









 文章详细分析了AMDGPU如何通过Ring进行硬解码的完成流程,涉及gpu_sched.ko模块的调度逻辑,以及Ringbuffer在GPU-CPU通信中的作用。还探讨了AMDGPU的视频解码器方案和中断处理机制,以及VAAPI和doorbell在视频处理中的角色。
文章详细分析了AMDGPU如何通过Ring进行硬解码的完成流程,涉及gpu_sched.ko模块的调度逻辑,以及Ringbuffer在GPU-CPU通信中的作用。还探讨了AMDGPU的视频解码器方案和中断处理机制,以及VAAPI和doorbell在视频处理中的角色。
因为对编解码的通路比较熟悉,以VIDEO RING为例,记录分析AMD GPU实现硬解码的完成流程,计算Ring ROCm和渲染Ring GFX大同小异。
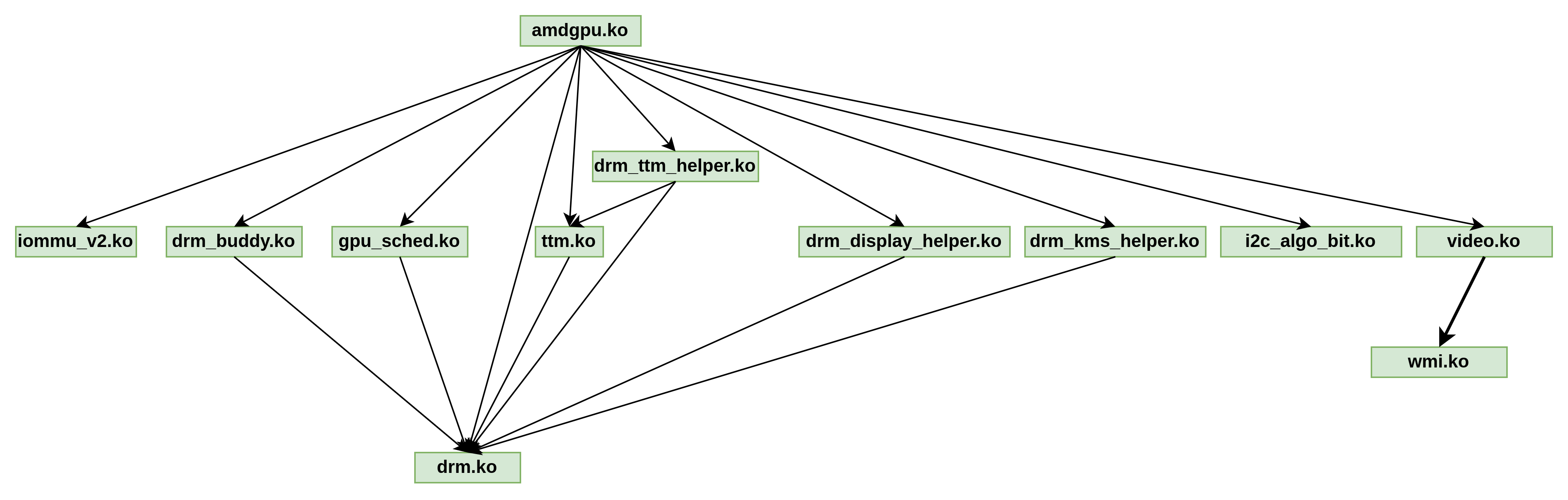
AMDGPU驱动模块的依赖关系如下图,gpu_sched.ko位于GPU驱动架构的中间层,主要负责对Ring在中任务的调度:
编译gpu_sched.ko
模块源码位于linux-x.x.xx/drivers/gpu/drm/scheduler下,通过CONFIG_DRM_SCHED项配置编译。从Makefile来看,代码量不是很大,只有三个源文件,但子曾经曰过,尿泡虽大无斤两,秤砣虽小挑千斤,这个小小的模块中包含了GPU调度的精髓,这篇文章也是从核心的下手开始分析。
编译一遍:
make drivers/gpu/drm/scheduler/
根据编译过程也可以看到,模块本身对应的源码仅仅有sched_main.c,sched_fence.c,sched_entity.c三个。
接口定义
sched_main.c接口定义
static bool drm_sched_blocked(struct drm_gpu_scheduler *sched);
static __always_inline bool drm_sched_entity_compare_before(struct rb_node *a,
const struct rb_node *b);
void drm_sched_fault(struct drm_gpu_scheduler *sched);
void drm_sched_fini(struct drm_gpu_scheduler *sched);
static struct drm_sched_job *
drm_sched_get_cleanup_job(struct drm_gpu_scheduler *sched);
void drm_sched_increase_karma(struct drm_sched_job *bad);
int drm_sched_init(struct drm_gpu_scheduler *sched,
onst struct drm_sched_backend_ops *ops,
unsigned hw_submission, unsigned hang_limit,
long timeout, struct workqueue_struct *timeout_wq,
atomic_t *score, const char *name, struct device *dev);
int drm_sched_job_add_dependency(struct drm_sched_job *job,
struct dma_fence *fence);
int drm_sched_job_add_implicit_dependencies(struct drm_sched_job *job,
struct drm_gem_object *obj,
bool write);
int drm_sched_job_add_resv_dependencies(struct drm_sched_job *job,
struct dma_resv *resv,
enum dma_resv_usage usage);
int drm_sched_job_add_syncobj_dependency(struct drm_sched_job *job,
struct drm_file *file,
u32 handle,
u32 point);
void drm_sched_job_arm(struct drm_sched_job *job);
static void drm_sched_job_begin(struct drm_sched_job *s_job);
static void drm_sched_job_timedout(struct work_struct *work);
void drm_sched_job_cleanup(struct drm_sched_job *job);
static void drm_sched_job_done(struct drm_sched_job *s_job);
static void drm_sched_job_done_cb(struct dma_fence *f, struct dma_fence_cb *cb);
int drm_sched_job_init(struct drm_sched_job *job,
struct drm_sched_entity *entity,void *owner);
static int drm_sched_main(void *param);
struct drm_gpu_scheduler *
drm_sched_pick_best(struct drm_gpu_scheduler **sched_list,unsigned int num_sched_list);
static bool drm_sched_ready(struct drm_gpu_scheduler *sched);
void drm_sched_resubmit_jobs(struct drm_gpu_scheduler *sched);
void drm_sched_resume_timeout(struct drm_gpu_scheduler *sched,unsigned long remaining);
void drm_sched_rq_add_entity(struct drm_sched_rq *rq,struct drm_sched_entity *entity);
static void drm_sched_rq_init(struct drm_gpu_scheduler *sched,struct drm_sched_rq *rq);
void drm_sched_rq_remove_entity(struct drm_sched_rq *rq,struct drm_sched_entity *entity);
static inline void drm_sched_rq_remove_fifo_locked(struct drm_sched_entity *entity);
static struct drm_sched_entity *
drm_sched_rq_select_entity_fifo(struct drm_sched_rq *rq);
static struct drm_sched_entity * drm_sched_rq_select_entity_rr(struct drm_sched_rq *rq);
void drm_sched_rq_update_fifo(struct drm_sched_entity *entity, ktime_t ts);
static struct drm_sched_entity *drm_sched_select_entity(struct drm_gpu_scheduler *sched);
void drm_sched_start(struct drm_gpu_scheduler *sched, bool full_recovery);
static void drm_sched_start_timeout(struct drm_gpu_scheduler *sched);
void drm_sched_stop(struct drm_gpu_scheduler *sched, struct drm_sched_job *bad);
sched_fence.c
struct drm_sched_fence *drm_sched_fence_alloc(struct drm_sched_entity *entity,
void *owner);
void drm_sched_fence_finished(struct drm_sched_fence *fence);
void drm_sched_fence_free(struct drm_sched_fence *fence);
static void drm_sched_fence_free_rcu(struct rcu_head *rcu);
static const char *drm_sched_fence_get_driver_name(struct dma_fence *fence);
static const char *drm_sched_fence_get_timeline_name(struct dma_fence *f);
void drm_sched_fence_init(struct drm_sched_fence *fence,struct drm_sched_entity *entity);
static void drm_sched_fence_release_finished(struct dma_fence *f);
static void drm_sched_fence_release_scheduled(struct dma_fence *f);
void drm_sched_fence_scheduled(struct drm_sched_fence *fence);
static void drm_sched_fence_set_deadline_finished(struct dma_fence *f,ktime_t deadline);
void drm_sched_fence_set_parent(struct drm_sched_fence *s_fence,struct dma_fence *fence);
static void __exit drm_sched_fence_slab_fini(void);
static int __init drm_sched_fence_slab_init(void);
struct drm_sched_fence *to_drm_sched_fence(struct dma_fence *f);sched_entity.c
static bool drm_sched_entity_add_dependency_cb(struct drm_sched_entity *entity);
static void drm_sched_entity_clear_dep(struct dma_fence *f,struct dma_fence_cb *cb);
void drm_sched_entity_destroy(struct drm_sched_entity *entity);
void drm_sched_entity_fini(struct drm_sched_entity *entity);
long drm_sched_entity_flush(struct drm_sched_entity *entity, long timeout);
int drm_sched_entity_init(struct drm_sched_entity *entity,
enum drm_sched_priority priority,
struct drm_gpu_scheduler **sched_list,
unsigned int num_sched_list,atomic_t *guilty);
static bool drm_sched_entity_is_idle(struct drm_sched_entity *entity);
bool drm_sched_entity_is_ready(struct drm_sched_entity *entity);
static void drm_sched_entity_kill(struct drm_sched_entity *entity);
static void drm_sched_entity_kill_jobs_cb(struct dma_fence *f,struct dma_fence_cb *cb);
static void drm_sched_entity_kill_jobs_work(struct work_struct *wrk);
void drm_sched_entity_modify_sched(struct drm_sched_entity *entity,
struct drm_gpu_scheduler **sched_list,
unsigned int num_sched_list);
struct drm_sched_job *drm_sched_entity_pop_job(struct drm_sched_entity *entity);
void drm_sched_entity_push_job(struct drm_sched_job *sched_job);
void drm_sched_entity_select_rq(struct drm_sched_entity *entity);
void drm_sched_entity_set_priority(struct drm_sched_entity *entity,
enum drm_sched_priority priority);
static void drm_sched_entity_wakeup(struct dma_fence *f,struct dma_fence_cb *cb);
static struct dma_fence *drm_sched_job_dependency(struct drm_sched_job *job,
struct drm_sched_entity *entity);主要接口TRACE
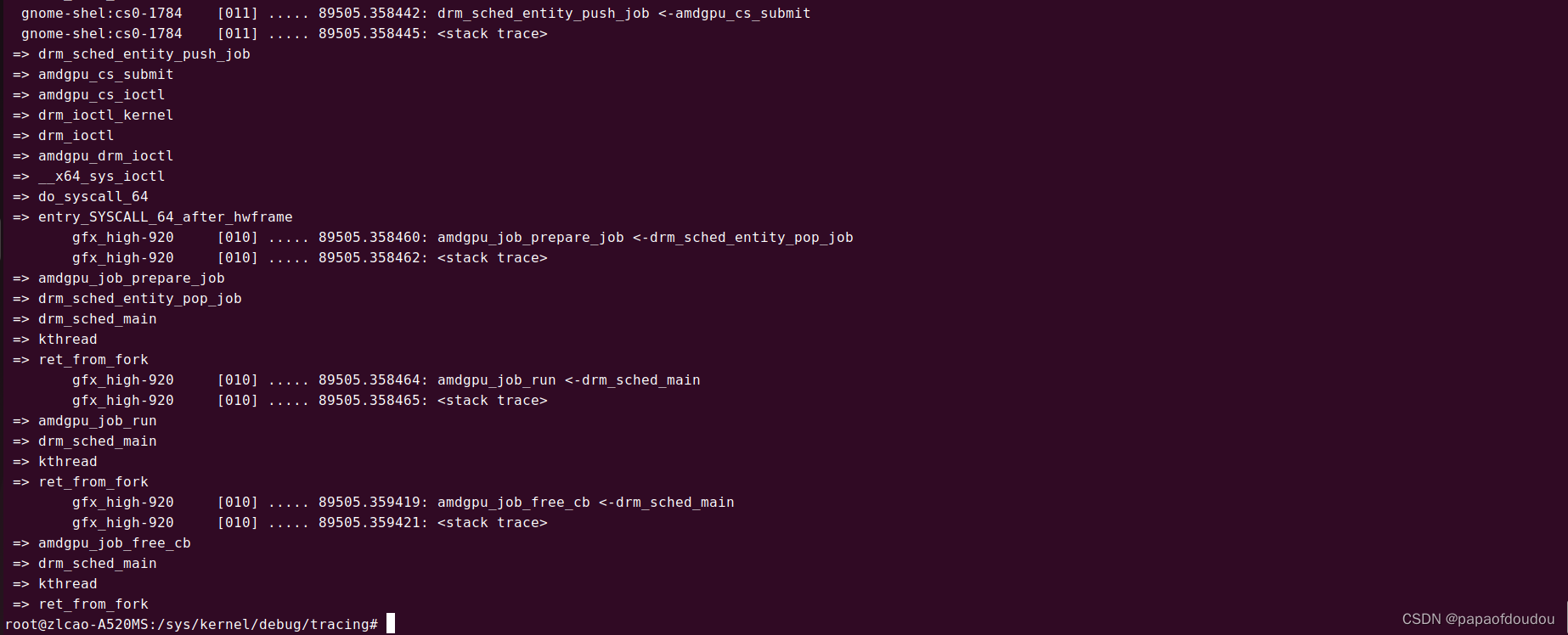
drm_sched_entity_push_job接口用于向GPU发送命令包去执行,尝试追踪其调用堆栈,DRM字符设备操作函数和DRM驱动函数之间建立桥接联系,当通过标准的字符设备驱动调用到KMS驱动后,就可以将驱动转化为DRM框架内部的调用,调动DRM驱动框架的资源驱动GPU,为用户渲染应用服务。


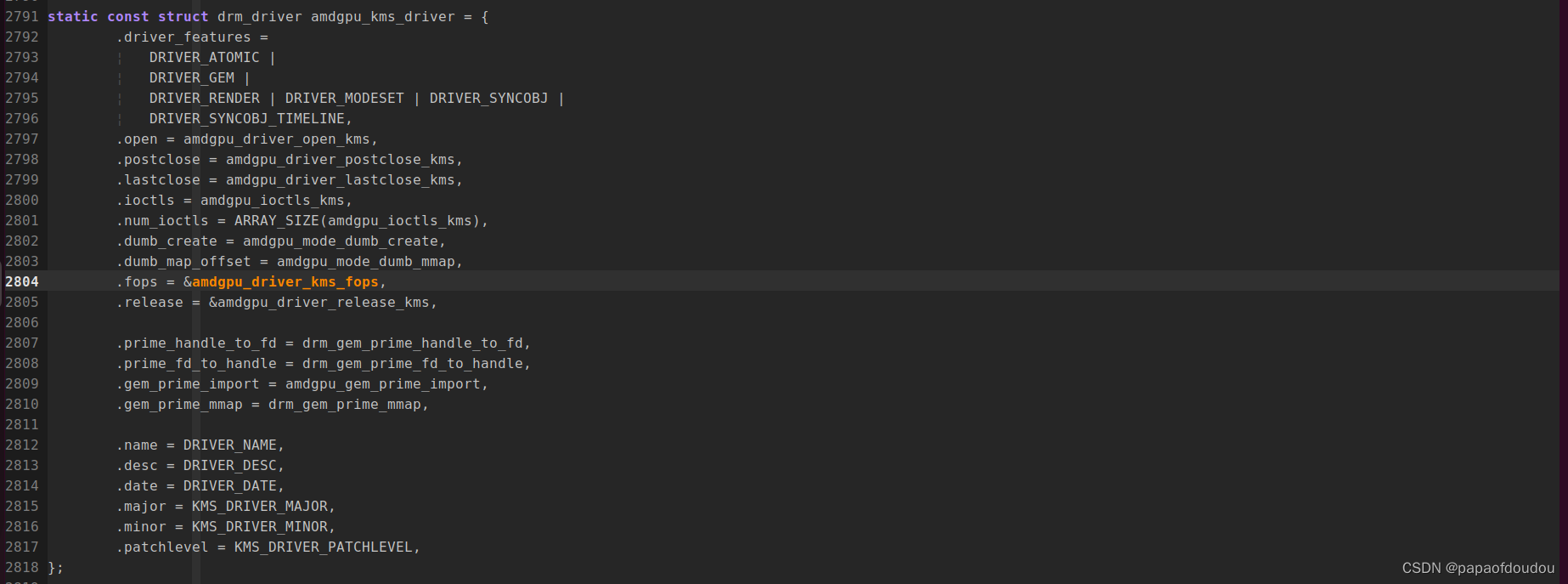
GPU命令执行上下文是由amdgpu_job_run驱动的,其调用上下文是gpu_sched.ko中创建的drm_sched_main内核线程。
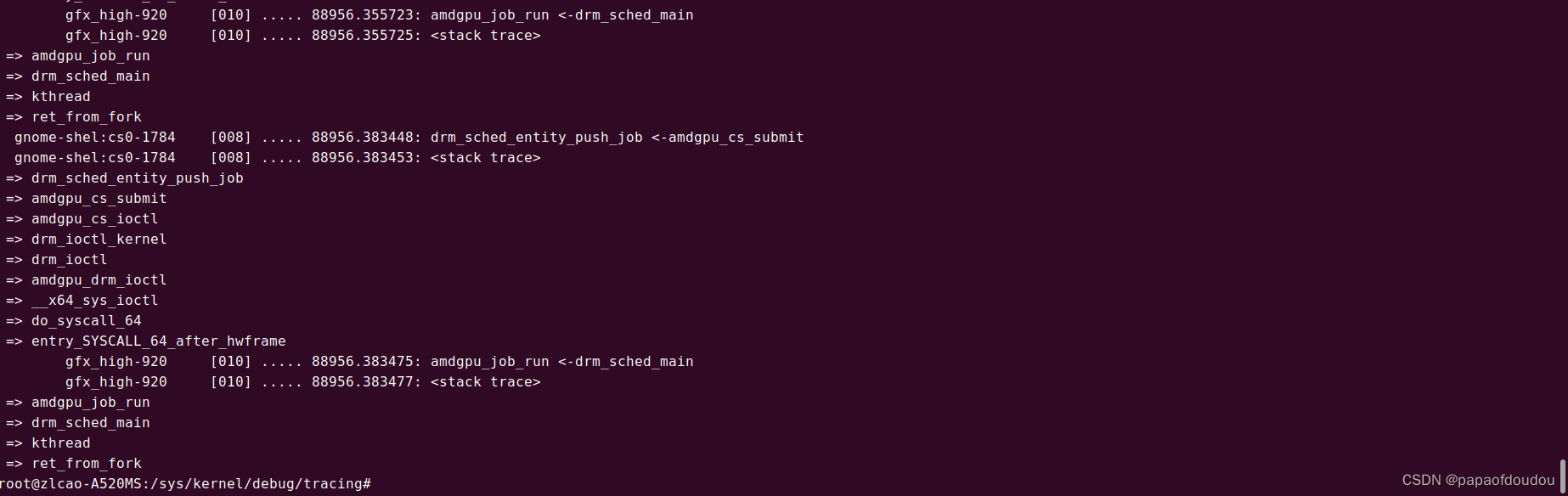
下图是抓到的一个命令包的调度执行周期,命令包首先由用户应用发起调用,在DRM上下文中调用drm_sched_entity_push_job命令包推入命令队列,完成发射。
之后在gpu_sched模块的内核线程中,完成准备,执行,释放的命令执行周期。
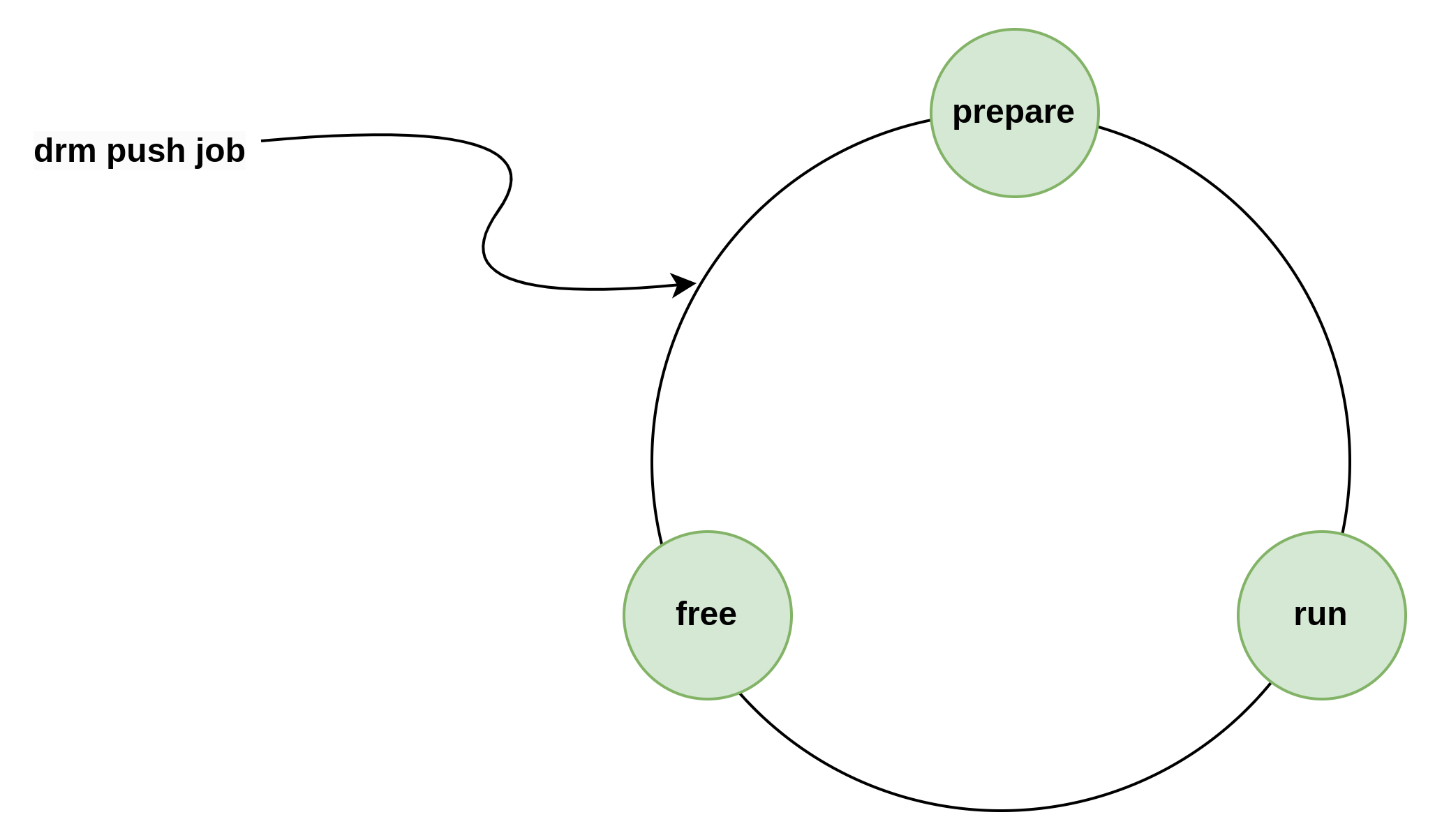

GFX渲染通道工作模型
GPU中广泛使用ringbuffer进行CPU和GPU之间的数据和命令交互,RINGBUFFER的好处是,它可以解决CPU和GPU之间无限的数据通信和有限的存储空间之间的矛盾,并且自带反压机制,尽可能的减少了对系统环境的影响。
GPU接收CPU发送的渲染命令,执行相应的计算,渲染命令在CPU和GPU之间传递,由CPU发送给GPU。AMD的GPU有两种命令发送方式,第一种是CPU通过直接写GPU的寄存器,发送相应的渲染命令,对于GPU来说,这种方式是CPU将命令push给自己,然后开始工作,被称为push模式;第二种是系统初始化时CPU在主存上分配一块内存,用作存放GPU的渲染命令,当CPU有渲染需求时就往这块内存写命令并通知GPU读取,这种方式对GPU来说,需要主动去主存上把渲染命令pull过来,然后开始工作,被称为pull模式。通常情况下AMD都建议使用pull模式,只有系统内存不适合pull模式时采用push模式。无论哪种模式,都需要在HOST和GPU之间建立命令QUEUE,AMDGPU中对应的数据实体叫做ring.
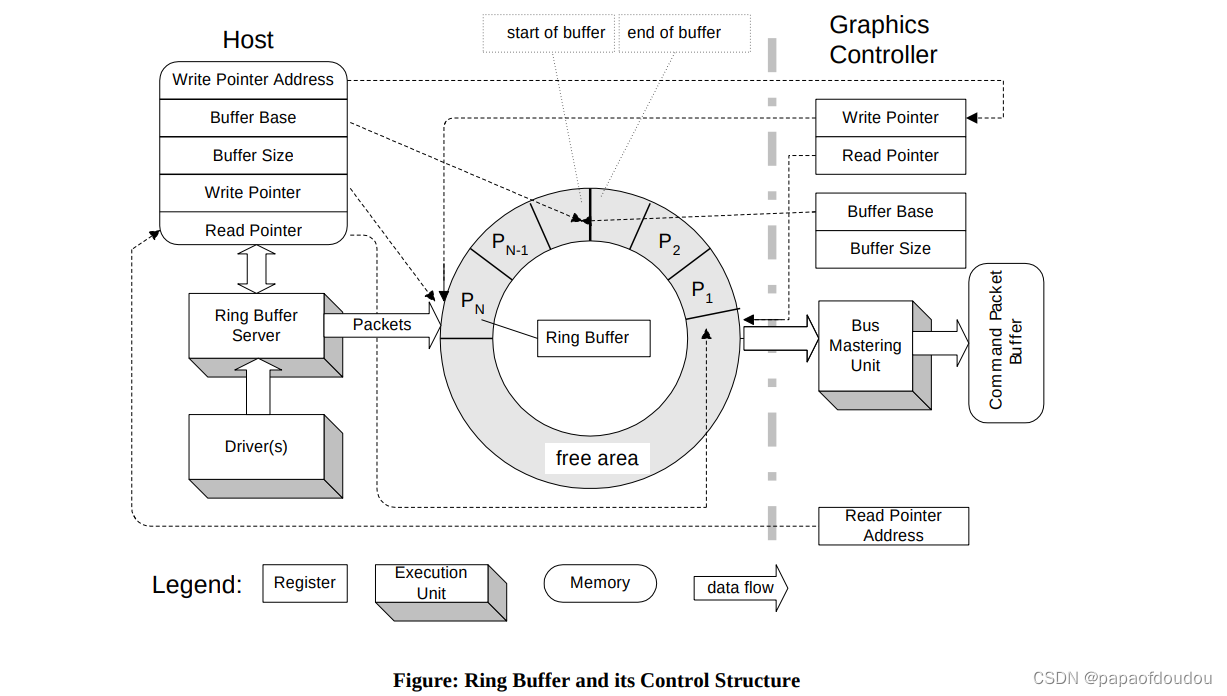
工作模型示意图如下:
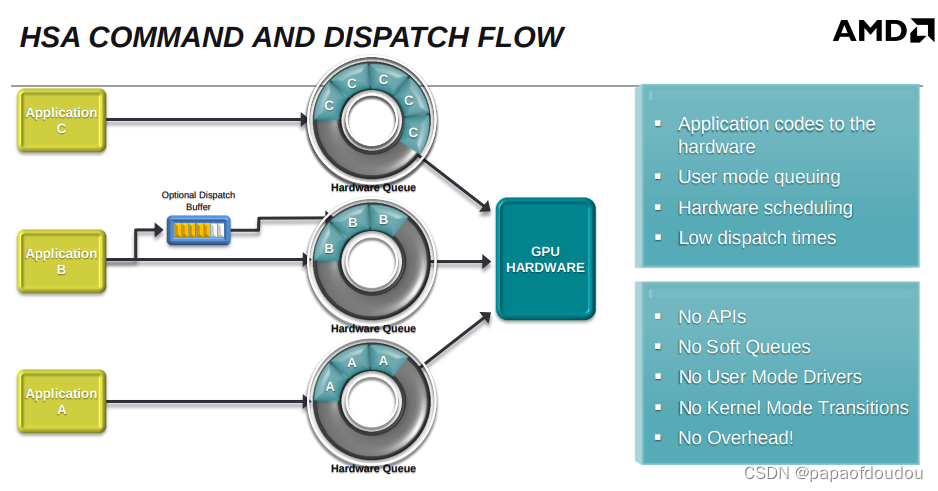
trace gfx渲染通道:
AMDGPU有不同的架构,并且同一种架构下有多个子版本, 内核驱动针对每个子版本都有定义一套独立的backend handler,经过多次尝试,最终找到了针对R5600G核显上的渲染 HANDLER。


为何在应用程序进行视频解码的时候,AMDGPU的UVD RING没有检测到活跃?这是一个疑问,不过后来尝试分析了mplayer解码时系统的负载分布,找到了这个问题的答案,原来mplayer解码用的是CPU软解,步骤如下:
1.尝试将mplayer解码进程固定在指定CPU上运行,方便后续进行系统监测。
$ taskset 0x2 mplayer '/home/zlcao/下载/The.Godfather.Part2.Blu-ray.720p.x264.DD51-HiS@MySiLU.mkv'
$ taskset -p `pidof mplayer`
pid 4910 的当前亲和力掩码:2
$
2.此时从各个CPU的负载情况来看,已经略见端倪,只有CPU 1的用户态占比较高,其它CPU基本上没有负载在跑。当然现的大部分处理器性能都是过剩的,单个CPU16%负荷并不算多,但是这里也要看到16%几乎全部是多媒体解码的线程的CPU占用,所以从这个角度来看,大概可以推测出当前场景使用的是软解方案。

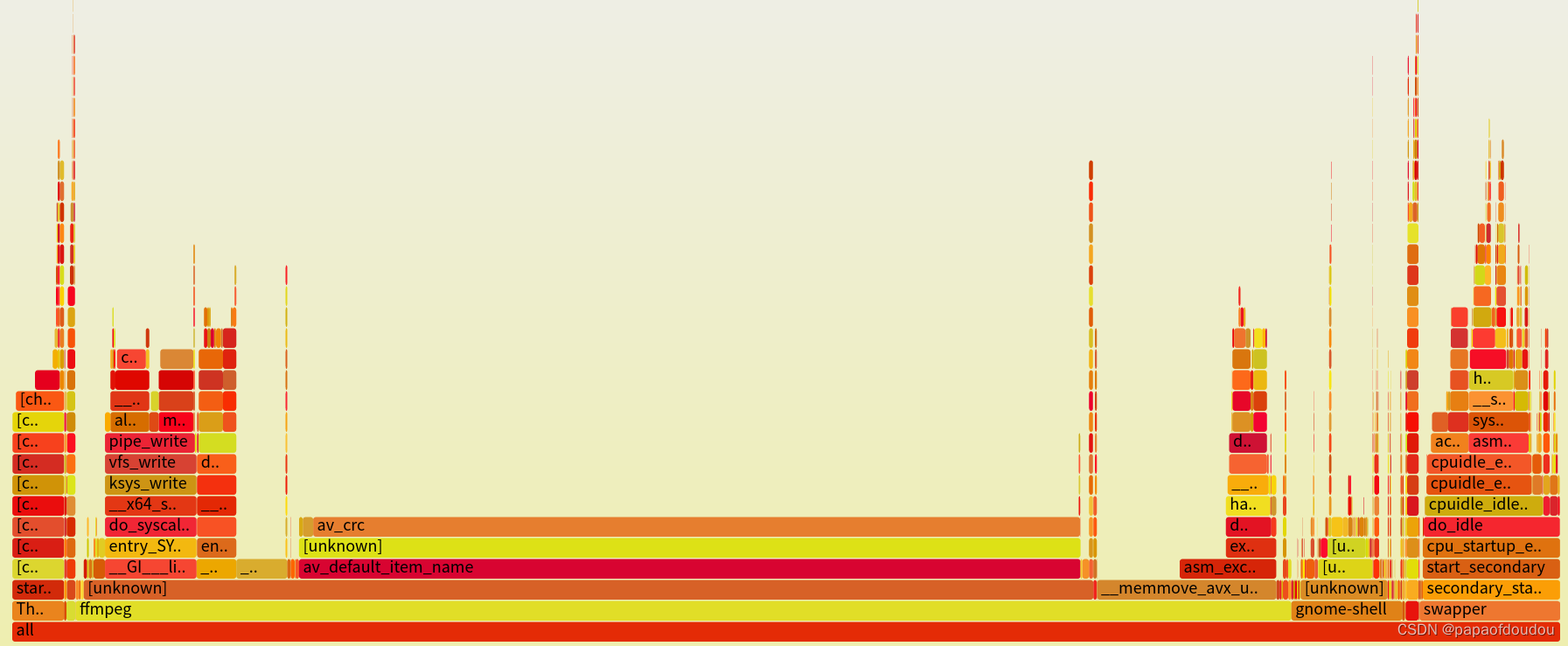
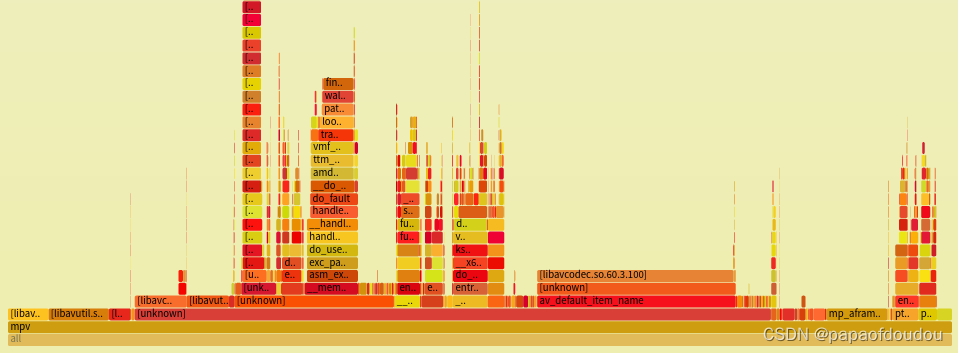
3.为了作实场景为软解场景,用火焰图分析,只抓CPU 1的负载情况,可以看到解码堆栈只发生在用户态,调用了libavcodec库中的接口,而这个接口来自于FFMPEG,也就是是说,mplayer是基于FFMPEG实现的。
$ sudo perf record -C 1 -g -e cpu-clock -e instructions -e cycles -F 999 -- sleep 30
$ sudo perf script -i perf.data &> perf.unfold
$ sudo ./FlameGraph/stackcollapse-perf.pl perf.unfold &> perf.folded
$ sudo ./FlameGraph/flamegraph.pl --title="mplayer playing flamegraph" perf.folded > perf.svg
这样澄清在运行解码应用时,内核中没有TRACE到AMDGPU UVD驱动被调用的问题,但是仍然不知道怎样做才能TRACE到UVD驱动被调用,或许只能到社区问一下了。
后面经过向AMD社区请教,搞清楚了触发利用AMDGPU进行视频硬解码的方式,R5600G核显是 AMD VEGA7, 代号为Renoir,这一代GPU集成了AMD新的视频编解码IP VCN, VCN 的全称为 Video Core Next / 下一代视频核心,VCN相关信息在如下网址:
https://en.wikipedia.org/wiki/Video_Core_Next
验证方法如下:
AMDGPU VIDEO解码加速
AMDGPU提供了VAAPI和VADPU两套解码API,最新版本的FFMPEG已经支持,但是前提是需要系统安装了AMDGPU的VAAPI加速库。使用如下命令查看:
vainfo --device /dev/dri/renderD128 --display drm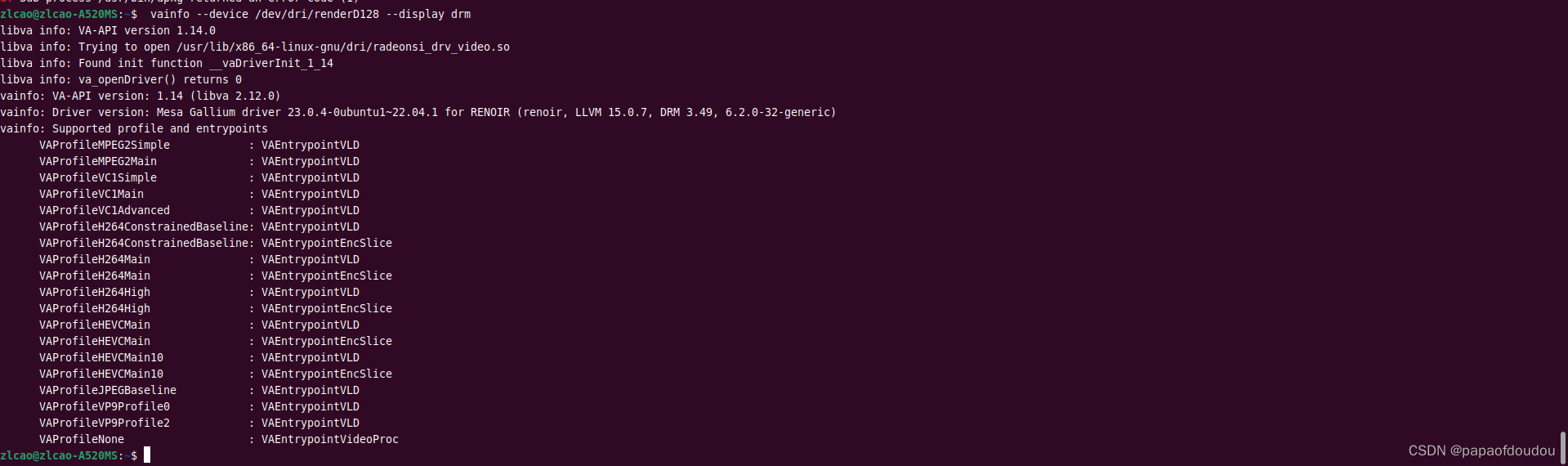
可以看到系统中已经随MESA安装了/usr/lib/x86_64-linux-gnu/dri/radeonsi_drv_video.so,确认这一点后,使用如下命令启用VAAPI GPU硬解码加速:
ffmpeg -hwaccel vaapi -hwaccel_device /dev/dri/renderD128 -i ./godfather.mkv -vcodec rawvideo -acodec copy -f matroska - | ffplay -i -此时系统解码时 ,CPU占用率极低,这是个好消息,意味着VAAPI硬解码应该是成功开启了。
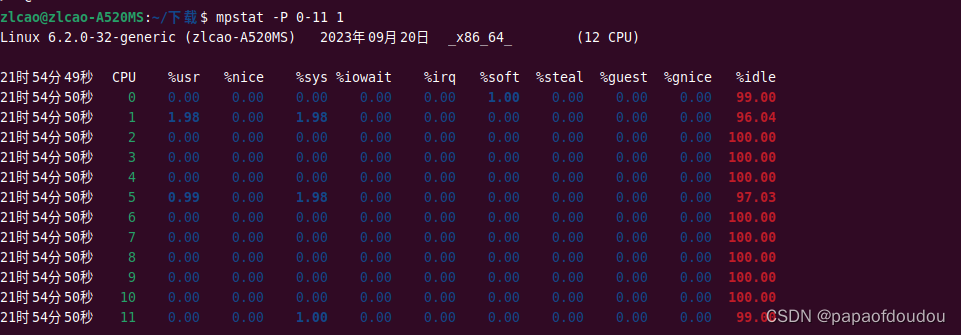
火焰图中显示解码应用有连接GPU加速后段库radeonsi_drv_video.so.

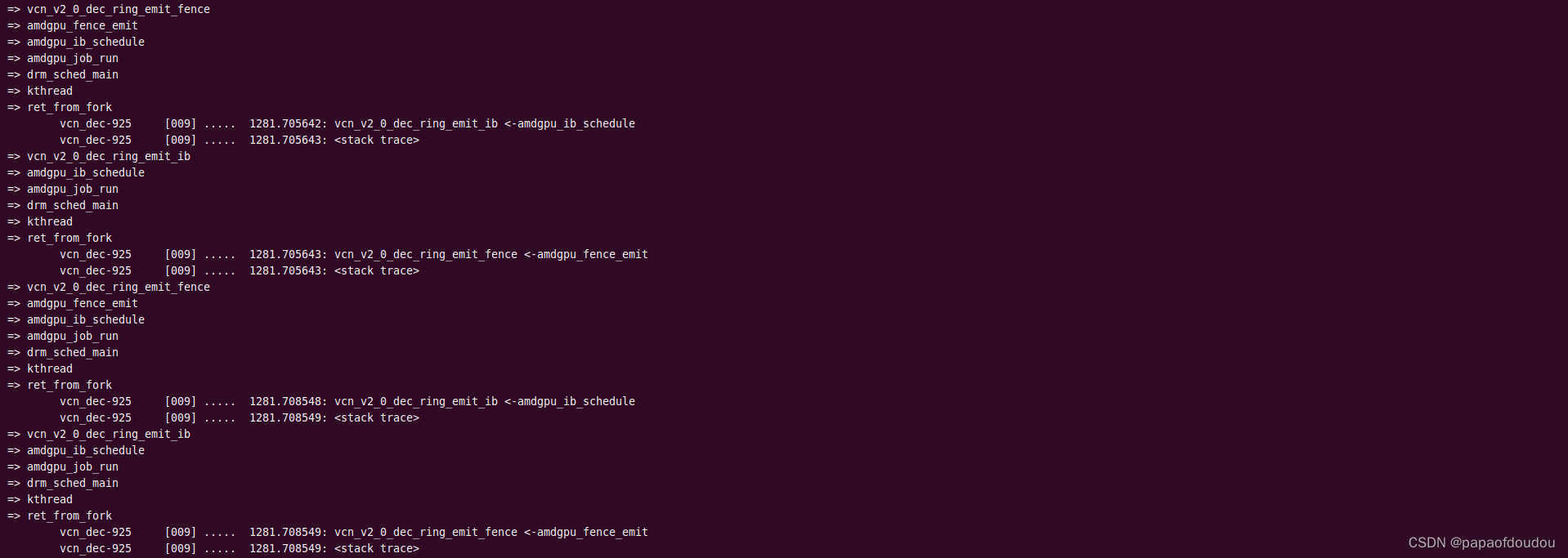
启用硬件解码后,再次追踪VCN(Video Codec Next, AMDGPU最新一代解码器,前面追踪的UVD(Unified Video Decoder)已经是过去时了,R5600G集成的是VCN 视频解码器,下图显示的是AMDGPU调度VIDEO 解码的IB包时的调用堆栈,调度线程名称为“vcn_dec-%d",区别于渲染通道的"gfx_high-%d",从线程名字可以看出解码加速确实使用的是VCN。
mpv player 以--hwdec=vaapi参数启动,使能GPU硬件加速,同样可以利用AMDGPU的硬解码能力。
$ taskset 0x2 mpv --hwdec=vaapi godfather.mkv 
FFMPEG GPU转码加速
使用FFMEG硬解码,在使用 FFmpeg 进行解码时,需要指定使用硬解码,并且指定相应的解码器。例如,如果要使用 VA-API 进行 H.264 解码,指定-hwaccel vaapi.之后使用libx264进行编码。
fmpeg -hwaccel vaapi -hwaccel_device /dev/dri/renderD128 -i ./godfather.mkv -c:v libx264 output.mp4
主流显卡上视频解码器方案

以NVIDIA为例,它的多媒体BLOCK实现如下:
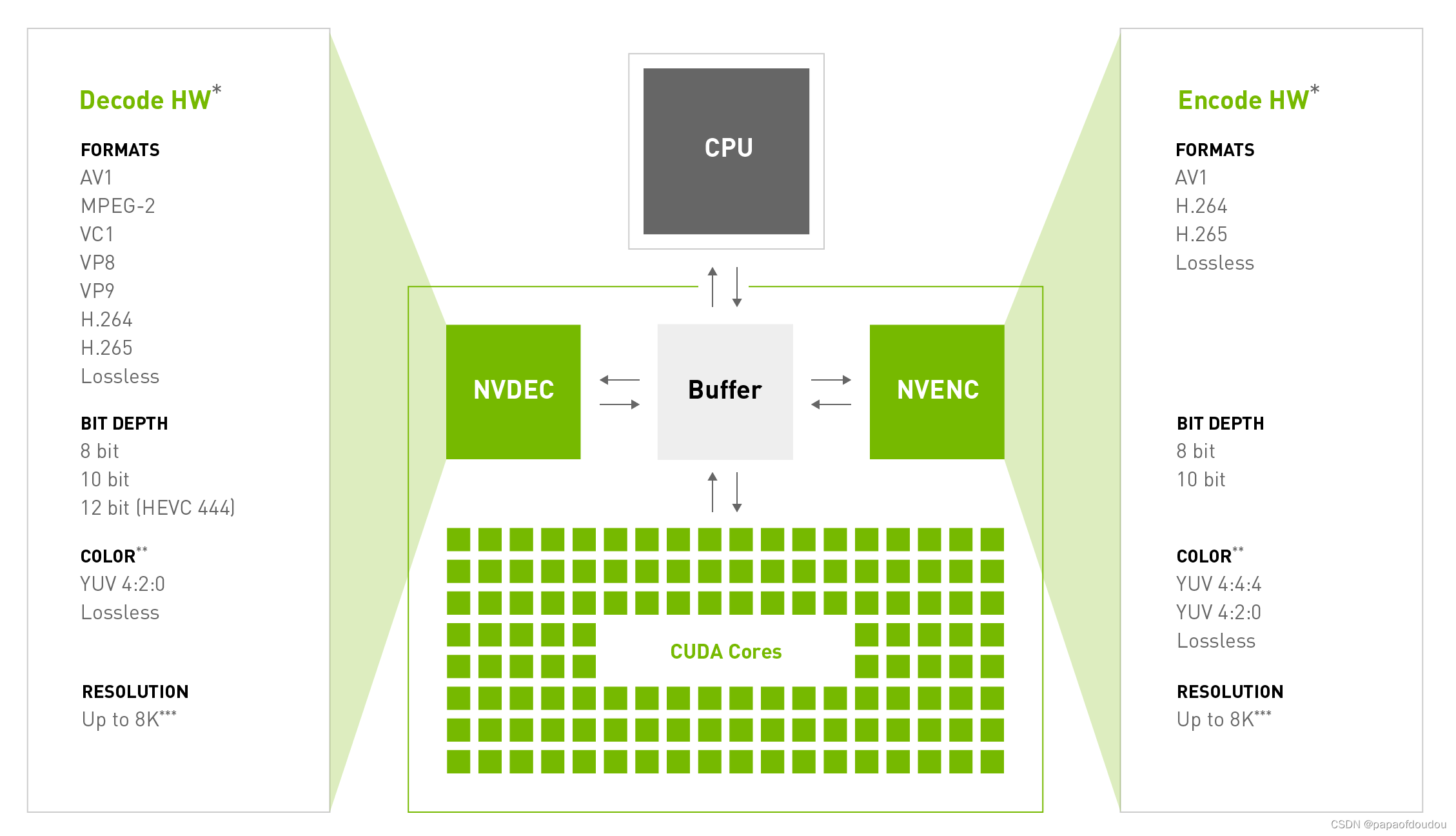

Video Code SDK | NVIDIA Developer
根据网上的公开评测,几款视频编解码的性能对比是:
英特尔的QUICKSYNC(编+解)>英伟达的NVENC(编)/NVDEC(解)>AMD的VCN(编+解)。
为什么GPU中集成VideoCodec?
GPU有强大的并行计算能力,而VIDEO编解码的核心算法DCT/IDCT则是并行计算中广泛使用的,并被深入优化的矩阵计算的一种,也就是说,在视频处理方面,GPU比CPU天然具备优势,那为什么还要在GPU中多此一举的集成专用的VIDEO CODEC IP呢?
还是回到在计算机领域中被广泛使用的那句话,专业的事交给专业的人去做,专业的ASIC CODEC比通用的并行加速计算具有更高的效能比,所以GPU通用并行计算+VIDEO CODEC ASIC解码才是最佳组合。在这里,计算机领域的2/8定律再次发挥作用。
其实在FFMPEG中,虽然默认情况下使用的VAAP使用的是GPU中的VIDEO CODEC ASIC作为解码后端,但是FFMPEG已经支持了基于CUDA通用计算的加速方式作为解码后端,只要启动FFMPEG时传入对应参数,即可将解码加速的后端切换为CUDA KERNEL核函数解码加速。
RING初始化
ring的个数,可以通过发送AMDGPU_INFO_HW_IP_INFO调用内核接口amdgpu_hw_ip_info查询每个IP BOLOCK的资源个数。


查看系统进程,发现AMDGPU 内核调度器相关的进程有如下几个,其中有1个SDMA,两个GFX,一个Video decoder和两个video encoder ring.



基本上每个调用amdgpu_ring_init的地方,都会对应一个RING的初始化。支持的RING类型包括以下这些类型:

EOP Packet
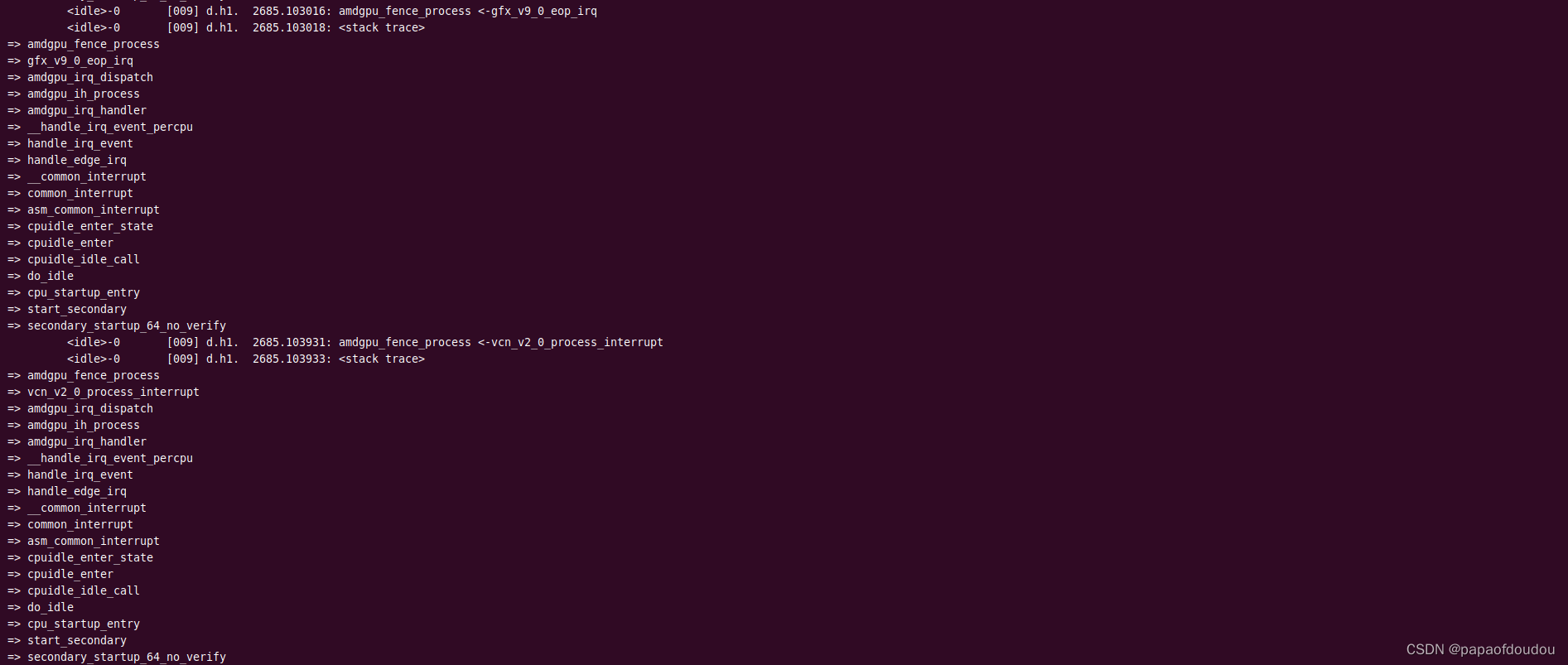
当一组渲染命令完成,或者一个视频帧被解码完成后,会调用对应模块的中断处理函数,在中断处理函数中调用amdgpu_fence_process singal当前完成JOB对应fence.
AMDGPU解码的工作模型总结如下:
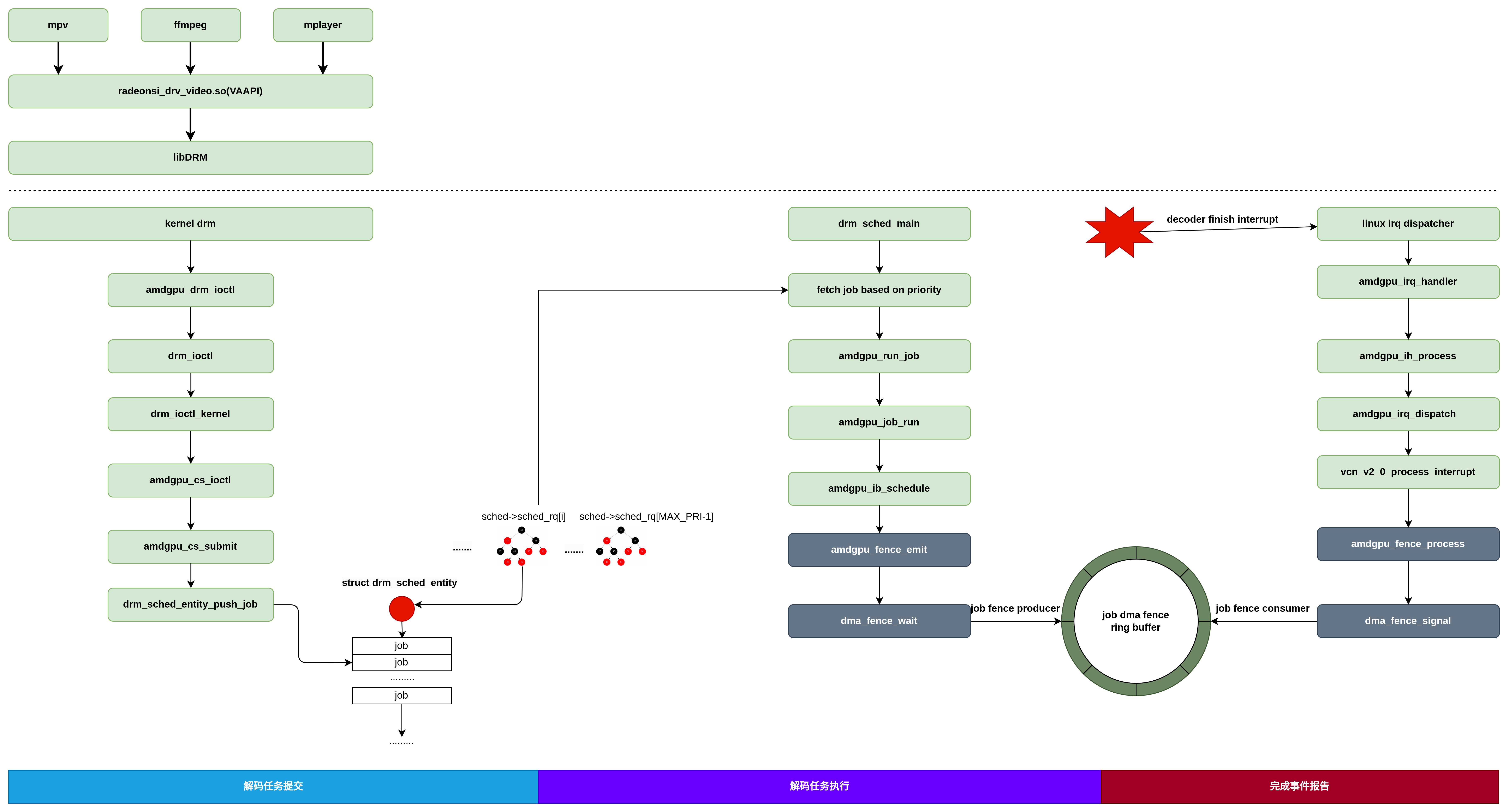
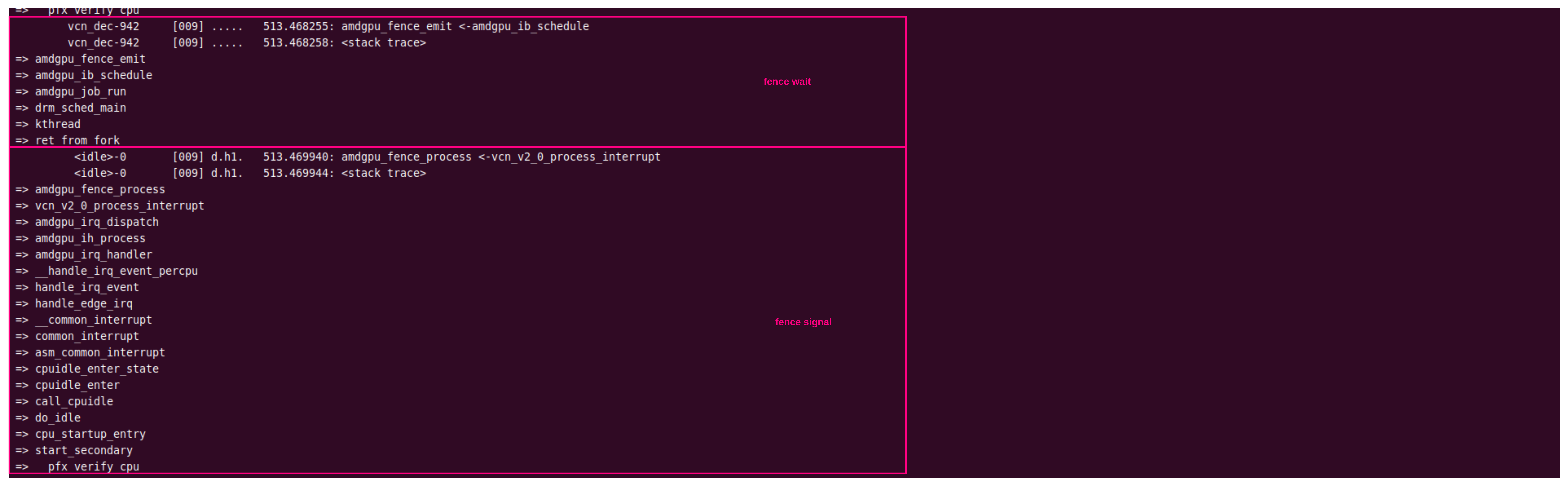
以上是对AMDGPU视频ring和渲染ring的初步分析。
doorbell:
doorbell是一种软件向硬件的通知机制,在底层编成中其实广泛存在,比如在嵌入式编成中,它类似于寄存器TRIGGER的动作,软件触发寄存器的TRIGGER后,硬件就会动起来,只不过除了通知硬件功能外,DB机制还可以携带更多的信息,比如任务位置等信息。
doorbell可以类比于中断,中断是硬件给软件的doorbell, doorbell是软件给硬件的中断。
Host端通过doorbell机制通知GPU执行操作
amdgpu_mm_wdoorbell64/amdgpu_mm_wdoorbell分别是GFX和video codec ring设置doorbell的接口,trace如下:


GPU中断控制器和KMD之间也是通过doorbell机制实现的通信,只不过和Ring不同的是,AMDGPU驱动的中断ring属于消费者,而硬件作为生产者,则更新wptr.在GPU发生中断后,通过中断机制将读指针位置返回给HOST主机端。

参考文档
AMD GPU任务调度(1)—— 用户态分析_amd gpu util-CSDN博客
https://www.cs.unc.edu/~otternes/papers/rtsj2022.pdf
https://en.wikipedia.org/wiki/Video_Core_Next
https://www.codenong.com/cs106658889/



















 1432
1432

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











