







介绍
这篇主要从总体上开始,介绍caffe中比blob高一个层次的layer。首先让我无耻的盗图。(读书人的事,哪里能叫偷!!!)
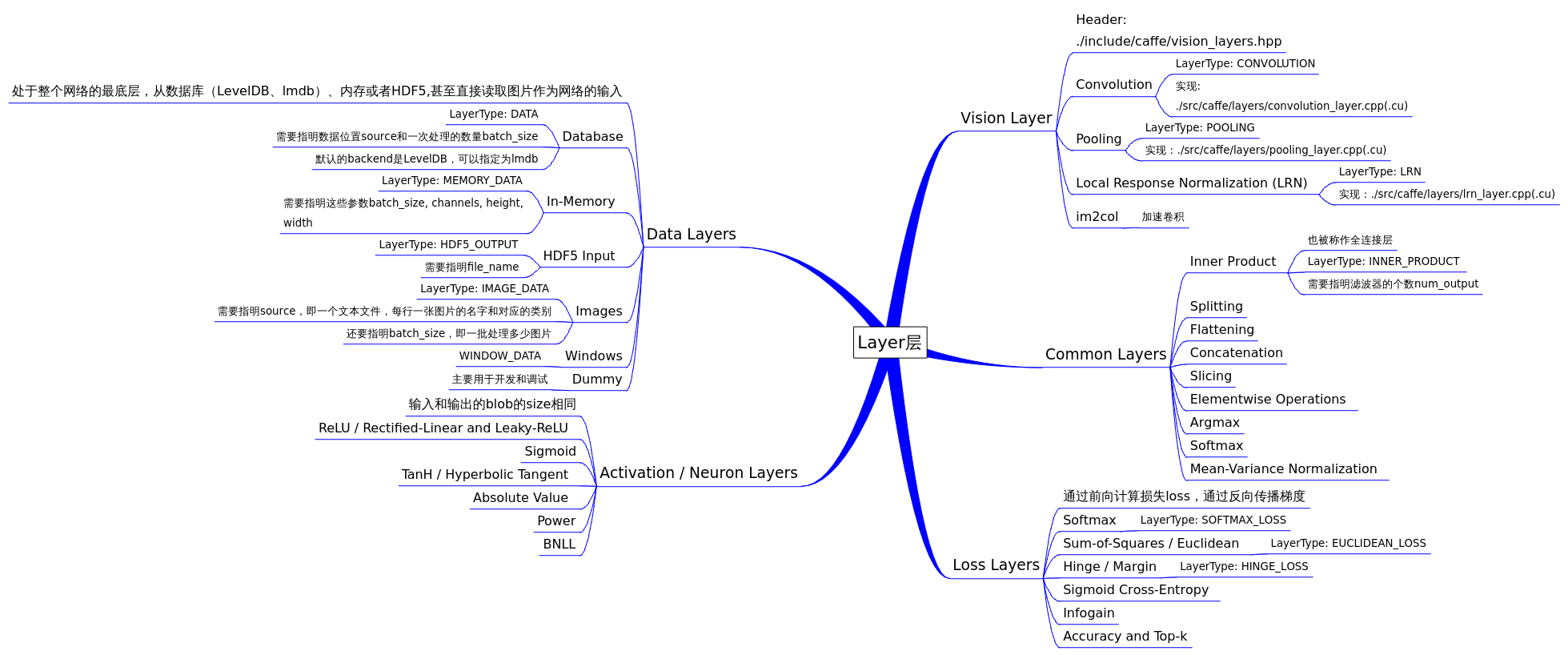
上图一是对layer的一个总体分类。图中很详细,不细说。
成员变量
在layer类中的成员变量
protected:
/** The protobuf that stores the layer parameters */
LayerParameter layer_param_;
/** The phase: TRAIN or TEST */
Phase phase_;
/** The vector that stores the learnable parameters as a set of blobs. */
vector<shared_ptr<Blob<Dtype> > > blobs_;
/** Vector indicating whether to compute the diff of each param blob. */
vector<bool> param_propagate_down_;
/** The vector that indicates whether each top blob has a non-zero weight in
* the objective function. */
vector<Dtype> loss_;layer_param_从文件中获取,存放该层参数。blobs_存储的是layer的参数,具体可以看成是权重。param_propagate_down_表明是否计算各个blob参数的diff,即传播误差。
成员函数
成员函数主要有如下几类:构造,setup(),Forward(),Backward()。
explicit Layer(const LayerParameter& param)
:layer_param_(param), is_shared_(false);
void SetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top);
inline Dtype Forward(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top);
inline void Backward(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down,
const vector<Blob<Dtype>*>& bottom);setup()主要负责一些初始化的工作,对于不同的layer,可以在子类中实现LayerSetUp(),已完成不同之类各自的特殊初始化工作。
Forward()向前传导。会调用Forward_cpu()或Forward_gpu()。在具体的layer子类中,会实现这两个函数,完成具体layer的向前传导。
Backward()向后传导。与Forward()相同,也有Backward_cpu()和Backward_gpu()。
其他的一些成员函数
/**
* @brief Whether a layer should be shared by multiple nets during data
* parallelism. By default, all layers except for data layers should
* not be shared. data layers should be shared to ensure each worker
* solver access data sequentially during data parallelism.
*/
virtual inline bool ShareInParallel() const { return false; }
/** @brief Return whether this layer is actually shared by other nets.
* If ShareInParallel() is true and using more than one GPU and the
* net has TRAIN phase, then this function is expected return true.
*/
inline bool IsShared() const { return is_shared_; }
/** @brief Set whether this layer is actually shared by other nets
* If ShareInParallel() is true and using more than one GPU and the
* net has TRAIN phase, then is_shared should be set true.
*/
inline void SetShared(bool is_shared) {
CHECK(ShareInParallel() || !is_shared)
<< type() << "Layer does not support sharing.";
is_shared_ = is_shared;
}
/* 根据该层的需要返回bottom blobs的个数,需要在之类中重载返回一个非负数*/
virtual inline int ExactNumBottomBlobs() const { return -1; }
/*返回该层需要的最小bottom blobs的个数,之类中需要重载返回一个非负数*/
virtual inline int MinBottomBlobs() const { return -1; }
/*类似上面*/
virtual inline int MaxBottomBlobs() const { return -1; }
/*类似上面*/
virtual inline int ExactNumTopBlobs() const { return -1; }
/*类似上面*/
virtual inline int MinTopBlobs() const { return -1; }
/*类似上面*/
virtual inline int MaxTopBlobs() const { return -1; }
/**
* @brief Returns true if the layer requires an equal number of bottom and top blobs.
* This method should be overridden to return true if your layer expects an equal number of bottom and top blobs.
*/
virtual inline bool EqualNumBottomTopBlobs() const { return false; }
/**
* @brief Return whether "anonymous" top blobs are created automatically by the layer. If this method returns true, Net::Init will create enough "anonymous" top blobs to fulfill the requirement specified by ExactNumTopBlobs() or MinTopBlobs().*/
virtual inline bool AutoTopBlobs() const { return false;
/**
* @brief Return whether to allow force_backward for a given bottom blob index.
* If AllowForceBackward(i) == false, we will ignore the force_backward setting and backpropagate to blob i only if it needs gradient information (as is done when force_backward == false).*/
virtual inline bool AllowForceBackward(const int bottom_index) const {
return true;
}
/**
* @brief Specifies whether the layer should compute gradients w.r.t. a parameter at a particular index given by param_id.
* You can safely ignore false values and always compute gradients for all parameters, but possibly with wasteful computation.
*/
inline bool param_propagate_down(const int param_id) {
return (param_propagate_down_.size() > param_id) ?
param_propagate_down_[param_id] : false;
}
/**
* @brief Sets whether the layer should compute gradients w.r.t. a parameter at a particular index given by param_id.
*/
inline void set_param_propagate_down(const int param_id, const bool value) {
if (param_propagate_down_.size() <= param_id) {
param_propagate_down_.resize(param_id + 1, true);
}
param_propagate_down_[param_id] = value;
}
//------------上面几个理解不是很透彻或者是仅仅知道功能不了解如何使用,以后在layer子类终于到在进一步学习。这里只能把注释直接拷过来了--------
virtual void Reshape(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) = 0;//根据输入blob与具体layer对输出blob进行reshape。
//----下面几个都比较好理解。看注释就行-----
/**
* @brief Returns the vector of learnable parameter blobs.
*/
vector<shared_ptr<Blob<Dtype> > >& blobs() {
return blobs_;
}
/**
* @brief Returns the layer parameter.
*/
const LayerParameter& layer_param() const { return layer_param_; }//关于Parameter以后将在以后学习,这一块的东西还比较多
/**
* @brief Writes the layer parameter to a protocol buffer
*/
virtual void ToProto(LayerParameter* param, bool write_diff = false);
/**
* @brief Returns the scalar loss associated with a top blob at a given index.
*/
inline Dtype loss(const int top_index) const {
return (loss_.size() > top_index) ? loss_[top_index] : Dtype(0);
}
/**
* @brief Sets the loss associated with a top blob at a given index.
*/
inline void set_loss(const int top_index, const Dtype value) {
if (loss_.size() <= top_index) {
loss_.resize(top_index + 1, Dtype(0));
}
loss_[top_index] = value;
}
/**
* @brief Returns the layer type.
*/
virtual inline const char* type() const { return ""; }//子类中实现,返回layer类型。
/**
在SetUp中调用,检测bottom和top 的blobs是否与要求的相匹配。通过{ExactNum,Min,Max}{Bottom,Top}Blobs()来实现*/
virtual void CheckBlobCounts(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top);
/**
在SetUp中调用,初始化loss的权重,具体操作是将权重存入diff blob*/
inline void SetLossWeights(const vector<Blob<Dtype>*>& top);
/*-------------------------------另外,还有几个私有成全变量和函数,觉得forward_mutex_在计算中是比较重要的,遇到了在学习------------------
private:
/** Whether this layer is actually shared by other nets*/
bool is_shared_;
/** The mutex for sequential forward if this layer is shared */
shared_ptr<boost::mutex> forward_mutex_;
/** Initialize forward_mutex_ */
void InitMutex();
/** Lock forward_mutex_ if this layer is shared */
void Lock();
/** Unlock forward_mutex_ if this layer is shared */
void Unlock(); 详细看一下Forward()与Backward()
template <typename Dtype>
inline Dtype Layer<Dtype>::Forward(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
// Lock during forward to ensure sequential forward
Lock();//上锁操作,其实是对forward_mutex_的上锁操作
Dtype loss = 0;//存放将要返回的该层loss值
Reshape(bottom, top);//根据bottom对top进行reshape以满足需要。
switch (Caffe::mode()) {
case Caffe::CPU:
Forward_cpu(bottom, top);//子类中的具体前向传导
for (int top_id = 0; top_id < top.size(); ++top_id) {
if (!this->loss(top_id)) { continue; }//loss非0时继续向下
const int count = top[top_id]->count();
const Dtype* data = top[top_id]->cpu_data();
const Dtype* loss_weights = top[top_id]->cpu_diff();
loss += caffe_cpu_dot(count, data, loss_weights);//将loss与权重点乘求和。
}
break;
case Caffe::GPU:
Forward_gpu(bottom, top);
#ifndef CPU_ONLY
for (int top_id = 0; top_id < top.size(); ++top_id) {
if (!this->loss(top_id)) { continue; }
const int count = top[top_id]->count();
const Dtype* data = top[top_id]->gpu_data();
const Dtype* loss_weights = top[top_id]->gpu_diff();
Dtype blob_loss = 0;
caffe_gpu_dot(count, data, loss_weights, &blob_loss);
loss += blob_loss;
}
#endif
break;
default:
LOG(FATAL) << "Unknown caffe mode.";
}
Unlock();//解锁
return loss;
}
/*----------------Backward----------------*/
/*基本上是直接调用子类的Backward_{gpu,cpu}-------*/
template <typename Dtype>
inline void Layer<Dtype>::Backward(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down,
const vector<Blob<Dtype>*>& bottom) {
switch (Caffe::mode()) {
case Caffe::CPU:
Backward_cpu(top, propagate_down, bottom);
break;
case Caffe::GPU:
Backward_gpu(top, propagate_down, bottom);
break;
default:
LOG(FATAL) << "Unknown caffe mode.";
}
}总结
感觉水平有限,看了一些东西后有了一定的理解,总感觉写不出来。轻拍















 4310
4310

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









