






在这篇文章中,我将向大家展示如何将预训练的大语言模型(LLM)打造成强大的文本分类器。
但为什么要专注于分类任务呢?首先,将预训练模型微调为分类器,是学习模型微调的一个简单且有效的入门方式。其次,在现实生活和商业场景中,许多挑战都围绕文本分类展开,比如垃圾邮件检测、情感分析、客户反馈分类、主题标注等。
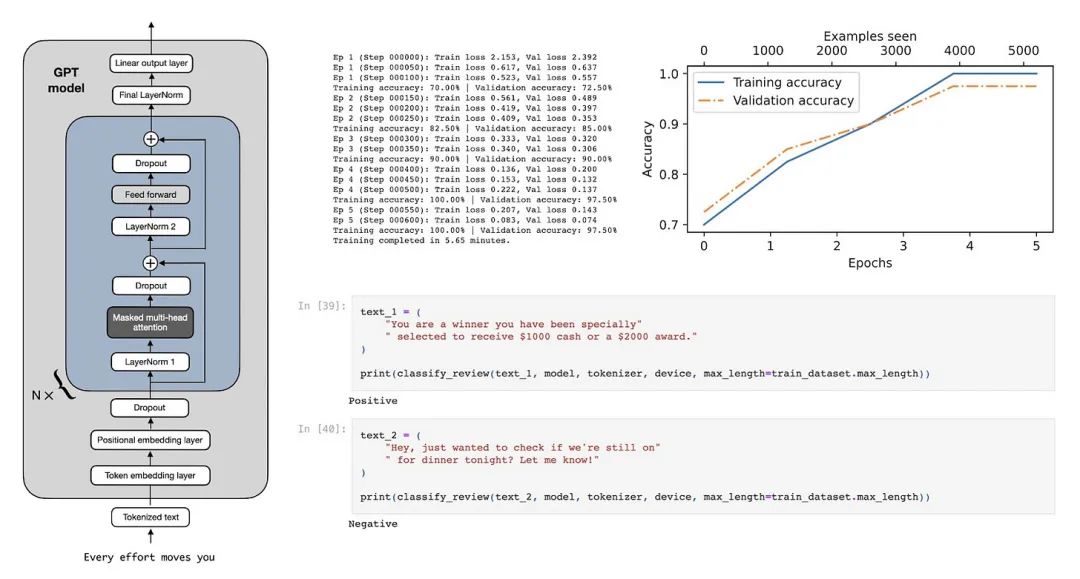 将 GPT 模型转变为文本分类器
将 GPT 模型转变为文本分类器
我的新书发布!
我非常激动地宣布,我的新书《Build a Large Language Model From Scratch》已经由 Manning 出版社正式发布,中文版也很快要跟大家见面(预计2月底)。

在我的经验中,理解一个概念最深刻的方式就是从零开始构建它。这本书耗时近两年打磨,在书中我将带着你从头开始构建一个类似 GPT 的大语言模型,包括实现数据输入以及使用指令数据进行微调。我的目标是,在读完这本书之后,你能够深入、全面地了解 LLM 的工作原理。
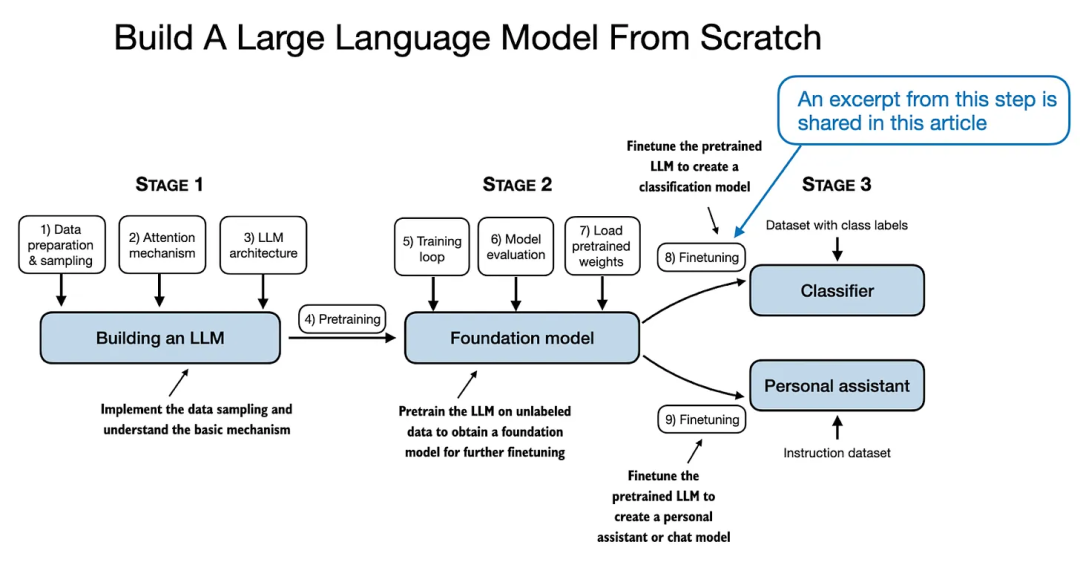
本文主要内容
为了庆祝新书发布,我将分享书中一个章节的节选,带你一步步完成如何微调预训练 LLM,使其成为一个垃圾邮件分类器。
重要提示
书中关于分类任务微调的章节共有 35 页,内容较多,不适合一次性在文章中全部呈现。因此,本篇文章将聚焦于其中约 10 页的核心内容,帮助你了解分类微调的背景和核心概念。
此外,我还会分享一些书中未涉及的其他实验见解,并解答读者可能提出的常见问题。(需要注意的是,以下节选基于我的个人草稿,尚未经过 Manning 的专业编辑或最终设计。)
文章完整代码可以在https://github.com/rasbt/LLMs-from-scratch/blob/main/ch06/01_main-chapter-code/ch06.ipynb 中找到。
7 个关于训练 LLM 分类器的常见问题
我们需要训练所有层吗?
为什么选择微调最后一个 token,而不是第一个?
BERT 和 GPT 在性能上有何区别?
我们是否应该禁用因果掩码(causal mask)?
增大模型规模会带来什么影响?
使用 LoRA(低秩适配)能带来哪些改进?
是否需要填充(padding)?
祝阅读愉快!
微调的不同类型
微调语言模型最常见的方式包括指令微调(instruction finetuning)和分类微调(classification finetuning)。
指令微调的核心是通过一组任务对语言模型进行训练,并使用具体的指令来提升模型理解和执行自然语言提示中任务的能力。下图(图 1)展示了这一过程的基本原理。
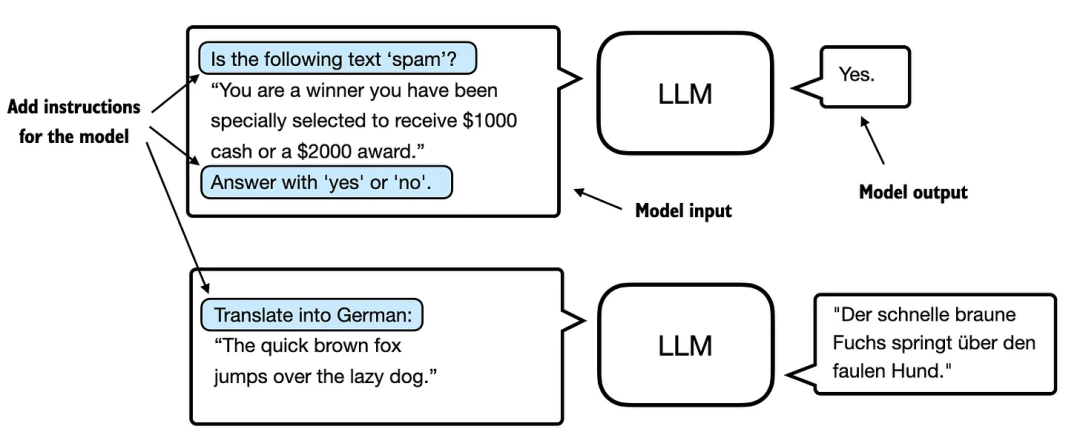 图 1:两种不同指令微调场景的说明。上方的模型任务是判断给定文本是否为垃圾邮件,下方的模型则被赋予将英文句子翻译成德语的指令。
图 1:两种不同指令微调场景的说明。上方的模型任务是判断给定文本是否为垃圾邮件,下方的模型则被赋予将英文句子翻译成德语的指令。
下一章将讨论图 1 中所示的指令微调内容。而本章则聚焦于分类微调,这个概念如果你有机器学习的背景,可能已经有所了解。
在分类微调中,模型被训练来识别一组特定的类别标签,例如“垃圾邮件”和“非垃圾邮件”。分类任务不仅限于大语言模型和电子邮件过滤,还包括从图像中识别不同植物种类、将新闻文章分类为体育、政治或科技等主题,以及在医学影像中区分良性和恶性肿瘤等。
重点在于,经过分类微调的模型只能预测它在训练中遇到过的类别。例如,它可以判断某件事物是否是“垃圾邮件”或“非垃圾邮件”,如图 2 所示,但除此之外无法对输入文本作出其他判断。
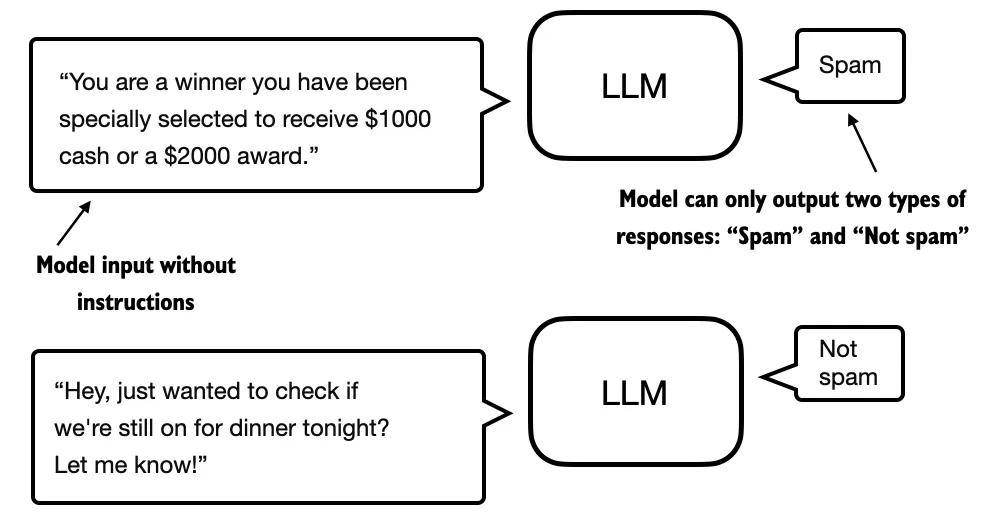 图 2:使用 LLM 进行文本分类场景的说明。一个针对垃圾邮件分类微调的模型不需要额外的指令来处理输入。然而,与指令微调模型相比,它只能给出“垃圾邮件”和“非垃圾邮件”的回应。
图 2:使用 LLM 进行文本分类场景的说明。一个针对垃圾邮件分类微调的模型不需要额外的指令来处理输入。然而,与指令微调模型相比,它只能给出“垃圾邮件”和“非垃圾邮件”的回应。
与图 2 所示的分类微调模型相比,指令微调模型通常能够承担更广泛的任务。我们可以将分类微调模型看作是高度专业化的模型,而开发一个能很好地处理多种任务的通用模型通常比开发一个专门模型更具挑战性。
选择合适的方法
指令微调提高了模型根据用户特定指令理解和生成回应的能力。它更适合需要根据复杂用户指令处理各种任务的模型,从而提高模型的灵活性和交互质量。而分类微调则适用于需要将数据精确分类为预定义类别的项目,例如情感分析或垃圾邮件检测。
尽管指令微调用途更广,但它需要更大的数据集和更多的计算资源来开发擅长多种任务的模型。而分类微调则需要较少的数据和计算资源,但其用途仅限于模型训练时涉及的特定类别。
使用预训练权重初始化模型
由于这是一个节选,我们将跳过数据准备和模型初始化的部分,这些内容已经在前几章中进行了实施和预训练。根据我的经验,与纸质书相比,阅读较长的数字文章时保持专注可能会更具挑战性。因此,我会尽量让这部分节选内容紧紧围绕本章的关键要点。
为了给这部分节选提供一些背景信息,这段内容主要聚焦于将一个通用的预训练大语言模型转变为专门用于分类任务的模型所需的修改,如图 3 所示。
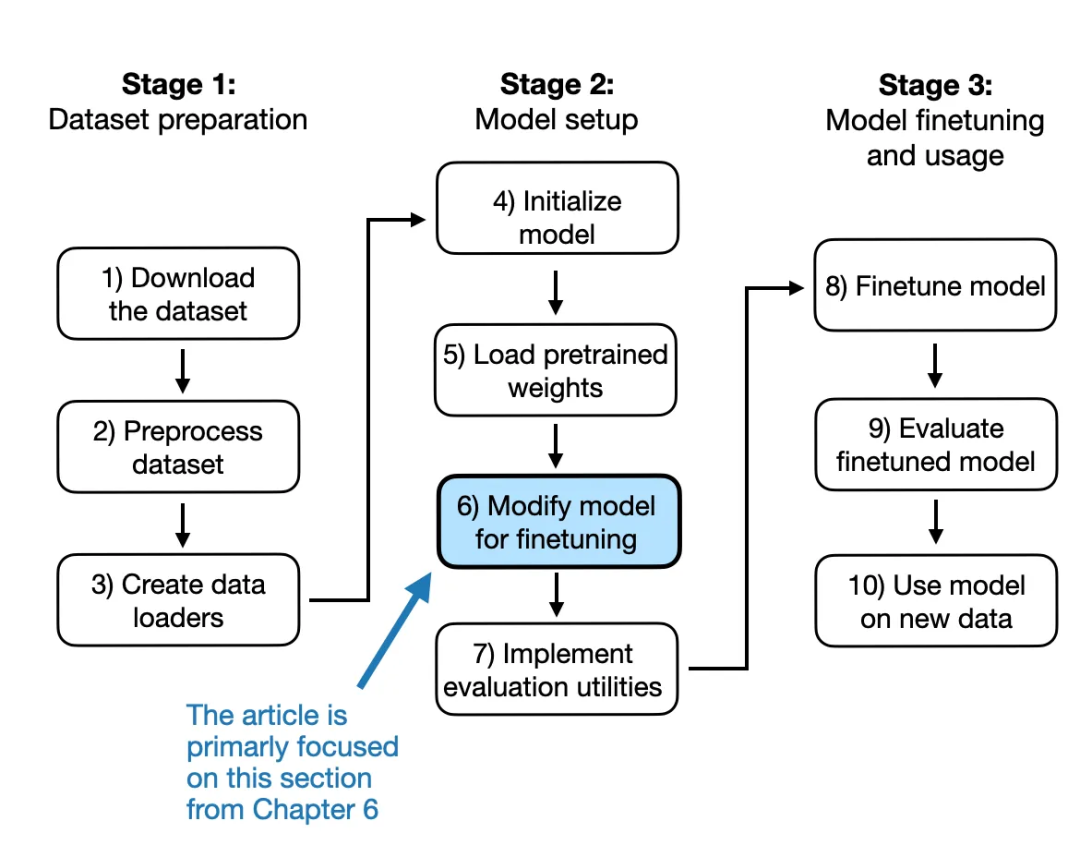 图 3:在这部分节选中,我们跳过步骤 1-5,直接进入第 6 步(从下一节开始)。
图 3:在这部分节选中,我们跳过步骤 1-5,直接进入第 6 步(从下一节开始)。
但在进行图 3 中提到的 LLM 修改之前,我们先简要了解一下我们正在使用的预训练 LLM。
为了简化讨论,我们假设已经设置好加载模型的代码,流程如下:
model = GPTModel(BASE_CONFIG)
load_weights_into_gpt(model, params)
model.eval()在将模型权重加载到 GPTModel 后,我们使用前几章中的文本生成工具函数,确保模型能够生成连贯的文本:
from chapter04 import generate_text_simple
from chapter05 import text_to_token_ids, token_ids_to_text
text_1 = "Every effort moves you"
token_ids = generate_text_simple(
model=model,
idx=text_to_token_ids(text_1, tokenizer),
max_new_tokens=15,
context_size=BASE_CONFIG["context_length"]
)
print(token_ids_to_text(token_ids, tokenizer))从以下输出中可以看出,模型生成了连贯的文本,这表明模型权重已正确加载:
Every effort moves you forward.
The first step is to understand the importance of your work现在,在开始将模型微调为垃圾邮件分类器之前,我们先试试通过提示给出指令,看看模型是否已经可以将垃圾邮件进行分类:
text_2 = (
"Is the following text 'spam'? Answer with 'yes' or 'no':"
" 'You are a winner you have been specially"
" selected to receive $1000 cash or a $2000 award.'"
)
token_ids = generate_text_simple(
model=model,
idx=text_to_token_ids(text_2, tokenizer),
max_new_tokens=23,
context_size=BASE_CONFIG["context_length"]
)
print(token_ids_to_text(token_ids, tokenizer))模型输出如下:
Is the following text 'spam'? Answer with 'yes' or 'no': 'You are a winner you have been specially selected to receive $1000 cash or a $2000 award.'
The following text 'spam'? Answer with 'yes' or 'no': 'You are a winner根据输出可以明显看出,模型在执行指令时存在困难。
这是预料之中的,因为模型仅经过预训练,并未进行指令微调,我们将在接下来的章节中探讨这一点。
下一节将为分类微调准备模型。
添加分类头
在本节中,我们将修改预训练的大语言模型,为分类微调做好准备。具体来说,我们将原始输出层(将隐藏表示映射到包含 50,257 个唯一 token 的词汇表)替换为一个较小的输出层,该输出层将隐藏表示映射到两个类别:0(“非垃圾邮件”)和 1(“垃圾邮件”),如图 4 所示。
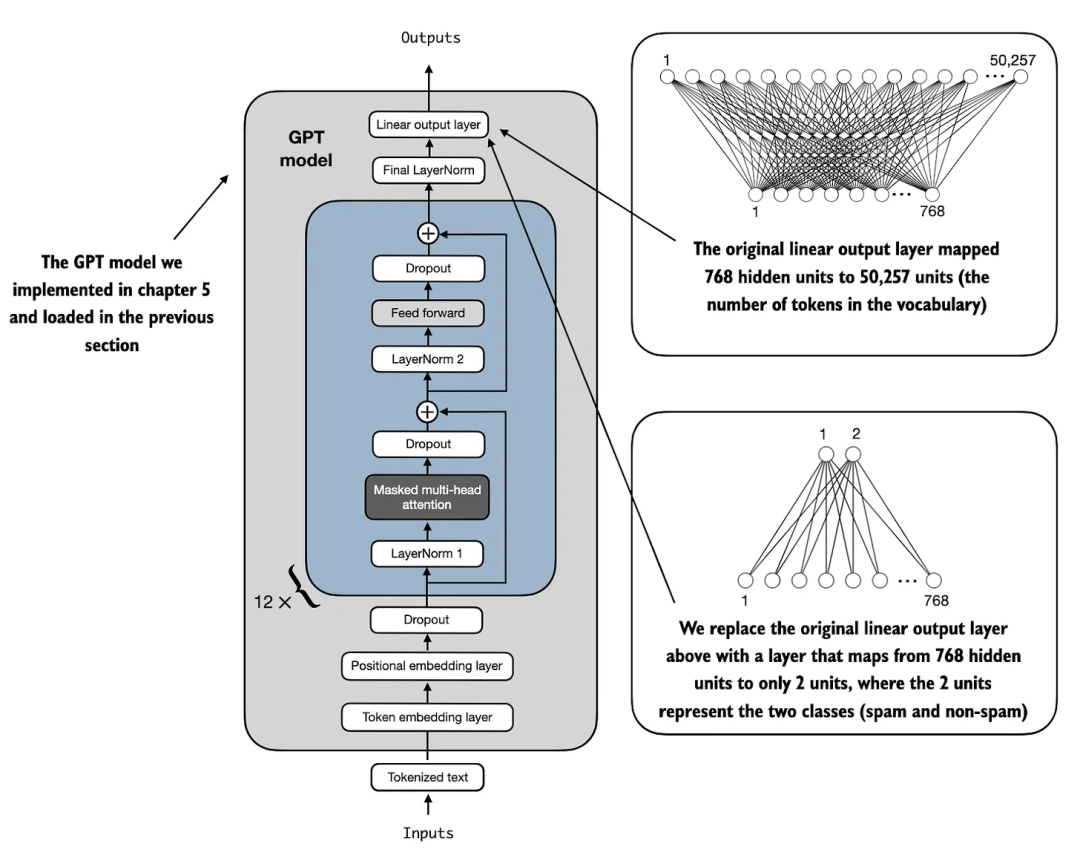 图 4 展示了通过修改架构将 GPT 模型适配为垃圾邮件分类器。最初,模型的线性输出层将 768 个隐藏单元映射到包含 50,257 个 token 的词汇表中。而在垃圾邮件检测任务中,这个输出层被替换为新的输出层,将相同的 768 个隐藏单元映射到两个类别,分别代表“垃圾邮件”和“非垃圾邮件”。
图 4 展示了通过修改架构将 GPT 模型适配为垃圾邮件分类器。最初,模型的线性输出层将 768 个隐藏单元映射到包含 50,257 个 token 的词汇表中。而在垃圾邮件检测任务中,这个输出层被替换为新的输出层,将相同的 768 个隐藏单元映射到两个类别,分别代表“垃圾邮件”和“非垃圾邮件”。
如上图 4 所示,除了替换输出层外,我们使用的模型与前几章中的相同。
输出层节点
由于我们处理的是一个二分类任务,技术上我们可以只使用一个输出节点。然而,这需要修改损失函数,这部分内容已在附录 B 的参考文献中讨论过。因此,我们选择了一种更通用的方法,即输出节点的数量与类别数量相匹配。例如,对于一个三分类问题,如将新闻文章分类为“科技”、“体育”或“政治”,我们将使用三个输出节点,以此类推。
在尝试图 4 所示的修改之前,我们通过 print(model) 打印模型架构,输出如下:
GPTModel(
(tok_emb): Embedding(50257, 768)
(pos_emb): Embedding(1024, 768)
(drop_emb): Dropout(p=0.0, inplace=False)
(trf_blocks): Sequential(
...
(11): TransformerBlock(
(att): MultiHeadAttention(
(W_query): Linear(in_features=768, out_features=768, bias=True)
(W_key): Linear(in_features=768, out_features=768, bias=True)
(W_value): Linear(in_features=768, out_features=768, bias=True)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.0, inplace=False)
)
(ff): FeedForward(
(layers): Sequential(
(0): Linear(in_features=768, out_features=3072, bias=True)
(1): GELU()
(2): Linear(in_features=3072, out_features=768, bias=True)
)
)
(norm1): LayerNorm()
(norm2): LayerNorm()
(drop_resid): Dropout(p=0.0, inplace=False)
)
)
(final_norm): LayerNorm()
(out_head): Linear(in_features=768, out_features=50257, bias=False)
)如上文所示,我们可以看到在第 4 章中实现的模型架构已经清晰地展示出来。如第 4 章所讨论的,GPTModel 由嵌入层、后续的 12 个相同的 Transformer 块(为简洁起见,仅展示了最后一个块)、一个最终的 LayerNorm 层,以及输出层 out_head 组成。
接下来,我们将用一个新的输出层替换 out_head,如图 4 所示,该输出层将用于微调。
对选定层进行微调与对所有层进行微调
由于我们从一个预训练模型开始,因此不必微调模型的所有层。这是因为,在基于神经网络的语言模型中,较低层通常捕获基本的语言结构和语义,这些结构和语义适用于广泛的任务和数据集。因此,仅微调最后几层(接近输出的层),这些层更具体地捕捉细微的语言模式和任务特定的特征,通常就足以将模型适配到新任务。这还有一个额外的好处,就是只微调少量层在计算上更高效。感兴趣的读者可以在附录 B 的本章参考文献部分找到更多关于微调哪些层的实验和信息。
为了让模型准备好进行分类微调,我们首先冻结模型,这意味着我们将所有层设为不可训练:
for param in model.parameters():
param.requires_grad = False接着,如前文图 4 所示,我们替换了原始的输出层(model.out_head),该层最初将输入映射到 50,257 维(即词汇表的大小):
torch.manual_seed(123)
num_classes = 2
model.out_head = torch.nn.Linear(
in_features=BASE_CONFIG["emb_dim"],
out_features=num_classes
)需要注意的是,在上述代码中,我们使用了 BASE_CONFIG["emb_dim"],在 "gpt2-small (124M)" 模型中,这个值等于 768。这样可以使下面的代码更具通用性,也就是说我们可以用同样的代码来处理更大的 GPT-2 模型变体。
这个新的 model.out_head 输出层的 requires_grad 属性默认设置为 True,这意味着它将是模型中唯一在训练期间会更新的层。
从技术上讲,只训练我们刚刚添加的输出层就足够了。然而,通过实验我发现,微调额外的层可以显著提升微调后模型的预测性能。(更多细节请参考附录 C 的参考文献。)
此外,我们还将最后一个 Transformer 模块和连接该模块与输出层的最终 LayerNorm 模块设置为可训练,如图 5 所示。
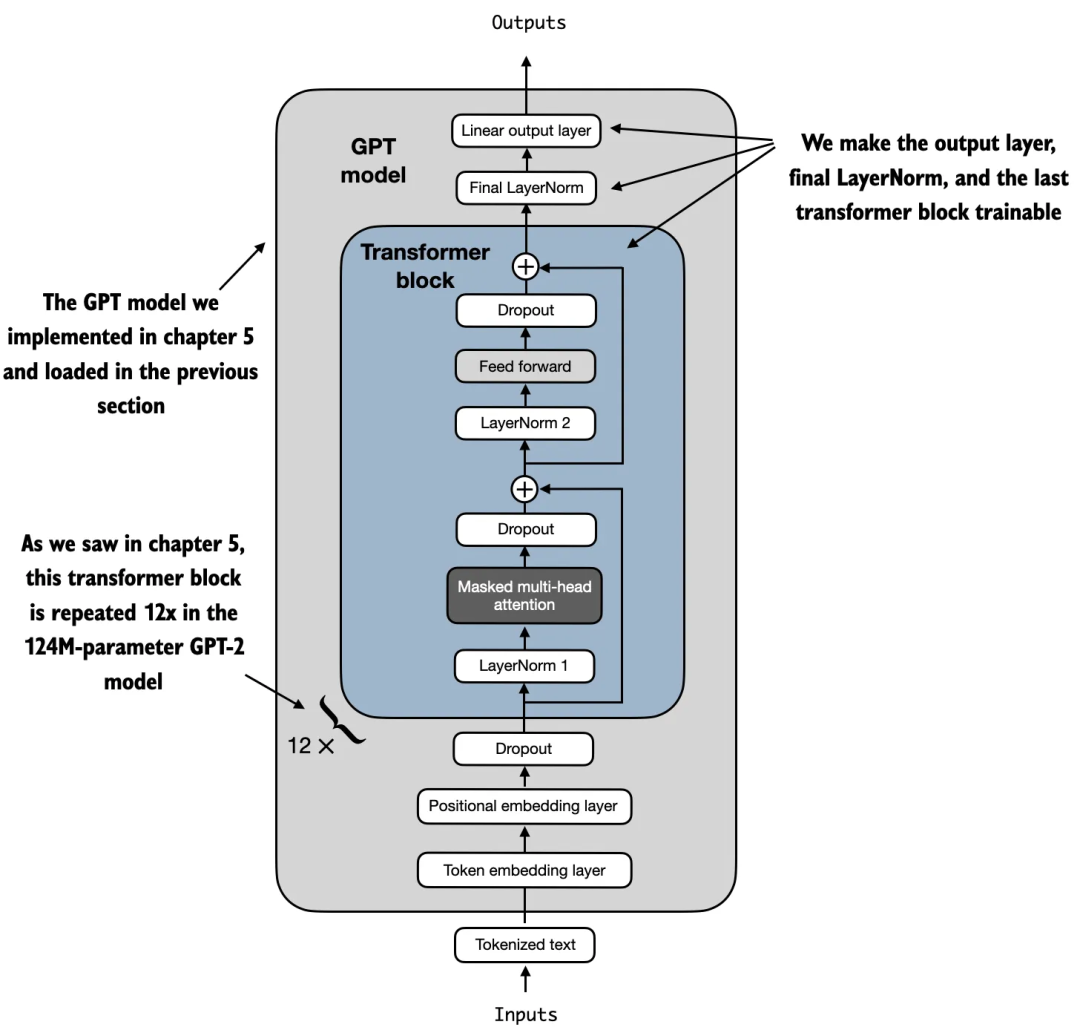 图 5 中展示了我们在前几章开发的 GPT 模型,该模型包含 12 个重复的 Transformer 模块。我们将输出层、最终的 LayerNorm 以及最后一个 Transformer 模块设置为可训练,而其余 11 个 Transformer 模块和嵌入层保持为不可训练状态。
图 5 中展示了我们在前几章开发的 GPT 模型,该模型包含 12 个重复的 Transformer 模块。我们将输出层、最终的 LayerNorm 以及最后一个 Transformer 模块设置为可训练,而其余 11 个 Transformer 模块和嵌入层保持为不可训练状态。
为了使最终的 LayerNorm 和最后一个 Transformer 模块可训练,如上图 5 所示,我们将它们各自的 requires_grad 属性设置为 True:
for param in model.trf_blocks[-1].parameters():
param.requires_grad = True
for param in model.final_norm.parameters():
param.requires_grad = True即便我们添加了新的输出层并将某些层标记为可训练或不可训练,我们仍然可以像前几章那样使用该模型。例如,我们可以像以前一样给它提供一个示例文本。如下所示:
inputs = tokenizer.encode("Do you have time")
inputs = torch.tensor(inputs).unsqueeze(0)
print("Inputs:", inputs)
print("Inputs dimensions:", inputs.shape)正如输出所示,上述代码将输入编码为一个包含 4 个输入 token 的张量:
Inputs: tensor([[5211, 345, 423, 640]])
Inputs dimensions: torch.Size([1, 4])然后,我们可以像往常一样将编码后的 token ID 传递给模型:
with torch.no_grad():
outputs = model(inputs)
print("Outputs:\n", outputs)
print("Outputs dimensions:", outputs.shape)输出张量如下所示:
Outputs:
tensor([[[-1.5854, 0.9904],
[-3.7235, 7.4548],
[-2.2661, 6.6049],
[-3.5983, 3.9902]]])
Outputs dimensions: torch.Size([1, 4, 2])在第 4 章和第 5 章中,类似的输入会生成形状为 [1, 4, 50257] 的输出张量,其中 50257 代表词汇表的大小。和前几章一样,输出的行数对应于输入 token 的数量(在本例中为 4)。然而,由于我们替换了模型的输出层,每个输出的嵌入维度(列数)现在减少到 2,而不是 50257。
请记住,我们的目标是微调这个模型,使其返回一个类别标签,指示输入文本是否为垃圾邮件。为此,我们不需要微调所有 4 行输出,可以只关注一个输出 token 。特别是,我们将关注最后一行对应于最后一个输出 token,如图 6 所示。
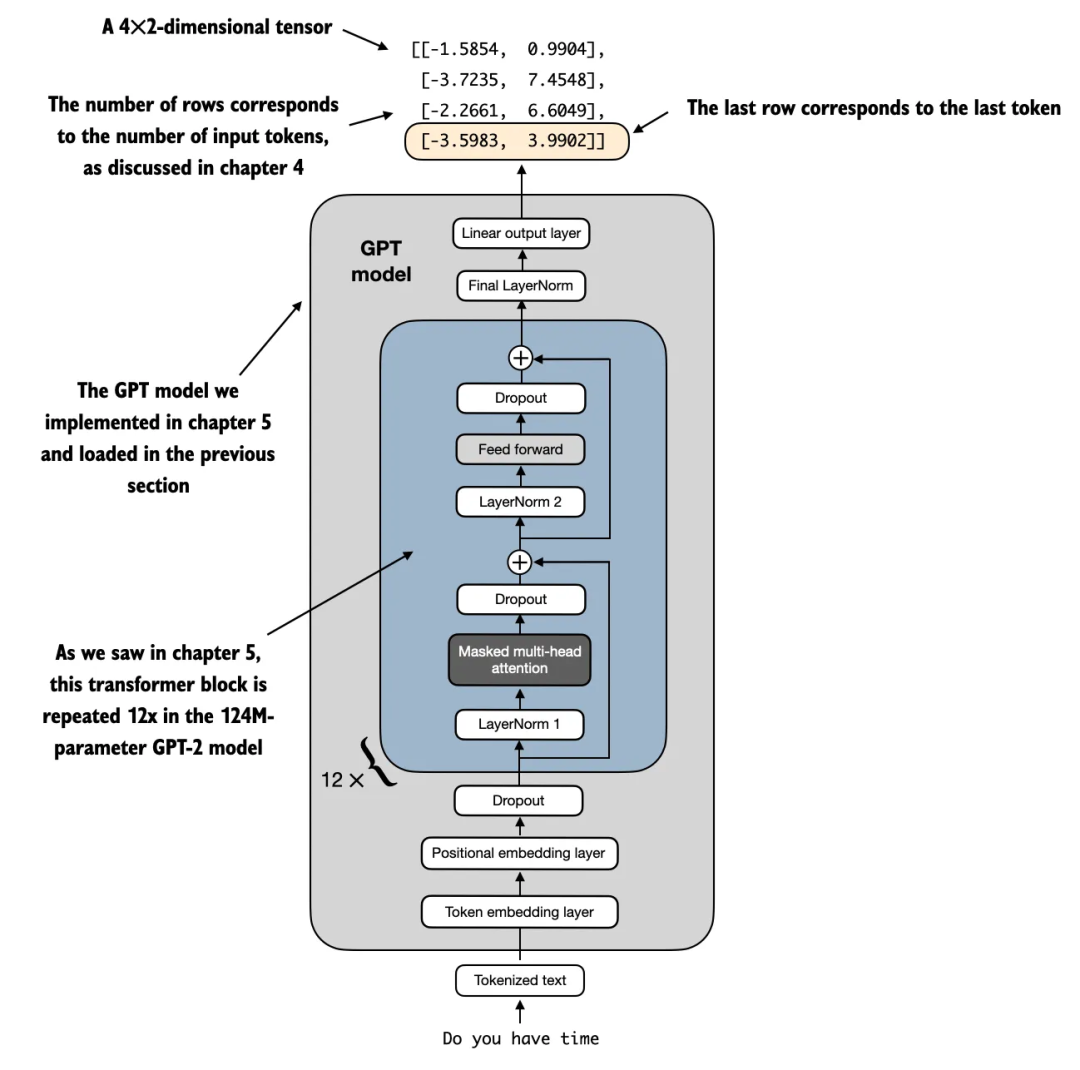 图 6:GPT 模型处理一个包含 4 个 token 的输入示例及其输出的示意图。由于修改了输出层,输出张量由 2 列组成。在微调模型进行垃圾邮件分类时,我们只关注最后一行对应的最后一个 token。
图 6:GPT 模型处理一个包含 4 个 token 的输入示例及其输出的示意图。由于修改了输出层,输出张量由 2 列组成。在微调模型进行垃圾邮件分类时,我们只关注最后一行对应的最后一个 token。
为了从输出张量中提取图 6 所示的最后一个输出 token,我们使用以下代码:
print("Last output token:", outputs[:, -1, :])输出如下:
Last output token: tensor([[-3.5983, 3.9902]])在进入下一节之前,我们先回顾一下刚才的讨论。我们将重点放在将这些值转换为类别标签预测上。但首先,让我们了解为什么我们特别关注最后一个输出 token,而不是第 1 个、第 2 个或第 3 个。
在第 3 章中,我们探讨了注意力机制,该机制建立了每个输入 token 与其他所有输入 token 之间的关系。随后,我们引入了因果注意力掩码的概念,这在类似 GPT 的模型中常用。这个掩码限制了每个 token 只能关注其当前位置及之前的 token ,确保每个 token 只受自己和前面的 token 影响,如图 7 所示。
 图 7:第 3 章中讨论的因果注意力机制示意图,其中输入 token 之间的注意力分数以矩阵格式显示。空白单元格表示由于因果注意力掩码而被屏蔽的位置,防止 token 关注未来的 token。单元格中的值代表注意力分数,其中最后一个 token "time" 是唯一一个计算所有前面 token 的注意力分数的 token。
图 7:第 3 章中讨论的因果注意力机制示意图,其中输入 token 之间的注意力分数以矩阵格式显示。空白单元格表示由于因果注意力掩码而被屏蔽的位置,防止 token 关注未来的 token。单元格中的值代表注意力分数,其中最后一个 token "time" 是唯一一个计算所有前面 token 的注意力分数的 token。
根据图 7 中展示的因果注意力掩码设置,序列中的最后一个 token 积累了最多的信息,因为它是唯一可以访问所有前面 token 数据的 token。因此,在我们的垃圾邮件分类任务中,我们在微调过程中将重点放在最后一个 token 上。
在修改完模型后,下一节将详细介绍如何将最后一个 token 转化为类别标签预测,并计算模型的初始预测准确率。随后,我们将在接下来的部分对模型进行垃圾邮件分类任务的微调。
评估模型性能
由于这部分内容已经较长,我不会详细讨论模型评估的过程。不过,我至少想展示一张图,显示在训练过程中训练集和验证集上的分类准确率,证明模型的学习效果非常好。
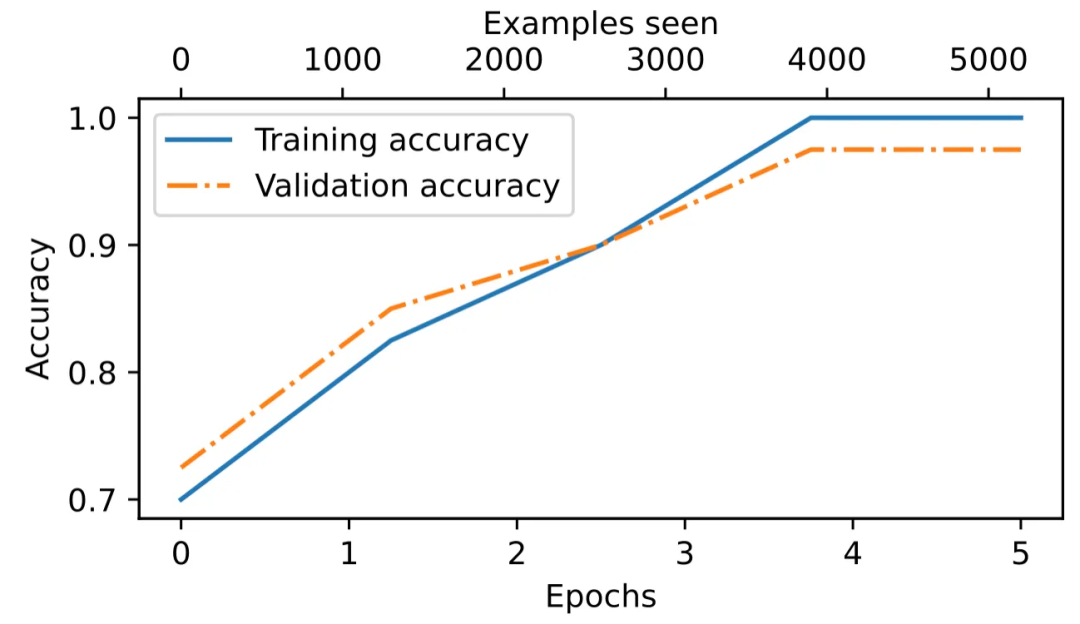 图 8:训练准确率(实线)和验证准确率(虚线)在早期训练轮次中显著提高,并最终趋于平稳,达到接近完美的准确率 1.0,即 100%。两条线在整个训练过程中非常接近,表明模型并没有过度拟合训练数据。
图 8:训练准确率(实线)和验证准确率(虚线)在早期训练轮次中显著提高,并最终趋于平稳,达到接近完美的准确率 1.0,即 100%。两条线在整个训练过程中非常接近,表明模型并没有过度拟合训练数据。
从图 8 中我们可以看到,模型在验证集上的准确率大约为 97%。测试集的准确率(未显示)大约为 96%。此外,我们可以看到模型略微过拟合,因为训练集的准确率稍高。总的来说,这个模型表现得非常好:96%的测试集准确率意味着它能正确识别 100 条消息中的 96 条是垃圾邮件还是非垃圾邮件。(虽然在这部分中没有讨论数据集,但它是一个平衡的数据集,垃圾邮件和非垃圾邮件各占 50%,这意味着随机分类器或训练不佳的分类器大约只能达到 50% 的准确率。)
来自其他实验的见解
到目前为止,你可能对某些设计选择有很多问题,所以我想分享一些其他实验的结果,这些结果可能会解答你的一些问题或疑虑。复现实验的代码可以在 GitHub 上找到。
免责声明:这些实验大多只在一个数据集上运行,未来需要在其他数据集上重复实验,以测试这些发现是否具有普适性。
1) 我们需要训练所有层吗?
在上面的章节节选中,出于效率考虑,我们仅训练了输出层和最后一个 Transformer 模块。如前文所述,对于分类微调,并不需要更新 LLM 中的所有层。(我们更新的权重越少,训练越快,因为我们不需要在反向传播时计算这些权重的梯度。)
但是,你可能会想,如果不更新所有层,我们会损失多少预测性能。所以在下表中,我比较了训练所有层、仅训练最后一个 Transformer 模块(加上最后一层)和仅训练最后一层的性能。
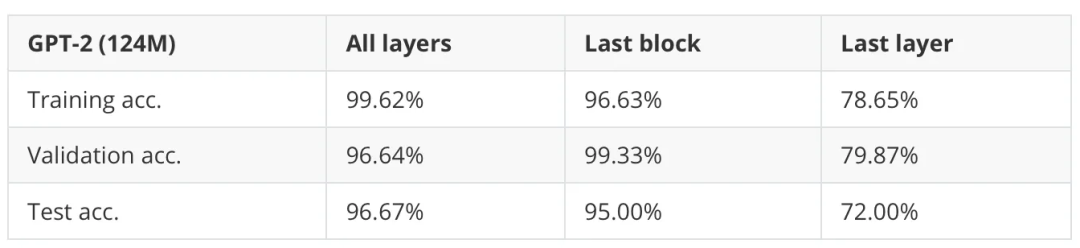 表 1:训练所有层与仅训练最后一个 Transformer 模块(包括最后一层)与仅训练最后一层的比较。
表 1:训练所有层与仅训练最后一个 Transformer 模块(包括最后一层)与仅训练最后一层的比较。
如表 1 所示,训练所有层的模型性能稍好一些:96.67% 对比 95.00%。(不过,这样做的运行时间大约增加了 2.5 倍。)
完整的实验结果可以在 GitHub 上找到。
2) 为什么选择微调最后一个 token,而不是第一个?
如果你熟悉像 BERT 这样的编码器风格语言模型(BERT:由 Devlin 等人于 2018 年提出的《BERT:用于语言理解的深度双向 Transformer 的预训练》),你可能知道,这类模型通常会有一个指定的分类 token,作为输入序列的第一个 token,如下图所示。
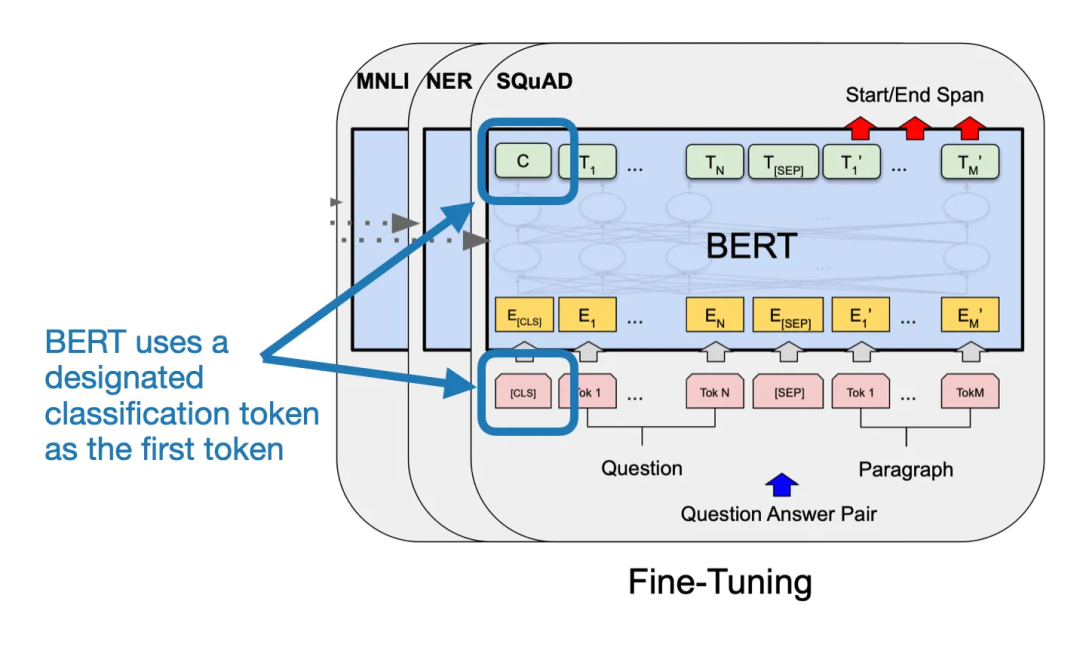 BERT 论文中的注释图,来源于原始论文:https://arxiv.org/abs/1810.04805
BERT 论文中的注释图,来源于原始论文:https://arxiv.org/abs/1810.04805
与 BERT 不同,GPT 是一种解码器风格的模型,采用了因果注意力机制(如之前的图 7 所示)。这意味着,第一个 token 没有任何其他 token 的上下文信息,只有最后一个 token 才能获得所有其他 token 的信息。
因此,如果我们希望使用像 GPT 这样的模型进行分类微调,就应该关注最后一个 token,因为它能捕捉到所有其他输入 token 的上下文信息。
以下是一些其他的实验结果,我们可以看到,使用第一个 token 来微调 GPT 模型进行分类,性能明显较差。
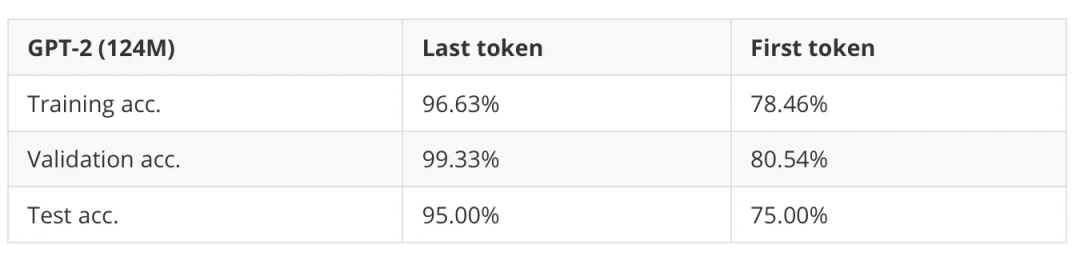 表 2:在 GPT 模型中微调最后一个 token 与第一个 token 的比较。
表 2:在 GPT 模型中微调最后一个 token 与第一个 token 的比较。
不过,我还是觉得挺惊讶的,尽管使用第一个 token 就能达到 75% 的准确率来判断消息是否为垃圾邮件。毕竟,这个数据集并不是平衡的,而随机分类器的准确率是 50%。
3)BERT 和 GPT 在性能上有何区别?
说到 BERT,你可能会好奇它与 GPT 风格的模型在分类任务中的表现如何。
简而言之,前面提到的小型 GPT-2 模型和 BERT 在垃圾邮件分类数据集上的表现相似,结果如下表所示:
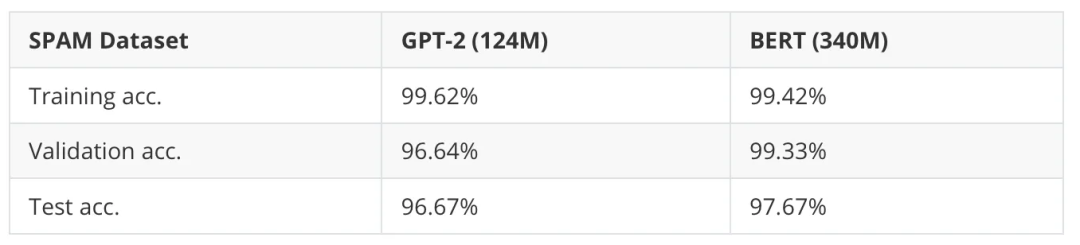 表 3:GPT-2 与 BERT 在垃圾邮件分类上的比较。
表 3:GPT-2 与 BERT 在垃圾邮件分类上的比较。
需要注意的是,BERT 模型的表现略好(测试准确率高 1%),但它的规模几乎是 GPT-2 的三倍。此外,数据集可能太小且过于简单,因此我还尝试了用于情感分类的 IMDB 电影评论数据集(即预测评论者是否喜欢这部电影)。
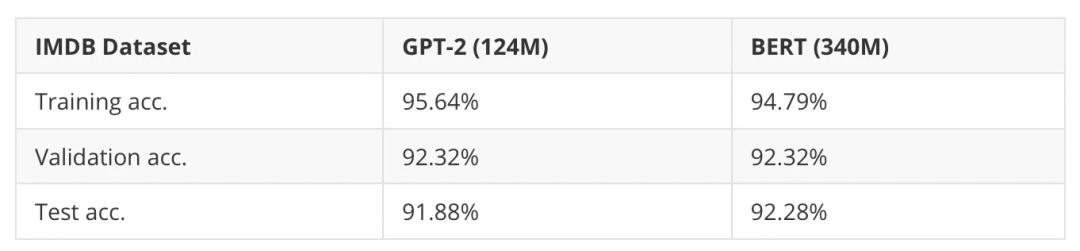 表 4:GPT-2 与 BERT 在电影评论分类上的比较。(代码可以在 GitHub 上找到。)
表 4:GPT-2 与 BERT 在电影评论分类上的比较。(代码可以在 GitHub 上找到。)
可以看出,GPT-2 和 BERT 在这个更大的数据集(包含 25,000 条训练数据和 25,000 条测试数据)上的预测表现也相对相似。
通常情况下,BERT 和其他编码器模型被认为在分类任务上优于解码器模型。然而,正如上述实验所示,编码器风格的 BERT 与解码器风格的 GPT 模型之间并没有显著差异。
此外,如果你对更多的基准比较以及如何进一步提升解码器模型在分类任务中的表现感兴趣,可以参考以下两篇最近的论文:
《Label Supervised LLaMA Finetuning (2023)》 作者:Li 等人
《LLM2Vec: Large Language Models Are Secretly Powerful Text Encoders (2024)》 作者:Behnam Ghader 等人
例如,正如这些论文所讨论的,移除因果掩码(causal mask)在分类微调过程中,可以进一步提高解码器风格模型的分类性能。
4) 我们是否应该禁用因果掩码?
由于 GPT 类模型是在下一个词预测任务上进行训练的,因此因果注意力掩码(causal attention mask)是 GPT 架构的核心特征(与 BERT 模型或原始 Transformer 架构不同)。
然而,在分类微调过程中,我们实际上可以移除因果掩码,这样就能让我们微调第一个而非最后一个 token,因为此时后续的 token 将不再被掩盖,第一个 token 可以看到所有其他 token。
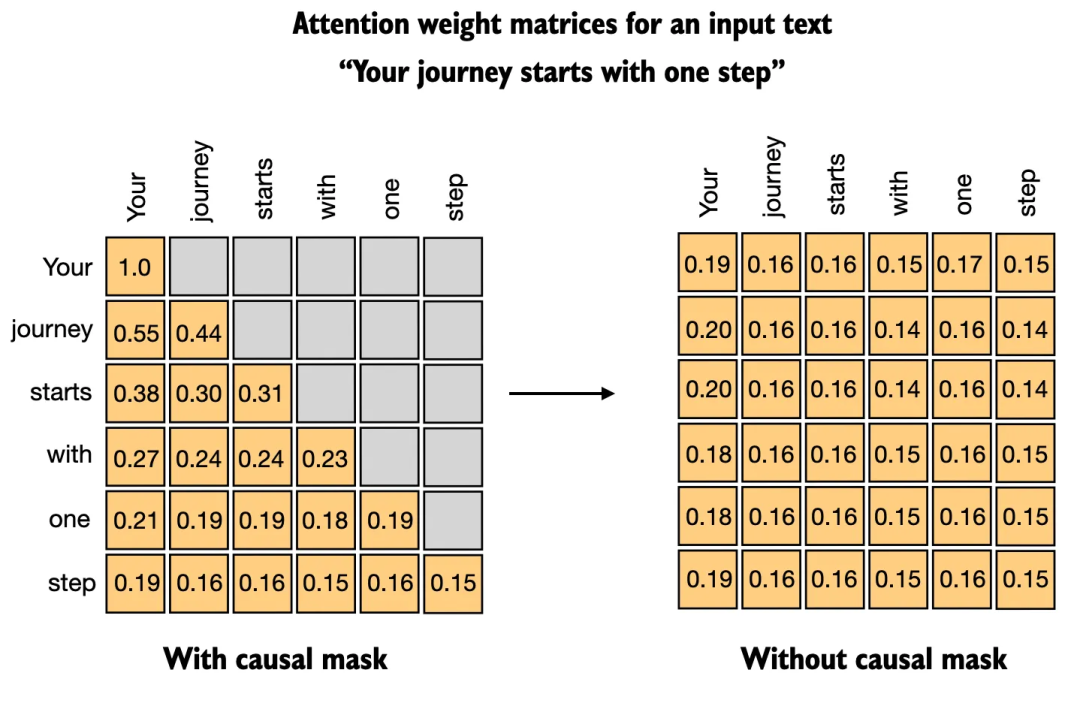 有因果掩码和没有因果掩码的注意力权重矩阵对比。
有因果掩码和没有因果掩码的注意力权重矩阵对比。
在 GPT 类的 LLM 中,禁用因果掩码实际上只需要修改两行代码。
class MultiheadAttention(nn.Module):
def __init__(self, d_in, d_out, context_length, dropout, num_heads):
super().__init__()
# ...
def forward(self, x):
b, num_tokens, d_in = x.shape
keys = self.W_key(x) # Shape: (b, num_tokens, d_out)
queries = self.W_query(x)
values = self.W_value(x)
# ...
attn_scores = queries @ keys.transpose(2, 3)
# Comment out the causal attention mask part
# mask_bool = self.mask.bool()[:num_tokens, :num_tokens]
# attn_scores.masked_fill_(mask_bool, -torch.inf)
attn_weights = torch.softmax(
attn_scores / keys.shape[-1]**0.5, dim=-1
)
context_vec = (attn_weights @ values).transpose(1, 2)
context_vec = context_vec.contiguous().view(
b, num_tokens, self.d_out
)
context_vec = self.out_proj(context_vec)
return context_vec下表(表 5)展示了禁用因果掩码对垃圾邮件分类任务性能的影响。
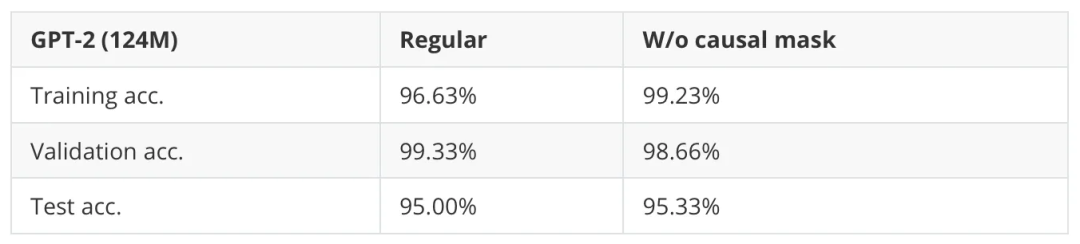 表 5:使用和不使用因果掩码进行微调的 GPT-2 分类器。
表 5:使用和不使用因果掩码进行微调的 GPT-2 分类器。
从表 5 的结果可以看出,在微调过程中禁用因果掩码会带来一定的小幅提升。
5) 增大模型规模会带来什么影响?
到目前为止,我们只研究了最小的 GPT-2 模型,也就是拥有 1.24 亿参数的版本。那么,较大的变体(分别有 3.55 亿、7.74 亿和 15 亿参数)会有什么表现呢?下表(表 6)总结了相关结果。
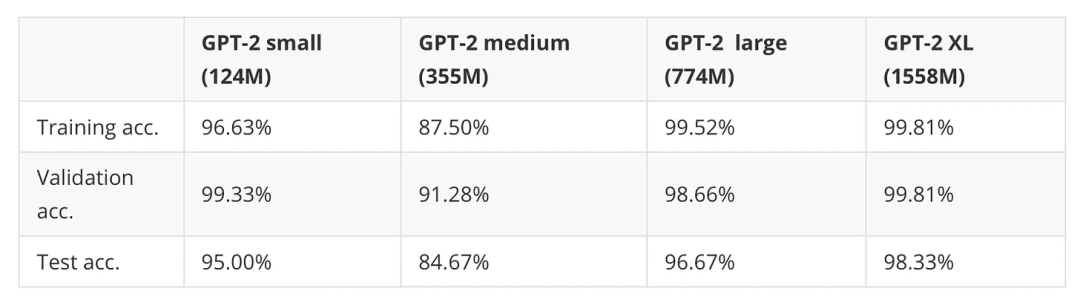 表 6:不同 GPT-2 模型规模在分类微调中的表现
表 6:不同 GPT-2 模型规模在分类微调中的表现
如表中所示,随着模型规模的增大,预测准确率显著提高(不过,GPT-2 中型模型在这里是一个例外。我也发现这个模型在其他数据集上的表现较差,我怀疑该模型的预训练可能存在问题)。
然而,虽然 GPT-2 XL 模型的分类准确率明显优于最小模型,但它的微调时间也增加了 7 倍。
6) 使用 LoRA 能带来哪些改进?
在第一个问题中,我们探讨了“1) 是否需要训练所有层?”并发现,通过仅微调最后一个变换器块(而非微调整个模型),我们几乎可以达到相同的分类性能。只微调最后一个变换器块的优点是训练速度更快,因为并非所有的权重参数都需要更新。
接下来的问题是,这种方法与低秩适应(LoRA)相比如何,LoRA 是一种高效的参数微调技术。(LoRA 的详细内容请参见附录 E。)
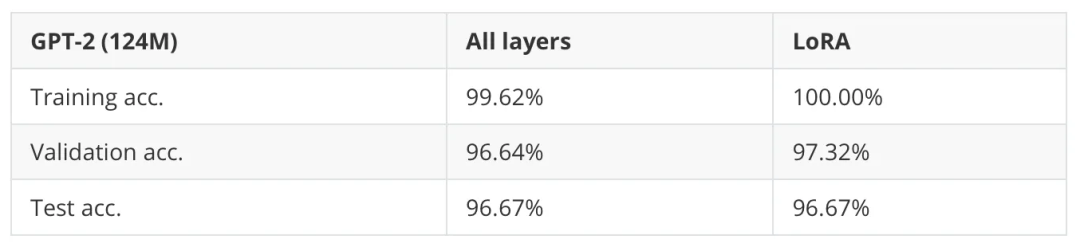 表 7:完全微调(所有层)与参数高效微调(LoRA)。
表 7:完全微调(所有层)与参数高效微调(LoRA)。
如表 7 所示,完全微调(所有层)和 LoRA 在这个数据集上得到了相同的测试集性能。
对于小型模型,LoRA 稍微慢一些,因为添加 LoRA 层的额外开销可能会超过其带来的好处。但在训练更大的 1.5 亿参数模型时,LoRA 的训练速度比完全微调快 1.53 倍。
7) 是否需要填充(Padding)?
如果我们想在训练或推理过程中批量处理数据(即一次处理多个输入序列),就需要插入填充 token,以确保训练样本的长度一致。
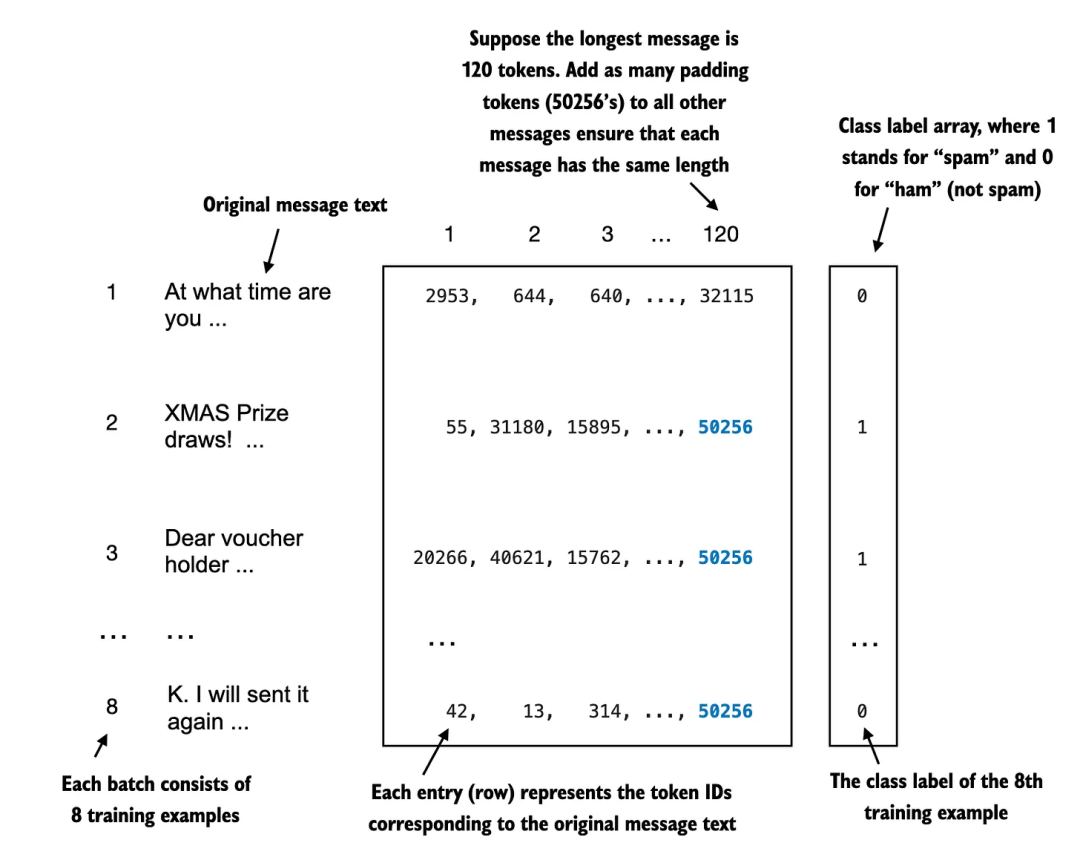 说明如何将一批输入文本填充到相同的长度。
说明如何将一批输入文本填充到相同的长度。
在常规的文本生成任务中,填充不会影响模型的输出,因为填充 token 通常会被加到右侧,并且由于之前讨论的因果掩码(causal mask),这些填充 token 不会影响其他 token 。
但是,请记住,我们在微调时关注的是最后一个 token。由于填充 token 位于最后 token 的左侧,它们可能会影响结果。
如果我们使用批量大小为 1,其实不需要对输入进行填充。当然,这样做在计算上效率较低(因为一次只处理一个输入例子)。尽管如此,批量大小为 1 仍然可以作为一种变通方法,来测试是否使用填充能够提高结果。(另一种解决方案是为注意力分数计算添加自定义掩码,忽略填充 token,但由于这涉及到修改 GPT 的实现,属于另一个话题,我们以后再讨论。)
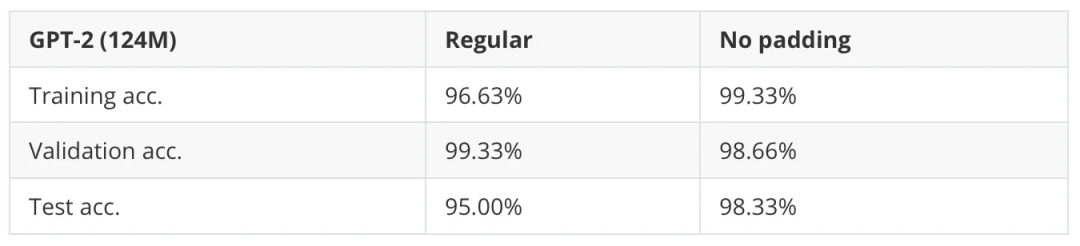 表 8:训练模型时使用填充(常规)和不填充输入至相似长度的对比。
表 8:训练模型时使用填充(常规)和不填充输入至相似长度的对比。
从表中可以看到,避免使用填充 token 确实能给模型带来明显的提升!(值得注意的是,我使用了梯度累积来模拟一个批量大小为 8 的情况,以匹配默认实验中的批量大小,从而进行公平对比。)
《Build A Large Language Model From Scratch》
本文展示了我新书《Build a Large Language Model From Scratch》第 6 章的 10 页节选内容。
你所阅读的只是整个 365 页书籍中的一小部分,这本书讲述了如何从零构建一个类似 GPT 的 LLM,并深入理解 LLM 是如何工作的。
如果你对这部分内容感兴趣,那么书中的其他部分同样会给你带来启发与帮助。

行动的时刻到了!
中文版预计 2 月底上市!
加入大模型交流群,提前抢先读,并有机会参与图书共创!



















 8
8

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









