






chatTTS
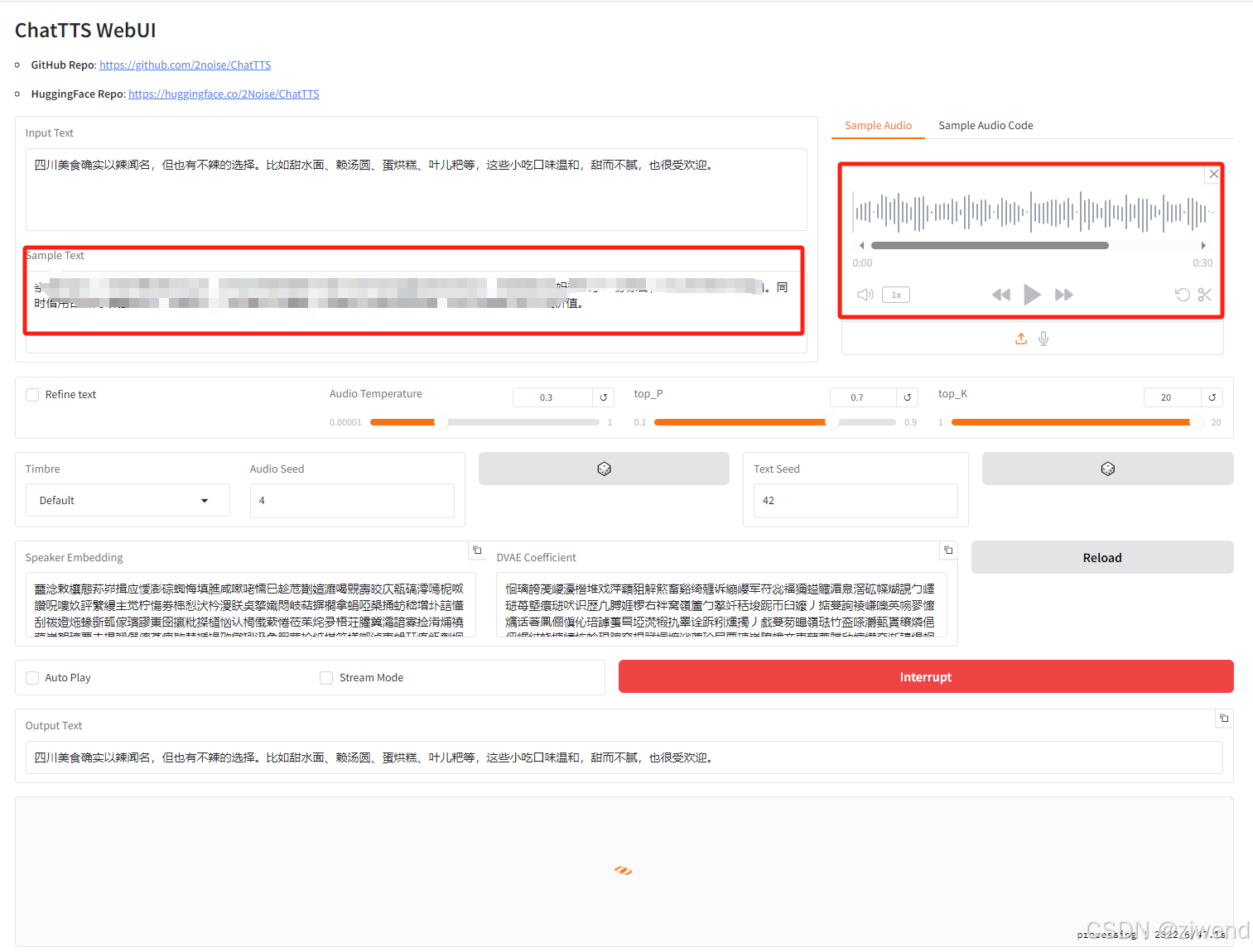
如下图所示,在不添加Sample Audio和Text的时候可以正常完成文本转语音,可以自定义添加语气词,笑声和停顿等。
无法实现声音克隆,即模仿某人的音色生成语音。
试用了chatTTS官网推荐的https://voicv.com/voice-cloning进行语音克隆,发现生成的音频效果很差,无法使用。
CosyVoice
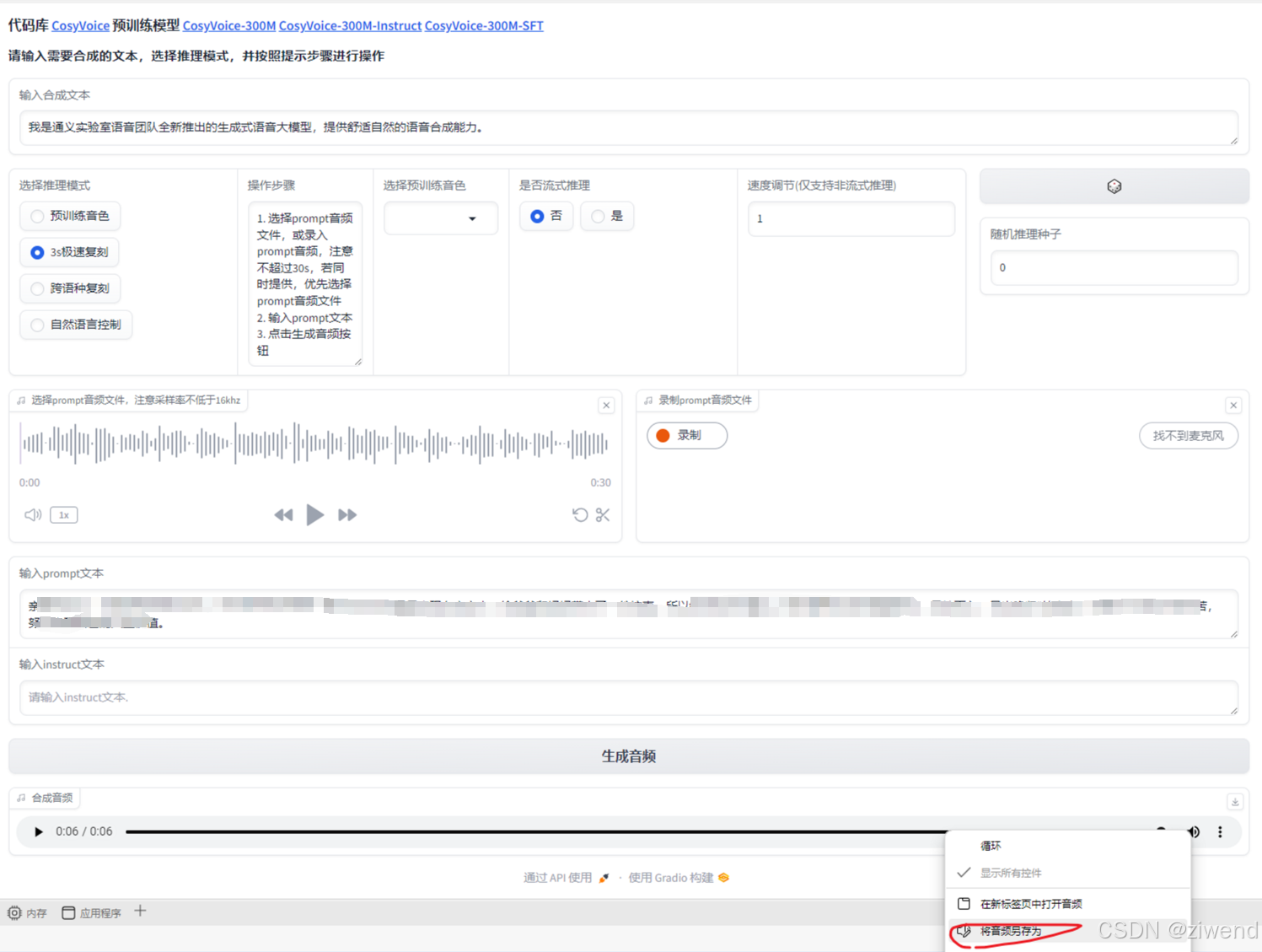
使用样例中的输入合成文本时可以完成声音克隆(注意音频不能超过30s,否则会报错)。模仿的音色比较像,模仿效果应该是本文试用的几个项目中最好的。
但是调整“输入合成文本”为自定义内容时就会出现文本和生成的音频无法对应,会缺少中间一部分文字对应的语音。一开始怀疑是文本过长,缩短“输入合成文本”后一样会缺少一部分语音输出,没啥规律,没找到解决方案。
Coqui.ai tts
参考官方文档:
https://docs.coqui.ai/en/latest/docker_images.html
docker run --rm -it -p 5002:5002 --gpus all --entrypoint /bin/bash ghcr.io/coqui-ai/tts
#在容器中执行:
python3 TTS/server/server.py --list_models #To get the list of available models
python3 TTS/server/server.py --model_name tts_models/en/vctk/vits --use_cuda true
这个生成的内容和cosyvoice一样,中间有缺失,而且缺失的地方是一致的,不知道二者底层是否使用的是同样的处理逻辑;
通过webui可以调整的参数有限,没有找到声音的克隆的方法。

尝试通过python脚本进行语音克隆,和上面一样生成的语音有缺失,模仿的音色一点也不像。
import torch
from TTS.api import TTS
# Get device
device = "cuda" if torch.cuda.is_available() else "cpu"
# Init TTS
tts = TTS("tts_models/zh-CN/baker/tacotron2-DDC-GST").to(device)
# Example voice cloning with YourTTS
tts.tts_with_vc_to_file("要合成的文本", speaker_wav="sample-devin-9s.WAV", file_path="output-coqui.wav")
GPT-SoVITS
参考官方文档安装部署后,执行python webui.py
https://github.com/RVC-Boss/GPT-SoVITS
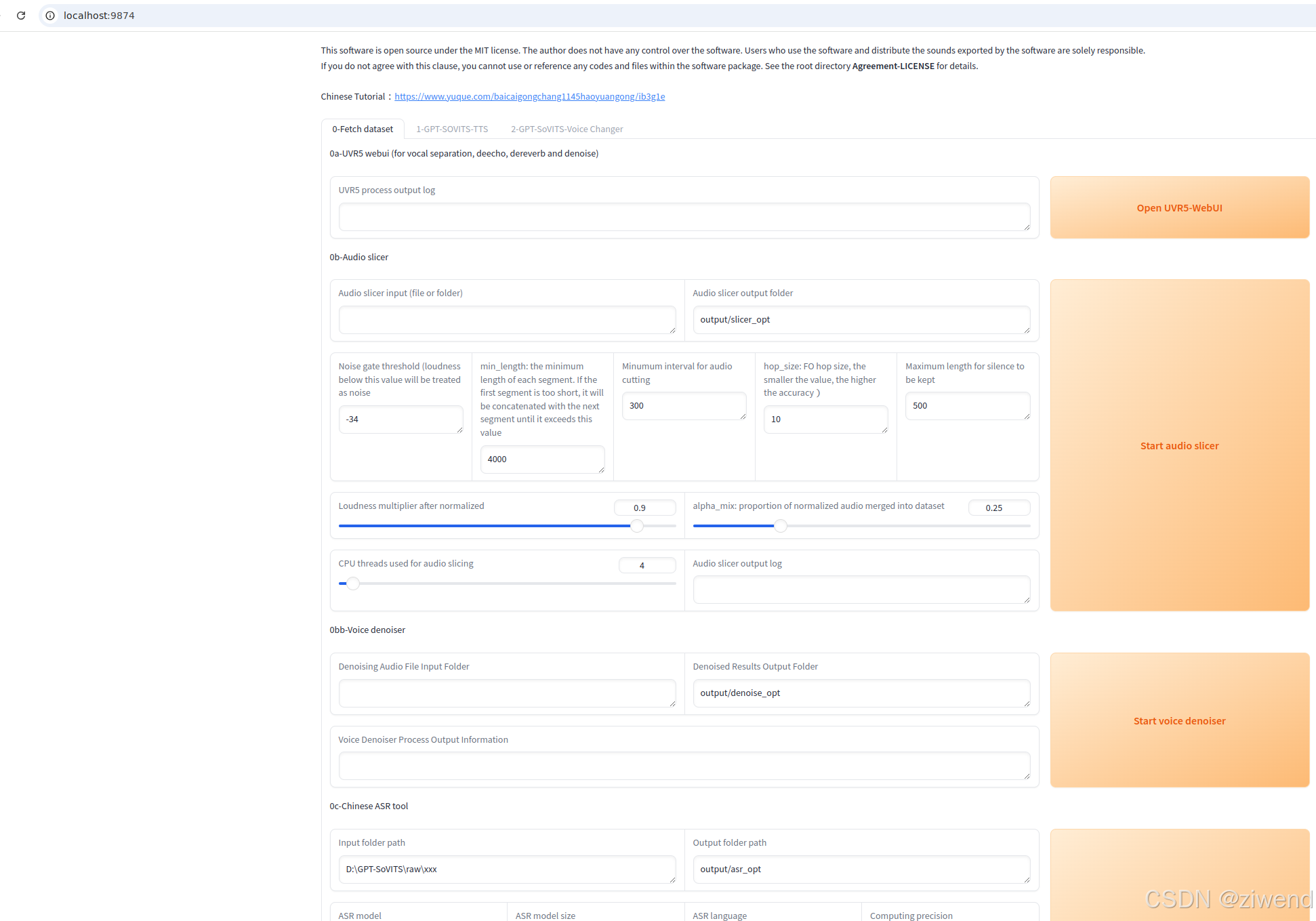
选择好模型点开启TTS推理,自动弹出推理界面。如果没有弹出,复制http://0.0.0.0:9872到浏览器打开。
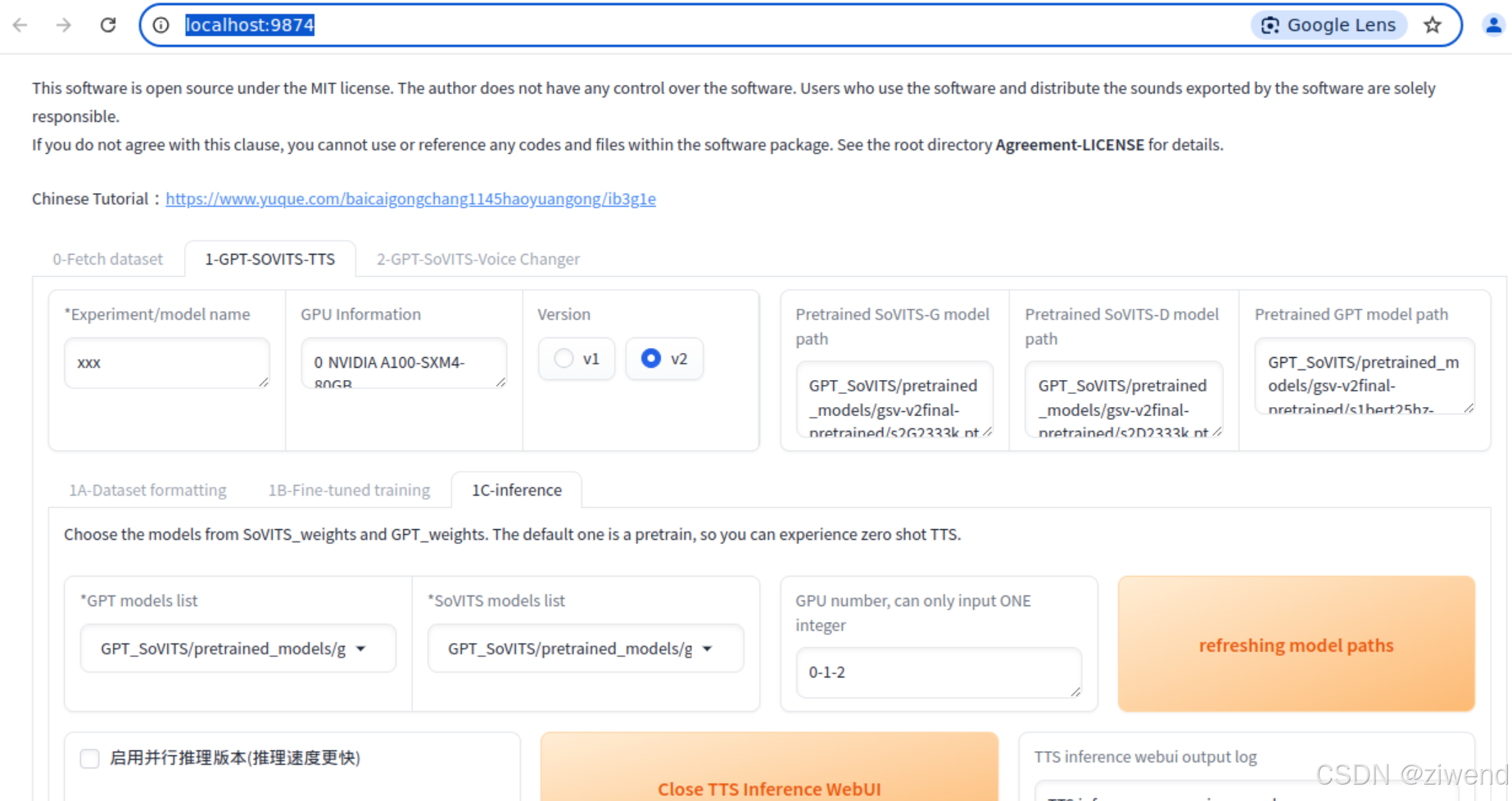
推理界面
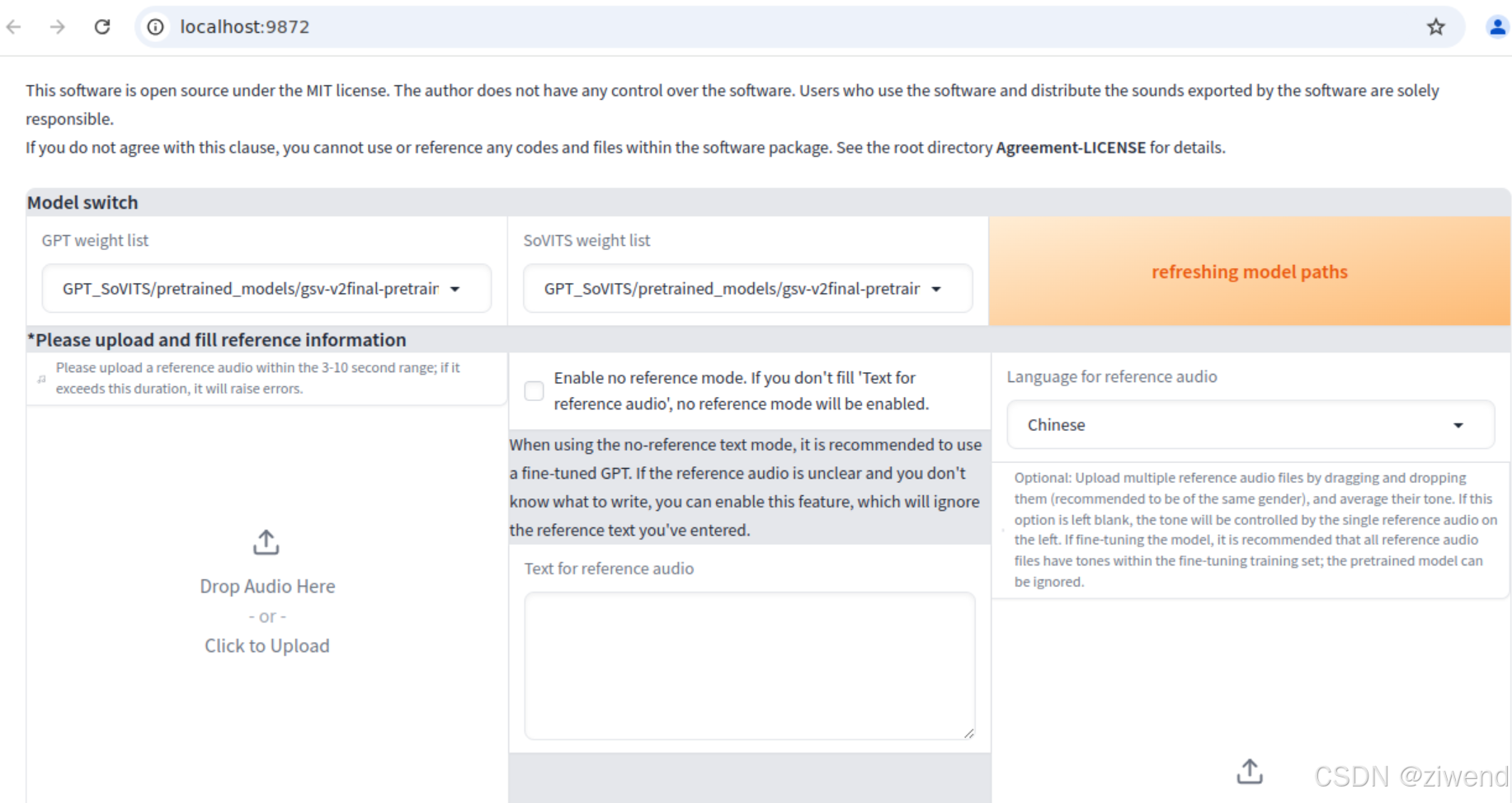
参考音频在3~10秒范围外,请更换!使用的参考音频需要满足时长要求,否则会报错
这个文本转语音的输出比较完整,但是在提供了reference audio和Text的情况下,模仿的音色一点都不像;
以上步骤繁琐复杂,可以先使用官方给的demo试用一下,不过只能选择游戏角色配音,输出的音频还是比较完整的。
https://gsv.acgnai.top/
MockingBird
曾经尝试部署,没有成功,步骤比较繁琐;
https://github.com/babysor/MockingBird
所以直接试用了一下作者提供的demo网站,先创建自定义声音,然后根据自定义声音进行语音合成。
合成的语音比较完整,有点声音克隆的效果,但是声音忽高忽低,音色也不固定,一段文字,前半部分和后面感觉不像是同一个人说的。
anyvoice
再补充一下当前可用的免费非开源的语音克隆工具
https://anyvoice.net/zh/ai-voice-cloning
参考链接
一文梳理ChatTTS的进阶用法,手把手带你实现个性化配音,音色、语速、停顿,口语,全搞定
来自 https://blog.csdn.net/u010522887/article/details/139719895

















 3997
3997

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









