证拥有所有的源操作数。
现在来看看流水线的暂停。我们基本上需要确保在发生冲突之前,没有新的指令进入IF和OF阶段,这可以通过禁用PC和IF-OF流水线寄存器的写入功能来简单地确保。因此,它们不能接受时钟边缘(clock edge)上的新数据,将继续保持它们以前的值。
其次,还需要在流水线中插入气泡,例如从OF传递到EX阶段的指令需要是无效指令或气泡,可以通过传递nop指令来确保。因此确保数据锁定条件的电路是直接的,需要一个连接到PC的冲突检测器和IF-OF寄存器。在发生冲突之前,这两个寄存器将被禁用,无法接受新数据。我们强制OF-EX寄存器中的指令包含nop,流水线的增强电路图如下图所示。
带互锁的流水线的数据路径(实现数据锁定条件)。
接下来阐述分支锁定条件。
假设流水线中有一条分支指令(b、beq、bgt、call、ret)。如果有延迟时隙,那么数据路径与上图所示的相同,不需要做任何更改,因为执行的整个复杂性已经加载到了软件中。然而,将流水线暴露于软件有其利弊,如果在管线中添加更多阶段,那么现有的可执行文件可能会停止工作。为了避免这种情况,让我们设计一个不向软件暴露延迟时隙的流水线。
有两个设计选项:
- 第一种:可以假设在确定结果之前不采取分支。我们可以继续在分支之后获取这两条指令并进行处理,一旦在EX阶段决定了分支的结果,就可以根据结果采取适当的行动。如果未执行分支,则在分支指令之后获取的指令位于正确的路径上,无需再执行任何操作。但是,如果执行了分支,则必须取消这两条指令,并用流水线气泡(nop指令)替换它们。
- 第二种:暂停流水线,直到分支的结果被确定,而不管结果如何。
显然,第二种设计的性能低于假设不采用分支的第一种替代方案,例如,如果一个分支30%的时间没有被占用,那么对于第一个设计,30%的时间都在做有用的工作。然而,对于第二个选项,我们在获取分支指令后的2个周期中从未做过任何有用的工作。
因此,让我们从性能的角度考虑第一个设计,只有在分支被占用时,才取消分支后的两个指令,这种方法为预测不采用(predict not
taken),因为实际上是在预测不采取的分支。稍后,如果发现此预测错误,则可以取消错误路径中的指令。
如果分支指令的PC等于p,那么选择在接下来的两个周期中在p+4和p+8处获取指令。如果分支没有被执行,那么将继续执行。但是,如果分支被执行,那么将取消这两条指令,并将它们转换为流水线气泡。
我们不需要对数据路径进行任何重大更改,需要一个小型分支冲突单元,从EX阶段接收输入。如果执行分支,则在下一个周期中,它将If-OF和OF-EX阶段中的指令转换为流水线气泡。带有分支互锁单元的扩展数据路径如下图所示。
带互锁的流水线的数据路径(实现数据锁定和分支锁定条件)。
接下来阐述带转发(Forwarding)的流水线。
上面已经实现了一个带有互锁的流水线。互锁确保流水线正确执行,而不管指令之间的依赖性如何。对于数据锁定条件,我们建议在流水线中添加互锁,在寄存器文件中有正确的值之前,不允许指令离开操作数获取阶段。然而,下面将看到,不必总是添加互锁。事实上,在很多情况下,正确的数据已经存在于流水线寄存器中,尽管不存在于寄存器文件中。可以设计一种方法,将数据从内部流水线寄存器正确地传递到适当的功能单元。考虑以下代码:
add r1, r2, r3
sub r4, r1, r2
下图仅包含这两条指令的流水线图,(a)显示了带互锁的流水线图,(b)显示了无互锁和气泡的流水线图。现在尝试论证不需要在指令之间插入气泡。

(a)带互锁的流水线图,(b)无互锁和气泡的流水线图。
让我们深入查看上图(b)。指令1在EX阶段结束时产生其结果,或者在周期3结束时产生结果,并在周期5中写入寄存器文件。指令2在周期3开始时需要寄存器le中的r1值,显然是不可能的,因此建议添加流水线互锁来解决此问题。
让我们尝试另一种解决方案,允许指令执行,然后在循环3中,[2]将获得错误的值,允许它在周期4中进入EX阶段。此时,指令[1]处于MA阶段,其指令包包含正确的r1值。r1值是在前一个周期中计算的,存在于指令包的aluResult字段中,[1] 的指令包在周期4中位于EX-MA寄存器中。现如果在EX-MA的aluResult字段和ALU的输入之间添加一个连接,那么可以成功地将r1的正确值传输到ALU。我们的计算不会出错,因为ALU的操作数是正确的,因此ALU运算的结果也将被正确计算。
下图显示了我们在流水线图中的操作结果,将指令[1]的MA阶段添加到指令[2]的EX阶段。由于箭头不会在时间上倒退,因此可以将数据(r1的值)从一个阶段转发(forward)到另一个阶段。
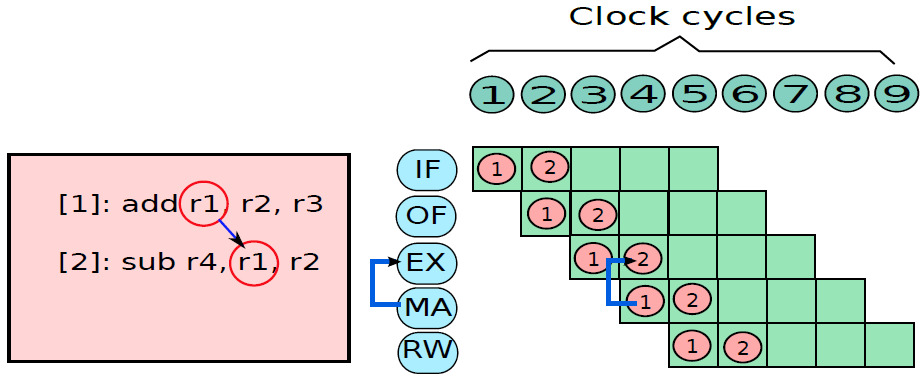
在流水线中转发的示例。
转发(Forwarding)是一种通过阶段之间的直接连接在不同流水线阶段中的指令之间传输操作数值的方法,不使用寄存器文件跨指令传输操作数的值,从而避免昂贵的流水线互锁。
我们刚刚研究了一种非常强大的技术,可以避免管线中的停顿,称为转发。本质上,我们允许操作数的值在指令之间流动,方法是跨阶段直接传递它们,不使用寄存器文件跨指令传输值。转发的概念允许我们背靠背地(以连续的周期)执行指令[1]和[2],不需要添加任何暂停周期。因此,不需要重新排序代码或插入nop。
为了在指令[1]和[2]之间转发r1的值,我们在MA级和EX级之间添加了一个连接,上图9中通过在指令[1]和[2]的相应阶段之间画一个箭头来显示这种联系。这个箭头的方向是垂直向上的,由于它没有在时间上倒退,有可能转发该值,否则是不可能的。
现在让我们尝试回答一个一般性问题——可以在所有指令对之间转发值吗?注意,不需要是连续的指令,即使生产者和消费者ALU指令之间有一条指令,我们仍然需要转发值。现在尝试考虑管线中各阶段之间的所有可能的转发路径。
广泛遵循的转发基本原则如下:
- 在后期和早期之间添加了转发路径。
- 在管线中尽可能迟地转发一个值。例如,如果给定阶段不需要给定值,并且可以在稍后阶段从生产者指令中获取该值,那么我们等待在稍后阶段获取转发的值。
请注意,这两个基本原则都不影响程序的正确性,它们只允许消除冗余的转发路径。现在,系统地看看管道中需要的所有转发路径:
-
RW --> MA:MA阶段需要来自RW阶段的转发路径,考虑下图所示的代码片段,指令[2]需要MA阶段(周期5)中的r1值,而指令[1]在周期4结束时从内存中获取r1值。因此,它可以在周期5中将其值转发给指令[2]。
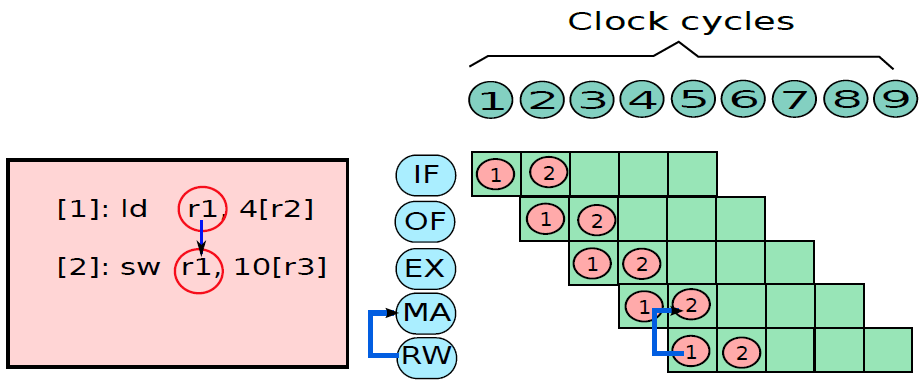
-
RW --> EX:下图所示的代码段显示了一条加载指令,它在周期4结束时获取寄存器r1的值,以及一条后续的ALU指令,它需要周期5中的r1值。因为不会在时间上倒退,所以可以转发该值。

-
MA --> EX:下图所示的代码段显示了一条ALU指令,该指令在周期3结束时计算寄存器r1的值,以及一条连续的ALU指令在周期4中需要r1的数值。在这种情况下,还可以通过在MA和EX级之间添加互连(转发路径)来转发数据。
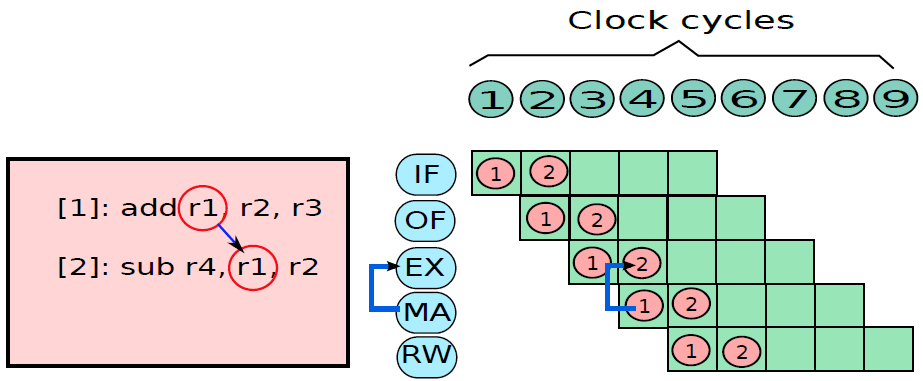
-
RW --> OF:通常OF阶段不需要转发路径,因为它没有任何功能单元,不需要立即使用值,可以稍后根据原则2转发价值。然而,唯一的例外是从RW阶段转发,无法稍后转发该值,因为指令将不在管线中。因此有必要添加从RW到OF级的转发路径,需要RW --> OF转发的代码段示例如下图所示。指令[1]通过在周期4结束时从内存中读取r1的值来生成r1值,然后它在周期5中将r1值写入寄存器文件。同时,指令[4]尝试在周期5的OF阶段读取r1值,不幸的是,这里存在冲突。因此,我们建议通过在RW和OF阶段之间添加转发路径来解决冲突。因此,禁止指令[4]读取r1值的寄存器文件。相反,指令[4]]使用RW --> OF转发路径从指令[1]获取r1值。
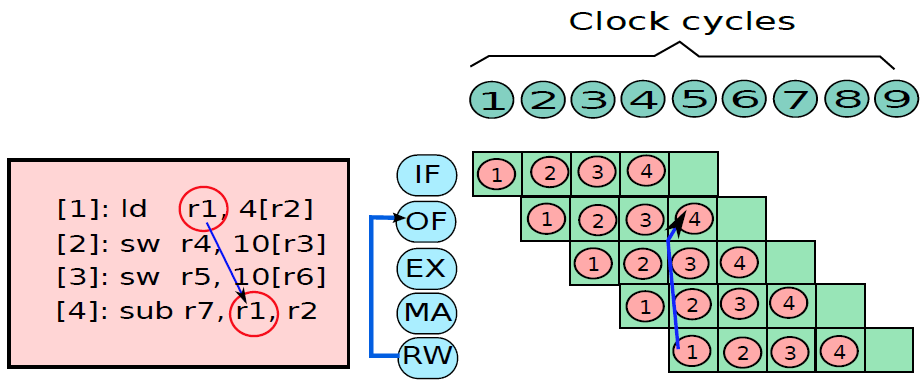
不需要添加以下转发路径:MA-->OF和EX-->OF,因为我们可以使用以下转发路径(RW-->EX)和(MA-->EX)。根据原则2,需要避免冗余转发路径,因此不添加从MA和EX级到OF级的转发路径。我们不向IF阶段添加转发路径,因为在这个阶段,还没有解码指令,不知道其操作数。
现在又衍生了一个问题:转发是否完全消除了数据冲突?
现在回答这个问题。先考量ALU指令,它们在EX阶段产生结果,并准备在MA阶段前进,任何后续的使用者指令都需要前一条ALU指令在EX阶段最早生成的操作数的值。此时可以实现成功的转发,因为操作数的值在MA阶段已经可用。如果生产者指令已离开流水线,则任何后续指令都可以使用任何可用的转发路径或从寄存器文件获取值。如果生产者指令是ALU指令,那么总是可以将ALU运算的结果转发给消费者指令。为了证明这一事实,需要考虑所有可能的指令组合,并判断是否可以将输入操作数转发给使用者指令。
唯一显式生成寄存器值的其他指令是加载指令。请记住,存储指令不会写入任何寄存器。让我们看看加载指令,加载指令在MA阶段结束时产生其值,因此它准备在RW阶段转发其值。考虑下图中的代码片段及其流水线图。

加载-使用冲突。
指令[1]是写入寄存器r1的加载指令,指令[2]是使用寄存器r1作为源操作数的ALU指令,加载指令在周期5开始时准备好转发。不幸的是,ALU指令在周期4开始时需要r1的值,故而需要在流水线图中绘制一个箭头,该箭头在时间上向后流动。因此,在这种情况下,转发是不可能的。
加载-使用冲突(Load-Use Hazard)是指加载指令将加载的值提供给在EX阶段需要该值的紧随其后的指令的情况。即使有转发,管线也需要在加载指令之后插入一个暂停周期。
这是需要在管线中引入暂停循环的唯一情况,这种情况被称为加载-使用冲突,加载指令将加载的值提供给在EX阶段需要该值的紧随其后的指令。消除加载-使用冲突的标准方法是允许管线插入气泡,或者使用编译器重新排序指令或插入nop指令。
总之,具有转发的管线确实可能需要互锁,唯一的特殊情况是加载-使用冲突。
请注意,如果在存储加载值的加载指令之后有一个存储指令,那么我们不需要插入暂停循环,因为存储指令需要MA阶段的值。此时,加载指令处于RW阶段,可以转发该值。
如果要实现管线的转发,需要根据不同的管线阶段来实现。
支持转发的OF阶段如下图所示,基线管道中没有转发的多路复用器用较浅的颜色着色,而为实现转发而添加的附加多路复用器被着色为较深的颜色。
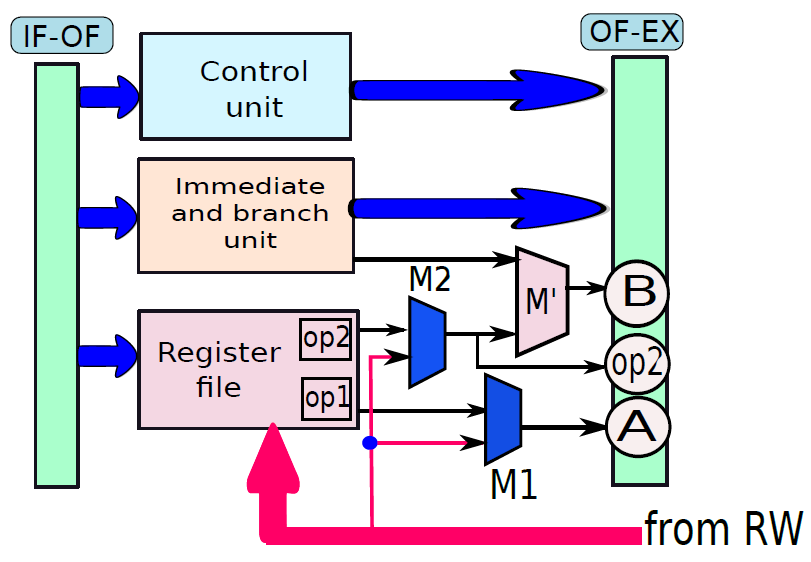
下图显示了修改后的EX阶段。EX级从OF级获得的三个输入是A(第一个ALU操作数)、B(第二个ALU运算数)和op2(第二寄存器操作数)。对于A和B,我们添加了两个复用器M3和M4,以在OF级中计算的值和分别从MA和RW级转发的值之间进行选择。对于可能包含存储值的op2字段,我们不需要MA --> EX转发,因为在MA阶段需要存储值,因此我们可以使用RW --> MA转发,从而减少一条转发路径。因此,多路复用器M5具有两个输入(默认值和从RW级转发的值)。
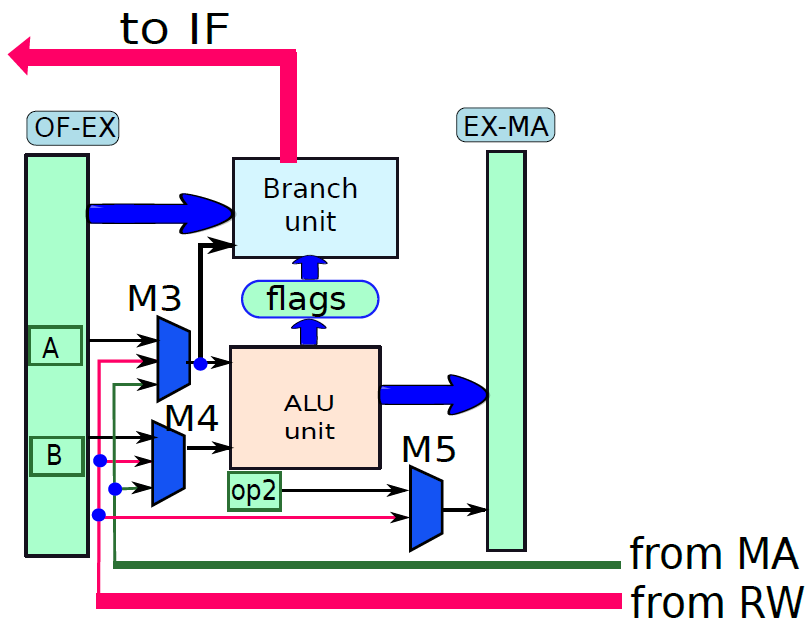
下图显示了具有额外转发支持的MA阶段。内存地址在EX阶段计算,并保存在指令包的aluResult字段中,内存单元直接使用该值作为地址。然而,在存储的情况下,需要存储的值(op2)可以从RW阶段转发,因此添加了多路复用器M6,它在指令包中的op2字段和从RW级转发的值之间进行选择。电路的其余部分保持不变。

下图显示了RW阶段。因为是最后一个阶段,所以它不使用任何转发值。但是,它将写入寄存器le的值分别发送到MA、EX和OF阶段。
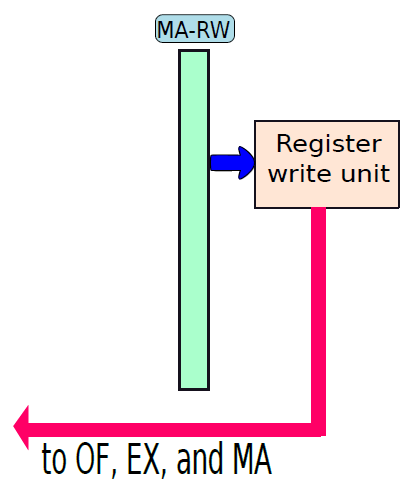
下图将所有部分放在一起,并显示了支持转发的管线。总之,我们需要添加6个多路复用器,并在单元之间进行一些额外的互连,以传递转发的值。我们设想一个专用的转发单元,它为多路复用器(图中未示出)计算控制信号。除了这些小的更改,不需要对数据路径进行其他重大更改。
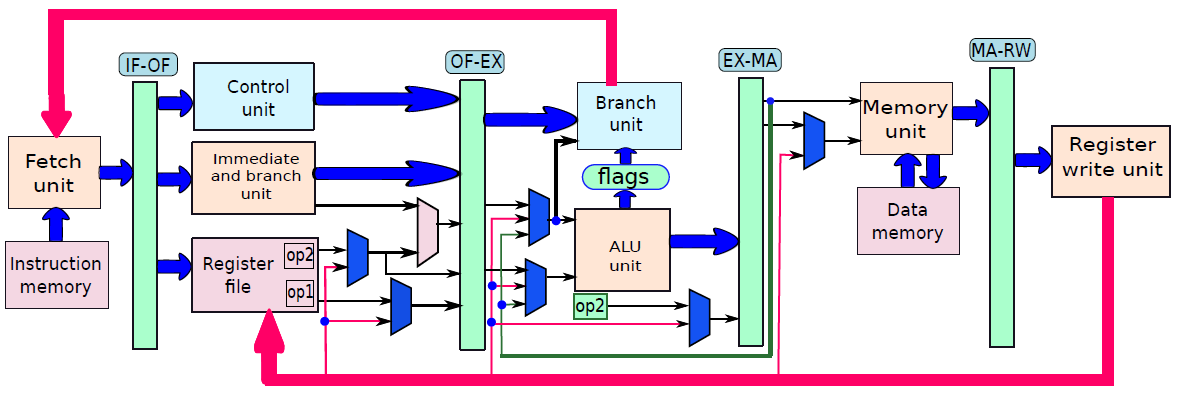
带转发的流水线数据路径(简图)。
我们在讨论转发时使用了一个简图(上图)。需要注意的是,实际电路现在变得相当复杂。除了对数据路径的扩展,还需要添加一个专用转发单元来为多路复用器生成控制信号。详细图片如下图所示。

现在将互锁逻辑添加到管线中,需要数据锁定和分支锁定条件的互锁逻辑。请注意,现在已经成功处理了除加载-使用冲突以外的所有RAW冲突。在加载-使用冲突的情况下,只需要停止一个周期,大大简化了数据锁定电路。如果EX阶段有加载指令,就需要检查加载指令和OF阶段的指令之间是否存在RAW数据依赖关系,不需要考虑的唯一RAW冲突是加载-存储依赖性,即加载写入包含存储值的寄存器,我们不需要暂停,因为可以将要存储的值从RW转发到MA阶段。对于所有其他数据依赖性,需要通过引入气泡将管线暂停1个周期,此举可以解决加载-使用冲突,确保分支锁定条件的电路保持不变。还需要检查EX阶段中的指令,如果它是一个执行的分支,需要使if和OF阶段的指令无效。最后应注意,互锁始终优先于转发。
19.5.3.5 性能标准和测量
本节讨论流水线处理器的性能。
需要首先在处理器的上下文中定义性能的含义。大多数时候,当我们查找笔记本电脑或智能手机的规格时,会被大量的术语淹没,比如时钟频率、RAM和硬盘大小,遗憾的是,这些术语都不能直接表示处理器的性能。计算机标签上从未明确提及性能的原因是“性能”一词相当模糊,处理器的性能一词总是指给定的程序或汇编,因为处理器对不同程序的性能不同。
给定一个程序P,让我们尝试量化给定处理器的性能。如果P在A上执行P的时间比在B上执行P所需的时间短,那么处理器A比处理器B性能更好。因此,量化给定程序的性能非常简单,测量运行程序所需的时间,然后计算其倒数,这个数字可以解释为与处理器相对于程序的性能成正比。
首先计算运行程序P所需的时间:
τ=# seconds =# seconds # cycles ×# cycles # instructions ×(# instructions )=# seconds # cycles 1/f×# cycles # instructions CPI×(# instructions )= CPI ×(# instructions )fτ=# seconds =# seconds # cycles ×# cycles # instructions ×(# instructions )=# seconds # cycles ⏟1/f×# cycles # instructions ⏟CPI×(# instructions )= CPI ×(# instructions )f
-
每秒的周期数是处理器的时钟频率(f)。
-
每个指令的平均周期数称为CPI(Cycles per instruction),其逆数(每个周期的指令数)称为IPC(Instructions per cycle)。
-
最后一项是指令数(缩写为#insts)。注意,是动态指令的数量,或者处理器实际执行的指令数量,不是程序可执行文件中的指令数。
静态指令是程序的二进制或可执行文件包含指令列表里的每条指令。
动态指令是静态指令的实例,当指令进入流水线时由处理器创建。
我们现在可以将性能P定义为与时间ττ成反比的量(称为性能等式):
P∝IPC×f# insts P∝IPC×f# insts
因此可以得出结论,处理器相对于程序的性能与IPC和频率成正比,与指令数成反比。
现在看看单周期处理器的性能。对于所有指令,其CPI都等于1,性能与finstsCountfinstsCount成正比,是一个相当微不足道的结果。当增加频率时,单周期处理器会按比例变快。同样,如果能够将程序中的指令数量减少X倍,那么性能也会增加X倍。让我们考虑流水线处理器的性能,分析更为复杂,见解也非常深刻。
下面阐述性能方程中的三个项:
-
指令数量。程序中指令的数量取决于编译器的智能,真正智能的编译器可以通过从ISA中选择正确的指令集并使用智能代码转换来减少指令。例如,程序员通常有一些归类为死代码的代码,此代码对最终输出没有影响,聪明的编译器可以删除它能找到的所有死代码。附加指令的另一个来源是溢出和恢复寄存器的代码,编译器通常对非常小的函数执行函数内联,这种优化动态地移除这些函数,并将它们的代码粘贴到调用函数的代码中。对于小函数,是一个非常有用的优化,可以摆脱溢出和恢复寄存器的代码。还有许多编译器优化有助于减少代码大小,本节假设指令的数量是常数,只关注硬件方面。
-
计算周期总数。假设一个理想的管线不需要插入任何气泡或停滞,它将能够每个周期完成一条指令,因此CPI为1。假设一个包含n条指令的程序,并让流水线有k个阶段,让我们计算所有n条指令离开流水线所需的周期总数。
第一条指令在周期1中进入流水线,在周期k中离开流水线,每个周期都会有一条指令离开流水线。在(n-1) 周期,所有指令都会离开流水线,循环总数为n+k- 1。CPI等于:
CPI=n+k−1nCPI=n+k−1n
请注意,CPI趋于1,因为n趋于正无穷。
-
与频率的关系。让指令在单周期处理器上完成执行所需的最大时间为tmaxtmax,也称为算法工作总量。我们在计算tmaxtmax时忽略了流水线寄存器的延迟。现在将数据路径划分为k个流水线阶段,需要添加k−1k−1个流水线寄存器。设流水线寄存器的延迟为ll,如果假设所有流水线阶段都是平衡的(做同样的工作,花费同样的时间),那么最慢的指令在一个阶段完成工作所需的时间等于tmaxktmaxk。每阶段的总时间等于电路延迟和流水线寄存器的延迟:
tstage=tmaxk+1tstage=tmaxk+1
现在,最小时钟周期时间必须等于流水线阶段的延迟,因为设计流水线时的假设是每个阶段只需要一个时钟周期。因此,最小时钟周期时间(tclktclk)或最大频率(ff)等于:
tclk=1f=tmaxk+ltclk=1f=tmaxk+l
下面计算管线的性能。简单地假设性能等于(f/CPI),因为指令数是常数(n)。
P=fCPI=1tmaxk+ln+k−1n=n(tmax/k+l)×(n+k−1)=n((n−1)tmax/k+(tmax+ln−l)+lkP=fCPI=1tmaxk+ln+k−1n=n(tmax/k+l)×(n+k−1)=n((n−1)tmax/k+(tmax+ln−l)+lk
尝试通过选择正确的k值来最大化性能,有:
∂((n−1)tmax/k+(tmax+ln−l)+lk)∂k=0⇒−(n−1)tmaxk2+l=0⇒k=√(n−1)tmaxl∂((n−1)tmax/k+(tmax+ln−l)+lk)∂k=0⇒−(n−1)tmaxk2+l=0⇒k=(n−1)tmaxl
需要在CPI方程中纳入停顿的影响,假设指令(n)的数量非常大。让理想的CPI是CPIidealCPIideal,在本例,CPIideal=1CPIideal=1,有:
CPI=CPIideal+stallRate×stallPenaltyCPI=CPIideal+stallRate×stallPenalty
为了最大化性能,需要将分母最小化,得到:
∂((n−1)tmax/k+(rcntmax+tmax+ln−l)+lk(1+rcn))∂k=0⇒−(n−1)tmaxk2+l(1+rcn)=0⇒k=√(n−1)tmaxl(1+rcn)≈√tmaxlrc( as n→∞)∂((n−1)tmax/k+(rcntmax+tmax+ln−l)+lk(1+rcn))∂k=0⇒−(n−1)tmaxk2+l(1+rcn)=0⇒k=(n−1)tmaxl(1+rcn)≈tmaxlrc( as n→∞)
为了确定管线阶段的最佳数量的性能,假设n是正无穷,因此(n+k−1)/n(n+k−1)/n趋近于1,因此有:
Pideal =1(tmax/k+l)×(1+rck)=1tmax/k+l+rctmax+lrck=1tmax×√(lrctmax)+l+rctmax+lrc×√(tmaxlrc)=1rctmax+2√lrctmax+l=1(√rctmax+√l)2Pideal =1(tmax/k+l)×(1+rck)=1tmax/k+l+rctmax+lrck=1tmax×(lrctmax)+l+rctmax+lrc×(tmaxlrc)=1rctmax+2lrctmax+l=1(rctmax+l)2
大多数时候,我们不会衡量处理器对一个程序的性能。考虑一组已知的基准程序,并测量处理器相对于所有程序的性能,以获得统一的图形。大多数处理器供应商通常总结其处理器相对于SPEC(Standard Performance Evaluation Corporation)的性能基准,发布用于测量、总结和报告处理器和软件系统性能的基准套件。
计算机架构通常使用SPEC CPU基准套件来衡量处理器的性能。SPEC CPU 2006基准有两种程序类型:整数算术基准(SPECint)和浮点基准(SPECfp)有12个用C/C++编写的SPECint基准测试。基准测试包含C编译器、基因测序器、AI引擎、离散事件模拟器和XML处理器的部分,在类似的线路上,SPECfp套件包含17个程序,解决了物理、化学和生物学领域的不同问题。
大多数处理器供应商通常计算SPEC分数,代表处理器的性能,建议的过程是采用基准测试在参考处理器上花费的时间与基准测试在给定处理器上花费时间的比率,SPEC分数等于所有比率的几何平均值。在计算机体系结构中,当我们报告平均相对性能(如SPEC分数)时,通常使用几何平均值。对于报告平均执行时间(绝对时间),可以使用算术平均值。
有时报告的不是SPEC分数,而是平均每秒执行的指令数,而对于科学程序,则是平均每秒浮点运算数,这些指标提供了处理器或处理器系统的速度指示。通常使用以下术语:
- KIPS:每秒千(103103)条指令。
- MIPS:每秒百万(106106)条指令。
- MFLOPS:每秒百万(106106)次浮点运算。
- GFLOPS:每秒千兆(109109)次浮点运算。
- TFLOPS:每秒万亿(10121012)次浮点运算。
- PFLOPS:每秒千万亿(10151015)次浮点运算。
现在通过查看性能、编译器设计、处理器架构和制造技术之间的关系来总结讨论。再次考虑性能等式:
P=f×IPC#instsP=f×IPC#insts
如果最终目标是最大化性能,那么需要最大化频率(f)和IPC,同时最小化动态指令(#insts)的数量。有三个变量在我们的控制之下,即处理器架构、制造技术和编译器。请注意,此处使用术语“构架”来指代处理器的实际组织和设计,然而文献通常使用体系结构来指ISA和处理器的设计。下面详细阐述每个变量。
- 编译器
通过使用智能编译器技术,可以减少动态指令的数量,也可以减少暂停的数量,将改善IPC。下面示例通过重新排序add和ld指令来删除一个暂停周期。在类似的行中,编译器通常会分析数百条指令,并对它们进行最佳排序,以尽可能减少暂停。
; -----示例1-----
; 在不违反程序正确性的情况下重新排序以下代码,以减少暂停。
add r1, r2, r3
ld r4, 10[r5]
sub r1, r4, r2
;答案
ld r4, 10[r5]
add r1, r2, r3
sub r1, r4, r2
; 没有加载-使用冲突,程序的逻辑保持不变。
; -----示例2-----
; 在不违反程序正确性的情况下重新排序以下代码,以减少暂停。假设有2个延迟时隙的延迟分支.
add r1, r2, r3
ld r4, 10[r5]
sub r1, r4, r2
add r8, r9, r10
b .foo
; 答案
add r1, r2, r3
ld r4, 10[r5]
b .foo
sub r1, r4, r2
add r8, r9, r10
; 消除了加载-使用风险,并最佳地使用了延迟时隙。
- 架构
我们使用流水线设计了一个高级架构。请注意,流水线本身并不能提高性能,由于暂停,与单周期处理器相比,流水线减少了程序的IPC。流水线的主要好处是它允许我们以更高的频率运行处理器,最小周期时间从单循环流水线的tmaxtmax减少到k级流水线机器的tmax/k+ltmax/k+l。由于每个周期都完成一条新指令的执行,除非出现暂停,所以可以在流水线机器上更快地执行一组指令,指令执行吞吐量要高得多。
流水线的主要好处是以更高的频率运行处理器,可以确保更高的指令吞吐量(更多的指令每秒完成执行)。与单周期处理器相比,流水线本身减少了程序的IPC,也增加了处理任何单个指令所需的时间。
延迟分支和转发等技术有助于提高流水线机器的IPC,我们需要专注于通过各种技术提高复杂管线的性能。需要注意的重要一点是,架构技术影响频率(通过流水线阶段的数量)和IPC(通过转发和延迟分支等优化)。
- 制造工艺
制造工艺影响晶体管的速度,进而影响组合逻辑块和锁存器的速度,晶体管越小,速度越快。因此总算法工作量(tmaxtmax)和锁存延迟(l)也在稳步减少,可以在更高的频率下运行处理器,从而提高性能。制造技术只影响我们运行处理器的频率,对IPC或指令数量没有任何影响。
总之,可以用下图总结这一段的讨论。

性能、编译器、架构和技术之间的关系。
请注意,总体情况并不像本节描述的那么简单,还需要考虑功率和复杂性问题。通常,由于复杂性的增加,实现超过20个阶段的流水线非常困难。其次,大多数现代处理器都有严重的功率和温度限制,这个问题也称为功率墙(power wall,下图)。通常不可能提高频率,因为我们无法承受功耗的增加,根据经验法则,功率随频率的立方而增加,将频率增加10%会使功耗增加30%以上,非常之大。设计者越来越避免以非常高的频率运行的深度流水线设计。

英特尔x86微处理器的时钟频率和功耗超过八代30年。奔腾4在时钟频率和功率上有了戏剧性的飞跃,但在性能上没有那么出色。Prescott的热问题导致了奔腾4系列的报废。Core 2系列恢复为更简单的流水线,具有更低的时钟速率和每个芯片多个处理器。Core i5管道紧随其后。
关于性能,最后要进一步讨论的是功率和温度的问题。
功率和温度问题在这些年变得越来越重要。高性能处理器芯片通常在正常操作期间消耗60-120W的功率。,如果在一台服务器级计算机中有四个芯片,那么将大致消耗400W的功率。一般来说,计算机中的其他组件,如主存储器、硬盘、外围设备和风扇,也会消耗类似的电量,总功耗约为800W。如果增加额外的开销,例如电源、显示硬件的非理想效率,则功率需求将达到约1KW。一个拥有100台服务器的典型服务器场将需要100千瓦的电力来运行计算机。此外还需要冷却装置(如空调),通常为了去除1W的热量,需要0.5W的冷却功率,因此服务器农场的总功耗约为150千瓦。相比之下,一个典型的家庭的额定功率为6-8千瓦,意味着一个服务器农场消耗的电力相当于20-25个家庭使用的电力,非常显而易见。请注意,包含100台机器的服务器场是一个相对较小的设置,实际上,有更大的服务器农场,包含数千台机器,需要兆瓦的电力,足以满足一个小镇的需求。
现在考虑真正的小型设备,比如手机处理器,由于电池寿命有限,功耗也是一个重要问题。所有人都会喜欢电池续航很长的设备,尤其是功能丰富的智能手机。现在考虑更小的设备,例如嵌入身体内部的小型处理器,用于医疗应用,通常在起搏器等设备中使用小型微芯片。在这种情况下,不想强迫患者携带重型电池,或经常给电池充电,从而给患者带来不便。为了延长电池寿命,重要的是尽可能减少耗电。
此外,温度是一个非常密切相关的概念。结合下图中芯片的典型封装图,通常有一个200-400平方毫米的硅管芯(silicon die),管芯是指包含芯片电路的矩形硅块。由于这一小块硅耗散60-100W的功率(相当于6-10个CFL灯泡),除非采取额外措施冷却硅管芯,否则其温度可能会升至200摄氏度。首先在硅管芯上添加一块5cm x 5cm的镀镍铜板,就是所谓的扩散器,扩散器通过传播热量,从而消除热点,有助于在模具上形成均匀的温度分布。需要一个扩散器,因为芯片的所有部分都不会散发相同的热量,例如ALU通常耗散大量热量,而存储元件相对较冷。其次,散热取决于程序的性质,对于整数基准测试,浮点ALU是空闲的,会更冷。为了确保热量正确地从硅管芯流到扩散器,通常添加一种导热凝胶,称为热界面材料(TIM)。
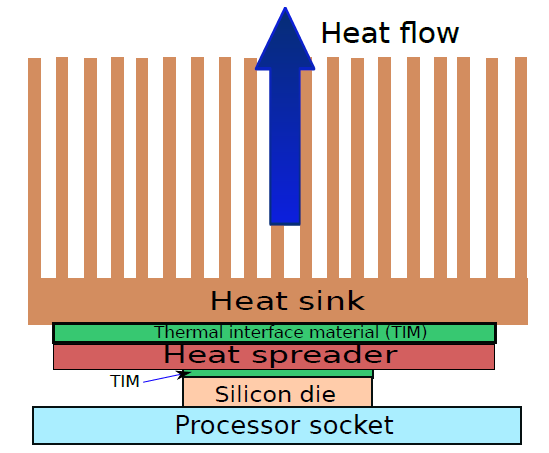
大多数芯片都有一种结构,即散热器顶部的散热器。它是一种铜基结构,具有一系列鳍片,如上图所示。添加了一系列鳍片以增加其表面积,确保处理器产生的大部分热量可以散发到周围的空气中。在台式机、笔记本电脑和服务器中使用的芯片中,有一个风扇安装在散热器上,或者安装在计算机机箱中,将空气吹过散热器,确保热空气被驱散,而来自外部的冷空气流过散热器。散热器、散热器和风扇的组合有助于散热处理器产生的大部分热量。
尽管采用了先进的冷却技术,处理器仍能达到60-100摄氏度。在玩高度互动的电脑游戏时,或者在运行天气模拟等大量数据处理应用程序时,芯片上的温度最高可达120摄氏度,足以烧开水、煮蔬菜,甚至在冬天温暖一个小房间,我们不需要买加热器,只需要运行一台计算机!请注意,温度有很多有害影响:
- 片上铜线和晶体管的可靠性随着温度的升高呈指数下降。由于一种被称为NBTI(负偏置温度不稳定性)的效应,芯片往往会随着时间老化,老化有效地减缓了晶体管的速度。因此,有必要随着时间的推移降低处理器的频率,以确保正确的操作。
- 一些功耗机制(如泄漏功率)取决于温度,意味着随着温度的升高,总功率的泄漏分量也随之升高,进一步提高了温度。
总之,为了降低电费、降低冷却成本、延长电池寿命、提高可靠性和减缓老化,降低芯片上的功率和温度非常重要。现在让我们快速回顾一下主要的功耗机制。主要关注两种机制,即动态和泄漏功率(leakage power),泄漏功率也称为静态功率。
先阐述动态功率。
可以把芯片的封装看作一个封闭的黑盒子,有电能流入,热量流出。在足够长的时间段内,流入芯片的电能的量完全等于根据能量守恒定律作为热量耗散的能量的量。此处忽略了沿I/O链路发送电信号所损失的能量,但与整个芯片的功耗相比,该能量可以忽略不计。
任何由晶体管和铜线组成的电路都可以被建模为具有电阻器、电容器和电感器的等效电路。电容器和电感器不散热,但电阻器将流经电阻器的一部分电能转换为热量,这是电能在等效电路中转化为热能的唯一机制。
现在考虑一个小电路,它有一个电阻器和一个电容器,如下图所示,电阻器代表电路中导线的电阻,电容器表示电路中晶体管的等效电容。需要注意的是,电路的不同部分,例如晶体管的栅极,在给定的时间点具有一定的电势,意味着晶体管的栅极起着电容器的作用,从而存储电荷。类似地,晶体管的漏极和源极具有等效的漏极电容和源极电容。通常不会在简单的分析中考虑等效电感,因为大多数导线通常很短,并且它们不起电感器的作用。
具有电阻和电容的电路。
耗散的功率与频率和电源电压的平方成正比,请注意,该功耗表示由于输入和输出中的转变而引起的电阻损耗,它被称为动态功率。因此有:
Pdyn∝n′∑i=1αiCiV2fPdyn∝∑i=1n′αiCiV2f
动态功率(dynamic power)是由于电路中所有晶体管的输入和输出转变而消耗的累积功率。
下面阐述静态功率(泄露功率)。
请注意,动态功耗不是处理器中唯一的功耗机制,静态或泄漏功率是高性能处理器功耗的主要组成部分,大约占处理器总功率预算的20-40%。
到目前为止,我们一直假设晶体管在截止状态时不允许任何电流流过,电容器的端子之间或NMOS晶体管的栅极和源极之间绝对没有电流流过,所有这些假设都不是严格正确的。在实践中,没有任何结构是完美的绝缘体,即使在关闭状态下,也有少量电流流过其端子。可以在理想情况下不应该通过电流的其他接口上有许多其他泄漏电源,这种电流源统称为泄漏电流,相关的功率耗散称为泄漏功率。
泄漏功率耗散有不同的机制,如亚阈值泄漏和栅极诱导漏极泄漏。研究人员通常使用BSIM3模型中的以下方程计算泄漏功率(主要捕获亚阈值泄漏):
Pleak=A×ν2T×eVGS−Vth−Voffn×νT(1−e−VDSνT)Pleak=A×νT2×eVGS−Vth−Voffn×νT(1−e−VDSνT)
其中:
| 变量 | 定义 |
|---|---|
| AA | 面积相关比例常数 |
| νTνT | 热电压 |
| kk | 波耳兹曼常数 |
| 1.6×10−191.6×10−19 | |
| TT | 温度 |
| VGSVGS | 栅极和源极之间的电压 |
| VthVth | 阈值电压,还取决于温度 |
| VoffVoff | 残余电压 |
| nn | 亚阈值摆动系数 |
| VDSVDS | 漏极和源极之间的电压 |
注意,泄漏功率通过变量νT=kT/qνT=kT/q取决于温度。为了显示温度相关性,可以简化方程以获得以下方程:
Pleak∝T2×eA/T×(1−eB/T)Pleak∝T2×eA/T×(1−eB/T)
上述公式中,A和B是常数。大约20年前,当晶体管阈值电压较高时(约500 mV),泄漏功率与温度呈指数关系,因此温度的小幅度升高将转化为泄漏功率的大幅度增加。然而,如今的阈值电压在100-150 mV之间,因此温度和泄漏之间的关系变得近似线性。
需要注意的是,泄漏功率始终由电路中的所有晶体管耗散,泄漏电流的量可能很小,但是当考虑数十亿晶体管的累积效应时,泄漏功率耗散的总量是相当大的,甚至可能成为动态功率的很大一部分。由此,设计人员试图控制温度以控制泄漏功率。总功率由下式给出:
Ptot =Pdyn +Pleak Ptot =Pdyn +Pleak
下面来建模温度。
对芯片上的温度建模是一个相当复杂的问题,需要大量的热力学和传热背景知识,这里陈述一个基本结果。让我们把硅管芯的面积分成一个网格,将网格点编号为1 ... m,功率向量Ptot表示每个网格点耗散的总功率,类似地,让每个网格点的温度由向量T表示。对于大量网格点,功率和温度通常由以下线性方程关联:
T−Tamb=ΔT=A×PtotT−Tamb=ΔT=A×Ptot
- TambTamb被称为环境温度,是周围空气的温度。
- A是m * m矩阵,也称为热阻矩阵。根据公式,温度(T)的变化和功耗彼此线性相关。
请注意,在Ptot =Pdyn +Pleak Ptot =Pdyn +Pleak ,Pleak Pleak 是温度的函数,和上述公式形成反馈回路。因此,我们需要假设温度的初始值,计算泄漏功率,估计新的温度,计算泄漏功耗,并不断迭代直到值收敛。
19.5.4 高级技术
本节将简要介绍实现处理器的高级技术。请注意,本节绝不是独立的,其主要目的是为读者提供额外学习的指导。本节将介绍几个大幅度提高性能的广泛范例,这些技术被最先进的处理器采用。
现代处理器通常使用非常深的流水线(12-20阶段)在同一周期内执行多条指令,并采用先进技术消除流水线中的冲突。让我们看看一些常见的方法。
19.5.4.1 分支预测
让我们从IF阶段开始,看看如何做得更好。如果在管线中有一个执行的分支,那么IF阶段尤其需要在管线中暂停2个周期,然后需要开始从分支目标中提取。随着我们添加更多的线线阶段,分支惩罚(branch penalty)从2个周期增加到20多个周期,使得分支指令非常昂贵,会严重限制性能。因此,有必要避免管线暂停,即使对于已采取的分支也是如此。
如果可以预测分支的方向,也可以预测分支目标,那会怎么样?在这种情况下,提取单元可以立即从预测的分支目标开始提取。如果在稍后的时间点发现预测错误,则需要取消预测错误的分支指令之后的所有指令,并将其从管线中丢弃,这种指令也称为推测指令(speculative instruction)。
现代处理器通常根据预测执行大量指令集,例如预测分支的方向,并相应地从预测的分支目标开始提取指令,稍后执行分支指令时验证预测。如果发现预测错误,则从管线中丢弃所有错误获取或执行的指令,这些指令称为推测指令(speculative instruction)。相反,正确获取并执行的指令,或其预测已验证的指令称为非推测指令。
请注意,禁止推测性指令更改寄存器文件或写入内存系统是极其重要的,因此需要等待指令变得非推测性,然后才允许它们进行永久性的更改。第二,不允许它们在非推测之前离开管线,但如果需要丢弃推测指令,那么现代管线采用更简单的机制,通常会删除在预测失败的分支指令之后获取的所有指令,而不是选择性地将推测指令转换为管线气泡。这个简单的机制在实践中非常有效,被称为管线刷新(pipeline flush)。
现代处理器通常采用一种简单的方法,即丢弃管线中的所有推测指令。它们完全完成所有指令的执行,直到出现预测失误的指令,然后清理整个管线,有效地删除在预测失误指令之后获取的所有指令。这种机制称为管线刷新(pipeline flush)。
现在概述分支预测中的主要挑战:
- 如果一条指令是一个分支,需要在提取阶段首先读取,如果是分支,需要读取分支目标的地址。
- 接下来,需要预测分支的预期方向。
- 有必要监测预测指令的结果。如果存在预测失误,那么需要在稍后的时间点执行管线刷新,以便能够有效地删除所有推测指令。
在分支的情况下检测预测失误是相当直接的,将预测添加到指令包中,并用实际结果验证预测。如果它们不同,那么安排管线刷新。主要的挑战是预测分支指令的目标及其结果。
现代处理器使用称为分支目标缓冲器(BTB)的简单硬件结构,它是一个简单的内存阵列,保存最后N(从128到8192不等)条分支指令的程序计数器及其目标。找到匹配的可能性很高,因为程序通常表现出一定程度的局部性,意味着它们倾向于在一段时间内重复执行同一段代码,例如循环,因此BTB中的条目往往会在很短的时间内被重复使用。如果存在匹配,那么也可以自动推断该指令是分支。
要有效地预测分支的方向要困难得多,但可以利用后面阐述的模式。程序中的大多数分支通常位于循环或if语句中,其中两个方向的可能性不大,事实上,一个方向的可能性远大于另一个方向,例如循环中的分支占用了大部分时间。有时if语句仅在某个异常条件为真时才求值,大多数情况下,与这些if语句关联的分支都不会被执行。类似地,对于大多数程序,设计者观察到几乎所有的分支指令都遵循特定的模式,它们要么对一个方向有强烈的偏倚,要么可以根据过去的历史进行预测,要么可以基于其它分支的行为进行预测。当然,这种说法没有理论依据,只是处理器设计者的观察结果,因此他们设计了预测器来利用程序中的这种模式。
本节讨论一个简单的2位分支预测器。假设有一个分支预测表,该表为表中的每个分支分配一个2位值,如下图所示。

如果该值为00或01,则预测该分支不会被执行。如果它等于10或11,那么预测分支被执行。此外,每次执行分支时,将相关计数器递增1,每次不执行分支时将计数器递减1。为了避免溢出,不将11递增1以产生00,也不将00递减以产生11。我们遵循饱和算术的规则,即(二进制):11+1=1111+1=11和00−1=0000−1=00。这个2位值被称为2位饱和计数器,其状态图如下图所示。
预测分支有两种基本操作:预测和训练。为了预测分支,我们在分支预测表中查找其程序计数器的值,在特定情况下,使用pc地址的最后n位来访问2n个条目的分支预测表。读取2位饱和计数器的值,并根据其值预测分支,当得到分支的实际结果时,我们训练通过使用饱和算法递增或递减计数器的值。
现在看看这个预测器的工作原理,考虑一段简单的C代码及其等效的汇编代码:
void main()
{
foo();
...
foo();
}
int foo()
{
int i, sum = 0
for(i=0; i < 10; i++)
{
sum = sum + i;
}
return sum;
}
.main:
call .foo
...
call .foo
.foo:
mov r0, 0 /* sum = 0 */
mov r1, 0 /* i = 0 */
.loop:
add r0, r0, r1 /* sum = sum + i */
add r1, r1, 1 /* i = i + 1 */
cmp r1, 10 /* compare i with 10 */
bgt .loop /* if(r1 > 10) jump to .loop */
ret
让我们看看循环中的分支语句bgt .loop,对于除最后一次之外的所有迭代,都会执行分支。如果在状态10下启动预测器,那么第一次,分支预测正确(采取),计数器递增并等于11,对于后续的每一次迭代,都会正确地预测分支。然而,在最后一次迭代中,需要将其预测为未采取,这里有一个错误的预测,因此,2位计数器递减,并设置为10。现在考虑一下再次调用函数foo时的情况,2位计数器的值为10,并且分支bgt .loop被正确预测为采用。
因此,2位计数器方案在预测方案中增加了一点延迟(或过去的历史)。如果分支历史上一直在一个方向,那么一个异常不会改变预测。这个模式对于循环非常有用,正如在这个简单的例子中看到的那样,循环最后一次迭代中分支指令的方向总是不同的,但下一次进入循环时,分支的预测是正确的,正如本例所示。请注意,这只是其中一种模式,现代分支预测程序可以利用更多类型的模式。
程序优化提示:
- 为编译器提供尽可能多的有关正在执行的操作的信息。
- 尽可能使用常量和局部变量。如果语言允许,请定义原型并声明静态函数。
- 尽可能使用数组而不是指针。
- 避免不必要的类型转换,并尽量减少浮点到整数的转换。
- 避免溢出和下溢。
- 使用适当的数据类型(如float、double、int)。
- 考虑用乘法代替除法。
- 消除所有不必要的分支。
- 尽可能使用迭代而不是递归。
- 首先使用最可能的情况构建条件语句(例如if、switch、case)。
- 在结构中按尺寸顺序声明变量,首先声明尺寸最大的变量。
- 当程序出现性能问题时,请在开始优化程序之前对程序进行概要分析。(评测是将代码分成小块,并对每一小块进行计时,以确定哪一块花费的时间最多的过程。)
- 切勿仅基于原始性能放弃算法。只有当所有算法都完全优化时,才能进行公平的比较。
- 过程内联(procedure inlining),用函数体替换对函数的调用,用调用者的参数替换过程的参数。
- 循环转换(loop transformation),可以减少循环开销,改善内存访问,并更有效地利用硬件。
- 循环展开(loop-unrolling)。在执行多次迭代的循环中,例如那些传统上由For语句控制的循环,循环展开loop-unrolling的优化通常有用。循环展开包括进行循环,多次复制身体,并减少执行转换后的循环的次数。循环展开减少了循环开销,并为许多其他优化提供了机会。
- 复杂的循环转换,如交换嵌套循环和阻塞循环以获得更好的内存行为。
- 局部和全局优化。在专用于局部和全局优化的过程中,执行以下优化:
- 局部优化在单个基本块内工作。局部优化过程通常作为全局优化的先导和后续运行,以在全局优化前后“清理”代码。
- 全局优化跨多个基本块工作。
- 全局寄存器分配为代码区域的寄存器分配变量。寄存器分配对于在现代处理器中获得良好性能至关重要。
- 更具体地,有子表达式消除(Common subexpression elimination)、削减强度(Strength reduction)、常量传播(Constant propagation)、拷贝传播(Copy propagation)、死存储消除(Dead store elimination)等操作。
如果使用两个位,则可以使用它们来记录相关指令执行的最后两个实例的结果,或者以其他方式记录状态。下图显示了一种典型的方法,假设算法从流程图的左上角开始。只要执行遇到的每个后续条件分支指令,决策过程就预测将执行下一个分支,如果单个预测错误,则算法继续预测下一个分支被执行。只有在没有采取两个连续分支的情况下,算法才会转移到流程图的右侧,随后该算法将预测在一行中的两个分支被取下之前不会取下分支,因此该算法需要两个连续的错误预测来改变预测决策。
分支预测流程图。
预测过程可以用有限状态机更紧凑地表示,如下图所示,许多文献通常使用有限状态机表示。

分支预测状态图。
下图将该方案与从未采取的预测策略进行了对比。使用前一种策略,指令获取阶段总是获取下一个顺序地址。如果执行了分支,处理器中的某些逻辑会检测到这一点,并指示从目标地址提取下一条指令(除了刷新管道之外)。分支历史表被视为缓存,每个预取都会触发分支历史表中的查找。如果未找到匹配项,则使用下一个顺序地址进行提取,如果找到匹配,则根据指令的状态进行预测:下一个顺序地址或分支目标地址被馈送到选择逻辑。
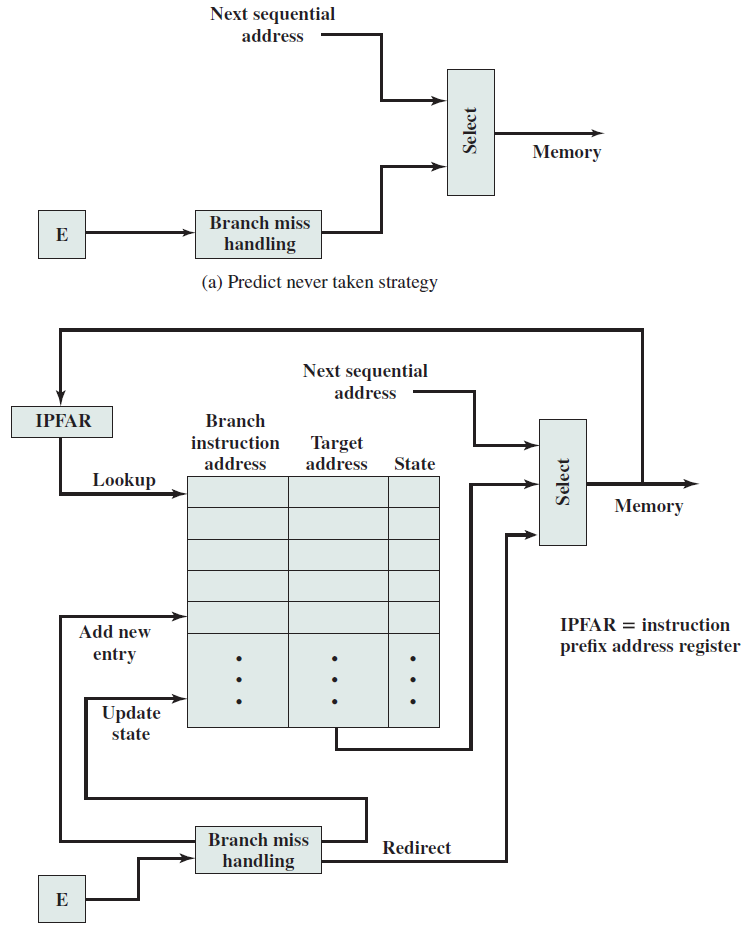
为了弥补依赖性,已经开发了代码重组技术,首先考虑分支指令。延迟分支(Delayed branch)是一种提高流水线效率的方法,它使用的分支在执行以下指令后才生效(因此称为延迟),紧接在分支之后的指令位置被称为延迟槽(delay slot)。这个奇怪的过程如下表所示。在标记为“正常分支”的列中,有一个正常的符号指令机器语言程序。执行102之后,下一条要执行的指令是105。为了规范流水线,在这个分支之后插入一个NOOP。但是,如果在101和102处的指令互换,则可以实现提高的性能。
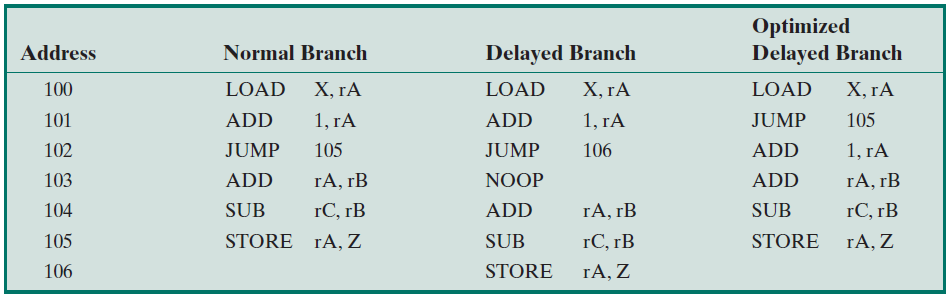
下图显示了结果。图a显示了传统管线方法。JUMP指令在时间4被获取,在时间5,JUMP指令与指令103(ADD指令)被获取的同时被执行。因为发生了JUMP,它更新了程序计数器,所以必须清除流水线中的指令103,在时间6,作为JUMP的目标的指令105被加载。
图b显示了典型RISC组织处理的相同管线,时间是一样的,但由于插入了NOOP指令,不需要特殊的电路来清除管线,NOOP简单地执行而没有效果。
图c显示了延迟分支的使用。JUMP指令在ADD指令之前的时间2获取,ADD指令在时间3获取。但请注意,ADD指令是在执行JUMP指令有机会改变程序计数器之前获取的。因此,在时间4期间,在获取指令105的同时执行ADD指令,保留了程序的原始语义,但执行需要两个更少的时钟周期。

19.5.4.2 延迟加载
类似延迟分支的策略称为延迟加载(delayed load),可以用于加载指令。在LOAD指令中,将成为加载目标的寄存器被处理器锁定。然后,处理器继续执行指令流,直到它到达需要该寄存器的指令为止,此时它将空闲,直到加载完成。如果编译器可以重新排列指令,以便在加载过程中完成有用的工作,那么效率就会提高。
19.5.4.3 循环展开
另一种提高指令并行性的编译器技术是循环展开(loop unrolling)。展开会多次复制循环体,称为展开因子(u),并按步骤u而不是步骤1进行迭代:
- 减少环路开销
- 通过提高流水线性能提高指令并行性
- 改进寄存器、数据缓存或TLB位置
下图在一个示例中说明了所有三种改进。循环开销减少了一半,因为在测试之前执行了两次迭代,并在循环结束时分支。由于可以在存储第一次赋值的结果和更新循环变量的同时执行第二次赋值,因此提高了指令并行性。如果将数组元素分配给寄存器,寄存器局部性将得到改善,因为在循环体中使用了两次a[i]和a[i+1],从而将每次迭代的加载次数从三次减少到两次。

指令流水线的设计不应与应用于系统的其他优化技术分离,例如流水线的指令调度和寄存器的动态分配应该一起考虑,以实现最大的效率。
19.5.4.4 顺序管线的问题
在简单管线中,每个周期只执行一条指令,但并非绝对必要。我们可以设计一个处理器,比如最初的英特尔奔腾,它有两条并行管线。该处理器可以在一个周期内同时执行两条指令。这些管道具有额外的功能单元,因此两条管线中的指令都可以在没有任何重大结构冲突的情况下执行。该策略增加了IPC,但也使处理器更加复杂。这样的处理器被称为包含多个顺序执行管线,因为可以在同一个周期内向执行单元发布多条指令。每个周期可以执行多条指令的处理器也称为超标量处理器(superscalar processor)。
其次,这种处理器被称为有序处理器(in-order processor),因为它按程序顺序执行指令,程序顺序是指令的动态实例在程序中出现时的执行顺序。例如,单周期处理器或流水线处理器按程序顺序执行指令。
每个周期可以执行多条指令的处理器称为超标量处理器(superscalar processor)。
有序处理器按程序顺序执行指令。程序顺序被定义为指令的动态实例的顺序,与顺序执行程序的每条指令时所感知的顺序相同。
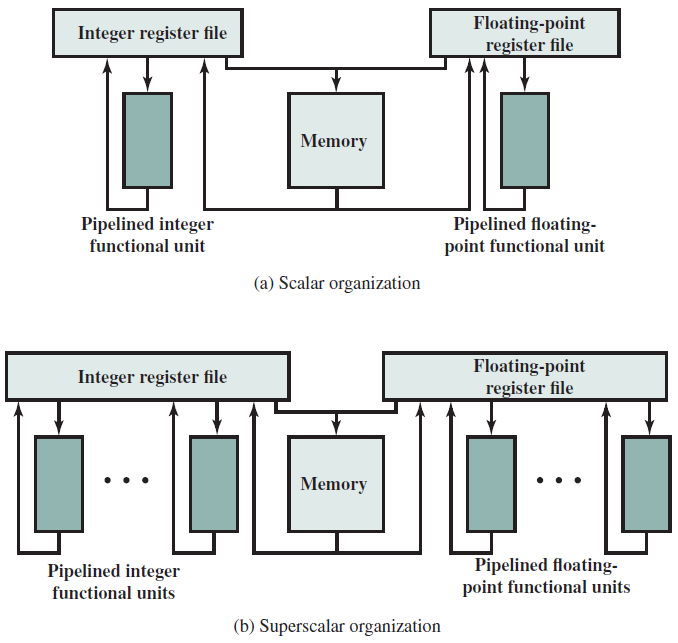
超标量组织与普通标量组织的比较。

超标量和超流水线方法的比较。
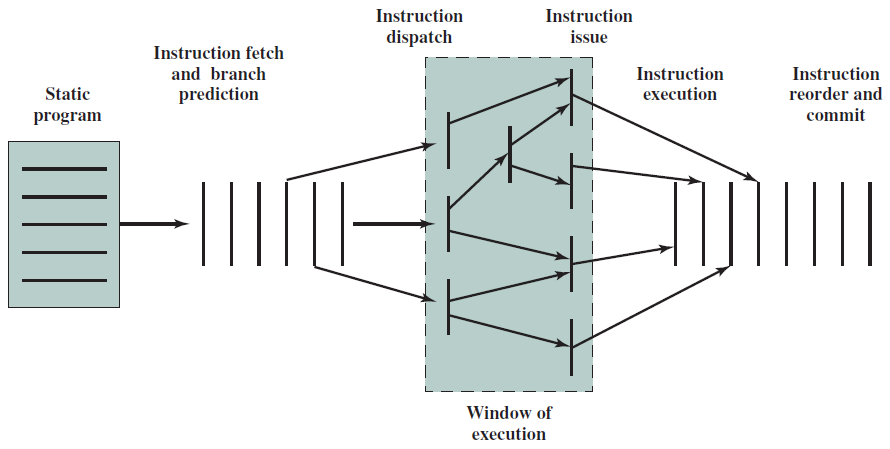
超标量处理的概念描述。
现在,我们需要寻找两条管线的依赖性和潜在冲突。其次,转发逻辑也要复杂得多,因为结果可以从任一管线转发。英特尔发布的原始奔腾处理器有两条管线,即U管线和V管线。U管线可以执行任何指令,而V管线仅限于简单指令。指令作为2-指令束(2-instruction bundle)获取,指令束中的前一条指令被发送到U管线,后一条指令则被发送到V管线。这种策略允许并行地执行这些指令。
让我们尝试在概念上设计一个简单的处理器,它采用了原始奔腾处理器的两条流水线:U和V。我们设想了一个组合的指令和操作数获取单元,它形成2-指令束,并被发送到两个流水线以同时执行。但如果指令不满足某些约束,则该单元形成1-指令束并将其发送到U流水线。无论何时,我们生成这样的束,都可以广泛遵守一些通用规则,应该避免具有RAW依赖性的两条指令,在这种情况下,管线将暂停。
其次,需要特别注意内存指令,因为它们之间的依赖关系在EX阶段结束之前无法发现。假设指令束中的第一条指令是存储指令,第二条指令是加载指令,并且它们碰巧访问相同的内存地址。需要在EX阶段结束时检测这种情况,并将值从存储转发到加载。对于相反的情况,当第一条指令是加载指令,第二条指令是存储到相同地址时,需要暂停存储指令,直到加载完成。如果指令束中的两条指令都存储到同一地址,那么前面的指令是冗余的,可以转换为nop。因此,需要设计一个符合这些规则的处理器,并具有复杂的互锁和转发逻辑。
下面展示一个简单的例子。为以下汇编代码绘制一个流水线图,假设流水线中存在2个问题。
[1]: add r1, r2, r3
[2]: add r4, r5, r6
[3]: add r9, r8, r8
[4]: add r10, r9, r8
[5]: add r3, r1, r2
[6]: ld r6, 10[r1]
[7]: st r6, 10[r1]
此处,流水线图包含每个阶段的两个条目,因为两个指令可以同时在一个阶段中。我们首先观察到可以并行执行指令[1]和[2],但不能并行执行指令[3]和[4],因为指令[3]写入r9,而指令[4]将r9作为源操作数。我们不能在同一个周期内执行这两条指令,因为r9的值是在EX阶段产生的,也是EX阶段需要的。我们继续并行执行[4]和[5],在指令[4]的情况下,可以使用转发来获得r9的值。最后,我们不能并行执行指令[6]和[7],它们访问相同的内存地址,加载需要在存储开始之前完成,因此插入了另一个气泡。管线图如下:
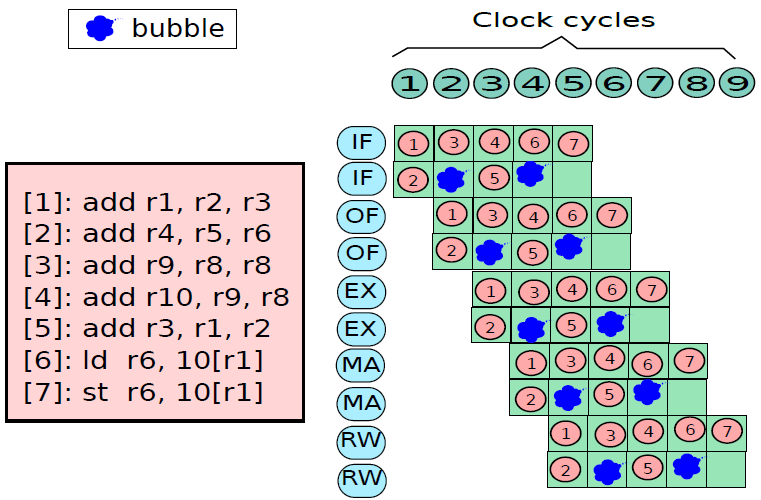
19.5.4.5 EPIC和VLIW处理器
现在,我们可以用软件(而不是用硬件)准备指令束。编译器对代码的可见性要高得多,并且可以执行广泛的分析以创建多指令束。英特尔和惠普设计的安腾处理器是一款基于类似原理的非常经典的处理器。让我们首先从定义术语开始:EPIC和VLIW。
VLIW(Very Long Instruction Word,超长指令字):编译器创建的指令束之间没有依赖关系,硬件并行执行每个包中的指令,正确性的全部责任在于编译器。
EPIC(Explicitly Parallel Instruction Computing,显式并行指令计算):这种范例扩展了VLIW计算,但在这种情况下,无论编译器生成什么代码,硬件都会确保执行正确。
EPIC/VLIW处理器需要非常聪明的编译器来分析程序并创建指令包,例如如果一个处理器有4条流水线,那么每个束包含4条指令。编译器创建束,以便束中的指令之间不存在依赖关系。设计EPIC/VLIW处理器的更广泛的目标是将所有的复杂性转移到软件上,编译器以这样一种方式排列束,可以最大限度地减少处理器中所需的互锁、转发和指令处理逻辑。
但事后看来,这类处理器未能兑现承诺,因为硬件无法像设计者最初计划的那样简单。高性能处理器仍然需要相当复杂的硬件,并且需要一些复杂的架构特性。这些特性增加了硬件的复杂性和功耗。
19.5.4.6 乱序管线
到目前为止,我们一直在主要考虑有序管线,这些管线按照指令在程序中出现的顺序执行指令,但并不是绝对必要的。考虑下面的代码片段:
[1]: add r1, r2, r3
[2]: add r4, r1, r1
[3]: add r5, r4, r2
[4]: mul r6, r5, r2
[5]: div r8, r9, r10
[6]: sub r11, r12, r13
上面代码中,由于数据依赖性,我们被限制按顺序执行指令1到4。然而,可以并行执行指令5和6,因为它们不依赖于指令1-4。如果无序执行指令5、6,不会牺牲正确性,例如如果可以在一个周期内发出两条指令,那么可以一起提交(1,5),然后提交(2,6),最后提交指令3和4。在这种情况下,可以通过在前两个周期内执行2条指令,在4个周期中执行6条指令的序列。这种可能在每个周期执行多条指令的处理器正是超标量处理器。
可以按照与其程序顺序不一致的顺序执行指令的处理器称为乱序(Out-Of-Order,OOO,亦称无序)处理器。

超标量指令执行和完成策略。
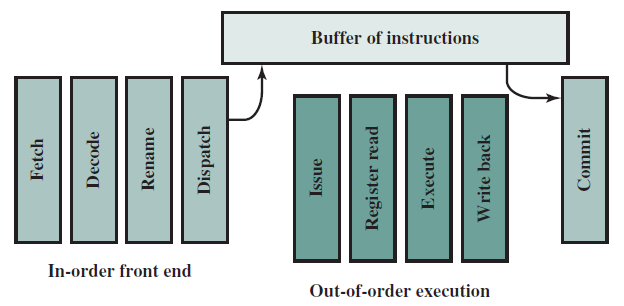
具备乱序完备的乱序执行组织。
乱序(OOO)处理器按顺序获取指令,在提取阶段之后,它继续解码指令。大多数真实世界的指令需要一个以上的解码周期,这些指令同时按程序顺序添加到称为重新排序缓冲区(reorder buffer,ROB)的队列中。解码指令后,需要执行一个称为寄存器重命名(register renaming)的步骤。大致思路是:由于执行的指令是无序的,可能会有WAR和WAW冲突。考虑下面的代码片段:
[1]: add r1, r2, r3
[2]: sub r4, r1, r2
[3]: add r1, r5, r6
[4]: add r9, r1, r7
如果在指令[1]之前执行指令[3]和[4],那么就有潜在的WAW冲突,因为指令[1]可能会覆盖指令[3]写入的r1的值,将导致错误的执行。因此,我们尝试重命名寄存器,以便消除这些冲突。大多数现代处理器都设计了一组架构寄存器(architectural register),这些寄存器与暴露于软件(汇编程序)的寄存器相同。此外,它们还有一组仅在内部可见的物理寄存器(physical register),重命名阶段将架构寄存器名转换为物理寄存器名,以消除WAR和WAW冲突。上面代码中仅存的冲突是RAW冲突,表明存在真正的数据依赖性。因此,重命名后的代码段将如下所示,假设物理寄存器的范围为p1 … p128。
[1]: add p1, p2, p3 /* p1 contains r1 */
[2]: sub p4, p1, p2
[3]: add p100, p5, p6 /* r1 is now begin saved in p100 */
[4]: add p9, p100, p7
我们通过将指令3中的r1映射到p100,消除了WAW冲突,唯一存在的依赖关系是指令之间的RAW依赖关系[1] --> [2] 和[3] --> [4],重命名后的指令进入指令窗口。请注意,到目前为止,指令一直在按顺序处理。
指令窗口或指令队列通常包含64-128个条目(参见下图),每条指令都监视其源操作数,只要一条指令的所有源操作数都准备好了,该指令就可以提交到其相应的功能单元。指令不必总是访问物理寄存器文件,还可以从转发路径中获取值。指令完成执行后,将结果的值广播给指令窗口中的等待指令。等待结果的指令,将其相应的源操作数标记为就绪,此过程称为指令唤醒(instruction wakeup)。现在,有可能在同一周期内准备好多条指令,为了避免结构冲突,指令选择单元选择一组指令执行。
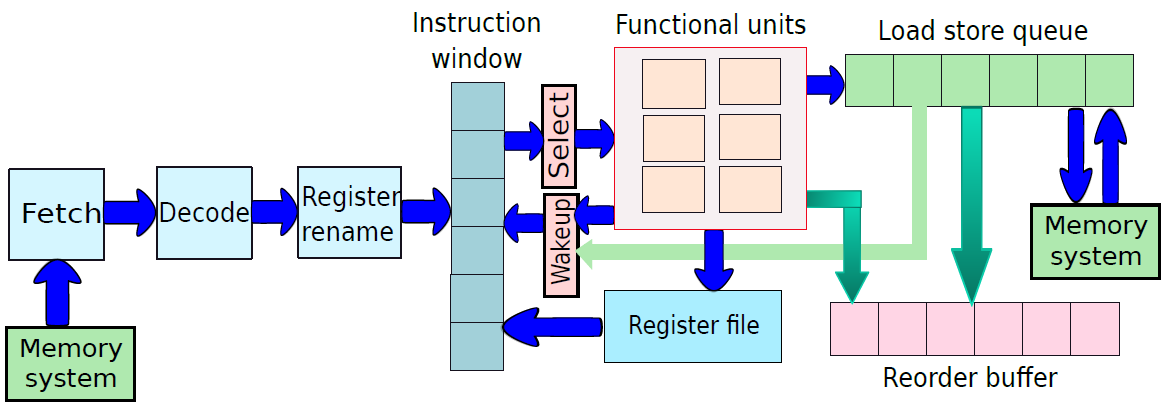
我们需要另一种用于加载和存储指令的结构,称为加载-存储(load-store)队列,它按程序顺序保存加载和存储列表,允许加载通过内部转发机制获取其值,如果同一地址有较早的存储。
指令完成执行后,我们在重新排序缓冲区中标记其条目,指令按程序顺序离开重新排序缓冲区。如果一条指令由于某种原因不能快速完成,那么重新排序缓冲区中的所有指令都需要暂停。回想一下,重新排序缓冲区中的指令条目是按程序顺序排序的,指令需要按程序顺序保留重新排序缓冲区,以便我们能够确保精确的异常。
综上所述,无序处理器(OOO)的主要优点是它可以并行执行指令,这些指令之间没有任何RAW依赖关系。大多数程序通常在大多数时间点都有这样的指令集。此属性称为指令级并行(instruction level parallelism,ILP),现代OOO处理器旨在尽可能地利用ILP。
19.5.4.7 微操作
在执行程序时,计算机的操作由一系列指令周期组成,每个周期有一条机器指令。由于分支指令的存在,这个指令周期序列不一定与组成程序的指令序列相同,这里所指的是指令的执行时间序列。
每个指令周期都由一些较小的单元组成,其中一种方便的细分是获取、间接、执行和中断,只有获取和执行周期总是发生。然而,要设计控制单元,需要进一步细分描述,而进一步的细分是可能的。事实上,我们将看到每个较小的周期都涉及一系列步骤,每个步骤都涉及处理器寄存器。这些步骤称为微操作(micro-operation)。
前缀micro指的是每个步骤都非常简单,完成的很少,下图描述了各种概念之间的关系。总之,程序的执行包括指令的顺序执行,每个指令在由较短子周期(如获取、间接、执行、中断)组成的指令周期内执行。每个子周期的执行涉及一个或多个较短的操作,即微操作。

程序执行的组成要素。
微操作是处理器的功能操作或原子操作。本节将研究微操作,以了解如何将任何指令周期的事件描述为此类微操作的序列。将使用一个简单的示例,并展示微操作的概念如何作为控制单元设计的指南。
先阐述获取周期(Fetch Cycle)。
获取周期发生在每个指令周期的开始,并导致从内存中获取指令,涉及四个寄存器:
- 内存地址寄存器(MAR):连接到系统总线的地址线。它为读或写操作指定内存中的地址。
- 内存缓冲寄存器(MBR):连接到系统总线的数据线。它包含要存储在内存中的值或从内存中读取的最后一个值。
- 程序计数器(PC):保存要获取的下一条指令的地址。
- 指令寄存器(IR):保存获取的最后一条指令。
让我们从获取周期对处理器寄存器的影响的角度来看获取周期的事件序列。下图中显示了一个示例,在提取周期开始时,要执行的下一条指令的地址在程序计数器(PC)中,其中地址是1100100。
- 第一步是将该地址移动到内存地址寄存器(MAR),因为这是连接到系统总线地址线的唯一寄存器。
- 第二步是引入指令,所需地址(在MAR中)被放置在地址总线上,控制单元在控制总线上发出READ命令,结果出现在数据总线上,并被复制到内存缓冲寄存器(MBR)中。我们还需要将PC增加指令长度,以便为下一条指令做好准备。这两个动作(从内存中读取字,递增PC)互不干扰,所以可以同时执行它们以节省时间。
- 第三步是将MBR的内容移动到指令寄存器(IR),将释放MBR,以便在可能的间接循环期间使用。

事件顺序,获取周期。
因此,简单的提取周期实际上由三个步骤和四个微操作组成。每个微操作都涉及将数据移入或移出寄存器。只要这些动作不相互干扰,一步中就可以进行几个动作,从而节省时间。象征性地,我们可以将这一系列事件写成如下:

其中I是指令长度。需要对这个序列做几点评论,假设时钟可用于定时目的,并且它发出规则间隔的时钟脉冲。每个时钟脉冲定义一个时间单位,因此所有时间单位都具有相同的持续时间。每个微操作可以在单个时间单位的时间内执行,符号(t1、t2、t3)表示连续的时间单位。换句话说,我们有:
- 第一时间单位:将PC的内容移动到MAR。
- 第二时间单位:将MAR指定的内存位置的内容移动到MBR。按I递增PC的内容。
- 第三时间单位:将MBR的内容移动到IR。
注意,第二和第三微操作都发生在第二时间单位期间,第三个微操作可以与第四个微操作分组,而不影响提取操作:

微操作的分组必须遵循两个简单的规则:
- 必须遵循正确的事件顺序。因此,(MAR <--(PC))必须在(MBR <-- Memory)之前,因为内存读取操作使用MAR中的地址。
- 必须避免冲突。不应试图在一个时间单位内对同一寄存器进行读写,因为结果是不可预测的,例如微操作(MBR dMemory)和(IR dMBR)不应在同一时间单位内发生。
最后一点值得注意的是,其中一个微操作涉及相加。为了避免电路重复,可以由ALU执行此相加。ALU的使用可能涉及额外的微操作,取决于ALU的功能和处理器的组织。
此外,在非直接周期(Indirect Cycle)、中断周期(Interrupt Cycle)、执行周期(Execute Cycle)、指令周期(Instruction Cycle)等也涉及了类似的机制和原理。
指令周期流程图。
19.5.5 商业处理器案例
现在来看看一些真正的处理器的设计,这样就可以将迄今为止所学的所有概念放在实际的角度。后面将研究ARM、AMD和Intel三大处理器公司的嵌入式(用于小型移动设备)和服务器处理器。本节的目的不是比较和对比三家公司的处理器设计,甚至是同一家公司的不同型号。每一个处理器都是针对特定的细分市场进行优化设计的,并考虑到某些关键业务决策。因此,本节的重点是从技术角度研究设计,并了解设计的细微差别。
在对RISC机器的最初热情之后,人们越来越认识到:
- RISC设计可能会从包含一些CISC功能中受益。
- CISC设计可能从包含一些RISC功能中获益。结果是,较新的RISC设计,特别是PowerPC,不再是“纯”RISC,而较新的CISC设计,尤其是奔腾II和更高版本的奔腾型号,确实包含了一些RISC特性。
下表列出了一些处理器,并对它们进行了多个特性的比较。为了进行比较,以下是典型的RISC:
- 单个指令大小。
- 该大小通常为4字节。
- 少量数据寻址模式,通常少于五种,很难确定。在表中,寄存器和文字模式不计算在内,具有不同偏移量大小的不同格式分别计算在内。
- 无需进行一次内存访问以获取内存中另一个操作数的地址的间接寻址。
- 没有将加载/存储与算术相结合的操作(如从内存添加、添加到内存)。
- 每条指令不超过一个内存寻址操作数。
- 不支持加载/存储操作的数据任意对齐。
- 内存管理单元(MMU)对指令中的数据地址的最大使用次数。
- 整数寄存器说明符的位数等于或大于5,意味着一次至少可以显式引用32个整数寄存器。
- 浮点寄存器说明符的位数等于或大于4,意味着一次至少可以显式引用16个浮点寄存器。

19.5.5.1 ARM处理器
ARM最初是Acorn计算机的处理器,因此其原名为Acorn RISC Machine,伯克利RISC论文影响了其架构。最重要的早期应用之一是16位微处理器AM 6502的仿真,该仿真旨在为Acorn计算机提供大部分软件。由于6502有一个可变长度的指令集,是字节的倍数,因此6502仿真有助于解释ARMv7指令集中对移位和屏蔽的强调。它作为一款低功耗嵌入式计算机的流行始于它被选为命运多舛的Apple Newton个人数字助理的处理器。
虽然Newton并没有苹果希望的那么受欢迎,但苹果的祝福让早期的ARM指令集变得引人注目,随后它们在包括手机在内的几个市场上流行起来。与Newton的经历不同,手机的非凡成功解释了2014年出货120亿ARM处理器的原因。ARM历史上的一个重大事件是称为版本8的64位地址扩展,ARM借此机会重新设计了指令集,使其看起来更像MIPS,而不像早期的ARM版本。
ARM处理器(通常称为ARM内核)最重要的一点是ARM设计处理器,然后将设计许可给客户。与英特尔或IBM等其他供应商不同,ARM不生产硅片。相反,德州仪器(Texas Instruments)和高通(Qualcomm)等供应商购买了使用ARM内核设计的许可证,并添加了额外的组件。然后,他们将合同交给半导体制造公司,或使用自己的制造设施在硅上制造整个SOC(片上系统)。
ARM的最新(截至2012年)ARMv8架构有三条处理器线:
- 第1系列处理器被称为ARM Cortex-M系列。这些处理器主要设计用于医疗设备、汽车和工业电子等嵌入式应用中的微控制器,其设计背后的主要关注点是功率效率和成本。本节将描述具有三阶段流水线的ARM Cortex-M3处理器。
- 第2系列处理器被称为ARM Cortex-R系列。这些处理器是为实时应用而设计的,主要重点是可靠性、高速和实时响应。它们不适用于智能手机等消费电子设备,不支持运行使用虚拟内存的操作系统。
- 第3系列处理器被称为ARM Cortex-A系列。这些处理器设计用于在智能手机、平板电脑和一系列高端嵌入式设备上运行常规用户应用程序。这些ARM内核通常具有复杂的管线,支持向量操作,并且可以运行需要虚拟内存硬件支持的复杂操作系统。
ARM Cortex-M3
让我们从主要为嵌入式处理器市场设计的ARM Cortex-M系列处理器开始。对于这样的嵌入式处理器,能效和成本比原始性能更重要。因此,ARM工程师设计了一个3执行的流水线,没有非常复杂的功能。
Cortex-M3支持ARMv7-M指令集的基本版本,通常使用ARM AMBA总线连接到其他组件,如下图所示。

连接到AMBA总线的ARM Cortex-M3以及其他组件。
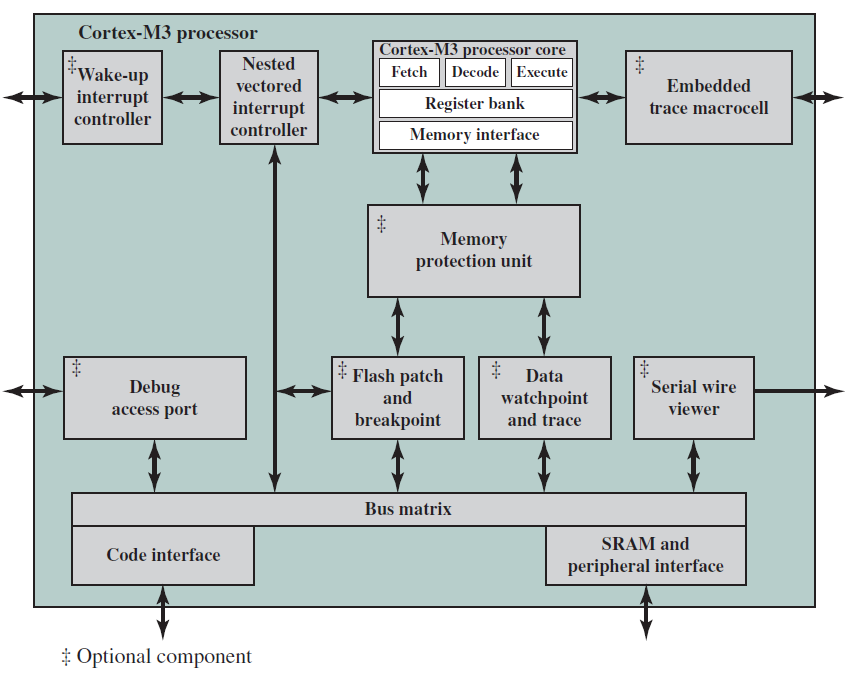
ARM Cortex-M3架构图。
AMBA(高级微控制器总线体系结构)是一种由ARM设计的总线体系结构,它用于将ARM内核与基于SOC的系统中的其他组件连接。例如,智能手机和移动设备中的大多数处理器使用AMBA总线通过桥接设备连接到高速内存设备、DMA引擎和其他外部总线。一种这样的外部总线是APB总线(高级外围总线),用于连接到外围设备,例如键盘、UART控制器(通用异步收发器协议)、计时器和PIO(并行输入输出)接口。
下图显示了ARM Cortex-M3的流水线。它有三个阶段:获取(F)、解码(D)和执行(E)。提取阶段从内存中提取指令,是所有三个阶段中最小的阶段。
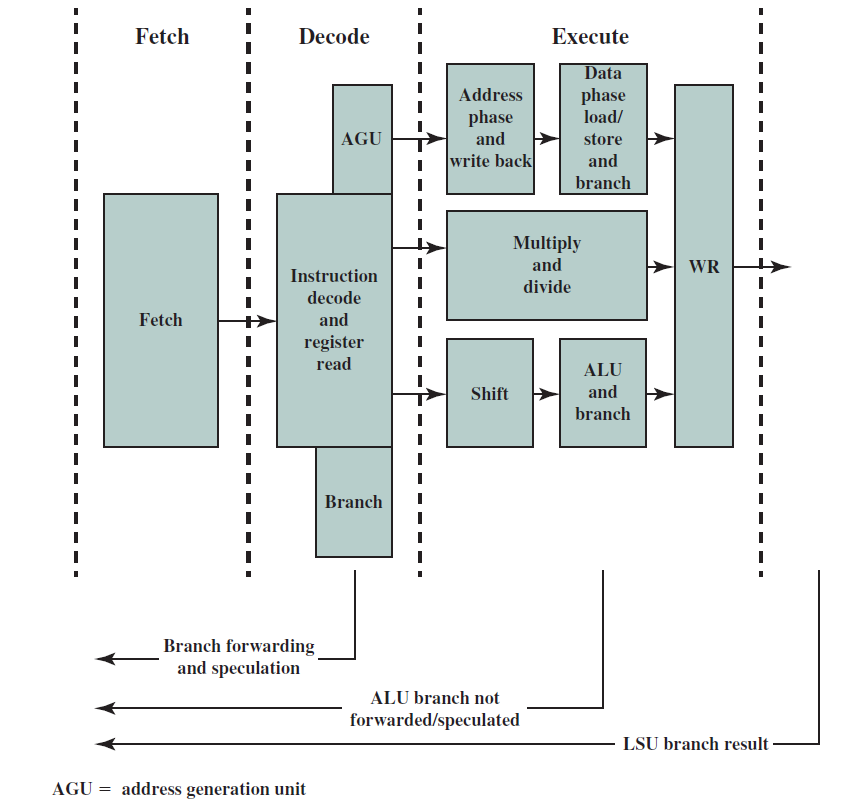
ARM Cortex-M3的流水线。
解码阶段(D阶段)有三个不同的子单元,如上图所示。D阶段有一个指令解码和寄存器读取单元,解码指令,并形成指令包,同时读取指令中嵌入的操作数的值,也从寄存器文件中读取值。AGU(地址生成单元)提取指令中的所有字段,并在流水线的下一阶段调度加载或存储指令的执行。它在处理ldm(加载多个)和stm(存储多个)指令时扮演着特殊的角色。这些指令可以同时读取或写入多个寄存器,AGU使用管线中的单个ldm或stm指令创建多个操作。分支单元用于分支预测,它预测分支结果和分支目标。
执行阶段在功能方面相当繁重,有些指令需要2个周期才能执行,先看看常规ALU和分支指令。ARM指令可以有一个移位器操作数,其次,从其12位编码计算32位立即数的值本质上是移位(旋转是移位的一种类型)操作,这两种操作都由具有称为桶形移位器的硬件结构的移位单元执行。一旦操作数就绪,它们就被传递给ALU和分支单元,后者计算分支结果/目标和ALU结果。
ARM有两种分支:直接分支和间接分支。对于直接分支,分支目标与当前PC的偏移量嵌入指令中,比如到标签的分支是直接分支的示例,可以在解码阶段计算直接分支的分支目标。ARM还支持间接分支,其中分支目标是ALU或内存指令的结果,例如,指令ldr-pc, [r1, #10]是间接分支的一个示例,此处的分支目标的值等于加载指令从内存加载的值,通常很难预测间接分支的目标。在Cortex-M3处理器中,每当出现分支预测失误(目标或结果)时,在分支后提取的两条指令都会被取消,处理器开始从正确的分支目标获取指令。
除了基本的ALU,Cortex-M3还有一个乘除单元,可以执行有符号和无符号、乘法和除法。Cortex-M3支持两条指令sdiv和udiv,分别用于有符号和无符号除法。除了这些指令外,它还支持乘法和乘法累加操作。
加载和存储指令通常需要两个周期,它们具有地址生成阶段和内存访问阶段。加载指令需要2个周期才能执行,注意,在第二个周期中,其他指令不可能在E阶段执行。管线因此停滞一个周期,这种特殊特性降低了管线的性能,ARM在其高性能处理器中消除了这一限制。存储指令也需要2个周期才能执行,但访问内存的第二个周期不会使管线停止。处理器将值写入存储缓冲器(类似于写入缓冲器),然后继续执行。还可以发出背靠背(连续循环)存储和加载指令,其中加载读取存储写入的值。管线不需要为加载指令暂停,因为它从存储缓冲区读取存储写入的值。
ARM Cortex-A8
与Cortex-M3(嵌入式处理器)相比,Cortex-A8被设计为可以在复杂的智能手机和平板电脑处理器上运行的全边缘处理器。A代表应用程序,ARM的意图是使用该处理器在移动设备上运行常规应用程序。其次,这些处理器被设计为支持虚拟内存,并且还包含专用浮点和SIMD单元。
Cortex-A8内核流水线的设计特点是它是一个双问题超标量处理器,但并不是一个完全乱序的处理器。问题的逻辑是无序的Cortex-A8有一个13阶段整数流水线,带有复杂的分支预测逻辑。由于它使用深度管线,因此可以以比其他具有较浅管线的ARM处理器更高的频率对其进行计时。Cortex-A8内核的时钟频率在500MHz和1GHz之间,在嵌入式领域是相当快的时钟速度。
除了整数管线,Cortex-A8还包含一个专用浮点和SIMD单元。浮点单元实现ARM的VFP(矢量浮点)ISA扩展,SIMD单元实现ARM NEON指令集。该单元也是流水线式的,有10个阶段。此外,ARM Cortex-A8处理器具有单独的指令和数据缓存,可以选择连接到大型共享二级缓存。
下图显示了ARM Cortex-A8处理器的流水线设计。提取单元在两个阶段之间进行流水线处理,主要目的是获取指令并更新PC,它还内置了指令预取器、ITLB(指令TLB)和分支预测器,指令随后传递到解码单元。

ARM Cortex-A8处理器的流水线。
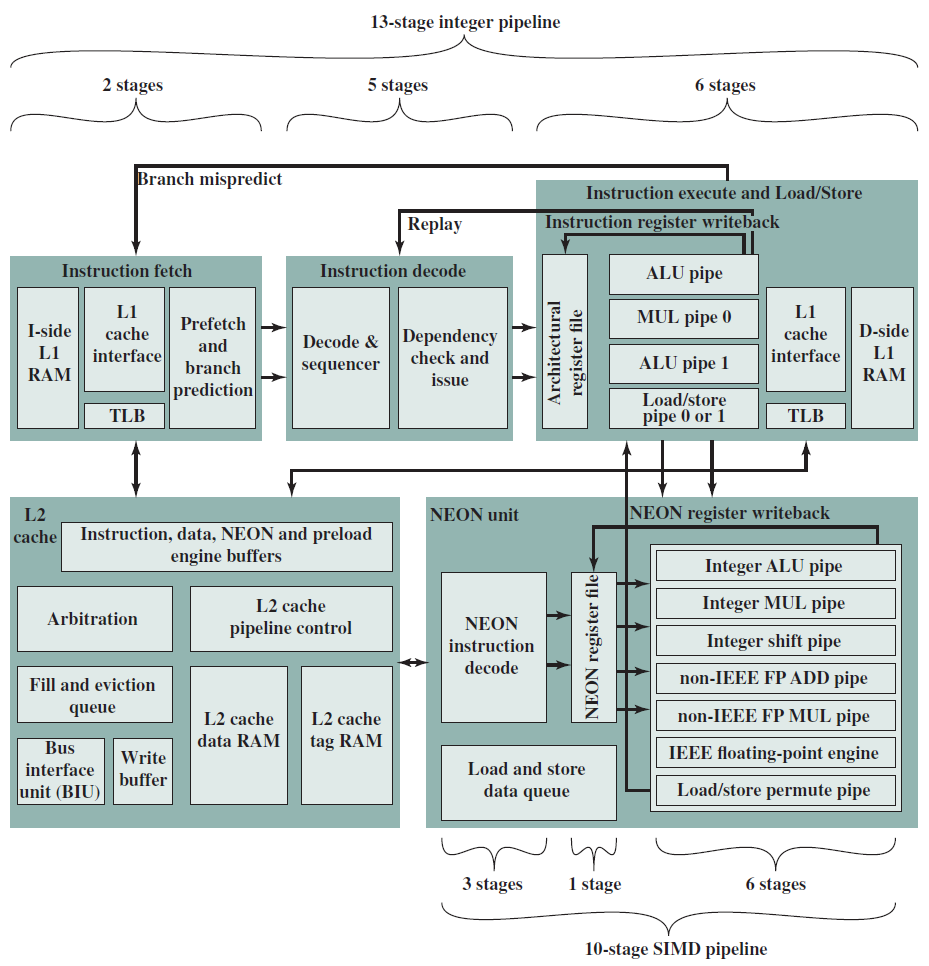
ARM Cortex-A8架构图。
解码单元在5阶段之间进行流水线处理。Cortex-A8处理器中的解码单元比Cortex-M3更复杂,因为它有额外的责任检查指令之间的相关性,并一起发出两条指令。因此,转发、暂停和互锁逻辑要复杂得多。让我们对两个指令执行槽0和1进行编号,如果解码阶段找到两个不具有任何相关性的指令,那么它会用指令填充两个执行槽,并将它们发送到执行单元。否则,解码阶段只发出一个时隙。
执行单元跨6个阶段进行流水线处理,它包含4个独立的流水线,有两个ALU管道,两个指令都可以使用。它有一个乘法管线,只能由插槽0中发出的指令使用。最后,它有一个加载/存储管线,可以再次被两个发布槽中发出的指令使用。
NEON和VFP指令发送到NEON/VFP单元,NEON/VFP指令的解码和调度需要三个周期,NEON/VFP单元从包含32个64位寄存器的NEON寄存器文件中取出操作数。NEON指令还可以将寄存器文件视为十六个128位寄存器,NEON/VFP单元有六个6级流水线用于算术运算,还有一个6阶段管道用于加载/存储操作,加载矢量数据是SIMD处理器中非常关键的性能操作。因此,ARM在NEON单元中有一个专用的加载队列,用于通过从L1缓存加载数据来填充NEON寄存器文件。为了存储数据,NEON单元将数据直接写入L1缓存。
每个一级缓存(指令/数据)的块大小为64字节,关联性为4,可以是16KB或32KB。其次,每个L1缓存有两个端口,每个周期可以为NEON和浮点操作提供4个字。需要注意的是,NEON/VFP单元和整数管线共享L1数据缓存。L1缓存可选地连接到大型L2缓存,它的块大小为64字节,是8路集关联的,最大可达1MB,二级缓存分为多个存储库。可以同时查找两个标记,数据数组访问并行进行。

ARM Cortex-A8 NEON和浮点管线。
ARM Cortex-A15
ARM Cortex-A15是2013年初发布的最新ARM处理器,面向高性能应用。
Cortex-A5处理器比Cortex-M3和Cortex-A8复杂得多,功能也更强大。它没有使用乱序内核,而是使用了3执行的超标量无序内核。它还有一条更深的管线,具体来说,它有一个15阶段整数管线和一个17-25阶段浮点管线。更深的管线允许它以更高的频率(1.5-2.5GHz)运行。此外,它在内核上完全集成了VFP和NEON单元,而不是将它们作为单独的执行单元。与服务器处理器一样,它被设计为访问大量内存,可以支持40位物理地址,意味着它可以使用支持系统级一致性的最新AMBA总线协议来寻址多达1 TB的内存。Cortex-A15旨在运行现代操作系统和虚拟机,虚拟机是可以帮助在同一处理器上同时运行多个操作系统的特殊程序,用于服务器和云计算环境,以支持具有不同软件需求的用户。Cortex-A15采用了先进的电源管理技术,可在不使用处理器时动态关闭部分处理器。
Cortex-A15处理器的另一个标志性特点是它是一个多核处理器,为每个集群组织4个核心,每个芯片可以有多个集群。Snoop控制单元提供集群内的一致性,AMBA4规范定义了跨集群支持缓存和系统级一致性的协议,AMBA4总线还支持同步操作。内存系统也更快、更可靠,Cortex-A15的内存系统使用SECDED(单错误纠正,双错误检测)错误控制代码。
下图显示了Cortex-A15内核的管线概览。有5个提取阶段,fetch更复杂,因为Cortex-A15有一个复杂的分支预测器,可以处理多种类型的分支指令。解码、重命名和指令分派单元在7个阶段之间进行流水线处理。寄存器重命名单元和指令窗口对无序处理器的性能至关重要,它们的作用是在给定的周期内发出准备执行的指令集。

ARM Cortex-A15处理器的概览。
ARM Cortex-A15 MPCore芯片结构图。
Cortex-A15有几个执行管线。整数ALU和分支管线各需要3个周期,但乘法和加载/存储管线更长。与其他将NEON/VFP单元视为物理独立单元的ARM处理器不同,Cortex-A15将其集成在内核上,是乱序管线的一部分。现在更详细地看一下管线(参见下图)。
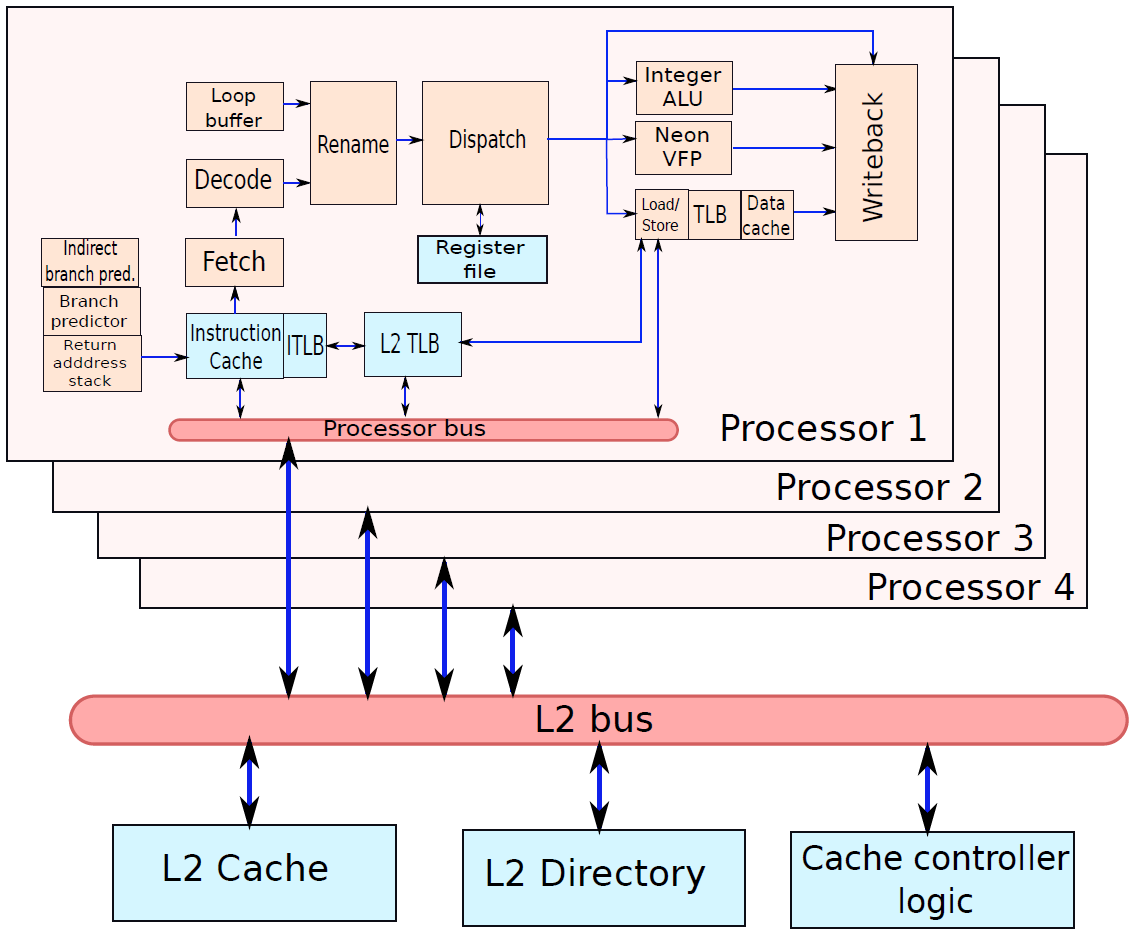

ARM Cortex-A15处理器的管线。
Cortex-A5内核(Cortex-A8的分支预测器也具有相同的功能)分支预测器包含直接分支预测器、间接分支预测器和预测返回地址的预测器。间接分支预测器尝试基于分支指令的PC来预测分支目标,有一个256个条目,由给定分支的历史及其PC索引。实际上不需要复杂的分支预测逻辑来预测返回指令的目标,一个更简单的方法是每当调用函数时记录返回地址,并将其推送到堆栈(称为返回地址堆栈,RAS)。由于函数调用表现出后进先出的行为,因此需要简单地弹出RAS并在从函数返回时获取返回地址的值。最后,为了支持更宽的问题宽度,提取单元被设计为一次从指令缓存中提取128位。
循环缓冲区(也存在于Cortex-A8中)是解码阶段的一个非常有趣的补充。假设在循环中执行一组指令,在任何其他处理器中,都需要在循环中重复获取指令,并对其进行解码,这个过程浪费了能量和内存带宽。可以通过将所有解码的指令包保存在循环缓冲区中来优化此过程,以便在执行循环时完全绕过提取和解码单元,寄存器重命名阶段因此可以从解码单元或循环缓冲器获得指令。
内核维护一个包含所有指令结果的重新排序缓冲区(ROB),ROB中的条目是按程序顺序分配的。重命名阶段将操作数映射到ROB中的条目(在ARM文档中称为结果队列),例如,如果指令3需要一个将由指令1产生的值,则相应的操作数被映射到指令1的ROB条目。所有指令随后进入指令窗口,等待其源操作数就绪。一旦准备就绪,它们就会被发送到相应的管线。Cortex-A15具有2个整数ALU、1个分支单元、1个乘法单元和2个加载/存储单元,NEON/VFP单元每个周期可接受2条指令。
加载/存储单元具有4阶段管线。为了确保精确的异常存储,只有当指令到达ROB的头部时(管线中没有更早的指令),才会向内存系统发出存储。同时,对管线中相同地址执行存储操作的任何加载操作都会通过转发路径获取其值。两个L1缓存(指令和数据)通常各为32KB。
Cortex-A15处理器支持大型二级缓存(高达4 MB),它是一个带有主动预取器的16路集合关联缓存。L1缓存和L2缓存是缓存一致性协议的一部分,Cortex-A55使用基于目录的MESI协议,二级缓存包含一个窥探标记数组,该数组维护一级所有目录的副本。如果I/O操作希望修改某一行,则二级缓存使用窥探标记数组来查找该行是否位于任何一级缓存中。如果任何一级缓存包含该行的副本,则该副本无效。同样,如果存在DMA读取操作,则L2控制器从包含其副本的L1缓存中取出该行。此外,还可以扩展此协议以支持L3缓存和一系列外围设备。
Cortex-A53是一个可配置内核,支持ARMv8指令集架构,作为IP(知识产权)核心交付。IP核心是嵌入式、个人移动设备和相关市场的主要技术交付形式,数十亿的ARM和MIPS处理器已经从这些IP核中创建出来。
注意,IP核与Intel i7多核计算机中的核不同。IP核(其本身可能是多核)被设计为与其他逻辑结合(因此它是芯片的“核心”),包括专用处理器(例如视频编码器或解码器)、I/O接口和存储器接口,然后被制造为针对特定应用优化的处理器。虽然处理器内核在逻辑上几乎相同,但最终产生的芯片有很多不同。一个参数是二级缓存的大小,它可以变化16倍。
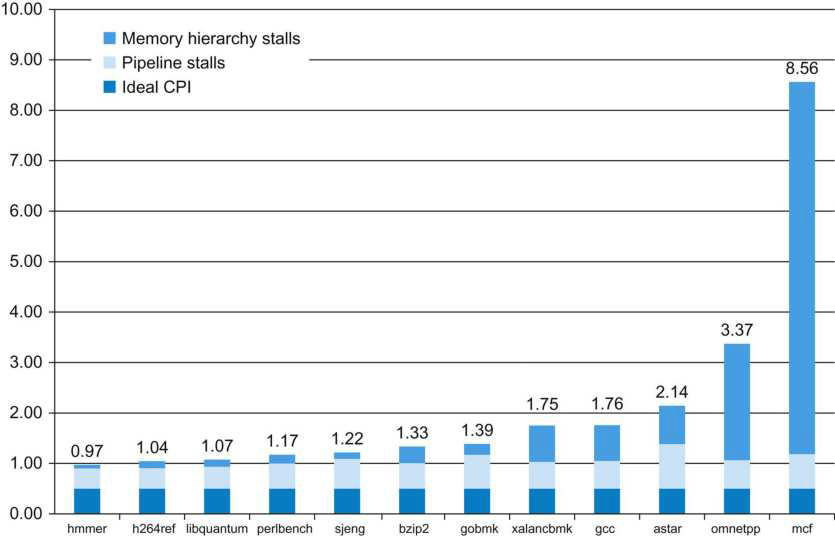
SPEC2006整数基准的ARM Cortex-A53上的CPI。
19.5.5.2 AMD处理器
现在来研究AMD处理器的设计。AMD处理器实现x86指令集,为移动设备、上网本、笔记本电脑、台式机和服务器制造处理器。本节将研究设计频谱两端的两个处理器。AMD Bobcat处理器适用于移动设备、平板电脑和上网本,它实现了x86指令集的一个子集,其设计的主要目标是功率效率和可接受的性能水平。AMD Bulldozer处理器处于另一端,专为高端服务器设计,它针对性能和指令吞吐量进行了优化,也是AMD的第一个多线程处理器,使用了一种称为联合内核的新型内核来实现多线程。
AMD Bobcat
Bobcat处理器设计为在10-15W功率预算内运行,在这个功率预算内,Bobcat的设计者能够在处理器中实现大量复杂的架构特性,如Bobcat使用了一个相当复杂的2执行乱序管线。Bobcat的流水线使用了一个复杂的分支预测器,设计用于在同一周期内获取2条指令。它随后可以以该速率解码它们,并将它们转换为复杂的微操作(Cop)。AMD术语中的复杂微操作是一种类似CISC的指令,可以读取和写入内存,这组Cop随后被发送到指令队列、重命名引擎和调度器。
调度器按顺序选择指令,并将它们分派给ALU、内存地址生成单元和加载/存储单元。为了提高性能,加载/存储单元还无序地向内存系统发送请求。因此很容易地得出结论,Bobcat支持弱内存模型,除了复杂的微架构功能外,Bobcat还支持SIMD指令集(最高SSE 4)、自动将处理器状态保存在内存中的方法以及64位指令。为了确保处理器的功耗在限制范围内,Bobcat包含大量节能优化,其中一个突出的机制被称为时钟门控( clock gating),对于未使用的单元,时钟信号被设置为逻辑0,确保了在未使用的单元中没有信号转换,因此没有动态功率的耗散。Bobcat处理器还尽可能使用指向数据的指针,并尽量减少在处理器中不同位置复制数据。
下图显示了AMD Bobcat处理器的流水线框图。Bobcat处理器的一个显著特点是相当复杂的分支预测器,需要首先预测指令是否是分支,因为在x86 ISA中没有办法快速解决这个问题。如果一条指令被预测为分支,需要计算其结果(执行/未执行)和目标。AMD使用基于高级模式匹配的专有算法进行分支预测,在分支预测之后,提取引擎一次从I缓存中提取32个字节,并将其发送到指令缓冲区。
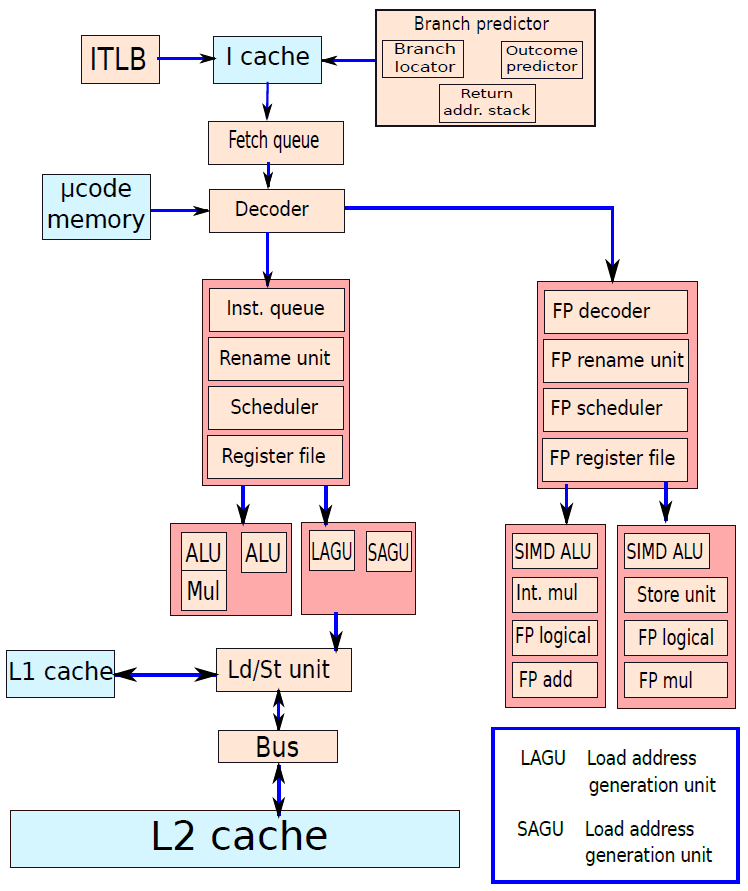
AMD Bobcat处理器的流水线。
解码器一次考虑22个指令字节,并试图划分指令边界。这是一个缓慢且计算密集的过程,因为x86指令长度可能具有很大的可变性。较大的处理器通常缓存该信息,以便第二次解码指令更容易。由于Bobcat的解码吞吐量仅限于2条指令,因此它没有此功能。现在,大多数x86指令对在22字节内,因此解码器可以在大多数时间提取这两个x86指令的内容。解码器通常将每个x86指令转换为1-2个Cop,对于一些不常用的指令,它用微码序列替换指令。
随后,Cop被添加到56条目重新排序缓冲区(ROB)中。Bobcat有两个调度程序,整数调度器有16个条目,浮点调度器有18个条目。整数调度器在每个周期选择两条指令执行,整数管线有两个ALU和两个地址生成单元(1个用于加载,1个用于存储),浮点管线也可以在每个周期执行两次Cop,但有一些限制。
处理器中的加载存储单元将值从存储转发到流水线中的加载指令。Bobcat拥有32KB(8路关联)的L1 D和I缓存,它们连接到512 KB的二级缓存(16路集合关联),总线接口将二级缓存连接到主内存和系统总线。
现在考虑一下管线的时间调度。Bobcat整数管道分为16个阶段,由于管线较深,可以在1-2GHz之间的频率对核心进行时钟控制。Bobcat管线有6个提取周期和3个解码周期,最后3个提取周期与解码周期重叠,重命名引擎和调度程序需要4个周期。对于大多数整数指令,需要1个周期读取寄存器文件,1个周期访问ALU,以及1个周期将结果写回寄存器文件。浮点流水线有7个附加阶段,加载存储单元需要3个附加阶段用于地址生成和数据缓存访问。
AMD Bulldozer
顾名思义,Bulldozer核心位于频谱的另一端,主要用于高端台式机、工作站和服务器。除了是一个激进的无序机器之外,它还具有多线程功能。Bulldozer实际上是多核、单粒度多线程处理器和SMT的组合,其核心实际上是一个“联合核心”,由两个共享功能单元的较小核心组成。
两个Bulldozer线程共享获取引擎(参见下图)和解码逻辑。管线的这一部分(称为前端)在两个线程之间每一个周期或几个周期切换一次,然后将整数、加载存储和分支指令分派到两个内核中的一个。每个内核包含一个指令调度器、寄存器文件、整数执行单元、L1缓存和一个加载存储单元,每个内核可被视为一个没有指令获取和解码功能的自我支持的内核。两个内核共享在SMT模式下运行的浮点单元,它有专用的调度器和执行单元Bulldozer处理器设计用于在3-4GHz下运行服务器和数字工作负载,最大功耗限制为125-140W。

Bulldozer处理器概览。
现在考虑下图中处理器的更详细视图。
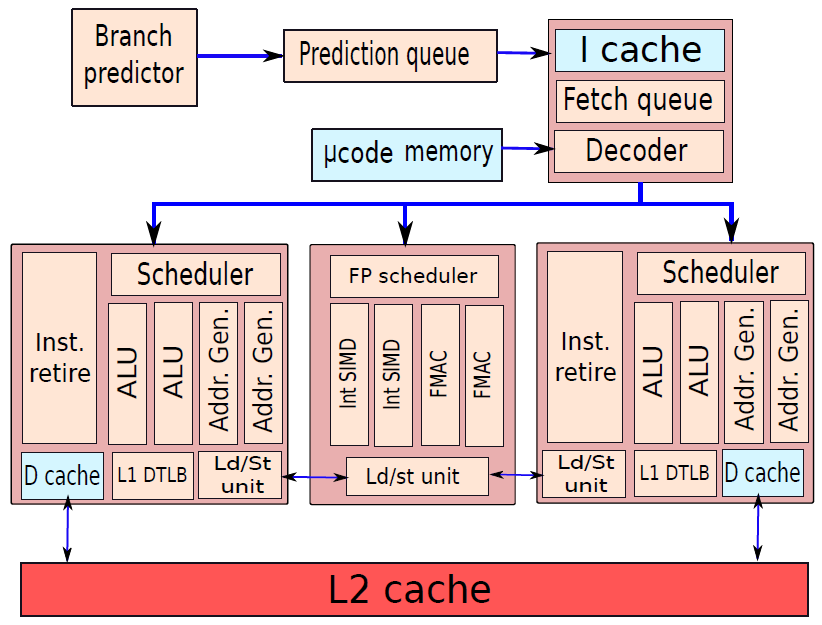
Bulldozer处理器的读取宽度是Bobcat处理器的两倍。它每个周期最多可以提取和解码4条x86指令,与Bobcat类似,Bulldozer处理器具有复杂的分支预测逻辑,可以预测指令是否为分支、分支结果和分支目标。它有一个多级分支目标缓冲区,可以保存大约5500条分支指令的预测分支目标。
解码引擎将x86指令转换为Cop。AMD中的一个Cop是CISC指令,尽管有时比原始的x86指令简单,大多数x86指令只转换为一个Cop。然而,有些指令被转换为多个Cop,有时需要使用微码内存进行指令转换。解码引擎的一个有趣的方面是它可以动态地合并指令以生成更大的指令,例如,它可以将比较指令和后续分支指令合并到一个Cop中。这被称为宏指令融合。
随后,整数指令被分派到内核执行。每个内核都有一个重命名引擎、指令调度器(40个条目)、一个寄存器文件和一个128个条目的ROB。核心的执行单元由4个独立的管线组成,两个管线具有ALU,另外两个管道专用于内存地址生成。加载存储单元协调对内存的访问,将存储之间的数据转发给加载,并使用跨步预取器执行积极的预取。跨步预取器可以自动推断数组访问,并从将来最可能访问的数组索引中提取。
两个内核共享一个64KB的指令缓存,而每个内核都有一个16KB的一级写缓存,每次加载访问需要4个周期。L1缓存连接到不同大小的L2缓存,在核心之间共享,具有18个周期的延迟。
浮点单元在两个内核之间共享,不仅仅是一个功能单元,可被看作是一个SMT处理器,同时调度和执行两个线程的指令。它有自己的指令窗口、寄存器文件、重命名和唤醒选择(无序调度)逻辑。Bulldozer的浮点单元有4条处理SIMD指令(整数和浮点)和常规浮点指令的流水线。前两条管线具有128位浮点ALU,称为FMAC单元,FMAC(浮点乘法累加)单元可以执行形式(a <-- a+b*c)的运算,以及常规浮点运算。最后两条管线具有128位整数SIMD单元,另外,最后一条管线还用于将结果存储到内存中。浮点单元有一个专用的加载存储单元来访问内核中的缓存。
19.5.5.3 Intel处理器
前些年的英特尔处理器在笔记本电脑和台式机市场占据主导地位,本节将介绍两种设计非常不同的英特尔处理器的设计。第一个处理器是Intel Atom,专为手机、平板电脑和嵌入式计算机设计。另一端是Sandy Bridge多核处理器,它是Intel Core i7系列处理器的一部分,这些处理器用于高端台式机和服务器。这两个处理器都有非常不同的业务需求,导致了两种截然不同的设计。
x86的祖先是1972年开始生产的第一批微处理器。Intel 4004和8008是极其简单的4位和8位累加器式架构,Morse等人将8086从上世纪70年代末的8080演变为具有更好吞吐量的16位架构。当时几乎所有微处理器的编程都是用汇编语言完成的,内存和编译器都很短缺。英特尔希望保持8080用户的基础,因此8086被设计为与8080“兼容”。8086从来都不是与8080兼容的目标代码,但其架构足够接近,可以自动完成汇编语言程序的翻译。
1980年初,IBM选择了一个带有8位外部总线的8086版本,称为8088,用于IBM PC。他们选择了8位版本以降低体系结构的成本,这一选择,加上IBM PC的巨大成功,使得8086体系结构无处不在。IBM PC的成功部分归因于IBM开放了PC的体系结构,并使PC克隆产业蓬勃发展。80286、80386、80486、奔腾、奔腾Pro、奔腾II、奔腾III、奔腾4和AMD64扩展了体系结构并提供了一系列性能增强。
虽然68000被选择用于Macintosh,但Mac从未像PC那样普及,部分原因是苹果不允许基于68000的Mac克隆,68000也没有获得8086所享受的软件。摩托罗拉68000在技术上可能比8086更重要,但IBM的选择和开放架构策略的影响主导了68000在市场上的技术优势。
一些人认为,x86指令集的不雅是不可避免的,是任何架构取得巨大成功所必须付出的代价。我们拒绝这种观点。显然,没有一个成功的架构可以抛弃以前实现中添加的特性,随着时间的推移,一些特性可能会被视为不可取的。x86的尴尬始于8086指令集的核心,并因8087、80286、80386、MMX、SSE、SSE2、SSE3、SSE4、AMD64(EM64T)和AVX中发现的架构不一致扩展而加剧。
一个反例是IBM 360/370体系结构,它比x86老得多,主宰了大型机市场,就像x86主宰了PC市场一样。毫无疑问,由于有了更好的基础和更兼容的增强功能,该指令集在首次实现50年后比x86更有意义。将x86扩展到64位寻址意味着该体系结构可能会持续几十年,未来的指令集人类学家将从这样的架构中一层又一层地剥离,直到他们从第一个微处理器中发现人工制品。鉴于这样的发现,他们将如何判断当今的计算机架构?
Intel核心微架构
尽管超标量设计的概念通常与RISC架构相关联,但同样的超标量原理也可以应用于CISC机器,其中值得注意的例子是Intel x86架构。Intel系列中超标量概念的演变值得注意,386是一种传统的CISC非管线机器,486引入了第一个管线x86处理器,将整数运算的平均延迟从两到四个周期减少到一个周期,但仍限于每个周期执行一条指令,没有超标量元素。最初的奔腾有一个适度的超标量组件,由两个独立的整数执行单元组成,奔腾Pro推出了全面的超标量设计,乱序执行。随后的x86型号改进并增强了超标量设计。
下图显示了x86管线架构的版本。Intel将流水线架构称为微架构(microarchitecture),微架构是机器指令集体系结构的基础和实现,也称为Intel核心微架构。它在Intel core 2和Intel Xeon处理器系列的每个处理器核上实现,还有一个增强型Intel核心微架构。两种微架构之间的一个关键区别是,后者提供了第三级缓存。
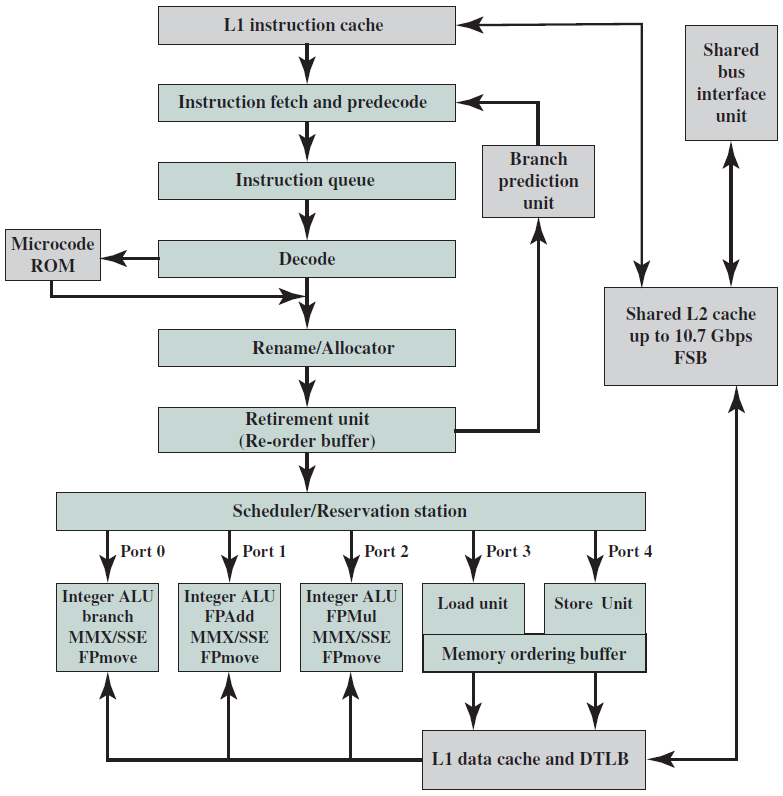
Intel核心微架构。

Intel Core i7-990X结构图。
Intel 8085 CPU结构图。
下表显示了缓存架构的一些参数和性能特征。所有缓存都使用写回更新策略,当指令从内存位置读取数据时,处理器会按以下顺序在缓存和主内存中查找包含此数据的缓存行:
- 发起核心的L1数据缓存。
- 其他核心的L1数据缓存和L2缓存。
- 系统内存。
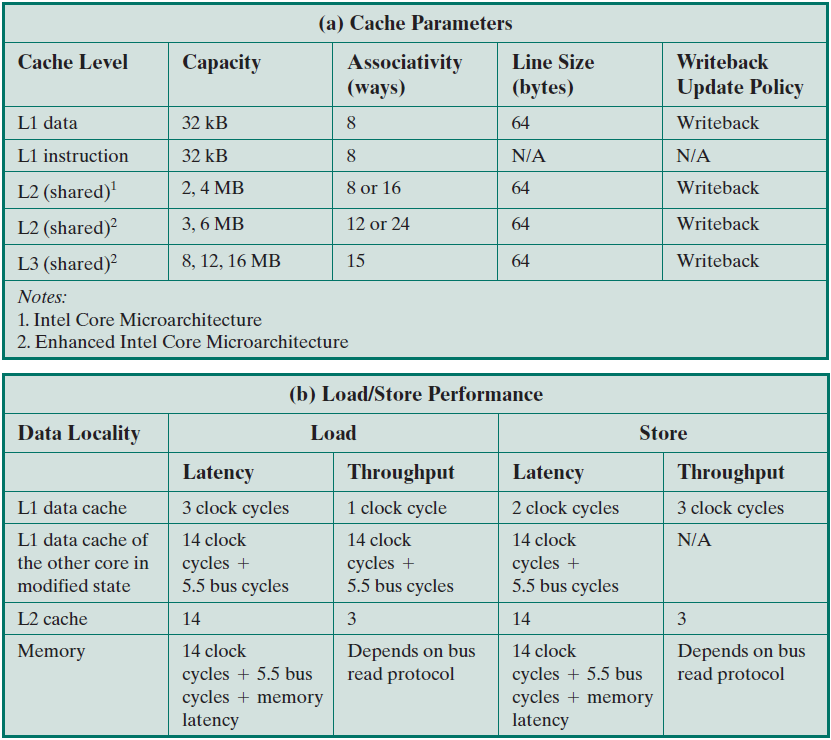
基于Intel Core微架构的处理器的缓存/内存参数和性能。
仅当缓存行被修改时,缓存行才会从另一个内核的一级数据缓存中取出,而忽略二级缓存中的缓存行可用性或状态。上表b显示了从内存集群中获取不同位置的前四个字节的特性,延迟列提供访问延迟的估计值,然但实际延迟可能会因缓存负载、内存组件及其参数而异。
Intel Core微架构的管线包含:
- 一种有序提交前端,从内存中获取指令流,具有四个指令解码器,将解码后的指令提供给无序执行核心。每个指令都被翻译成一个或多个固定长度的RISC指令,称为微操作(micro-operation或micro-ops)。
- 一个无序的超标量执行核心,每个周期最多可以发出6个微操作,并在源就绪且执行资源可用时重新排序微操作以执行。
- 一种有序的引退单元,确保微操作的执行结果得到处理,架构状态和处理器的寄存器集根据原始程序顺序进行更新。
实际上,Intel核心微架构在RISC微架构上实现了CISC指令集架构。内部RISC微操作通过至少14阶段的流水线,在某些情况下,微操作需要多个执行阶段,从而导致更长的管线,与早期Intel x86处理器和Pentium上使用的5阶段流水线形成了鲜明对比。
接下来阐述前端(Front End)。
先阐述分支预测单元。前端需要提供解码的指令(微操作),并将流维持到一个6阶段的无序引擎,该引擎由三个主要部件组成:分支预测单元(BPU)、指令提取和预译码单元、指令队列和译码单元。
分支预测单元此单元通过预测各种分支类型(条件、间接、直接、调用和返回),帮助指令获取单元获取最可能执行的指令,BPU为每种分支类型使用专用硬件,分支预测使处理器能够在决定分支结果之前很久就开始执行指令。
微架构使用基于最近执行分支指令的历史的动态分支预测策略。维护分支目标缓冲区(BTB),该缓冲区缓存关于最近遇到的分支指令的信息。每当在指令流中遇到分支指令时,都会检查BTB,如果BTB中已经存在条目,则指令单元在确定是否预测分支被采取时由该条目的历史信息引导。如果预测到分支,则与该条目关联的分支目标地址用于预取分支目标指令。
一旦指令被执行,相应条目的历史部分被更新以反映分支指令的结果。如果此指令未在BTB中表示,则将此指令的地址加载到BTB中的条目中,如果需要,将删除较旧的条目。
前两段的描述大体上适用于原始奔腾机型以及后来的奔腾机型(包括后续的Intel机型)上使用的分支预测策略,但在奔腾的情况下,使用了相对简单的2位历史方案。后来的型号具有更长的流水线(Intel核心微架构为14阶段,奔腾为5阶段),因此预测失误的惩罚更大。所以后面的模型使用了更复杂的分支预测方案,具有更多的历史比特,以降低预测失误率。
根据以下规则,使用静态预测算法预测在BTB中没有历史的条件分支:
- 对于与指令指针(IP)无关的分支地址,如果分支是返回,则预测执行,否则不执行。
- 对于IP相对后向条件分支,请进行预测。此规则反映了循环的典型行为。
- 对于IP相对前向条件分支,预测不执行。
再阐述指令获取和预译码单元。指令获取单元包括指令翻译后备缓冲器(ITLB)、指令预取器、指令缓存和预译码逻辑。
指令获取是从一级指令缓存执行的。当发生一级缓存未命中时,有序前端将新指令从二级缓存一次64字节送入一级缓存。默认情况下,指令是按顺序提取的,因此每个二级缓存行提取都包含下一条要提取的指令,经由分支预测单元的分支预测可以改变该顺序提取操作。ITLB将给定的线性IP地址转换为访问二级缓存所需的物理地址,前端的静态分支预测用于确定下一个要获取的指令。
预译码单元接受来自指令高速缓存或预取缓冲器的十六个字节,并执行以下任务:
- 确定指令的长度。
- 解码与指令相关的所有前缀。
- 标记解码器指令的各种属性(如“is branch”)。
预编码单元每个周期最多可将六条指令写入指令队列。如果一个提取包含六条以上的指令,则预解码器在每个周期继续解码多达六条指令,直到提取中的所有指令都写入指令队列。后续提取只能在当前提取完成后进入预编码。
最后阐述指令队列和解码单元。提取的指令被放置在指令队列中,从那里,解码单元扫描字节以确定指令边界,由于x86指令的长度可变,是一个必要的操作。解码器将每个机器指令翻译成一到四个微操作,每个微操作都是118位RISC指令。请注意,大多数纯RISC机器的指令长度仅为32位,需要更长的微操作长度来适应更复杂的x86指令。尽管如此,微操作比它们派生的原始指令更容易管理。
一些指令需要四个以上的微操作,这些指令被传送到微码ROM,其中包含与复杂机器指令相关的一系列微操作(五个或更多),例如一个字符串指令可以转换为一个非常大(甚至数百个)的重复微操作序列。因此,微码ROM是一个微程序控制单元。
生成的微操作序列被传递到重命名/分配器模块。
上面阐述完前端的三个部件,接下来阐述乱序执行逻辑。
处理器的这一部分对微操作进行重新排序,以允许它们在输入操作数就绪时尽快执行。分配阶段分配执行所需的资源,它执行以下功能:
- 如果在一个时钟周期内到达分配器的三个微操作中的一个无法使用所需的资源(如寄存器),则分配器会暂停管线。
- 分配器分配一个重新排序缓冲区(ROB)条目,该条目跟踪随时可能正在进行的126个微操作之一的完成状态。
- 分配器为微操作的结果数据值分配128个整数或浮点寄存器项中的一个,并且可能分配一个用于跟踪机器流水线中48个加载或24个存储之一的加载或存储缓冲区。
- 分配器在指令调度器前面的两个微操作队列之一中分配一个条目。
ROB是一个循环缓冲区,最多可容纳126个微操作,还包含128个硬件寄存器。每个缓冲区条目由以下字段组成:
- 状态:指示此微操作是否计划执行、是否已调度执行,或是否已完成执行并准备好退出。
- 内存地址:生成微操作的奔腾指令的地址。
- 微操作:实际操作。
- 别名寄存器:如果微操作引用了16个架构寄存器中的一个,则此条目将该引用重定向到128个硬件寄存器中的其中一个。
微操作按顺序进入ROB,然后微操作从ROB无序地发送到调度/执行单元,调度的标准是适当的执行单元和此微操作所需的所有必要数据项可用,最后微操作按顺序从ROB中退出。为了实现有序清理,在每个微操作被指定为准备清理后,微操作首先被清理。
重命名阶段将对16个架构寄存器(8个浮点寄存器,外加EAX、EBX、ECX、EDX、ESI、EDI、EBP和ESP)的引用重新映射到一组128个物理寄存器中。该阶段消除了由有限数量的架构寄存器引起的错误依赖,同时保留了真实的数据依赖(写入后读取)。
在资源分配和寄存器重命名之后,微操作被放置在两个微操作队列中的一个队列中,在那里它们被保存,直到调度器中有空间为止。两个队列中的一个用于内存操作(加载和存储),另一个用于不涉及内存引用的微操作。每个队列都遵循FIFO(先进先出)规则,但队列之间不保持顺序。也就是说,相对于另一个队列中的微操作,微操作可能会被无序地从一个队列读取。此举为调度器提供了更大的灵活性。
调度器负责从微操作队列中检索微操作,并分派这些微操作以供执行。每个调度程序查找状态指示微操作具有其所有操作数的微操作,如果该微操作所需的执行单元可用,则调度器获取该微操作并将其分派给适当的执行单元。一个周期内最多可调度六个微操作,如果给定的执行单元有多个微操作可用,那么调度器会从队列中按顺序分派它们。这是一种FIFO规则,有利于按顺序执行,但此时指令流已被依赖项和分支重新排列,基本上已乱序。
四个端口将调度器连接到执行单元,端口0用于整数和浮点指令,但分配给端口1的简单整数操作和处理分支预测失误除外。此外,MMX执行单元在这两个端口之间分配,其余端口用于内存加载和存储。
接下来阐述整数和浮点执行单元。
整数和浮点寄存器文件是执行单元挂起操作的源,执行单元从寄存器文件以及L1数据缓存中检索值。单独的管道阶段用于计算标志(如零、负),通常是分支指令的输入。
随后的管线阶段执行分支检查,此函数将实际分支结果与预测结果进行比较。如果分支预测被证明是错误的,那么在处理的各个阶段都存在必须从管道中删除的微操作。然后,在驱动阶段将正确的分支目标提供给分支预测器,该阶段将从新的目标地址重新启动整个管线。
Intel Atom
Intel Atom处理器一开始就有一套独特的要求。设计者必须设计一个非常节能的内核,具有足够的功能来运行商业操作系统和web浏览器,并且完全兼容x86。一种降低功耗的粗略方法是实现x86 ISA的一个子集,这种方法将导致更简单和更节能的解码器。由于已知解码逻辑在x86处理器中是耗电的,因此降低其复杂性是降低功耗的最简单方法之一,但完全的x86兼容性排除了此选项。
因此,设计师不得不考虑非常节能且不影响性能的新颖设计,决定简化管线,只考虑两个问题。乱序管线具有复杂的结构,用于确定指令之间的依赖关系,以及无序执行指令。其中一些结构是指令窗口、重命名逻辑、调度器和唤醒选择逻辑,它们增加了处理器的复杂性,并增加了其功耗。
其次,大多数英特尔处理器通常将CISC指令转换为类似RISC的微操作,这些微操作像流水线中的普通RISC指令一样执行。指令翻译过程消耗大量的能量,Intel Atom的设计者决定放弃指令翻译,Atom管线直接处理CISC指令。对于一些非常复杂的指令,Atom处理器确实使用微码ROM将它们转换为更简单的CISC指令。然而,这更多的是一种例外,而不是一种常态。
与RISC处理器相比,CISC处理器的提取和解码阶段更加复杂,因为指令具有可变的长度,划分指令边界是一个乏味的过程。其次,解码的过程也更加复杂。Atom将其16阶段流水线中的6个阶段用于指令获取和解码,如下图所示,其余阶段执行寄存器访问、数据缓存访问和指令执行等传统功能。除了更简单的流水线之外,Intel Atom处理器的另一个显著特点是它支持双向多线程,现代移动设备通常运行多任务操作系统,用户同时运行多个程序。多线程可以支持这一需求,实现额外的并行性,并减少处理器管线中的空闲时间。管线中的最后3个阶段专门用于处理异常、处理与多线程相关的事件以及将数据写回寄存器或内存。与所有现代处理器一样,存储指令不在关键路径上。通常,不遵守顺序一致性的处理器将其存储值写入写入缓冲区并继续执行后续指令。

Intel Atom处理器的流水线。
现在更详细地描述其设计。从提取和解码阶段开始(见下图)。在提取阶段,Atom处理器预测分支的方向和目标,并将一个字节流提取到指令预取缓冲区。下一个任务是在获取的字节流中划分指令,x86指令的边界是这部分流水线执行的最复杂的任务之一,因此Atom处理器有一个2级预解码步骤,在第一次解码指令后,在指令之间添加1位标记,该步骤由ILD(指令长度解码器)单元执行,然后将指令保存在I缓存中。随后,从I缓存中提取的预解码指令可以绕过预解码步骤,并直接进入解码步骤,因为其长度是已知的。保存这些附加标记会减少I缓存的有效大小,I缓存的大小为36KB,但在添加标记之后,它实际上是32KB。解码器不会将大多数CISC指令转换为类似RISC的微操作。但对于一些复杂的x86指令,有必要通过访问微码内存将它们转换为更简单的微操作。
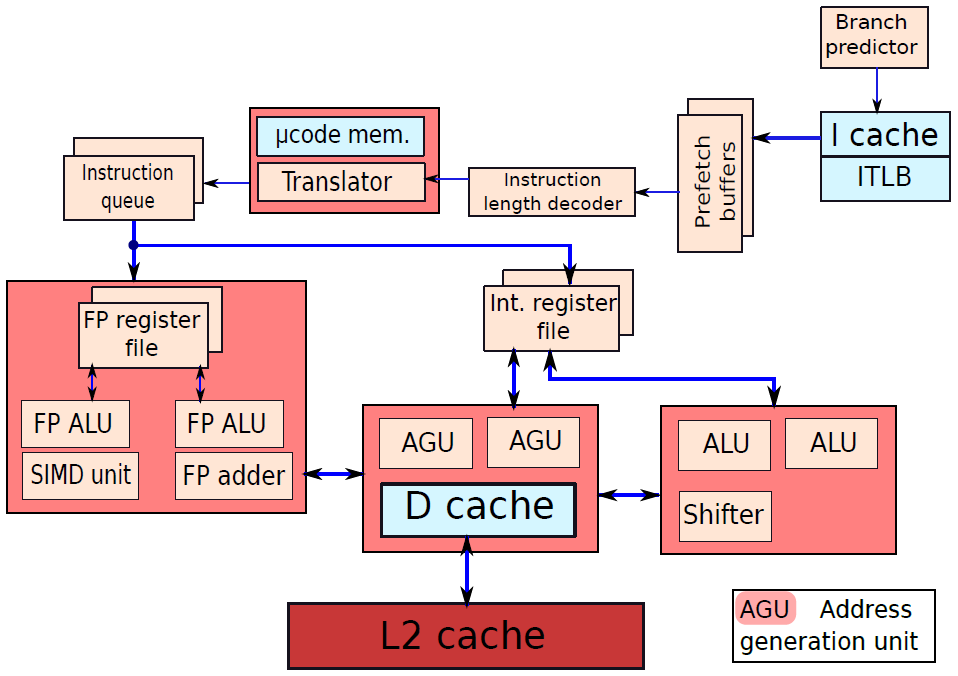
Intel Atom处理器内部结构图。
随后,整数指令被分派到整数执行单元,FP指令被分派给FP执行单元,Atom有两个整数ALU、两个FP ALU和两个用于内存操作的地址生成单元。为了支持多线程,需要有两个指令队列副本(每个线程1个),以及两个整数和FP寄存器文件副本。英特尔没有像指令队列那样创建硬件结构的副本,而是采用了不同的方法,例如在Atom处理器中,32个条目的指令队列被分成两个部分(每个部分有16个条目),每个线程都使用其部分的指令队列。
现在讨论一下关于多线程的一般观点。多线程通过减少芯片上的资源闲置时间来提高其利用率,因此理想情况下,多线程处理器应该具有更高的功率开销(因为活动更高),并且具有更好的指令吞吐量。需要注意的是,除非处理器设计得很明智,否则吞吐量可能无法预测地增加。多线程增加了共享资源(如缓存、TLB和指令调度/调度逻辑)中的争用,特别是,缓存在线程之间进行分区,预计未命中率会增加,TLB的情况也类似。另一方面,流水线不需要在二级未命中的阴影下或在程序的低ILP(指令级并行性)阶段保持空闲。因此,多线程有其优点和缺点,只有当好的效果(性能提高效果)大于坏的效果(争用增加效果)时,才能获得性能优势。
Intel Sandy Bridge
现在讨论一款名为Sandy Bridge处理器的高性能Intel处理器的设计,该处理器是市场上Intel Core i7处理器的一部分。设计Sandy Bridge处理器的主要目的是支持新兴的多媒体工作负载、数字密集型应用程序和多核友好并行应用程序。
Sandy Bridge处理器最显著的特点是它包含一个片上图形处理器。图形处理器装有专门的单元,用于执行图像渲染、视频编码/解码和自定义图像处理,CPU和GPU通过大型共享片上L3缓存进行通信。Sandy Bridge处理器概览如下图所示。
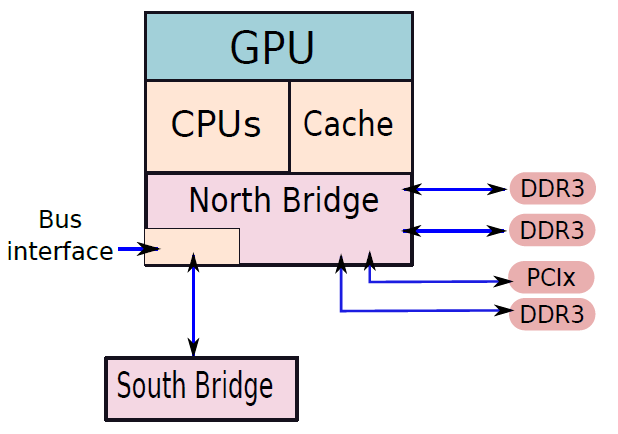
随着芯片上组件的增加,CPU也进行了大量修改。Sandy Bridge处理器完全支持新的AVX指令集,AVX指令集是一个256位SIMD指令集,对于每个SIMD单元,可以同时执行4个双精度操作或8个单精度操作。由于添加了这么多高性能功能,因此也有必要添加许多节能功能。对于未使用的单元,诸如DVFS(动态电压频率缩放)、时钟门控(关闭时钟)和电源门控(关闭一组功能单元的电源)等技术已然常见。此外,Sandy Bridge的设计人员修改了核心的设计,以尽可能减少单元之间的复制值(AMD Bobcat的设计人员也做出了类似的设计决策),并对一些核心结构的设计进行了基本更改,如分支预测器和分支目标缓冲器,以提高功率效率。
需要注意的是,Intel Sandy Bridge等处理器设计为支持多核(4-8),每个内核支持双向多线程,因此可以在8核机器上运行16个线程,这些线程可以在彼此、三级缓存组、GPU和片上北桥控制器之间进行主动通信。有这么多通信实体,需要设计灵活的片上网络,以促进高带宽和低延迟通信。
Sandy Bridge的设计者选择了基于环的互连,而不是传统的总线。Sandy Bridge处理器设计用于32纳米1半导体工艺,它的继任者是Intel Ivy Bridge处理器,该处理器具有相同的设计,但设计用于22纳米工艺。
现在考虑下图中Sandy Bridge核心的详细设计。它有一个32KB的指令缓存,每个周期可以提供4条x86指令。解码x86指令流的第一步是划定它们的边界(称为预译码),一旦4条指令被预先编码,它们就被发送到解码器。Sandy Bridge有4个解码器,其中三个是简单的解码器,一个解码器被称为使用微程序内存的复杂解码器,所有解码器都将CISC指令转换为类似RISC的微操作。Sandy Bridge有一个用于微操作的L0缓存,可以存储大约1500个微操作,L0微操作缓存在性能和功耗方面都具有性能优势。如果分支目标处的指令在L0缓存中可用,则可以减少分支预测失误延迟。由于程序中的大多数分支都在分支附近,因此预计L0缓存的命中率会很高,还可以节省电力。如果一条指令的微操作在L0缓存中可用,就不需要再次获取、预编码和解码该指令,从而避免了这些耗电的操作。

Sandy Bridge处理器的内部结构。
带有内存组件的Core i7管线。
一个有趣的设计决策是设计者针对分支预测器做出的,代表了计算机体系结构中的许多类似问题:应该用复杂的条目设计一个小结构,还是应该用简单的条目设计大结构?例如,应该使用4路16 KB关联缓存,还是2路32 KB关联缓存?一般来说,这种性质的问题没有明确的答案,它们高度依赖于目标工作负载的性质。对于Sandy Bridge处理器,设计者有一个选择,可以选择具有2位饱和计数器的分支预测器,或者具有更多条目的预测器和1位饱和计数器。发现后一种设计的功率和性能权衡更好,因此他们选择了1位计数器。
随后,4个微操作被发送到执行无序调度的重命名和调度单元。在早期的处理器(如Nehalem处理器)中,正在运行的指令的临时结果保存在ROB中,一旦指令完成,它们就被复制到寄存器中,该操作涉及复制数据,从功率的角度来看效率不高。Sandy Bridge避免了这一点,并将结果直接保存在物理寄存器中,类似于高性能RISC处理器。当一条指令到达重命名阶段时,检查重命名表中的映射,并查找包含源操作数值的物理寄存器的ID,或者在将来的某个时间点应该包含这些值。随后,要么读取物理寄存器文件,要么等待生成它们的值。使用物理寄存器文件是一种比使用其他方法更好的方法,这些方法将未完成指令的结果保存在ROB中,然后将结果复制回寄存器文件,使用物理寄存器是快速、简单和节能的。通过在Sandy Bridge处理器中使用这种方法,ROB得到了简化,在任何时间点都有可能有168条正在运行的指令。
Sandy Bridge处理器有3个整数ALU、1个加载单元和1个加载/存储单元,整数单元从160个入口寄存器文件读取和写入其操作数。为了支持浮点运算,它有一个FP加法单元和一个FP乘法单元,它们支持AVX SIMD指令集(对单精度和双精度数字集执行256位操作)。此外,为了支持256位操作,Intel在x86 AVX ISA中添加了新的256位矢量寄存器(YMM寄存器)。
要实现AVX指令集,必须支持来自32KB数据缓存的256位传输。Sandy Bridge处理器可以执行两个128位加载,每个周期执行一个128位存储。在加载YMM(256位)寄存器的情况下,两个128位加载操作被融合为一个(256位的)加载操作。Sandy Bridge有一个256 KB的二级缓存和一个大的(1-8 MB)三级缓存,三级缓存分为多个组,三级组、内核、GPU和北桥控制器使用基于单向环的互连进行连接。注意,单向环的直径是(N-1),因为只能在一个方向上发送消息。为了克服这个限制,每个节点实际上连接到环上的两个点,这些点彼此正好相反,因此有效直径接近N=2。
Sandy Bridge处理器有一个独特功能,称为turbo(涡轮)模式,想法如下。假设处理器有一段静止期(活动较少),所有芯的温度将保持相对较低。再假设用户决定执行计算密集型活动,需要数字密集型的计算,也需要大量的功率。每个处理器都有额定热设计功率(TDP),是处理器允许消耗的最大功率。在turbo模式下,允许处理器在短时间内(20-25秒)消耗比TDP更多的功率,亦即允许处理器以高于标称值的频率运行所有单元。一旦温度达到某个阈值,turbo模式将自动关闭,处理器将恢复正常运行。需要注意的主要点是,在短时间内消耗大量电力不是问题,但即使在短时间里也不允许出现非常高的温度,因为高温会永久损坏芯片,比如如果一根电线熔化,整个芯片就会被破坏。由于处理器需要几秒钟才能加热,因此可以利用这一效应,使用高频率和高功率的相位来快速完成零星的工作。请注意,turbo模式对于耗时数小时的长时间运行作业不适用。
Intel CPU架构
Intel架构指令扩展的软件编程接口以及未来几代Intel处理器可能包含的功能。指令集扩展涵盖了各种应用领域和编程用途。512位
SIMD矢量SIMD扩展,称为Intel Advanced vector extensions 512(Intel AVX-512)指令,与矢量扩展(IntelAVX)和IntelAdvanced vector Extension(IntelAVX2)指令相比,可提供全面的功能和更高的性能。
512位SIMD指令扩展的基础称为Intel AVX-512 Foundation指令,包括Intel AVX和Intel AVX2系列SIMD指令的扩展,但使用新的编码方案编码,支持512位矢量寄存器、64位模式下最多32个矢量寄存器以及使用opmask寄存器的条件处理。Intel处理器相关的特性包含但不限于:高级矩阵扩展(AMX)、ENQCMD/ENWCMDS指令和虚拟化支持、TSX挂起加载地址跟踪、线性地址转换、架构最后分支记录(LBRS)、非回写锁定禁用架构、总线锁定和VM通知功能、资源管理器技术、增强型硬件反馈接口(EHFI)、线性地址屏蔽(LAM)、基于Sapphire Rapids微架构的处理器的机器错误代码、IPI虚拟化等等。关于它们的具体描述可参阅Intel的说明文档:Intel Architecture Instruction Set Extensions and Future Feature。
Xeon E5-2600/4600的芯片架构如下:
2021年的Intel架构支持标量、向量、矩阵和空间的混合计算:

单个包中集成了混合计算集群:

新架构的基础组件如下,包含了各类高性能且节能的核心:
对于高效的x86核心而言,其具备高度可扩展的体系结构,以满足下一个计算十年的吞吐量效率需求:

专为吞吐量而设计,为现代多任务实现可伸缩的多线程性能。针对功率和密度高效吞吐量进行了优化,具有:
- 深度前端,按需长度解码。
- 具有许多执行端口的宽带后端。
- 针对最新晶体管技术的优化设计。

对于指令控制,带有按需指令长度解码器的大型指令缓存(64KB)加快了现代工作负载的速度,占用了大量代码。通过深度的分支历史和大结构尺寸精确预测分支。

双三宽乱序解码器,每个周期最多可解码6条指令,同时保持功率和延迟:

对于数据执行,五宽分配,八宽回收,256项乱序窗口发现数据并行性,17个执行端口执行数据并行。

数据执行涉及的硬件部件、数量和布局如下:

在内存子系统方面:
- 双重加载+双重存储。
- 高达4MB的L2缓存:四个核心之间共享L2,在17个延迟周期内具有64字节/周期带宽。
- 高级预取器:在所有缓存级别检测各种流。
- 深度缓冲(Deep buffering,注意不是Depth Buffer):支持64次未命中。
- 英特尔资源管理器(Resource Director)技术:使软件能够控制内核之间以及不同软件线程之间的公平性。

具备现代的指令级:
- 安全。
- 浮点乘法累加(FMA)指令,吞吐量为2倍。
- 添加关键指令以实现整数AI吞吐量(VNNI)。
- 宽矢量。指令集架构。
- 支持Intel VT-rp(虚拟化技术重定向保护)。
- 高级推测执行验证方法。
- Intel Control flow Enforcement Technology旨在提高防御深度。
- 支持具有AI扩展的高级矢量指令。
每个晶体管的功率和性能效率:
- 高度关注功能选择和设计实现成本,以最大限度地提高面积效率,从而实现核心数量的扩展。
- 每个指令的低切换能量可最大化受功率限制的吞吐量,是当今吞吐量驱动工作负载的关键。
- 在扩展性能范围的同时,降低了所有频率传输功率所需的工作电压。

处理器功率计算公式。
在延迟性能方面,ISO功率下提升40%以上的性能,在ISO性能下降低功率40%以上。
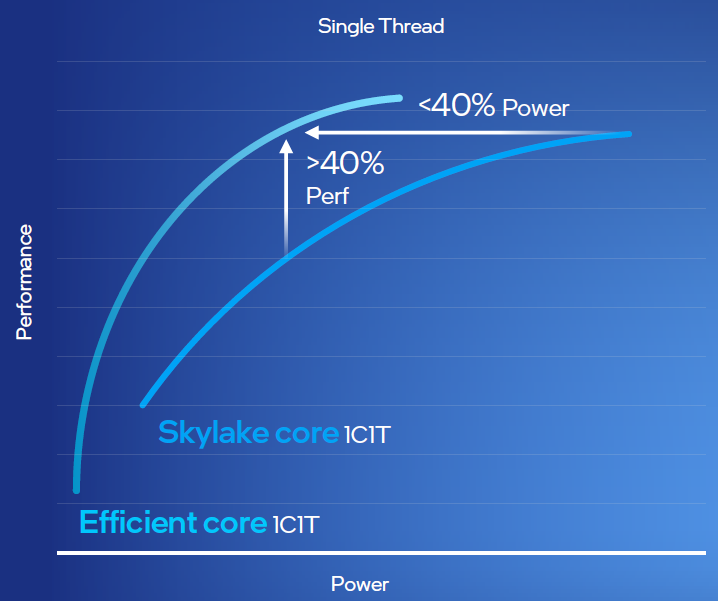
在吞吐量性能方面,提升80%的性能,降低80%的功率。

专为吞吐量而设计,为现代多任务实现可伸缩的多线程性能。针对功率和密度高效吞吐量进行了优化,具有:
- 深度前端,按需长度解码。
- 宽后端,具有许多执行端口。
- 针对最新晶体管技术的优化设计。
接下来阐述x86核心的性能。架构的目标是:
- 提供通用CPU性能的步进函数。
- 使用新功能改进Arch/uArch,以适应不断变化的工作负载模式的趋势。
- 在人工智能性能加速方面实现创新。
新的x86架构专为速度而设计,通过以下方式突破低延迟和单线程应用程序性能的限制:
- 更宽。
- 更深。
- 更智能。
使用大代码占用和大数据集加速工作负载,通过协处理器实现矩阵乘法的新型AI加速技术,用于细粒度电力预算管理的新型智能PM控制器。
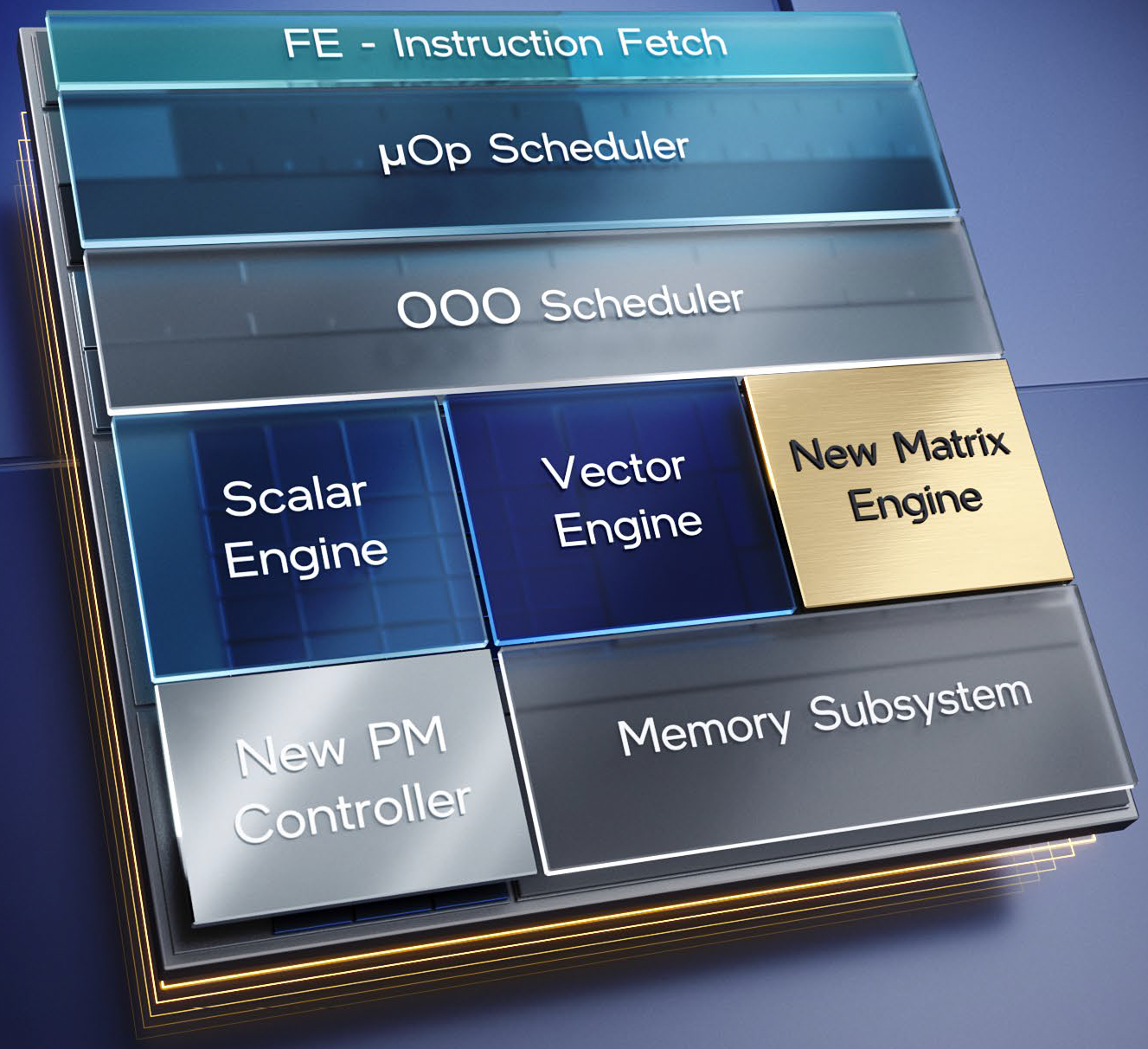
前端获取指令并将其解码到μμ级别的操作:
- 更大的代码:从128提升到256个4K iTLB,从16提升到32个2M/4M iTLB。
- 更宽:解码长度从16B提升到32B。
- 更智能:提高分支预测精度,更智能的代码预取机制。
- μμ队列:每线程条目从70提升到72,单个线程从70提升到144。
- μμ操作:2.25K提升到4K,提升命中率,提升前端带宽。

乱序引擎跟踪μμ操作依赖性并将准备好的μμ操作分派给执行单元:
- 更宽:分配宽度从5提到到6,执行端口从10提升到12。
- 更深:512项重新排序缓冲区和更大的调度器大小。
- 更智能:在重命名/分配阶段“执行”更多指令。

整数执行单元添加了第5代整数执行端口/ALU,所有5个端口上的1周期LEA也用于算术计算:

向量运算单元具有新的快速加法器(FADD):节能、低延迟,以及FMA单元支持FP16数据类型:FP16添加到Intel AVX512,包括复数支持。

L1缓存和内存子系统的特性有:
- 更宽:加载端口从2提升到3:3x256 bit的加载,2x512 bit的加载。
- 更深:更深入的加载缓冲区和存储缓冲区暴露了更多的内存并行性。
- 更智能:降低有效负载延迟,更快的内存消除分支。
- 更大数据:DTLB(数据快表)从64提升到96,L1数据缓存从12提升到16且具有增强型预取器,页面遍历器(page walker)从2提升到4。
L2缓存和内存子系统的特性有:
- 更大:1.25M(客户端)或2M(数据中心)。
- 更快:最大需求未命中从32提升到48。
- 更智能:基于L2缓存模式的多路径预取器,基于反馈的预取限制(throttling),全线写入预测带宽优化以减少DRAM读取。
通用性能与第11代Intel Core,ISO频率下性能提高19%:

英特尔高级矩阵扩展(英特尔AMX),分块矩阵乘法加速器——数据中心,VNNI从256 int8提升至AMX的2048 int8,提升了8倍的操作、时钟周期、核心。

AMX架构有两个组件:
- 分块(Tile):
- 新的可扩展2D寄存器文件——8个新寄存器,每个1Kb:T0-T7。
- 寄存器文件支持基本数据运算符——加载/存储、清除、设置为常量等。
- 分块声明状态并由XSAVE体系结构管理操作系统。
- TMUL:
- 矩阵乘法指令集,TILE上的第一个运算符。
- MAC计算网格计算数据的“分块”。
- TMUL使用三个分块寄存器(
T2=+T1*T0)执行矩阵加法乘法(C=+A*C)。 - TMUL要求分块已被呈现。
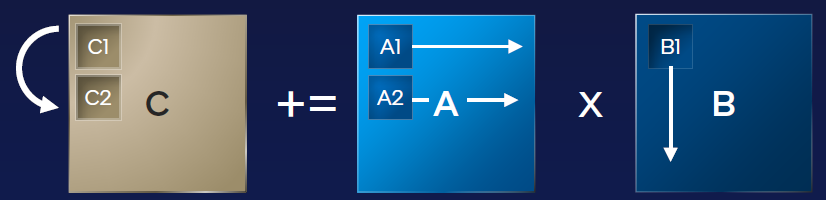
英特尔高级矩阵扩展(英特尔AMX)架构如下:

x86核心是下一个计算十年CPU架构性能的阶梯函数,在高功率效率下显著提高IPC,具备更宽、更深、更智能的特点。更好地支持大型数据集和大型代码占用应用程序,机器学习技术:Intel AMX的分块乘法,增强的电源管理可提高频率和功率。所有这些都采用量身定制的可扩展架构,可为从笔记本电脑到台式机再到数据中心的全系列产品提供服务。
Intel标量架构的路线图如下:

单线程/延迟和多线程性能/吞吐量的二维关系如下:
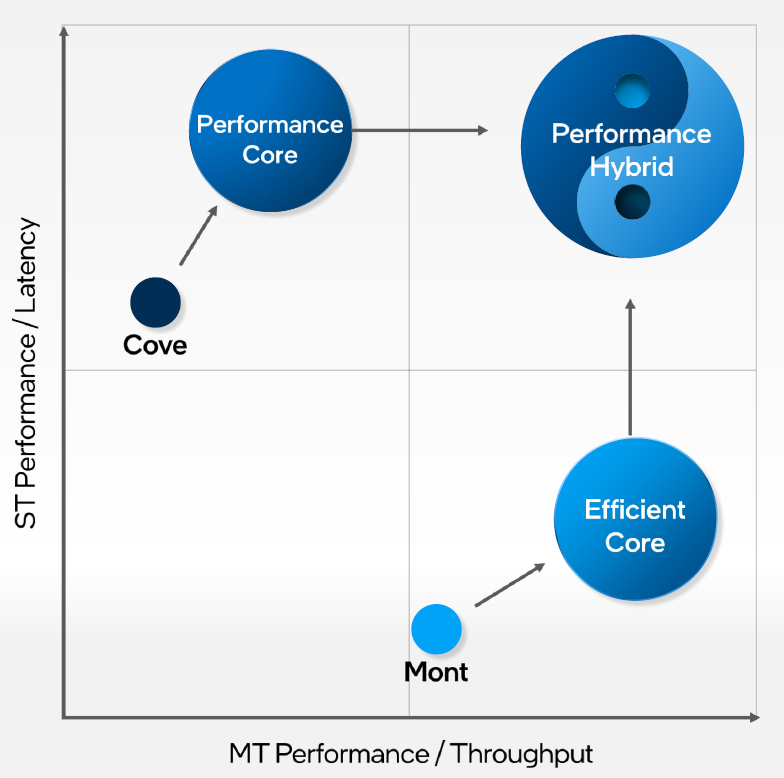
Intel线程管理器(Thread Director):
- 调度的目标是:软件透明、实时自适应、从移动端到桌面的可扩展性。
- 直接内置于核心的智能,基于热设计点、运行条件和功率设置动态调整指导,无需任何用户输入。
- 向操作系统提供运行时反馈,以便为任何工作负载或工作流做出最佳调度决策。
- 以纳秒级精度监控每个线程的运行时指令组合以及每个内核的状态。
Thread Director调度案例如下:

1:在P核上调度的优先任务。
2:在E核上调度的后台任务。
3:新的AI线程就绪。
4:AI线程优先调度于P核。
5-7:自旋等待从P核移动到E核。
接下来介绍多核架构Alder Lake。Alder Lake的特点是:
- 单一可扩展SoC架构。所有客户端段,从9W至125W,基于Intel 7进程构建。
- 全新核心设计。与Intel线程控制器的性能混合。
- 业界领先的内存和I/O。支持DDR5、PCIe Gen5、Thunderbolt 4、Wi-Fi 6E等。
可扩展的客户端架构:

架构积木:


Alder Lake的核心和缓存数据如下:
- 高达16核,8性能核,8效率核。
- 高达24线程,每个P核2个线程,每个E核1个线程。
- 高达30M缓存,非包容性,LL缓存。
Alder Lake的内存引领行业向DDR5过渡,支持所有四种主要内存技术,动态电压频率缩放,增强的超频支持。

PCIe引领行业向PCIe Gen5过渡,与Gen4相比,带宽高达2倍,最高64GB/s,x16通道。
内部连线(Interconnect)的特点:
- 计算结构:高达1000 GB/s,动态延迟优化。
- I/O结构:高达64GB/s,实时、基于需求的带宽控制。
- 内存结构:高达204 GB/s,动态总线宽度和频率。
Intel的集成图形芯片XeXe HPG的Render Slice架构如下图,包含核心、采样器、光线追踪单元各4个,几何处理、光栅化、HiZ等各1个,像素后端2个:

XeXe HPG具有可扩展的图形引擎,包含8个Render Slice,其性能和功率关系如下:

基于XeXe HPC的GPU的计算构建块:

向量引擎和矩阵引擎的参数及所处的位置如下:

单个切片结构如下:

多个切片组成的栈(stack)如下:

当然多个栈还可以组成更大的结构。连接具有高度伸缩性,支持2点互联、4点互联、6点互联甚至8点和互联:
Sapphire Rappids是下一代Intel Xeon可扩展处理器,数据中心体系结构的新标准,专为微服务和AI工作负载设计,开创性的高级内存和IO转换。Intel Xeon的节点性能表现在标量性能、数据并行性能、缓存和内存子系统架构,以及套接字内/套接字间缩放等方面:

Intel Xeon的数据中心性能表现在整合和业务流程、性能一致性、弹性和高效的数据中心利用率、基础设施和框架开销等方面:

通过模块化架构,利用单片CPU的现有软件范例(如Ice Lake),提供可扩展、平衡的架构(如Sapphire Rapids):

Sapphire Rapids是多片、单CPU架构,每个线程都可以完全访问所有分块的缓存、内存、IO…在整个SoC中提供一致的低延迟和高横截面的带宽。Sapphire Rapids的SoC的物理架构如下:

Sapphire Rapids的关键构建块如下:
为数据中心构建的性能核心,主要微架构和IPC改进,改进了对大代码/数据占用的支持,高频自动/快速PM。

性能核心,DC工作负载和使用的架构改进:
- AI:英特尔高级矩阵扩展-AMX,用于推理和训练加速的平铺矩阵运算。
- 连接设备:加速器接口架构-AiA,用户级的高效调度、信令和同步。
- FP16:半精度,支持更高的吞吐量和更低的精度。
- 缓存管理:CLDEMOTE,主动放置缓存内容。
Sapphire Rapids加速引擎,通过无缝集成的加速引擎实现共模任务的卸载以提高核心的效率,原生调度、来自用户空间的信令和同步、加速器接口架构,核心与加速引擎之间的相干共享存储空间,可并发共享的进程、容器和VM。

Intel Data Streaming加速引擎优化流数据移动和转换操作,每个套接字最多4个实例,低延迟调用,无内存固定开销,DSA卸载后获得额外39%的CPU核心周期。
Intel Quick Assist Technology加速引擎加快加密和数据消除/压缩,高达400Gb/s对称加密,高达160Gb/s压缩+160Gb/s解压缩,融合操作,QAT卸载后增加98%的工作负载容量。
Sapphire Rapids的I/O高级特性:
- Compute ePressLink(CXL)1.1简介,数据中心中的加速器和内存扩展。
- 通过PCIe 5.0和连接扩展设备性能,通过Intel®Ultra Path Interconnect(UPI)2.0改进多插槽扩展。
- 最多4 x24 UPI链路以16 GT/s的速度运行,新的8S-4UPI性能优化拓扑,改进的DDIO和QoS功能。
Sapphire Rapids的内存和最后一级缓存:
- 增加的共享最后一级缓存(LLC),在所有核心中共享的最大容量超过100 MB LLC。
- 通过DDR 5内存提高带宽、安全性和可靠性,4个内存控制器,支持8个通道。
- Intel Optane永久内存300系列。
Sapphire Rapids具有高带宽内存:
- 与8通道DDR 5的基线Xeon SP相比,内存带宽显著提高。
- 增加容量和带宽,某些用途可以完全消除对DDR的需求。
- 2种模式:
- HBM扁平模式。带HBM和DRAM的扁平内存区域。
- HBM缓存模式。DRAM备份缓存。
Sapphire Rapids为弹性计算模型构建微服务,80%以上的新云原生和SaaS应用程序预计将作为微服务构建。其目标是:实现更高的吞吐量,同时满足延迟要求,并减少执行、监控和协调数千个微服务的基础架构开销;提高性能和服务质量,减少基础设施开销,更好的分布式通信。微服务性能的对比如下:

Ponte Vecchio具有:
- 新的验证方法。
- 新的SOC架构。
- 新的IP架构。
- 新内存体系结构。
- 新的I/O体系结构。
- 新的包装技术。
- 新的电力输送技术。
- 新的互连。
- 新的信号完整性技术。
- 新的可靠性方法。
- 新的软件。
Ponte Vecchio SoC拥有1000亿以上晶体管,47活动分块,5个进程节点。其内部结构图如下:

具有不同加速比的加速计算系统:

克服分离的CPU和GPU软件堆栈,囊括了CPU优化堆栈和GPU优化堆栈:

19.6 内存系统
到目前为止,我们已经将内存系统视为一个大的字节阵列,这种抽象对于设计指令集、学习汇编语言,甚至对于设计具有复杂流水线的基本处理器来说,都已经足够好了。然而,从实际角度来看,这种抽象需要进一步重新定义,以设计一个快速内存系统。在前面章节介绍的基础流水线中,假设访问数据和指令内存需要1个周期,在本章并不总是正确的。事实上,需要对内存系统进行重大优化,以接近1个周期的理想延迟,需要引入“缓存”和分层内存系统的概念,以解决具有大内存容量和低延迟的双重问题。
其次,到目前为止,一直假设只有一个程序在系统上运行,但大多数处理器通常在分时基础上运行多个程序,例如,如果有两个程序A和B,现代台式机或笔记本电脑通常会运行程序A几毫秒,执行程序B几毫秒,然后来回切换。事实上,系统运行着许多其他程序,比如网页浏览器、音频播放器和日历应用程序。一般来说,用户不会感知到任何中断,因为中断发生的时间尺度远低于人脑所能感知的时间尺度。例如,一个典型的视频每秒显示30次新图片,或者每隔33毫秒显示一张新图片。人脑通过将图片拼接在一起,产生一个平稳移动的物体的错觉。如果处理器在33毫秒之前完成处理视频序列中下一张图片的工作,那么它可以执行另一个程序的一部分。人脑将无法分辨差异。这里的重点是,在我们不知情的情况下,处理器与操作系统合作,在多个程序之间每秒切换多次。操作系统本身就是一个专门的程序,可以帮助处理器管理自己和其他程序。Windows和Linux是流行操作系统的示例。
我们需要内存系统中的特殊支持来支持多个程序,如果没有这种支持,那么多个程序会覆盖彼此的数据,这是不希望的行为。第二,我们一直假设拥有无限的内存,这也不是事实,我们拥有的内存量是零,而且它可能会被大型内存密集型程序耗尽。因此,我们应该有一个机制来继续运行这样大的程序,将引入虚拟内存的概念来解决这两个问题:运行多个程序和处理大型内存密集型程序。
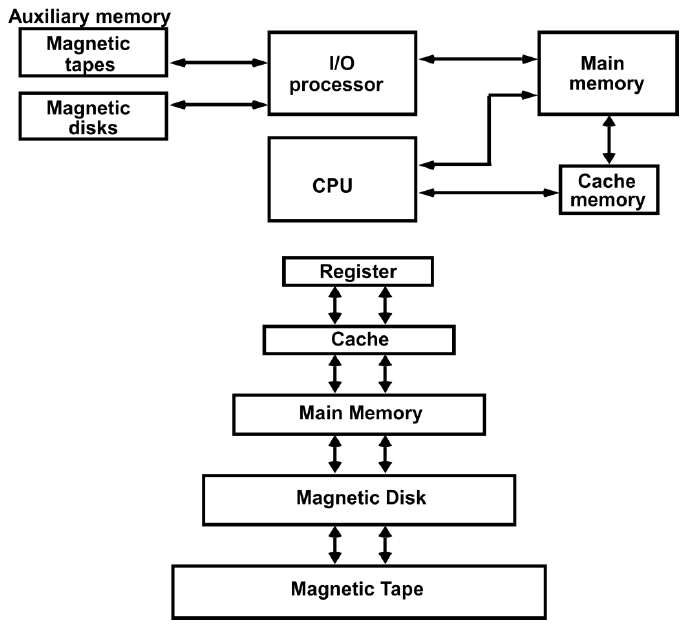
计算机系统中的内存层次结构。
如果根据内存系统的关键特性对其进行分类,那么计算机内存这一复杂的主题就更容易管理。其中最重要的列于下表。
表中的术语位置是指内存是计算机内部还是外部,内部内存通常等同于主内存,但也有其他形式的内部内存。处理器需要自己的局部存储器,以寄存器的形式,处理器的控制单元部分也可能需要其自己的内部存储器,缓存是内存的另一种形式。外部内存由外围存储设备(如磁盘和磁带)组成,处理器可以通过I/O控制器访问这些设备。
内存的一个明显特征是它的容量。对于内部内存,通常以字节(1字节=8位)或字表示,常见的字长为8、16和32位。外部内存容量通常以字节表示。
一个相关的概念是传输单位(unit of transfer)。对于内部内存,传输单位等于进出存储模块的电线数量,可能等于字长,但通常更大,例如64、128或256位。为了阐明这一点,请考虑内部内存的三个相关概念:
- 字(Word):内存组织的“自然”单位,字的大小通常等于用于表示整数的位数和指令长度。不幸的是,有很多例外,例如CRAY C90(一种老式CRAY超级计算机)具有64位的字长,但使用46位整数表示。Intel x86体系结构具有多种指令长度,以字节的倍数表示,字大小为32位。
- 可寻址单元(Addressable unit):在某些系统中,可寻址单元是字,但许多系统允许在字节级别寻址。在任何情况下,地址的位A长度与可寻址单元的数量N之间的关系是2A=N2A=N。
- 传输单位(Unit of transfer):对于主内存,是一次从内存中读出或写入的位数,传输单位不必等于字或可寻址单位。对于外部内存,数据通常以比字大得多的单位传输,这些单位被称为块。
内存类型的另一个区别是访问数据单元的方法,其中包括以下内容:
- 顺序存取:内存被组织成数据单元,称为记录,访问必须按照特定的线性顺序进行,存储的寻址信息用于分离记录并协助检索过程。使用共享读写机制,必须将其从当前位置移动到所需位置,传递和拒绝每个中间记录,因此访问任意记录的时间是高度可变的。
- 直接访问:与顺序访问一样,直接访问涉及共享的读写机制,但单个块或记录具有基于物理位置的唯一地址。访问是通过直接访问来实现的,以到达一般邻近位置,再加上顺序搜索、计数或等待到达最终位置。同样,访问时间是可变的。
- 随机访问:内存中的每个可寻址位置都有一个独特的物理连线寻址机制,访问给定位置的时间与先前访问的顺序无关,并且是恒定的。因此,可以随机选择任何位置,并直接寻址和访问。主内存和一些缓存系统是随机访问的。
- 关联(Associative):是一种随机存取类型的内存,使我们能够对一个字内的所需位位置进行比较,以获得指定的匹配,并同时对所有字进行比较。因此,一个字是基于其内容的一部分而不是其地址来检索的。与普通随机存取内存一样,每个位置都有自己的寻址机制,检索时间与位置或先前的存取模式无关。高速缓存内存可以采用关联访问。
从用户的角度来看,内存的两个最重要的特性是容量和性能,性能涉及三个参数:
-
访问时间(延迟):对于随机存取内存,是执行读取或写入操作所需的时间,即从地址呈现到内存的那一刻到数据被存储或可供使用的那一瞬间的时间。对于非随机存取内存,存取时间是将读写机制定位在所需位置所需的时间。
-
内存周期时间:主要应用于随机存取内存,包括存取时间加上第二次存取开始前所需的任何额外时间。如果信号线上的瞬变消失(die out)或数据被破坏性读取,则可能需要额外的时间来重新生成数据。注意,内存周期时间与系统总线有关,与处理器无关。
-
传输速率:是数据可以传输到内存单元或从内存单元传输出去的速率。对于随机-访问内存,它等于1/(循环时间),对于非随机存取内存,以下关系成立:
Tn=TA+nRTn=TA+nR
其中:
- TnTn=读取或写入n位的平均时间。
- TATA=平均访问时间。
- nn=位数。
- RR=传输速率,单位为比特/秒(bps)。
已经阐述了各种物理类型的内存。当今最常见的是半导体内存、用于磁盘和磁带的磁表面存储器、光学和磁光存储器。
19.6.1 内存系统概论
19.6.1.1 快速内存系统需求
现在看看构建快速存储系统的技术要求。我们可以用四种基本电路设计内存元件:锁存器、SRAM单元、CAM单元和DRAM单元。这里有一个权衡,锁存器和SRAM单元比DRAM或CAM单元快得多,但与DRAM单元相比,锁存器、CAM或SRAM单元的面积要大一个数量级,而且功耗也要大得多。锁存器被设计为在负时钟边沿读取和读出数据,是一个快速电路,可以在时钟周期的一小部分内存储和检索数据。另一方面,SRAM单元通常被设计为与解码器和感测放大器一起用作SRAM单元的大阵列的一部分。由于这种额外的开销,SRAM单元通常比典型的边缘触发锁存器慢。相比之下,CAM单元最适合与内容相关的存储器,而DRAM单元最适合容量非常大的存储器。
现在,管线假定内存访问需要1个周期,为了满足这一要求,需要用锁存器或SRAM单元的小阵列构建整个内存。下表显示了截至2012年的典型锁存器、SRAM单元和DRAM单元的尺寸。
| 单元类型 | 面积 | 典型延迟 |
|---|---|---|
| 主从D触发器 | 0.8 μm2μm2 | 一个时钟周期内的分数 |
| SRAM单元 | 0.08 μm2μm2 | 1-5时钟周期 |
| DRAM单元 | 0.005 μm2μm2 | 50-200时钟周期 |
典型的锁存器(主从D触发器)比SRAM单元大10倍,而SRAM单元又比DRAM单元大约16倍,意味着,给定一定量的硅,如果使用DRAM单元,可以保存160倍的数据,但也慢200倍(如果考虑DRAM单元的代表性阵列)。显然,容量和速度之间存在权衡,但我们实际上需要两者。
让我们首先考虑存储能力问题。由于技术和可制造性方面的若干限制,截至2012年,无法制造面积超过400-500平方毫米的芯片,因此在芯片上拥有的内存总量是有限的,但用专门包含存储单元的附加芯片来补充可用存储器的数量是完全可能的。请记住,片外存储器速度较慢,处理器访问此类内存模块需要数十个周期。为了实现1周期内存访问的目标,我们需要在大多数时间使用相对更快的片上内存,但选择也是有限的,无法承受只由锁存器组成的存储系统。对于大量程序,无法将所有数据存储在内存中,例如,现代程序通常需要数百兆字节的内存,一些大型科学程序需要千兆字节的内存。其次,由于技术限制,很难在同一芯片上集成大型DRAM阵列和处理器,设计者不得不将大型SRAM阵列用于片上存储器。如上表所示,SRAM单元(阵列)比DRAM单元(数组)大得多,因此容量小得多。
但是,延迟要求存在冲突。假设我们决定最大化存储,并使内存完全由DRAM单元组成,访问DRAM的等待时间为100个周期。如果假设三分之一的指令是内存指令,那么完美的5阶段处理器管线的有效CPI计算为:1+1/3×(100−1)=341+1/3×(100−1)=34。需要注意的是,CPI增加了34倍,完全不能接受!
因此,我们需要在延迟和存储之间进行公平的权衡,希望存储尽可能多的数据,但不能以非常低的IPC为代价。不幸的是,如果假设内存访问是完全随机的,那么就没有办法摆脱这种情况。如果内存访问中存在某种模式,那么会做得更好,这样就可以做到两全其美:高存储容量和低延迟。
19.6.1.2 内存访问模式
内存访问模式有两种:
- 时间局部性(Temporal Locality)。如果某个资源在某个时间点被访问,那么很可能会在很短的时间间隔内再次被访问。
- 空间局部性(Spatial Locality)。如果某个资源在某个时间点被访问,那么很可能在不久的将来也会访问类似的资源。
内存访问中是否存在时间和空间局部性?
如果存在一定程度的时间和空间局部性,那么可以进行一些关键的优化,以帮助解决大内存需求和低延迟这两个问题。在计算机架构中,通常利用诸如时间和空间局部性之类的特性来解决问题。
19.6.1.3 指令访问的时空局部性
解决这一问题的标准方法是在一组具有代表性的项目中测量和描述局部性,如SPEC基准。可将将内存访问分为两大类:指令和数据,指令访问更容易进行非正式分析,因此先来看看它。
一个典型的程序有赋值语句、分支语句(if、else)和循环,大型程序中的大部分代码都是循环的一部分或一些通用代码。计算机架构中有一个标准的经验法则,它表明90%的代码运行10%的时间,10%的代码运行90%的时间。对于一个文字处理器,处理用户输入并在屏幕上显示结果的代码比显示帮助屏幕的代码运行得更频繁。同样,对于科学应用,大部分时间都花在程序中的几个循环中。事实上,对于大多数常见的应用程序,我们使用这种模式。因此,计算机架构师得出结论,指令访问的时间局部性适用于绝大多数程序。
现在考虑指令访问的空间局部性。如果没有分支语句,那么下一个程序计数器是当前程序计数器加上ISA的4个字节(常规ISA而言)。如果两个访问的内存地址彼此接近,我们认为这两个访问“相似”,很明显,此处具有空间局部性。程序中的大多数指令是非分支的,空间局部性成立。此外,在大多数程序中,分支的一个很好的模式是,分支目标实际上并不远。如果我们考虑一个简单的If-else语句或for循环,那么分支目标的距离等于循环的长度或语句的If部分。在大多数程序中,通常是10到100条指令长,而不是数千条指令长。因此,架构师得出结论,指令内存访问也表现出大量的空间局部性。
数据访问的情况稍微复杂一些,但差别不大。对于数据访问,我们也倾向于重用相同的数据,并访问类似的数据项。
19.6.1.4 时间局部性特征
让我们描述一种称为堆栈距离(stack distance)方法的方法,以表征程序中的时间局部性。
我们维护一个访问的数据地址堆栈。对于每个内存指令(加载/存储),在堆栈中搜索相应的地址,找到条目的位置(如果找到)称为“堆栈距离”。距离是从堆栈顶部开始测量的,堆栈顶部的距离等于零,而第100个条目的堆栈距离等于99。每当我们检测到堆栈中的条目时,我们就会将其移除,并将其推到堆栈顶部。
如果找不到内存地址,那么创建一个新条目并将其推到堆栈的顶部。通常,堆栈的深度是有界的,它的长度为L。如果由于添加了一个新条目,堆栈中的条目数超过了L,那么需要删除堆栈底部的条目。其次,在添加新条目时,堆栈距离没有定义。注意,由于我们考虑有界堆栈,因此无法区分新条目和堆栈中的条目,但必须将其删除,因为它位于堆栈的底部。因此,在这种情况下,我们将堆栈距离设为等于L(以堆栈深度为界)。
请注意,堆栈距离的概念为我们提供了时间局部性的指示。如果访问具有高的时间局部性,那么平均堆栈距离预计会更低。相反,如果内存访问具有低的时间局部性,那么平均堆栈距离将很高,因此可以使用堆栈距离的分布来衡量程序中的时间局部性。
我们可以使用SPEC2006基准测试Perlbench进行了一个简单的实验,它运行不同的Perl程序,我们维护计数器以跟踪堆栈距离。第一百万次内存访问是一个预热期(warm-up period),在此期间,堆栈保持不变,但计数器不递增。对于接下来的一百万次内存访问,堆栈将保持不变,计数器也将递增。下图显示了堆栈距离的直方图,堆栈的大小限制为1000个条目,足以捕获绝大多数的内存访问。

堆栈距离分布图。
以上可知,大多数访问具有非常低的堆栈距离,0-9之间的堆栈距离是最常见的值,大约27%的所有访问都在这个箱中。事实上,超过三分之二的内存访问的堆栈距离小于100。超过100,分布逐渐减少,但仍然相当稳定。堆栈距离的分布通常被称为遵循重尾分布(heavy tailed distribution),意味着分布严重偏向于较小的堆栈距离,但大的堆栈距离并不少见。对于大的堆栈距离,分布的尾部仍然是非零的,上图显示了类似的行为。
研究人员试图使用对数正态分布来近似堆栈距离:
f(x)=1xσ√2πe−(ln(x)−μ)22σ2f(x)=1xσ2πe−(ln(x)−μ)22σ2
19.6.1.5 空间局部性特征
关于堆栈距离,我们定义了术语地址距离,第i个地址距离是第i次内存访问的存储器地址与最后K次内存访问集合中最近的地址之间的差,内存访问可以是加载或存储。以这种方式消除不良地址距离有一个直观的原因,程序通常在同一时间间隔内访问主内存的不同区域,例如,对数组执行操作,访问数组项,然后访问一些常量,执行操作,保存结果,然后使用For循环移动到下一个数组条目。这里显然存在空间局部性,即循环访问的连续迭代接近数组中的地址。但为了量化它,需要搜索最近K次访问中最近的访问(以内存地址表示),其中K是封闭循环每次迭代中的内存访问数。在这种情况下,地址距离被证明是一个小值,并且表示高空间局部性。但K需要精心选择,不应该太小,也不应该太大,根据经验,K=10对于一组大型程序来说是一个合适的值。
总之,如果平均地址距离很小,意味着程序具有较高的空间局部性,该程序倾向于在相同的时间间隔内以高可能性访问附近的内存地址。相反,如果地址距离很高,则访问彼此相距很远,程序不会表现出空间局部性。
使用SPEC2006基准Perlbench重复前面描述的实验,为前100万次访问提供了地址距离分布,见下图。
四分之一以上的访问的地址距离在-5和+5之间,三分之二以上的访问地址距离在-25和+25之间。超过±50±50,地址距离分布逐渐减小。从经验上看,这种分布也具有重尾性质。
19.6.1.6 利用时空局部性
前面小节展示了示例程序的堆栈和地址距离分布。用户在日常生活中使用的数千个程序也进行了类似的实验,包括计算机游戏、文字处理器、数据库、电子表格应用程序、天气模拟程序、金融应用程序和在移动计算机上运行的软件应用程序。几乎所有这些都表现出非常高的时间和空间局部性,换句话说,时间和空间的局部性是人类的基本特征,无论我们做什么(如拿取书本或编写程序)都会保持不变。请注意,这些只是经验观察,依然可以编写一个不显示任何形式的时间和空间局部性的程序,在商业程序中也可以找到不显示这些特征的代码区域。但这些是例外,不是常态。我们需要为常规而不是特例设计计算机系统,这就是我们如何提高大多数用户期望运行的程序的性能。
从现在起,将时间和空间的局部性视为理所当然,看看可以做些什么来提高内存系统的性能,而不影响存储容量。让我们先看看时间局部性。
利用时间局部性:分层内存系统
我们可以为内存设计一个存储位置,称之为缓存,缓存中的每个条目在概念上都包含两个字段:内存地址和值,并定义一个缓存层次结构,如下图所示。
内存层次。
主内存(物理内存)是一个大型DRAM阵列,包含处理器使用的所有内存位置的值。
L1缓存通常是一个小型SRAM阵列(8 - 64KB),L2缓存是一个更大的SRAM阵列(128KB - 4 MB)。一些处理器(如Intel Sandybridge处理器)有另一级缓存,称为L3缓存(4MB+)。在L2/L3高速缓存下面,有一个包含所有内存位置的大型DRAM阵列,被称为主内存或物理内存。在L1缓存中维护L2缓存的值子集更容易,以此类推,称为具有包含式缓存(inclusive cache)的系统。因此,对于包含性缓存层次结构,我们有: values (L1)⊂ values (L2)⊂ values ( main memory ) values (L1)⊂ values (L2)⊂ values ( main memory )。或者,我们可以使用独占缓存(exclusive cache),其中较高级别的缓存不一定包含较低级别缓存中的值子集。到目前为止,所有处理器都普遍使用非独占缓存,因为其设计的简单性、简单性和一些微妙的正确性问题。然而,截至2012年,通用处理器的实用性尚未确定。
第n级缓存中包含的一组存储器值是第(n+1)级缓存中所有值的子集的内存系统称为包含式缓存(inclusive cache)层次结构。不遵循严格包含的内存系统称为独占缓存(exclusive cache)层次结构。
现在再次查看上图所示的缓存层次结构。由于L1缓存较小,所以访问速度更快,访问时间通常为1-2个周期。L2缓存更大,通常需要5-15个周期才能访问。主内存由于其大尺寸和使用DRAM单元,速度要慢得多,访问时间通常非常高,在100-300个周期之间。内存访问协议类似于作者访问书籍的方式。
内存访问协议如下。每当有内存访问(加载或存储)时,处理器都会首先检查一级缓存。请注意,缓存中的每个条目在概念上都包含内存地址和值。如果数据项存在于一级缓存中,则缓存命中(cache hit),否则缓存未命中(cache miss)。如果存在缓存命中,并且内存请求是读取,那么只需将值返回给处理器,如果内存请求是写入,则处理器将新值写入缓存条目。然后,它可以将更改传播到较低级别,或恢复处理。后面章节会讨论不同的写入策略和执行缓存写入的不同方法。但是,如果存在缓存未命中,则需要进一步处理。
缓存命中(cache hit):当缓存中存在内存位置时,该事件称为缓存命中。
缓存未命中(cache miss):当缓存中不存在内存位置时,该事件称为缓存未命中。
在一级缓存未命中的情况下,处理器需要访问二级缓存并搜索数据项。如果找到项目(缓存命中),则协议与一级缓存相同,由于本文考虑了包含性缓存,所以有必要将数据项提取到一级缓存。如果存在L2未命中,则需要访问较低级别,较低级别可以是另一个L3缓存,也可以是主内存。在最低级别(即主内存),我们保证不会发生未命中,因为我们假设主内存包含所有内存位置的条目。
处理器使用分层内存系统来最大化性能,而不是使用单一的平面存储系统,分层存储系统旨在提供具有理想单周期延迟的大内存的错觉。
举个具体的例子,查找以下配置的平均内存访问延迟。
| 级别 | 未命中率(%) | 延迟 |
|---|---|---|
| L1 | 10 | 1 |
| L2 | 10 | 10 |
| 主内存 | 0 | 100 |
内存系统配置1。
| 级别 | 未命中率(%) | 延迟 |
|---|---|---|
| 主内存 | 0 | 100 |
内存系统配置2。
答案:让我们先考虑配置1,90%的访问都发生在一级缓存中,这些命中的内存访问时间是1个周期。请注意,即使在一级缓存中未命中的访问仍会导致1个周期的延迟,因为我们不知道访问是否会在缓存中命中或未命中。随后,90%到二级缓存的访问都会在缓存中命中,它们会产生10个周期的延迟。最后,剩余的访问(1%)命中了主内存,并导致了额外的延迟。因此,平均内存存取时间(T)为:
T=1+0.1×(10+0.1×100)=1+1+1=3T=1+0.1×(10+0.1×100)=1+1+1=3
因此,配置1的分层内存系统的平均内存延迟是3个周期。
配置2是一个平面层次结构,使用主内存进行所有访问,平均内存访问时间为100个周期。因此,使用分层内存系统可以将速度提高100/3=33.3100/3=33.3倍。
上面的示例表明,使用分层内存系统的性能增益是具有单层分层结构的平面内存系统的33.33倍,性能改进是不同缓存的命中率及其延迟的函数。此外,缓存的命中率取决于程序的堆栈距离分布和缓存管理策略,同样,缓存访问延迟取决于缓存制造技术、缓存设计和缓存管理方案。在过去二十年中,优化缓存访问一直是计算机体系结构研究中的一个非常重要的主题,研究人员在这方面发表了数千篇论文。本文只讨论其中的一些基本机制。
利用空间局部性:缓存块
现在考虑空间局部性,上上图揭示了大多数访问的地址距离在±25±25字节内。地址距离分布表明,如果将一组内存位置分组到一个块中,并从较低级别一次性获取,那么可以增加缓存命中数,因为访问中存在高度的空间局部性。
因此,几乎所有处理器都创建连续地址块,缓存将每个块视为一个原子单元。一次从较低级别获取整个块,如果需要,也会从缓存中逐出整个块。缓存块也称为缓存行,一个典型的缓存块或一行是32-128字节长,为了便于寻址,它的大小必须是2的严格幂。
缓存块(cache block)或缓存行(cache line)是一组连续的内存位置,被视为缓存中的原子数据单元。
因此,我们需要稍微重新定义缓存条目(cache entry)的概念,没有为每个内存地址创建一个条目,而是为每个缓存行创建一个单独的条目。请注意,本文将同义地使用术语缓存行和块,还要注意,L1高速缓存和L2高速缓存中不必具有相同的高速缓存行大小,它们可以不同。然而,为了保持高速缓存的包容性,并最小化额外的内存访问,通常需要在L2使用与L1相同或更大的块大小。
迄今所学到的要点:
- 时间和空间局部性是大多数人类行为固有的特性,它们同样适用于阅读书籍和编写计算机程序。
- 时间局部性可以由堆栈距离量化,空间局部性可以通过地址距离量化。
- 我们需要设计内存系统,以利用时间和空间的局部性。
- 为了利用时间局部性,我们使用由一组缓存组成的分层内存系统。L1高速缓存通常是一种小而快的结构,旨在快速满足大多数存储器访问。较低级别的缓存存储的数据量较大,访问频率较低,访问时间较长。
- 为了利用空间局部性,我们将连续的存储器位置集合分组为块(也称为行),块被视为缓存中的原子数据单元。
前面已经定性地研究了缓存的需求,后面将继续讨论缓存的设计。
19.6.2 缓存
19.6.2.1 缓存综述
高速缓存的设计是为了将昂贵的高速内存的内存访问时间与较便宜的低速内存的大内存大小相结合,如下图a所示。下图b描述了多级缓存的使用,L2高速缓存比L1高速缓存慢且通常更大,而L3高速缓存比L2高速缓存慢并且通常更大。

下图描述了缓存/主内存系统的结构。主内存由多达2n2n个可寻址字组成,每个字具有唯一的n位地址。出于映射的目的,该内存被认为由多个固定长度的块组成,每个块包含K个字,也就是说,主内存中有M=2n/KM=2n/K个块。缓存由m个块组成,称为行(line),每行包含K个字,加上几个位的标记。每一行还包括控制位(未示出),例如指示该行自从被加载到缓存中以来是否已被修改的位,行的长度(不包括标记和控制位)是行大小。
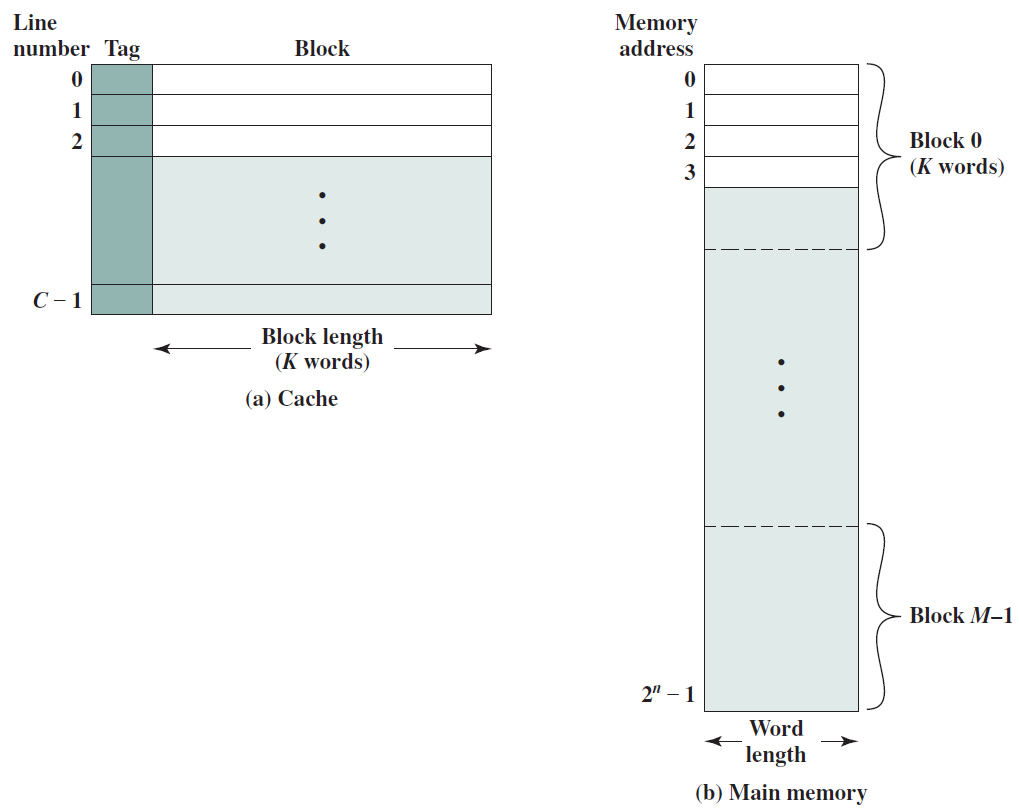
下图说明了读取操作。处理器生成要读取的字的读取地址(RA),如果该单词包含在缓存中,则将其传递给处理器。否则,包含该字的块被加载到缓存中,并且该字被传递到处理器。图中显示了并行发生的最后两个操作,并反映了下下图所示的当代缓存组织的典型。在这种组织中,缓存通过数据、控制和地址线连接到处理器。数据和地址线还连接到数据和地址缓冲区,这些缓冲区连接到系统总线,从该总线可以访问主内存。当缓存命中时,数据和地址缓冲区将被禁用,并且只有处理器和缓存之间的通信,没有系统总线通信。当发生缓存未命中时,所需的地址被加载到系统总线上,数据通过数据缓冲区返回到缓存和处理器。在其他组织中,缓存物理地插入处理器和主内存之间,用于所有数据、地址和控制线。在后一种情况下,对于缓存未命中,所需的字首先被读取到缓存中,然后从缓存传输到处理器。
缓存读取操作。

典型的缓存组织。
当使用虚拟地址时,系统设计者可以选择在处理器和MMU之间或MMU和主内存之间放置缓存(下图)。逻辑缓存(也称为虚拟缓存)使用虚拟地址存储数据,处理器直接访问缓存,而不经过MMU,物理缓存则使用主内存物理地址存储数据。
下图a显示了缓存的直接映射方式,其中前m个主内存块的映射,每个主内存块映射到缓存的一个唯一行中,接下来的m个主内存块以相同的方式映射到缓存中。
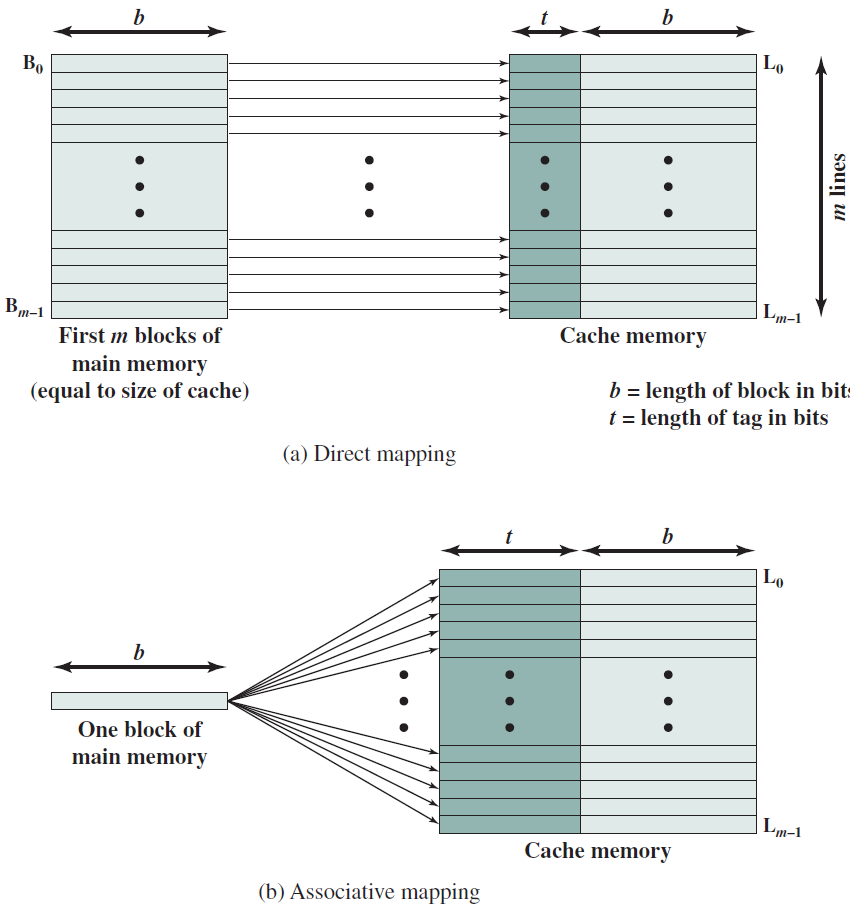
缓存的直接和关联映射。

直接映射缓存组织。

完全的关联映射缓存组织。
此处之外,还存在K路(如2、4、8、16路)的缓存映射方式,参见下图。
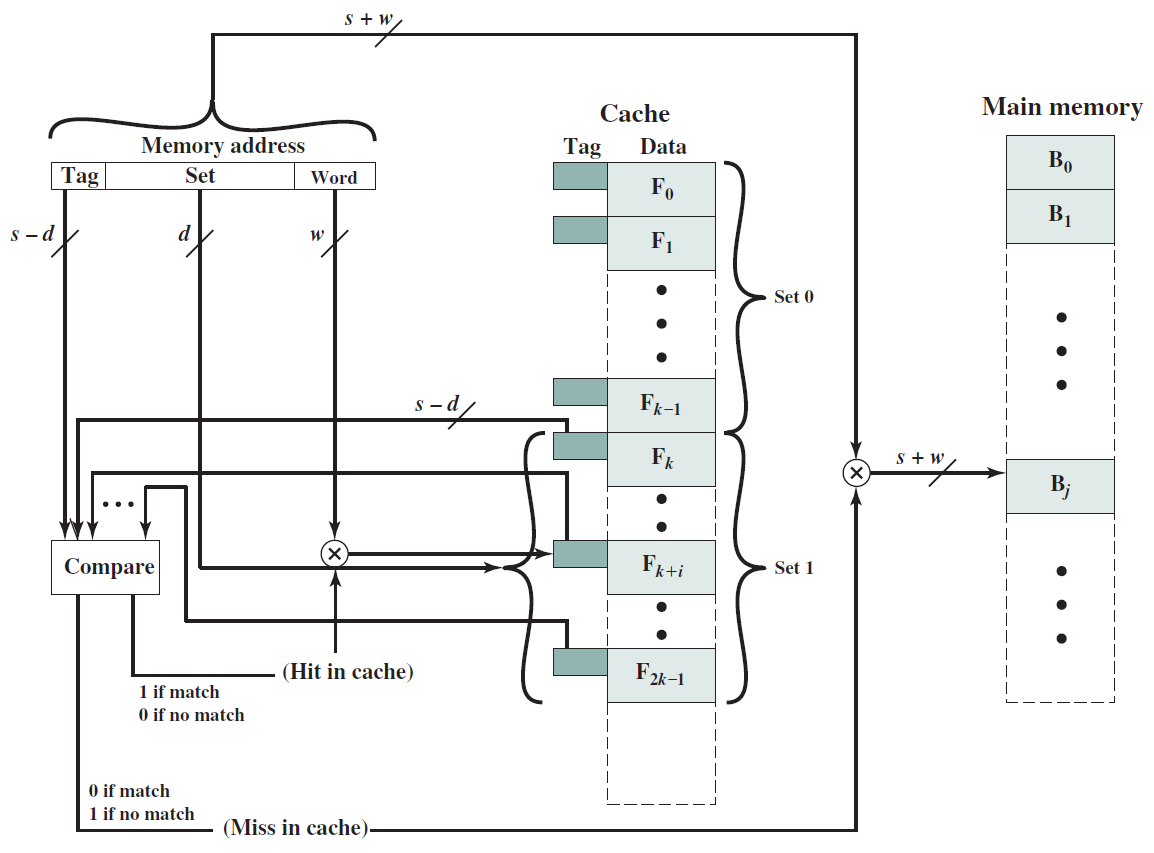
k路集关联缓存组织。
不同映射方式随着缓存大小改变关联性的曲线如下:

下图是曾经风靡一时具有代表性的奔腾4的结构图,清晰地展示了缓存的结构:
19.6.2.2 基本缓存操作
让我们将缓存视为一个黑盒子,如下图所示。在加载操作的情况下,输入是内存地址,如果缓存命中,输出是内存位置的值。我们设想缓存有一个状态行,指示请求是命中还是未命中。如果操作是存储,则缓存接受两个输入:内存地址和值。如果缓存命中,则缓存将值存储在与内存位置相对应的条目中,否则,表示缓存未命中。
作为黑盒子的缓存。
现在看看实现这个黑盒子的方法,将使用SRAM阵列作为构建块。
为了启发设计,考虑一个例子,有一个块大小为64字节的32位机器,在这台机器中,有226226个块。一级缓存的大小为8 KB,包含128个块。因此,可以在任何时间点将一级缓存视为整个内存地址空间的非常小的子集,最多包含226226个块中的128个。为了确定一级缓存中是否存在给定的块,需要查看128个条目中是否有任何一个包含该块。
假设一级缓存是内存层次结构的一部分,内存层次结构作为一个整体支持两个基本请求:读和写。然而,在缓存级别需要许多基本操作来实现这两个高级操作。
类似于内存地址,将块地址定义为内存地址的26个MSB位。第一个问题是判断缓存中是否存在具有给定块地址的块,需要执行一个查找(lookup)操作。如果块存在于缓存中(即缓存命中),则返回指向该块的指针,需要两个基本操作来服务请求,即数据读取(data read)和数据写入(data write)——读取或写入块的内容,并需要指向块的指针作为参数。
如果有缓存未命中,那么需要从内存层次结构的较低级别获取块并将其插入缓存。从内存层次结构的较低级别获取块并将其插入缓存的过程称为填充(fill)操作,填充操作是一个复杂的操作,并使用许多原子子操作。需要首先向较低级别的缓存发送加载请求以获取块,然后插入L1缓存。
插入过程也是一个复杂的过程。首先需要检查在一组给定的块中是否有空间插入一个新块,如果有足够的空间,那么可以使用插入(insert)操作填充其中一个条目。但是,如果要在缓存中插入块的所有位置都已经被占用,那么需要从缓存中移除一个已经存在的块。因此,需要调用一个替换(replace)操作来结束需要收回的缓存块。一旦找到了合适的替换候选块,需要使用逐出(evict)操作将其从缓存中逐出。
总之,实现缓存广泛地需要这些基本操作:查找、数据读取、数据写入、插入、替换和逐出。填充操作只是内存层次结构不同级别的查找、插入和替换操作的序列,同样,读取操作主要是查找操作,或者是查找和填充操作的组合。
19.6.2.3 缓存查找和缓存设计
假设为32位系统设计一个块大小为64字节的8KB缓存。为了进行高效的高速缓存查找,需要找到一种高效的方法来查找高速缓存中128个条目中是否存在26位块地址。存在两个问题:第一个问题是快速找到给定的条目,第二个问题是执行读/写操作。与其使用单个SRAM阵列来解决这两个问题,不如将其拆分为两个阵列,如下图所示。

缓存结构。
完全关联(FA)缓存
在典型的设计中,缓存条目保存在两个基于SRAM的阵列中,一个称为标记阵列的SRAM阵列包含与块地址有关的信息,另一个称称为数据阵列的SRRAM阵列包含块的数据。标记数组包含唯一标识块的标记,标记通常是块地址的一部分,并取决于缓存的类型。除了标签和数据阵列之外,还有一个专用的高速缓存控制器,用于执行高速缓存访问算法。
首先考虑一种非常简单的定位块的方法。我们可以同时检查缓存中128个条目中的每一个,以查看块地址是否等于缓存条目中的块地址。此缓存称为完全关联缓存(fully associative cache)或内容可寻址缓存(content addressable cache),“完全关联”表示给定块可以与缓存中的任何条目关联。
因此,全关联(FA)缓存中的每个缓存条目都需要包含两个字段:标签(tag)和数据(data)。在这种情况下,可以将标记设置为等于块地址,由于块地址对于每个块都是唯一的,因此它适合标记的定义。块数据指的是块的内容(在这种情况中为64字节)在我们的示例中,块地址需要26位,块数据需要64字节。搜索操作需要跨越整个缓存,一旦找到条目,我们需要读取数据或写入新值。
先看看标签数组。在这种情况下,每个标签都等于26位块地址,内存请求到达缓存后,第一步是通过提取26个最重要的位来计算标签,然后,需要使用一组比较器将提取的标签与标签数组中的每个条目进行匹配。如果没有匹配,可以声明缓存未命中并进一步处理,如果有缓存命中,需要使用与标记匹配的条目编号来访问数据条目,例如,在包含128个条目的8KB缓存中,标签数组中的第53个条目可能与标签匹配。在这种情况下,高速缓存控制器需要在读取访问的情况下从数据阵列中取出第53个条目,或者在写入访问的情况中写入第53个条目的。
有两种方法可以在完全关联缓存中实现标记数组,或者可以将其设计为一个普通的SRAM阵列,其中缓存控制器迭代每个条目,并将其与给定的标记进行比较,或者可以使用每行都有比较器的CAM阵列。它们可以将标签的值与存储在行中的数据进行比较,并根据比较结果生成输出(1或0)。CAM阵列通常使用编码器来计算与结果匹配的行数,完全关联缓存的标记数组的CAM实现更为常见,主要是因为顺序迭代数组非常耗时。
下图说明了这一概念。通过将对应的字线设置为1来启用CAM阵列的每一行,随后,CAM单元中的嵌入式比较器将每一行的内容与标签进行比较,并生成输出。我们使用OR门来确定是否有任何输出等于1,如果有任何输出为1,则表示缓存命中,否则表示缓存未命中。这些输出线中的每一条还连接到编码器,该编码器生成匹配行的索引,我们使用此索引访问数据数组并读取块的数据。在写入的情况下,我们写入块,而不是读取它。
完全关联缓存。
全关联缓存对于小型结构(通常为2-32)条目非常有用,但不可能将CAM阵列用于更大的结构,比较和编码的面积和功率开销非常高。也不可能顺序地遍历标签阵列的SRAM实现的每个条目,非常耗时。因此,我们需要找到一种更好的方法来定位更大结构中的数据。
直接映射(DM)缓存
在完全关联的缓存中,可以将任何块存储在缓存中的任何位置。这个方案非常灵活,但是,当缓存有大量条目时,它不能使用,主要是因为面积和电源开销太大。我们不允许将块存储在缓存中的任何位置,而是只为给定块指定一个固定位置。可以按如下方式进行。
在示例中,有一个8 KB的缓存,包含128个条目,不妨限制64字节块在缓存中的位置。对于每个块,在标记数组中指定一个唯一的位置,在该位置可以存储与其地址对应的标记,可以生成这样一个独特的位置,如下所示。让我们考虑块a的地址和缓存中的条目数(128),并计算a%128,%运算符计算a除以128的余数,由于a是二进制值,128是2的幂,因此计算余数非常容易。我们只需要从26位块地址中提取7个LSB位,这7位可用于访问标签阵列,就可以将保存在标记数组中的标记值与根据块地址计算的标记值进行比较,以确定是否命中或未命中。
还可以稍微优化它的设计,而不是像完全关联缓存那样将块地址保存在标记数组中。块地址中的26位中有7位用于访问标签阵列中的标签,意味着所有可能被映射到标签数组中给定条目的块都将有其最后7位共用,因此这7位不需要明确地保存为标签的一部分,只需要保存块地址的剩余19位,这些位可以在块之间变化。因此,高速缓存的直接映射实现中的标签只需要包含19位。
下图以图形方式描述了这一概念。将32位地址分成三部分,最重要的19位包括标记,接下来的7位称为索引(标记数组中的索引),其余6位指向块中字节的偏移,访问协议的其余部分在概念上类似于完全关联缓存。在这种情况下,我们使用索引来访问标记数组中的相应位置,读取内容并将其与计算标记进行比较。如果它们相等,则我们声明缓存命中,否则,缓存未命中。在缓存命中的情况下,使用索引访问数据数组,使用缓存命中/未命中结果来启用/禁用数据阵列。
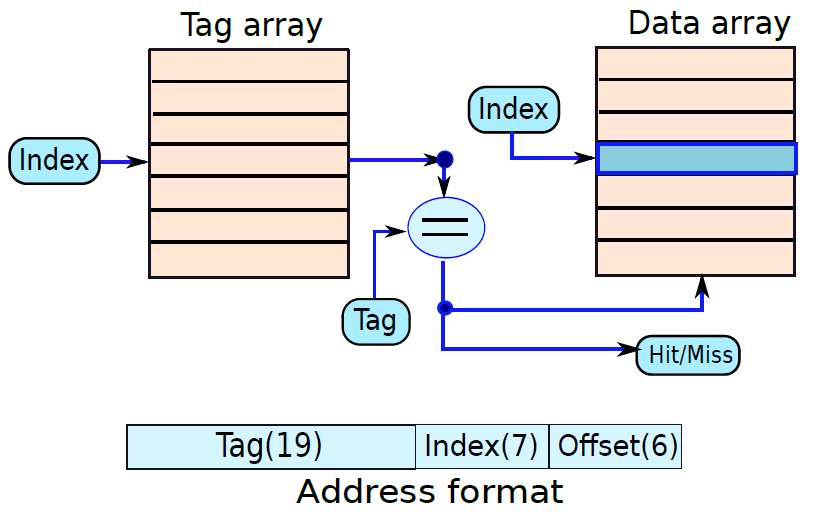
直接映射缓存。
到目前为止,我们已经研究了完全关联和直接映射缓存:
- 全关联缓存是一种非常灵活的结构,因为块可以保存在缓存中的任何条目中,但具有更高的延迟和功耗。由于给定的块可能被分配到缓存的更多条目中,因此它的命中率高于直接映射缓存。
- 直接映射缓存是一种速度更快、功耗更低的结构。一个块只能驻留在缓存中的一个条目中,此缓存的预期命中率小于完全关联缓存的命中率。
在完全关联和直接映射缓存之间,在功率、延迟和命中率之间存在折衷。
集合相联缓存
全关联缓存更耗电,因为需要在缓存的所有条目中搜索块。相比之下,直接映射缓存更快、更高效,因为只需要检查一个条目,但命中率较低,也是不可接受的。因此,尝试将这两种范式结合起来。
让我们设计一个缓存,其中一个块可以潜在地驻留在缓存中多个条目的集合中的任何一个条目中,将缓存中的一组条目与块地址相关联,像完全关联缓存一样,必须在声明命中或未命中之前检查集合中的所有条目,这种方法结合了完全关联和直接映射方案的优点。如果一个集合包含4或8个条目,那么就不必使用昂贵的CAM结构,也不必依次迭代所有条目,可以简单地从标记数组中并行读取集合的所有条目,并将所有条目与块地址的标记部分进行并行比较。如果存在匹配,那么我们可以从数据数组中读取相应的条目。由于多个块可以与一个集合相关联,因此将此设计称为集合关联(set associative)缓存。集合中的块数称为缓存的关联性,集合中的每个条目都被称为一个路(way)。
关联性(Associativity):集合中包含的块数定义为缓存的关联性。
路(Way):集合中的每个条目都被称为路。
让我们描述一个简单的方法,将缓存项分组为集合,考虑了一个32位内存系统,其中有一个8 KB的缓存和64字节的块。如下图所示,首先从32位地址中删除最低的6位,因为它们指定了块中字节的地址,剩余的26位指定块地址,8-KB缓存总共有128个条目。如果想创建每个包含4个条目的集合,那么我们需要将所有缓存条目分成4个条目,将有32(2525)个这样的集合。

在直接映射缓存中,我们使用26位块地址中的最低7位来指定缓存中条目的索引,现在可以将这7个比特分成两部分,如上图所示。一部分包含5个比特并指示集合的地址,而第二部分包含2个比特则被忽略,指示集合地址的5位组称为集合索引。
在计算集合索引ii之后,需要访问标签数组中属于集合的所有元素。可以按有以下方式排列标签数组,如果一个集合中的块数是S,那么可以对属于一个集合的所有条目进行连续分组。对于第ii个集合,我们需要访问元素iSiS、(iS+1)(iS+1) ... (iS+S−1)(iS+S−1)在标签数组中。
对于标记数组中的每个条目,需要将条目中保存的标记与块地址的标记部分进行比较。如果有匹配,那么我们可以宣布命中。集合关联缓存中标记的概念相当棘手。如上图所示,它由不属于索引的位组成,是块地址的(21=26−5)(21=26−5)MSB位,用于确定标签比特数的逻辑如下。
每个集合由5位集合索引指定,这5个比特对于可能映射到给定集合的所有块都是公用的,需要使用其余的比特(21=26−5)(21=26−5)来区分映射到同一集合的不同块。因此,集合关联高速缓存中的标签的大小介于直接映射高速缓存(19)和完全关联高速缓存(26)的大小之间。
下图显示了集合关联缓存的设计。首先从块的地址计算集合索引,使用位7-11,使用集合索引来使用标签数组索引生成器生成标签数组中相应四个条目的索引。然后,并行访问标记数组中的所有四个条目,并读取它们的值。此处无需使用CAM阵列,可以使用单个多端口(多输入、多输出)SRAM阵列。接下来,将每个元素与标记进行比较,并生成一个输出(0或1)。如果任何一个输出等于1(由或门确定),缓存命中,否则缓存未命中。我们使用编码器对匹配的集合中的标记进行索引,因为假设4路关联缓存,编码器的输出在00到11之间。随后,使用多路复用器来选择标签数组中匹配条目的索引,这个索引可以用来访问数据数组,数据数组中的相应条目包含块的数据,可以读或写它。
可以对读取操作进行一个小优化。请注意,在读取操作的情况下,对数据数组和标记数组的访问可以并行进行。如果一个集合有4路,那么当计算标签匹配时,可以读取与该集合的4路对应的4个数据块。随后,在缓存命中的情况下,在计算了标记数组中的匹配条目之后,我们可以使用多路复用器选择正确的数据块。在这种情况下,实际上将从数据数组读取块所需的部分或全部时间与标记计算、标记数组访问和匹配操作重叠。
集合关联缓存。
总之,集合关联缓存是目前最常见的缓存设计,即使是非常大的缓存,它也具有可接受的功耗值和延迟。集合关联缓存的关联性通常为2、4或8,关联性为K的集合也称为K路关联缓存。
在设计集合关联缓存时,我们需要回答一个深刻的问题。设置索引位和忽略位的相对顺序应该是什么?被忽略的位应该朝向索引位的左侧(MSB),还是朝向索引位右侧(LSB)?上上图选择了MSB,背后的逻辑是什么?
答案:
如果索引位的左边(MSB)有被忽略的位,那么相邻的块映射到不同的集合。然而,对于被忽略的位在索引位的右侧(LSB)的相反情况,连续块映射到同一集合。前一种方案称为非CONT,后一种方案为CONT,在设计中选择了非CONT。
考虑两个数组A和B,让A和B的大小明显小于缓存的大小,让它们的一些组成块映射到同一组集合。下图显示了存储CONT和NON-CONT方案数组的缓存区域的概念图。我们观察到,即使缓存中有足够的空间,也不可能使用CONT方案同时保存缓存中的两个数组。它们的内存占用在缓存的一个区域中重叠,因此不可能在缓存中同时保存两个程序的数据。然而,NON-CONT方案试图将块均匀分布在所有集合上。因此,可以同时将两个阵列保存在缓存中。
这是程序中经常出现的模式。CONT方案保留缓存的整个区域,因此不可能容纳映射到冲突集的其他数据结构。然而,如果将数据分布在缓存中,那么可以容纳更多的数据结构并减少冲突。
举个具体的示例,在32位系统中,缓存具有以下参数:
| 参数 | 值 |
|---|---|
| 尺寸 | NN |
| 关联性 | KK |
| 块尺寸 | BB |
那么,标签的尺寸是多数?答案:
- 指定块内的字节所需的位数为log(B)log(B)。
- 块数等于N=BN=B,集合数等于N/(BK)N/(BK)。
- 设置的索引位数等于:log(N)−log(B)−log(K)log(N)−log(B)−log(K)。
- 剩余的位数是标签位,等于:32−(log(N)−log(B)−log(K)+log(B))=32−log(N)+log(K)32−(log(N)−log(B)−log(K)+log(B))=32−log(N)+log(K)。
19.6.2.4 数据读取和写入操作
一旦我们确定给定的块存在于缓存中,我们就使用基本的读取操作从数据数组中获取内存位置的值。如果查找操作返回缓存命中,将确定缓存中是否存在块。如果缓存中存在未命中,则缓存控制器需要向较低级别的缓存发出读取请求,并获取块。数据读取操作可以在数据可用时立即开始。
第一步是读取数据数组中对应于匹配标记条目的块,然后从块中的所有字节中选择合适的字节集,可以使用一组多路复用器来实现之。在查找操作之后,不必严格开始数据读取操作,可以在两次行动之间有明显的重叠,例如,可以并行读取标记数组和数据数组。在计算出匹配标记之后,可以使用多路复用器选择正确的值集合。
在写入值之前,需要确保整个块已经存在于缓存中,这点非常重要。请注意,我们不能断言,因为正在创建新数据,所以不需要块的前一个值。原因是:对于单个内存访问,通常写入4个字节或最多8个字节,但一个块至少有32或64字节长,块是缓存中的原子单元,因此不能在不同的地方拥有它的不同部分。例如,不能将一个块的4个字节保存在一级缓存中,其余的字节保存在二级缓存中。其次,为了做到这一点,需要维护额外的状态,以跟踪已被写入更新的字节。因此,为了简单起见,即使希望只写入1个字节,也需要用整个块填充缓存。
之后,需要通过启用适当的一组字行(word line)和位行(bit line)将新值写入数据阵列,可以使用一组解复用器的电路来简单实现。
执行数据写入有两种方法:
- 直写(write-through)。直写是一种相对简单的方案,在这种方法中,每当将值写入数据数组时,也会向较低级别的缓存发送写操作。这种方法增加了缓存流量,但实现缓存更简单,因为不必在将块放入缓存后跟踪已修改的块。因此,如果需要,可以无缝地从缓存中逐出一行。缓存收回和替换也很简单,但以写入为代价。如果L1缓存遵循直写协议,那么很容易为多处理器实现缓存。
- 回写(write-back)。此方案明确地跟踪已使用写操作修改的块,可以通过在标记数组中使用额外的位来维护此信息,该位通常称为修改位,每当从内存层次结构的较低级别获得一个块时,修改位为0,然而,当进行数据写入并更新数据数组时,将标记数组中的修改位设置为1。逐出一行需要额外的处理。对于写回协议,写入成本较低,逐出操作成本较高。这里的折衷与直写缓存中的折衷相反。
带有附加修改位的标签数组中的条目结构如下图所示。

带有修改位的标签数组中的条目。
19.6.2.5 插入操作
本节将讨论在缓存中插入块的协议。当块从较低级别到达时,将调用此操作。需要首先查看给定块映射到的集合的所有方式,并查看是否有空条目。如果存在空条目,那么可以任意选择其中一个条目,并用给定块的内容填充它。如果没有结束任何空条目,需要调用替换和逐出操作来从集合中选择和删除一个已经存在的块。
需要维护一些额外的状态信息,以确定给定条目是空的还是非空的。在计算机体系结构中,这些状态也分别被称为无效(invalid)和有效(valid)。只需要在标记数组中存储一个额外的位,以指示块的状态,被称为有效位(valid bit)。使用标签数组来保存关于条目的附加信息,因为它比数据数组更小,通常更快。添加了有效位的标签数组中的条目结构如下图所示。
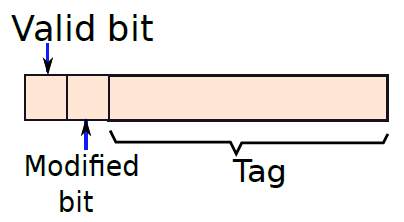
标签数组中的一个条目,包含修改后的有效位。
缓存控制器需要在搜索无效条目时检查每个标签的有效位。缓存的所有条目最初都是无效的,如果发现无效条目,则可以用块的内容填充数据数组中的相应条目,该条目随后生效。但是,如果没有无效条目,那么需要用需要插入缓存的给定块替换一个条目。
19.6.2.6 替换操作
这里的任务是在集合中查找一个可以被新条目替换的条目。我们不希望替换频繁访问的元素,因为会增加缓存未命中的数量。理想情况下,希望替换将来被访问的可能性最小的元素,但是,很难预测未来的事件。需要根据过去的行为做出合理的猜测,可以有不同的策略来替换缓存中的块。这些被称为替换方案或替换策略。
缓存替换方案(replacement scheme)或替换策略(replacement policy)是用新条目替换集合中的条目的方法。
常用的替换策略有:
-
随机替换策略。此策略最简单和普通,随机选取一个块并替换它。但是,它在性能方面并不是很理想,因为没有考虑程序的行为和内存访问模式的性质。该方案最终经常替换非常频繁访问的块。
-
FIFO替换策略。FIFO(先入先出)替换策略的假设是,在最早的时间点被带入缓存的块在将来被访问的可能性最小。为了实现FIFO替换策略,需要在标记数组中添加一个计数器。每当引入一个块时,都会给它分配一个等于0的计数器值,为其余的块增加计数器值。计数器越大,块越早进入缓存。
此外,要查找替换的候选项,我们需要查找计数器值最大的条目,一定是最早的区块。不幸的是,FIFO方案并不严格符合时间局部性原则。它会惩罚缓存中长期存在的块,而实际上,这些块也可能是非常频繁访问的块,不应该首先被逐出。
现在考虑实施FIFO替换策略的实际方面。计数器的最大大小需要等于集合中元素的数量,即缓存的关联性。例如,如果缓存的关联性为8,则需要有一个3位计数器,需要替换的条目应具有最大的计数器值。
请注意,在这种情况下,将新值引入缓存的过程相当昂贵,我们需要增加集合中除一个元素外的所有元素的计数器。然而,与缓存命中相比,缓存未命中更为罕见。因此,开销实践上并不显著,并且该方案可以在没有较大性能开销的情况下实现。
-
LRU替换策略。LRU(最近最少使用的)更换策略被认为是最有效的方案之一。LRU方案直接从堆栈距离的定义开始,理想情况下,我们希望替换将来被访问的机会最低的块,根据堆栈距离的概念,未来被访问的概率与最近访问的概率有关。如果处理器在n次(n不是很大的数目)访问的最后一个窗口中频繁地访问一个块,那么该块很有可能在不久的将来被访问。然而,如果上一次访问一个块是很久以前的事了,那么它很快就不太可能被访问了。
在LRU更换策略中,我们保留块最后一次访问的时间,选择在最早的时间点最后访问的块作为替换的候选。此策略为每个块维护一个时间戳,每当访问一个块时,它的时间戳都会被更新以匹配当前时间。要查找合适的替换候选项,需要查找集合中时间戳最小的条目。
实现LRU策略最大的问题是需要为对缓存的每次读写访问做额外的工作,对性能产生重大影响,因为通常三分之一的指令是内存访问。其次,需要专用比特来保存足够大的时间戳,否则需要频繁地重置集合中每个块的时间戳,此过程导致缓存控制器的进一步减速和额外复杂性。因此,实现尽可能接近理想的LRU方案且没有显著的开销是一项艰巨的任务。
可以尝试设计使用小时间戳(通常为1-3位)并大致遵循LRU策略的LRU方案,称为伪LRU(pseudo-LRU)方案。下面概述实现基本伪LRU的简单方法。与其尝试显式标记最近最少使用的元素,不如尝试标记最近使用的元素。未标记的元素将自动分类为最近最少使用的元素。
让我们从将计数器与标记数组中的每个块相关联开始。每当访问一个块(读/写)时,都递增计数器,一旦计数器达到最大值,就停止递增。例如,如果使用一个2位计数器,那么避免将计数器递增到3以上。为了实现与每个块关联的计数器将最终达到3并保持值,可以周期性地将集合中每个块的计数器递减1,甚至可以将它们重置为0。随后,一些计数器将再次开始增加。
此举确保大多数情况下,可以通过查看计数器的值来识别最近最少使用的块。与计数器的最低值相关联的块是最近最少使用的块之一,最有可能、最近最少使用的块。请注意,这种方法确实涉及每次访问的一定活动量,但是递增一个小计数器几乎没有额外开销。其次,它在计时方面不在关键路径上,可以并行执行,也可以稍后执行。寻找替换的候选项包括查看一组中的所有计数器,并查找计数器值最低的块。用新块替换块后,大多数处理器通常会将新块的计数器设置为最大可能值。这向高速缓存控制器指示,相对于替换的候选,新块应该具有最低优先级。
19.6.2.7 逐出操作
如果缓存遵循直写策略,则无需执行任何操作,该块可以简单地丢弃。然而,如果缓存遵循写回策略,那么需要查看修改后的位。如果数据没有被修改,那么它可以被无缝地收回。但是,如果数据已被修改,则需要将其写回较低级别的缓存。
19.6.2.8 综合操作
缓存读取操作的步骤序列如下图所示,从查找操作开始,可以在查找和数据读取操作之间有部分重叠。如果有缓存命中,则缓存将值返回给处理器或更高级别的缓存(无论是哪种情况)。但是,如果缓存未命中,则需要取消数据读取操作,并向较低级别的缓存发送请求。较低级别的缓存将执行相同的访问序列,并返回整个缓存块(不仅仅是4个字节)。然后,高速缓存控制器可以从块中提取所请求的数据,并将其发送到处理器,同时缓存控制器调用插入操作将块插入缓存。如果集合中有一个无效的条目,那么可以用给定的块替换它,但如果集合中的所有方法都有效,则需要调用替换操作来查找替换的候选。该图为该操作附加了一个问号,因为该操作并非一直被调用(仅当集合的所有路径都包含有效数据时)。然后,需要收回块,如果修改了行,可能会将其写入较低级别的缓存,并且正在使用写回缓存。然后缓存控制器调用插入操作,这次肯定会成功。
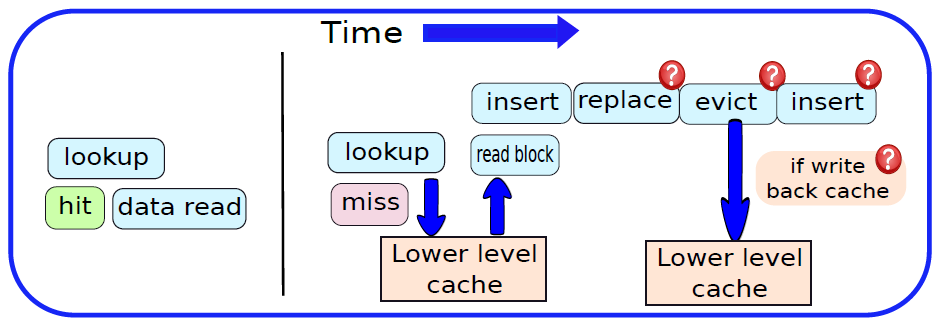
读取操作。
下图显示了回写缓存的缓存写入操作的操作序列,操作顺序大致类似于缓存读取。如果缓存命中,将调用数据写入操作,并将修改后的位设置为1,否则将向较低级别的缓存发出块的读取请求。块到达后,大多数缓存控制器通常将其存储在一个小的临时缓冲区中,此时将4个字节写入缓冲区,然后返回。在某些处理器中,缓存控制器可能会等待所有子操作完成。写入临时缓冲区后(上图中的写入块操作),调用插入操作来写入块的内容(修改后),如果此操作不成功(因为所有方法都有效),那么将遵循与读取操作相同的步骤顺序(替换、逐出和插入)。
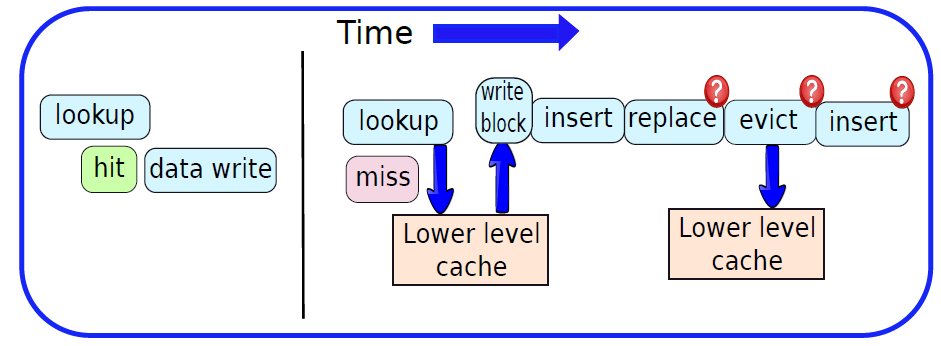
写操作(回写缓存)。
下图显示了直写缓存的操作序列。第一个不同点是,即使请求在缓存中命中,也会将块写入较低级别。第二个不同点是,在将值写入临时缓冲区之后(在未命中之后),还将块的新内容写回较低级别的缓存。其余步骤类似于为回写缓存所遵循的步骤序列。
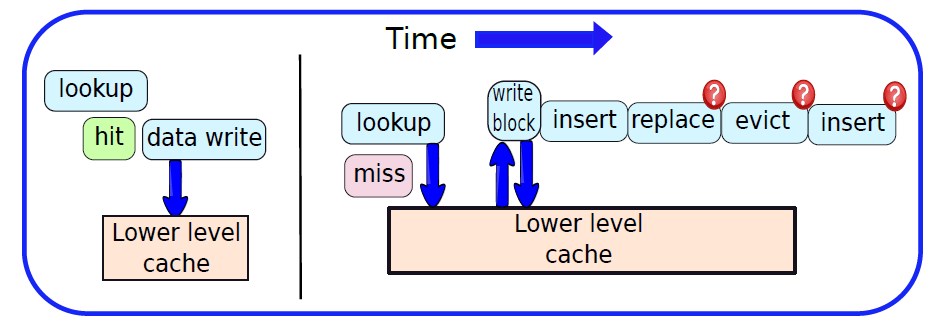
写入操作(直写缓存)。
19.6.3 内存系统机制
我们已经对缓存的工作及其所有组成操作有了一个合理的理解,使用缓存层次结构构建内存系统。内存系统作为一个整体支持两种基本操作:读取和写入,或者加载和存储。
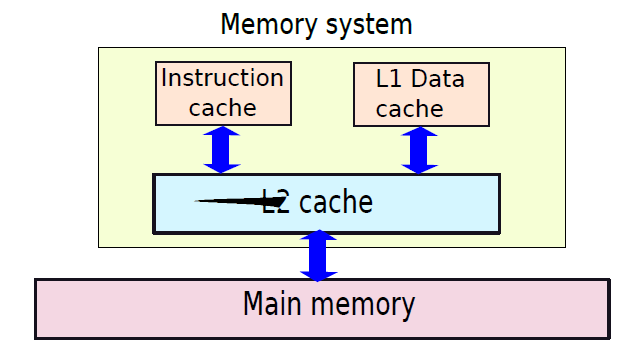
有两个最高级别的缓存:数据缓存(也称为一级缓存)和指令缓存(也称I缓存)。几乎所有时候,它们都包含不同的内存位置集。用于访问I缓存和L1缓存的协议相同,为了避免重复,后面只关注一级缓存。我们只需要记住,对指令缓存的访问遵循相同的步骤顺序。
处理器通过访问一级缓存启动。如果存在L1命中,则它通常在1-2个周期内接收该值。否则,请求需要转到二级缓存,或者甚至更低级别的缓存,如主内存。在这种情况下,请求可能需要数十或数百个周期。本节将从整体上看缓存系统,并将它们视为一个称为内存系统的黑盒子。
如果考虑包含性缓存,那么内存系统的总大小等于主内存的大小。例如,如果一个系统有1 GB的主内存,那么内存系统的大小等于1 GB。内存系统内部可能有一个用于提高性能的缓存层次结构,但不会增加总存储容量,因为只包含主内存中包含的数据子集。此外,处理器的存储器访问逻辑还将整个存储器系统视为单个单元,概念上被建模为一个大的字节阵列。这也称为物理内存系统或物理地址空间。
物理地址空间包括高速缓存和主内存中包含的所有存储器位置的集合。
19.6.3.1 内存系统的数学模型
性能
内存系统可以被认为是一个只服务于读写请求的黑盒子,请求所用的时间是可变的,取决于请求到达的内存系统的级别。管线在内存访问(MA)阶段连接到内存系统,并向其发出请求。如果回复不在一个周期内,那么需要在5阶段顺序流水线中引入额外的气泡。
设平均内存访问时间为AMAT(以周期测量),加载/存储指令的分数为fmemfmem,那么CPI可以表示为:
CPI=CPIideal + stall\_rate ∗ stall\_cycles =CPIideal +fmem ×(AMAT−1)CPI=CPIideal + stall\_rate ∗ stall\_cycles =CPIideal +fmem ×(AMAT−1)
CPIidealCPIideal是假定完美的存储器系统对所有访问具有1个周期延迟的CPI。请注意,在5阶段顺序流水线中,理想的指令吞吐量是每个周期1条指令,内存级分配1个周期。在实践中,如果一次内存访问需要n个周期,那么我们有n-1个暂停周期,它们需要上述公式来解释。在此公式中,我们隐式地假设每次内存访问都会经历AMAT-1个周期的暂停。实际上,情况并非如此,因为大多数指令将在一级缓存中命中,并且一级缓存通常具有1个周期的延迟。因此,命中一级缓存的访问不会停止。但是,L1和L2缓存中的访问失败会导致长的暂停周期。
尽管如此,上述公式仍然成立,因为我们只对大量指令的平均CPI感兴趣,可以通过考虑大量指令,对所有内存暂停周期求和,并计算每条指令的平均周期数来推导出这个方程。
平均内存访问时间
在上述公式中,CPIidealCPIideal由程序的性质和管线的其他阶段(MA除外)的性质决定,fmemfmem也是处理器上运行的程序的固有属性。我们需要一个公式来计算AMAT,可以用类似于上面公式的方法计算它。假设一个具有L1和L2缓存的内存系统,有:
AMAT =L1hittime +L1miss rate ×L1miss penalty =L1hittime +L1miss rate ×( L2 hittime +L2miss rate ×L2miss penalty ) AMAT =L1hittime +L1miss rate ×L1miss penalty =L1hittime +L1miss rate ×( L2 hittime +L2miss rate ×L2miss penalty )
所有内存访问都需要访问L1缓存,而不管命中还是未命中,因此它们需要产生等于L1命中时间的延迟。一部分访问(L1miss rateL1miss rate)将在L1缓存中丢失,并移动到L2缓存。此外,无论命中还是未命中,都需要产生L2hit timeL2hit time周期的延迟。如果L2缓存中有一部分访问(L2miss rateL2miss rate)未命中,则需要继续访问主存储器。我们假设所有的访问都发生在主内存中。因此,L2miss penaltyL2miss penalty惩罚等于主存储器访问时间。
假设有一个n级存储器系统,其中第一级是L1缓存,最后一级是主存储器,那么可以使用类似的公式:
AM AT =L1hittime +L1miss rate ×L1miss penalty L1miss penalty =L2hittime +L2miss rate ×L2miss penalty L2miss penalty =L3hit time +L3miss rate ×L3miss penalty ⋯=…L(n−1)miss penalty =Lnhit time AM AT =L1hittime +L1miss rate ×L1miss penalty L1miss penalty =L2hittime +L2miss rate ×L2miss penalty L2miss penalty =L3hit time +L3miss rate ×L3miss penalty ⋯=…L(n−1)miss penalty =Lnhit time
需要注意的是,这些等式中针对某一级别ii使用的未命中率等于该级别未命中的访问数除以该级别的访问总数,被称为局部未命中率(local miss rate)。相比之下,我们可以定义第ii级的全局未命中率(global miss rate),它等于第ii级未命中数除以内存访问总数。
局部未命中率(local miss rate):它等于第ii级缓存中的未命中数除以第ii级的访问总数。
全局未命中率(global miss rate):它等于ii级缓存中的未命中数除以内存访问总数。
可以通过降低未命中率、未命中惩罚或减少命中时间来提高系统的性能。后面先看看未命中率。
19.6.3.2 缓存未命中
缓存未命中分类
让我们首先尝试对缓存中不同类型的未命中进行分类。
- 强制未命中或冷未命中。当数据第一次加载到缓存中时,由于数据值不在缓存中,必然会发生此类未命中。
- 容量未命中。当一个程序所需的内存量大于缓存大小时,会发生容量未命中。例如,假设一个程序重复访问数组的所有元素,数组的大小等于1 MB,二级缓存的大小为512 KB。在这种情况下,二级缓存中会有容量未命中,因为它太小,无法容纳所有数据。
- 冲突未命中。程序在一个典型的时间间隔内访问的一组块称为其工作集,也可以说,当缓存的大小小于程序的工作集时,会发生冲突未命中。请注意,工作集的定义有点不精确,因为间隔的长度是主观考虑的。然而,时间间隔的内涵是,与程序执行的总时间相比,它是一个很小的间隔。只要它足够大,以确保系统的行为达到稳定状态,此类未命中发生在直接映射和集关联缓存中。例如,考虑一个4路集合关联缓存,如果一个程序的工作集中有5个块映射到同一个集,必然会有缓存未命中,因为访问的块的数量大于可以作为集合一部分的最大条目数。
程序在短时间间隔内访问的内存位置包括程序在该时间点的工作集。
由此,可将未命中分为三类:强制、容量和冲突,也称为三“C”。
降低未命中率
为了维持高IPC,有必要降低缓存未命中率。我们需要采取不同的策略来减少不同类型的缓存未命中。
让我们从强制性失误开始。我们需要一种方法来预测未来将访问的块,并提前获取这些块。通常,利用空间局部性的方案是有效的预测因素。因此,增加块大小对于减少强制未命中的数量应该是有益的。然而,将块大小增加到超过某个限制也会产生负面后果。它减少了可以保存在缓存中的块的数量,其次,额外的好处可能是微不足道的。最后,从内存系统的较低级别读取和传输较大的块将需要更多的时间。因此,设计师避免过大的块尺寸。32-128字节之间的任何值都是合理的。
现代处理器通常具有复杂的预测器,这些预测器试图根据当前的访问模式预测将来可能访问的块的地址。他们随后从内存层次结构的较低级别获取预测的块,试图降低未命中率。例如,如果我们按顺序访问一个大数组的元素,那么可以根据访问模式预测未来的访问。有时我们访问数组中的元素,其中的索引相差固定值。例如,我们可能有一个访问数组中每四个元素的算法。在这种情况下,也可以分析模式并预测未来的访问,因为连续访问的地址相差相同的值。这种单元被称为硬件预取器。它存在于大多数现代处理器中,并使用复杂的算法来“预取”块,从而降低未命中率。请注意,硬件预取器不应非常激进。否则,它将倾向于从缓存中移出比它带来的更有用的数据。
硬件预取器(hardware prefetcher)是一个专用的硬件单元,它预测在不久将来的内存访问,并从内存系统的较低级别获取它们。
先阐述容量未命中。唯一有效的解决方案是增加缓存的大小,不幸的是,本文介绍的缓存设计要求缓存的大小等于2的幂(以字节为单位),使用一些高级技术可能会违反这一规则。然而,大体上,商业处理器中的大多数缓存的大小都是2的幂。因此,增加缓存的大小等于至少使其大小加倍,将缓存的大小加倍需要两倍的面积,使其速度减慢,并增加功耗。如果明智地使用预取,也会有所帮助。
减少冲突未命中数的经典解决方案是增加缓存的关联性,但也会增加缓存的延迟和功耗,设计者有必要仔细平衡集合关联缓存的额外命中率和额外延迟。有时,缓存中的一些集合中会出现冲突未命中,在这种情况下,可以用一个小型的全关联缓存,称为牺牲缓存(victim cache)和主缓存。从主缓存移位的任何块都可以写入牺牲缓存,缓存控制器需要首先检查主缓存,如果有未命中,则需要检查牺牲缓存,然后再继续进行下一级。因此,级别i的牺牲缓存可以过滤掉一些到达级别(i+1)的请求。
注意,与硬件技术一起,以“缓存友好”的方式编写程序是可行的,可以最大化时间和空间的局部性,编译器也可以优化给定内存系统的代码。其次,编译器可以插入预取代码,以便在实际使用之前将块预取到缓存中。
现在快速提及两条经验法则,这些规则被发现在经验上大致成立,并且在理论上并非完全正确。
第一个被称为平方根规则(Square Root Rule),它表示未命中率与缓存大小的平方根成正比:
miss rate∝1√ cachesize [SquareRootRule]miss rate∝1 cachesize [SquareRootRule]
哈特斯坦等人[Hartstein等人,2006]试图为该规则找到理论依据,并利用概率论的结果解释该规则的基础。根据他们的实验结果,得出了该规则的通用版本,该规则表示平方根规则中缓存大小的指数从-0.3到-0.7不等。
第二个规则被称为关联性规则(Associativity Rule),它表明将关联性加倍的效果几乎与将缓存大小与原始关联性加倍相同,例如64 KB 4路关联缓存的未命中率几乎与128 KB 2路关联缓存相同。
注意,关联性规则和平方根规则只是经验规则,并不完全成立,仅仅用作概念辅助工具,我们总是可以构造违反这些规则的示例。
减少命中时间和未命中不利
还可以通过减少命中时间和未命中不利(Miss Penalty)来减少平均内存访问时间。为了减少命中时间,需要使用小而简单的缓存,但也增加了未命中率。
现在讨论一下减少不利的方法。请注意,级别i处的未命中不利等于从级别(i+1)开始的存储器系统的存储器延迟。传统的减少命中时间和未命中率的方法总是可以用于在给定的水平上减少未命中不利,现在研究专门针对减少未命中不利的方法。首先看看一级缓存中的写入未命中。在这种情况下,必须将整个块从L2高速缓存带入高速缓存,需要时间(>10个周期),其次,除非写入完成,否则管线无法恢复。处理器设计人员使用一个称为写缓冲区的小集合关联缓存,如下图所示。处理器可以将值写入写缓冲区,然后恢复,或者,只有在L1缓存中未命中时(假设),它才可以写入写缓冲。任何后续读取都需要在访问一级缓存的同时检查写入缓冲区,该结构通常非常小且快速(4-8个条目)。
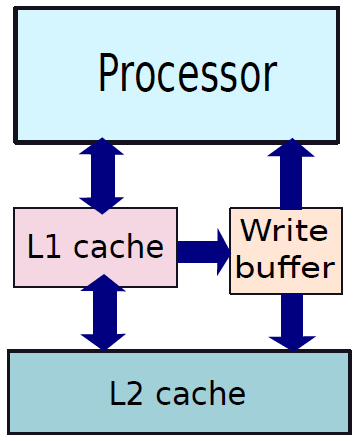
一旦数据到达一级缓存,就可以从写缓冲器中删除相应的条目。注意,如果写缓冲区中没有可用的空闲条目,则管线需要暂停。其次,在从较低级别的高速缓存服务写入未命中之前,可能存在对同一地址的另一次写入,可以通过写入写入缓冲区中给定地址的分配条目来无缝处理。
现在看看读取未命中。处理器通常只对每次内存访问最多4个字节感兴趣,如果提供了这些关键的4字节,管线可以恢复。然而,在操作完成之前,内存系统需要填充整个块,块的大小通常在32-128字节之间。因此,如果内存系统知道处理器所需的确切字节集,则可以在此引入优化。在这种情况下,内存系统可以首先获取所需的内存字(4字节),随后或者并行地获取块的其余部分。这种优化被称为关键词优先(critical word first)。然后,可以将这些数据快速发送到管线,以便恢复其操作。这种优化被称为提前重启(early restart)。实现这两种优化增加了内存系统的复杂性。然而,关键词语优先和提前重启在减少未命中不利方面相当有效。
内存系统优化技术概述
下表总结了我们为优化存储系统而引入的不同技术。请注意,每种技术都有一些负面影响,如果一种技术在一个方面改进了内存系统,那么在另一个方面是有害的。例如,通过增加缓存大小,我们可以减少容量未命中的数量,但也增加了面积、延迟和功率。
| 技术 | 应用 | 劣势 |
|---|---|---|
| 大块尺寸 | 强制未命中 | 减少缓存的块数 |
| 预获取 | 强制未命中、容量未命中 | 额外的复杂性和从缓存中替换有用数据的风险 |
| 大缓存大小 | 容量未命中 | 高延迟、高功率、更大面积 |
| 关联性增强 | 冲突未命中 | 高延迟、高功率 |
| 牺牲缓存 | 冲突未命中 | 额外复杂性 |
| 基于编译器的技术 | 所有类型的未命中 | 不是很通用 |
| 小而简单的缓存 | 命中时间 | 高未命中率 |
| 写入缓冲器 | 未命中不利 | 额外复杂性 |
| 关键词优先 | 未命中不利 | 额外的复杂性和状态 |
| 提前重启 | 未命中不利 | 额外复杂性 |
总而言之,必须非常仔细地设计内存系统。目标工作量的要求必须与设计师设置的限制和制造技术的限制仔细平衡,需要最大化性能,同时注意功率、面积和复杂性限制。
19.6.4 虚拟内存
一个处理器可以通过在不同的程序之间快速切换来运行多个程序。例如,当用户玩游戏时,他的处理器可能正在接收电子邮件,之所以感觉不到任何中断,是因为处理器在程序之间来回切换的时间尺度(通常为几毫秒)比人类所能感知的要小得多。
到目前为止,我们假设程序所需的所有数据都驻留在主内存中,这种假设是不正确的。在过去,主内存的大小曾经是几兆字节,而用户可以运行需要数百兆字节数据的非常大的程序。即使现在,也可以处理比主内存量大得多的数据。用户可以通过编写一个C程序来轻松验证这一语句,该程序创建的数据结构大于机器中包含的物理内存量。在大多数系统中,此C程序将成功编译并运行。
本节通过对内存系统进行少量更改,可以满足以上要求。阅读本节需要一定的操作系统知识(如进程、线程、内存等),可参阅剖析虚幻渲染体系(18)- 操作系统。
19.6.4.1 内存的虚拟视图
因为多个进程在同一时间点处于活动状态,有必要在进程之间划分内存,如果不这样做,那么进程可能最终会修改彼此的值,同时也不希望程序员或编译器知道多个进程的存在。否则,会引入不必要的复杂性,其次,如果给定的程序是用某个内存映射编译的,那么它可能不会在另一台具有重叠内存映射的进程的机器上运行,更糟糕的是,不可能运行同一程序的两个副本。因此,每个程序都必须看到内存的虚拟视图,在该视图中,它假定自己拥有整个内存系统。
这两个要求出现了相互的矛盾——内存系统和操作系统希望不同的进程访问不同的内存地址,而程序员和编译器不希望知道这一要求。此外,程序员希望根据自己的意愿布局内存映射。事实证明,有一种方法可以让程序员和操作系统都感到满意。
我们需要定义内存的虚拟和物理视图。在内存的物理视图中,不同的进程在内存空间的非重叠区域中操作。然而,在虚拟视图中,每个进程都访问它希望访问的任何地址,并且不同进程的虚拟视图可以重叠。解决方案是分页。内存的虚拟视图也称为虚拟内存,它被定义为一个假设的内存系统,其中一个进程假定它拥有整个内存空间,并且没有任何其它进程的干扰。
虚拟内存系统被定义为一个假设的内存系统,其中一个进程假定它拥有整个内存空间,并且没有任何其他进程的干扰。内存的大小与系统的总可寻址内存一样大。例如,在32位系统中,虚拟内存的大小为232232字节(4 GB)。虚拟内存中所有内存位置的集合称为虚拟地址空间。
下图显示了32位Linux操作系统中进程的内存映射的简化视图。让我们从底部(最低地址)开始。第一段包含标头,从进程、格式和目标机器的详细信息开始。标头包含内存映射中每段的详细信息,例如,它包含包含程序代码的文本部分的详细信息,包括其大小、起始地址和其他属性。文本段从标头之后开始,加载程序时,操作系统将程序计数器设置为文本段的开始。程序中的所有指令通常都包含在文本段中。
Linux操作系统中进程的内存映射(32位)。
文本段后面是另外两个段,用于包含静态变量和全局变量。可选地,一些操作系统也有一个额外的区域来包含只读数据,如常量。文本段之后通常是数据部分,包含所有由程序员初始化的静态/全局变量。让我们考虑以下形式的声明(在C或C++中):
static int val = 5;
与变量val对应的4个字节保存在数据段中。
数据段后面是bss段,bss段保存程序员未明确初始化的静态变量和全局变量。大多数操作系统,所有与bss段对应的内存区域都为零。为了安全起见,必须这样做。让我们假设程序A运行并将其值写入bss段,随后程序B运行。在写入bss段中的变量之前,B总是可以尝试读取其值。在这种情况下,它将获得程序A写入的值,但这不是理想的行为,程序A可能在bss段保存了一些敏感数据,例如密码或信用卡号。因此,程序B可以在程序A不知情的情况下访问这些敏感数据,并可能滥用这些数据。因此,有必要用零填充bss段,这样就不会发生此类安全错误。
bss段后面是一个称为堆的内存区域,堆区域用于在程序中保存动态分配的变量。C程序通常使用malloc调用分配新数据,Java和C++使用new运算符。让我们看看一些例子:
int *intarray = (int*) malloc(10 * sizeof(int)); // [C]
int *intarray = new int[10]; // [C++]
int[] intarray = new int[10]; // [Java]
请注意,在这些语言中,动态分配数组非常有用,因为它们的大小在编译时是未知的。堆中有数据的另一个优点是它们可以跨函数调用生存。堆栈中的数据仅在函数调用期间保持有效,随后被删除。然而,堆中的数据会在程序的整个生命周期中保留,它可以由程序中的所有函数使用,指向堆中不同数据结构的指针可以跨函数共享。请注意,堆向上增长(朝向更高的地址)。其次,在堆中管理内存是一项相当困难的任务,因为在高级语言中,堆的区域动态地被分配了malloc/new调用,并被释放了free/delete调用。一旦释放了分配的内存区域,就会在内存映射中形成一个孔洞。如果孔的大小小于孔的大小,则可以在孔中分配一些其他数据结构。在这种情况下,将在内存映射中创建另一个较小的孔。随着时间的推移,随着越来越多的数据结构被分配和取消分配,孔洞的数量往往会增加,这就是所谓的碎片化。因此,有必要拥有一个高效的内存管理器,以减少堆中的孔数。下图显示了带有孔和分配内存的堆的视图。
堆的内存映射。
下一段用于存储与内存映射的文件和动态链接的库相对应的数据。大多数情况下,操作系统将文件的内容(如音乐、文本或视频文件)传输到内存区域,并将文件的属性视为常规数组,该存内存区域被称为内存映射文件。其次,程序可能偶尔会动态读取其他程序(称为库)的内容,并将其文本段的内容传输到内存映射中,这种库称为动态链接库(dll)。这种内存映射结构的内容存储在进程的内存映射中的专用段中。
下一段是堆栈,它从内存映射的顶部开始向下增长(朝向更小的地址),堆栈根据程序的行为不断增长和收缩。请注意,上上图未按比例绘制。如果我们考虑32位内存系统,那么虚拟内存的总量是4 GB,但程序可能使用的内存总量通常限制在数百兆字节。因此,在堆的开始部分和堆栈部分之间的映射中有一个巨大的空区域。
请注意,操作系统需要非常频繁地运行,需要为设备请求提供服务,并执行进程管理。从一个进程到另一个进程更改内存的虚拟视图稍微有些昂贵,因此,大多数操作系统在用户进程和内核之间划分虚拟内存,例如,Linux为用户进程提供了较低的3GB,为内核保留了较高的1GB。类似地,Windows为内核保留较高的2GB,为用户进程保留较低的2GB。当处理器从用户进程转换到内核时,不需要更改内存视图。其次,这种小的修改不会极大地降低程序的性能,因为2GB或3GB远远超过程序的典型内存占用量。此外,这个技巧也与虚拟内存概念不冲突,一个程序只需要假设它的内存空间减少了(在Linux的情况下,从4GB减少到3GB),参考下图。
Linux和Windows的用户、内核的内存映射。
19.6.4.2 重叠和尺寸问题
我们需要解决两个虚拟内存的问题:
- 重叠问题。程序员和编译器编写程序时假定他们拥有整个内存空间,并且可以随意写入任何位置。不幸的是,所有同时处于活动状态的进程都做出了相同的假设。除非采取措施,否则它们可能会在不经意间写入对方的内存空间并破坏对方的数据。事实上,考虑到它们使用相同的内存映射,在粗略的系统中发生这种情况的可能性非常高,硬件需要确保不同的进程相互隔离。这就是重叠问题。
- 尺寸问题。有时我们需要运行需要比可用物理内存更多内存的进程。如果其他存储介质(例如硬盘)中的一些空间可以重新用于存储进程的内存占用,便是理想的,这就是所谓的尺寸问题。
任何虚拟内存的实现都需要有效地解决尺寸和重叠问题。
19.6.4.3 分页
本小节涉及到的概念解析如下:
- 虚拟地址:程序在虚拟地址空间中指定的地址。
- 物理地址:地址转换后呈现给内存系统的地址。
- 页(page):是虚拟地址空间中的一块内存。
- 帧(frame):是物理地址空间中的一块内存,页和帧大小相同。
- 页表(page table):是一个映射表,将每个页面的地址映射到帧的地址。每个进程都有自己的页表。
为了平衡处理器、操作系统、编译器和程序员的需求,需要设计一个转译系统,将进程生成的地址转译成内存系统可以使用的地址。通过使用转译器,可以满足需要虚拟内存的程序员/编译器和需要物理内存的处理器/内存系统的需求。转译系统类似于现实生活中的翻译人员,例如,如果我们有一个俄罗斯代表团访问迪拜,那么我们需要一个能将俄语翻译成阿拉伯语的翻译。然后双方都可以说自己的语言,从而感到高兴。转译系统的概念图如下图所示。

考虑一个32位内存地址,现在可以把它分成两部分。如果考虑一个4KB的页面,那么低12位指定页面中字节的地址(原因:212212=4096=4KB),称为偏移,高20位指定页码(下图)。同样,可以将物理地址分为两部分:帧号和偏移。下图的转换过程首先将20位页码替换为等效的20位帧号,然后将12位偏移量附加到物理帧号。

将虚拟地址转换为物理地址。
在实现的方案中,按照页表的层级,有1级和2级页表,它们的示意图如下:
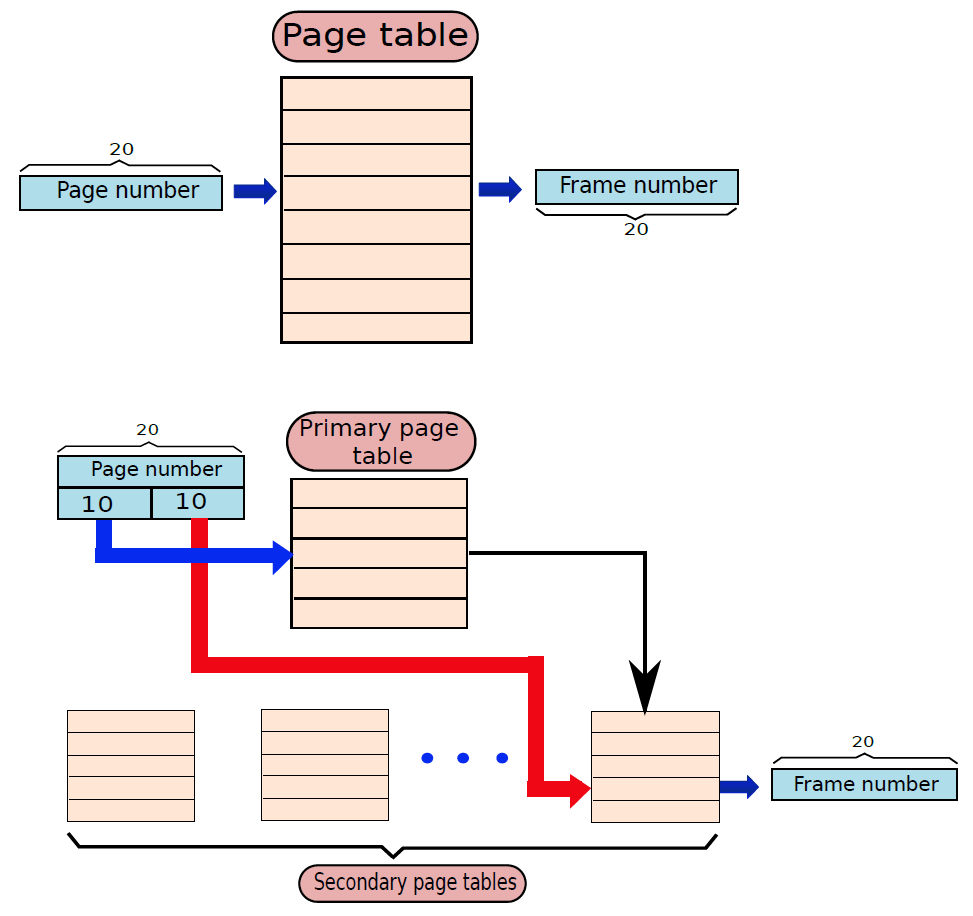
上:1级页表;下:2级页表。
一些处理器,如英特尔安腾和PowerPC 603,对页表使用不同的设计。它们不是使用页码来寻址页表,而是使用帧号来寻址页。在这种情况下,整个系统只有一个页面表。由于一个帧通常被唯一地映射到进程中的一个页面,所以这个反向页面表中的每个条目都包含进程id和页码。下图(a)显示了反转页表的结构,其主要优点是不需要为每个进程保留单独的页表。如果有很多进程,并且物理内存的大小很小,可以节省空间。
反转页表。
反向页表的主要困难在于查找虚拟地址。扫描所有条目是一个非常缓慢的过程,因此不实用。因此,需要一个哈希函数,将(进程id,页码)对映射到哈希表中的索引,哈希表中的这个索引需要指向反向页表中的一个条目。由于多个虚拟地址可以指向哈希表中的同一条目,因此有必要验证(进程id、页码)与存储在反向页表中的条目中的匹配。
上图(b)中展示了一种使用反向页表的方案。在计算页码和进程id对的哈希之后,访问一个由哈希内容索引的哈希表,哈希表条目的内容指向可能映射到给定页面的帧f。然而,我们需要验证,因为哈希函数可能将多个页面映射到同一帧。随后访问反向页表,并访问条目f。反向页表的一个条目包含映射到给定条目(或给定帧)的页码、进程id对。如果发现内容不匹配,就继续在随后的K个条目中搜索页码、进程id对。这种方法被称为线性探测(linear probing),在目标数据结构中不断搜索,直到找到匹配。如果没有在K个条目中找到匹配项,就可能会得出页面没有映射的结论。然后,需要创建一个映射,方法是逐出一个条目(类似于缓存),并将其写入主内存中的一个专用区域,该区域存储从反向页表中逐出的所有条目,需要始终确保哈希表指向的条目和包含映射的实际条目之间的差异不超过K个条目。如果没有找到任何空闲插槽,那么就需要收回一个条目。
有人可能认为,可以直接使用哈希引擎的输出来访问反向页表。通常,我们添加访问哈希表作为中间步骤,因为它允许更好地控制实际使用的帧集。使用此过程,可以禁止某些帧的映射,这些帧可用于其他目的。最后需要注意的是,维护和更新哈希表的开销大于拥有全系统页面表的收益。因此,反转页表通常不用于商业系统。
虚拟内存还涉及TLB、空间替换、MMU、页面错误等概念和机制,这些可在虚拟内存中寻得支持,本文不再累述。
地址转译过程。
19.6.4.4 分页系统高级功能
事实证明,我们可以用页表机制做一些有趣的事情,下面看看几个例子。
- 共享内存
假设两个进程希望在彼此之间共享一些内存,以便它们交换数据,每个进程都需要让内核知道这一点。内核可以将两个虚拟地址空间中的两个页面映射到同一帧,之后,每个进程都可以在自己的虚拟地址空间中写入页面,神奇的是,数据将反映在另一个进程的虚拟地址中。有时需要几个进程相互通信,共享内存机制是最快的方法之一。
- 保护
计算机病毒通常会更改正在运行的进程的代码,以便它们可以执行自己的代码,通常通过向程序提供一个特定的错误输入序列来实现。如果没有进行适当的检查,那么程序中特定变量的值将被覆盖。一些变量可以更改为指向文本段的指针,并且可以利用此机制更改文本部分段中的指令。可以通过将文本段中的所有页面标记为只读来解决此问题,无法在运行时修改它们的内容。
- 分段
我们一直假设程序员可以根据自己的意愿自由布局内存映射,例如,程序员可能决定在非常高的地址(例如0xFFFFFFF8)启动堆栈,然而,即使程序的内存占用非常小,该代码也可能无法在使用16位地址的机器上运行。其次,某个系统可能保留了虚拟内存的某些段,并使其无法用于进程。例如,操作系统通常为内核保留较高的1或2 GB。为了解决这些问题,我们需要在虚拟内存之上创建另一个虚拟层。
在分段内存(用于x86系统)中,有用于文本、数据和堆栈段的特定段寄存器。每个虚拟地址指定为特定段寄存器的偏移量。默认情况下,指令使用代码段寄存器,数据使用数据段寄存器。管线的内存访问(MA)阶段将偏移量添加到存储在段寄存器中的值以生成虚拟地址。随后,MMU使用该虚拟地址来生成物理地址。

















 1027
1027

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









