







上篇介绍了神经网络语言模型,因为每次训练都与词表大小线性相关,所以too expensive。本篇主要介绍word2vec里面应用的一种分层优化的方法可以把O(|V|)复杂度降至O(log|V|)
原问题为
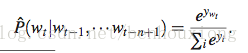
分母需要将词表中所有的词都当做候选词,做|V|次决策。如果从分类的角度来看的话,这步softmax相当于一个多分类问题,每个词相当于一个要预测的类标,优化目的是寻找一个在当前上下文环境下最合适的词。
Hinton 在[1]中提出了层次化的决策方法,主要想法是:
- 构建叶子节点为词的二叉树,每个非叶子节点也由向量表示,但不表示具体的词。
- 从上自下逐层决策,相当于每一层都是一个二分类
公式化表示为

每一层相当于一个二分类

博主自己画了两个直观的图,加深下理解,其中v表示要训练的那个词
Standrad softmax

Hierarchical sofmax

对于二叉树的构建,
- 可以用现有的知识图谱如WORDNET;
- 更为常用的是根据语料特征,构建二叉树,如根据词频的Haffman Tree
[2] 中阐述word2vec原理中提到了另外一种优化方法,
Negative Sampling 。简单的说就是随机选取一部分负例,原来的word为正例,还是用二分类来做。具体抽样方法比较复杂,这里不赘述了。
参考资料
[1] Frederic Morin and Yoshua Bengio. Hierarchical probabilistic neural networklanguage model. In Robert G. Cowell and Zoubin Ghahramani, editors, AISTATS’05,pages 246–252, 2005.
[2] Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. Efficient Estimation ofWord Representations in Vector Space. In Proceedings of Workshop at ICLR, 2013.















 540
540

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









