







- 算法概述
- 整体细节描述
- 代码实现(ID3)
- 总结
一.算法概述
形象化描述:for example:女孩是否约会男孩
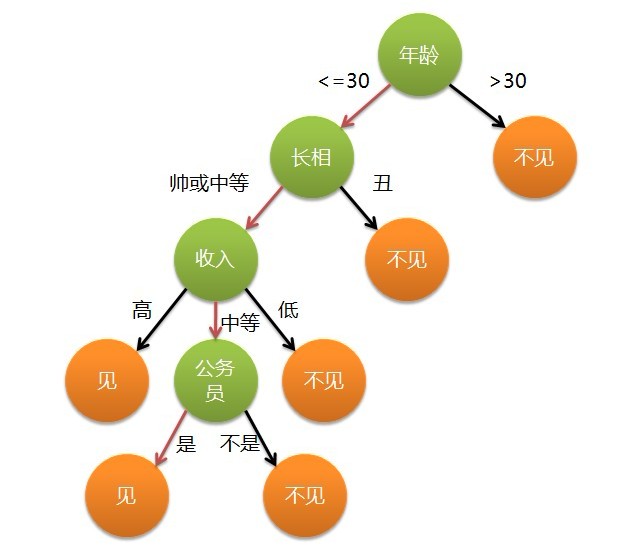
用途:分类预测
缺点:过拟合;输出单一
解决办法:剪枝;建立独立决策树
二.整体细节描述
整体描述:
决策树(decision tree)是一个树结构;非叶节点表示特征属性;分支代表特征属性值域上的输出结果;叶节点存放一个类别。
过程描述:
①进行决策从根节点开始->②测试待分类项中相应的特征属性->③按照其值选择输出分支
结束条件:直到到达叶子节点
result:叶子节点存放的类别作为决策结果
概念引入:
信息熵(entropy):
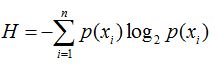
信息熵表征:混合数据越多->熵越高
举例:

p(x)表征了最后一列(是否为鱼类的概率)[这里i=2]
三.代码实现(ID3)
ID3简述: ID3算法就是在每次需要分裂时,计算每个属性的增益率,然后选择增益率最大的属性进行分裂。
信息增益:将某个属性去掉后,在进行求熵,找出信息增益最大(gain(i)=|newEntropy-H|)这即可
形象化描述:某个属性的移除对熵差异性波动最大
#!urs/bin/python
from math import log
def createDataSet():
dataSet= [[1,1,'yes'],[1,0,'no'],[0,1,'no'],[0,1,'no']]
labels=['no surfacing','flippers']
return dataSet,labels
def calcShannonEnt(dataSet):
numEntries = len(dataSet)
labelCounts = {}
for featVec in dataSet: #the the number of unique elements and their occurance
currentLabel = featVec[-1]
if currentLabel not in labelCounts.keys(): labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1
shannonEnt = 0.0
for key in labelCounts:
prob = float(labelCounts[key])/numEntries
shannonEnt -= prob * log(prob,2) #log base 2
return shannonEnt
def splitDataSet(dataSet, axis, value):
retDataSet = []
for featVec in dataSet:
if featVec[axis] == value:
reducedFeatVec = featVec[:axis] #chop out axis used for splitting
#reducedFeatVec=[]
reducedFeatVec.extend(featVec[axis+1:])
retDataSet.append(reducedFeatVec)
return retDataSet
def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0]) - 1 #the last column is used for the labels
baseEntropy = calcShannonEnt(dataSet)
bestInfoGain = 0.0; bestFeature = -1
tableVocabulary={}
print "baseEntropy="+str(baseEntropy)
for i in range(numFeatures): #iterate over all the features
featList = [example[i] for example in dataSet]#create a list of all the examples of this feature
uniqueVals = set(featList) #get a set of unique values
newEntropy = 0.0
for value in uniqueVals:
subDataSet = splitDataSet(dataSet, i, value)
prob = len(subDataSet)/float(len(dataSet))
newEntropy += prob * calcShannonEnt(subDataSet)
tableVocabulary[i] = newEntropy
infoGain = baseEntropy - newEntropy #calculate the info gain; ie reduction in entropy
if (infoGain > bestInfoGain): #compare this to the best gain so far
bestInfoGain = infoGain #if better than current best, set to best
bestFeature = i
return tableVocabulary # finding the min and min is the best choice
if __name__=='__main__':
# first:split data
dataSet,labels=createDataSet()
# shannonEnt1=calcShannonEnt(dataSet)
# print "shannonEnt1="+str(shannonEnt1)
# dataSet.append([1,1,'maybe'])
# shannonEnt2=calcShannonEnt(dataSet)
# print "shannonEnt2="+str(shannonEnt2)
###################################
# second:split data
retDataSet=splitDataSet(dataSet,1,0)
print retDataSet
print "\n\n\n"
################################
table=chooseBestFeatureToSplit(dataSet)
min=1.7976931348623157e+308
xiaoBiao=0
for key in table:
print str(key)+"->"+str(table[key])
if table[key]<=min:
xiaoBiao=key
min=table[key]
print "\n\n\n"
#print str(xiaoBiao)+"->"+str(table[xiaoBiao])扩展:
C4.5:(信息增益率的引入)
解决问题:如果存在唯一标识属性ID,则ID3会选择它作为分裂属性,这样虽然使得划分充分纯净,划分对分类无用
信息增益率:
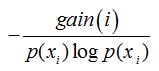
参考资料:
http://www.cnblogs.com/leoo2sk/archive/2010/09/19/decision-tree.html
http://blog.163.com/zhoulili1987619@126/blog/static/353082012013113083417956/
《机器学习实战》
四.总结
I.决策树是机器学习当中很重要的方法,我们多多学习II.让我们一同努力,明天会更好!















 2036
2036

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









