







在概率统计学中,最大似然估计(Maximum Likelihood Estimation, MLE)和最大后验估计(Maximum A Posteriori Estimation, MAP)是两种常用的参数估计方法。本文将深入剖析这两种方法的异同点,揭示它们在概率模型中的核心原理。
最大似然估计(MLE)
定义: 最大似然估计是一种通过优化似然函数来估计模型参数的方法。似然函数描述了在给定模型和观测数据的情况下,参数值出现的可能性。
核心原理: MLE寻找使似然函数取得最大值的参数值,即找到最可能解释观测数据的参数。
数学公式:
这里,θ^MLE 是最大似然估计得到的参数值,L(θ∣Data) 是似然函数,Data 是观测数据。
最大后验估计(MAP)
定义: 最大后验估计是一种贝叶斯估计方法,结合了先验分布和似然函数。通过引入先验知识,MAP提供了对参数的更稳健的估计。
核心原理: MAP估计寻找使后验分布取得最大值的参数值,综合考虑了先验分布和似然函数。
数学公式:
这里,θ^MAP 是最大后验估计得到的参数值,P(θ∣Data) 是后验分布,L(θ∣Data) 是似然函数,P(θ) 是先验分布。
异同点对比:
-
核心原理:
- MLE:寻找最大化似然函数的参数,着重考虑数据的可能性。
- MAP:结合先验知识和似然函数,寻找最大化后验分布的参数,更稳健。
-
公式表达:
- MLE:
- MAP:
- MLE:
-
考虑先验知识:
- MLE:不考虑先验分布,仅关注似然函数。
- MAP:结合了先验分布,对极端数据情况有更好的鲁棒性。
结论:
最大似然估计和最大后验估计是两种重要的参数估计方法,它们在数据科学、机器学习等领域都有着广泛的应用。理解它们的异同点有助于选择适当的估计方法,并更好地理解概率模型中的参数估计过程。在实际问题中,根据数据特点和领域知识的不同,选择合适的估计方法是关键的。
MATLAB演示:最大似然估计与最大后验估计的比较
在统计学中,最大似然估计(MLE)和最大后验估计(MAP)是两种常用的参数估计方法。本文通过一个简单的 MATLAB 示例,以正态分布的均值和标准差为例,演示了这两种估计方法的应用。
1. 数据生成:
首先,我们生成一些正态分布的随机观测数据:
% 生成观测数据
rng(42); % 设置随机数种子,以保证结果的可重复性
data = normrnd(5, 2, [100, 1]); % 正态分布,均值为5,标准差为2,共100个样本
最大似然估计(MLE):
% MLE 估计均值和标准差
mle_mean = mean(data);
mle_std = std(data);
% 显示结果
disp('最大似然估计结果:');
disp(['估计均值:', num2str(mle_mean)]);
disp(['估计标准差:', num2str(mle_std)]);
3. 最大后验估计(MAP):
假设我们对均值和标准差的先验分布有一些先验知识,比如均值在4附近,标准差在1附近。我们选择正态分布作为先验分布。
% 先验分布的均值和标准差
prior_mean = 4;
prior_std = 1;
% MAP 估计均值和标准差
map_mean = (prior_std^2 * mean(data) + mle_std^2 * prior_mean) / (prior_std^2 + mle_std^2);
map_std = sqrt((prior_std^2 * mle_std^2) / (prior_std^2 + mle_std^2));
% 显示结果
disp('最大后验估计结果:');
disp(['估计均值:', num2str(map_mean)]);
disp(['估计标准差:', num2str(map_std)]);
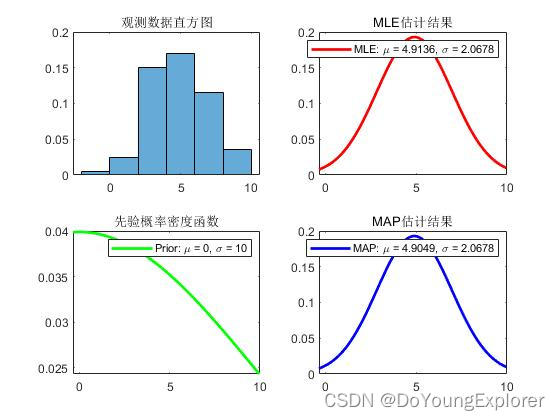
结论与分析:
- MLE 估计仅基于观测数据,而 MAP 估计结合了观测数据与先验信息。
- MLE 估计的结果受到观测数据的直接影响,而 MAP 估计的结果同时考虑了观测数据和先验概率。
- 先验概率密度函数在 MAP 中充当了调整估计结果的“引导者”,在数据量有限时对估计结果的影响较为显著。
这个简单的例子展示了最大似然估计和最大后验估计之间的关系,以及先验信息如何影响参数估计结果。在实际应用中,根据问题的特性,可以选择使用 MLE、MAP 或其他贝叶斯估计方法
















 1622
1622

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











