






回顾与总结
我们回顾一下我们之前讲过的东西,实际上我们可以发现:
1、SVM中需要计算的地方,数据向量总是以内积的形式出现的。
2、对于非线性可分的数据,存在一个简化映射空间中的内积运算的核函数。
3、对于大部分的数据来说,都是位于分隔超平面两侧的(或者说大部分数据还是分类正确的),所以大部分的样本对决策边界的贡献为0,而只有少数的,重要的支持向量起作用。
对于线性可分的数据,我们的优化问题为:
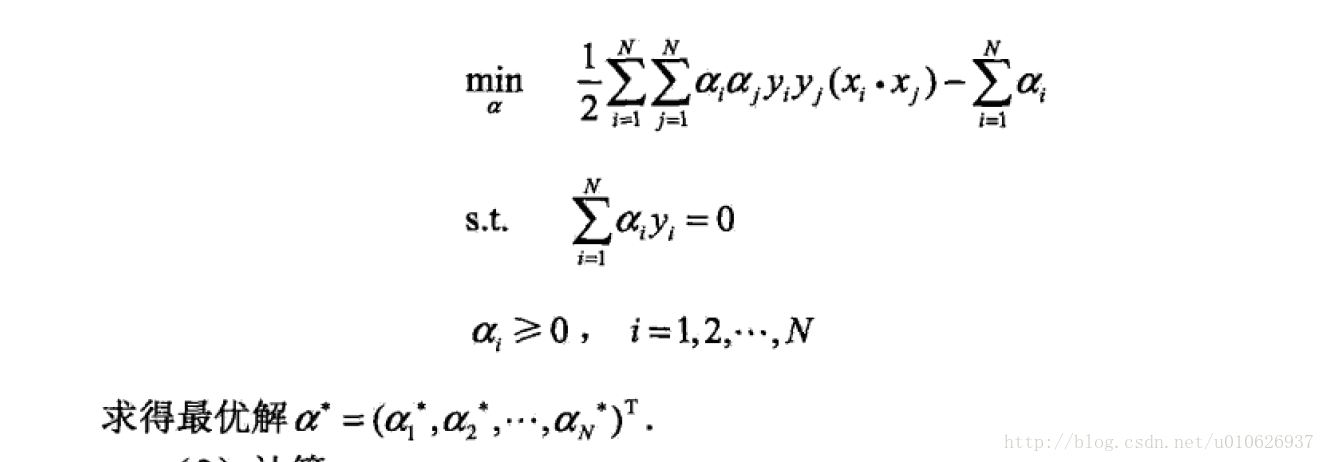
对于近似线性(数据分布基本上是线性的,只是包含少量的噪音打乱了数据的线性分布)的数据:
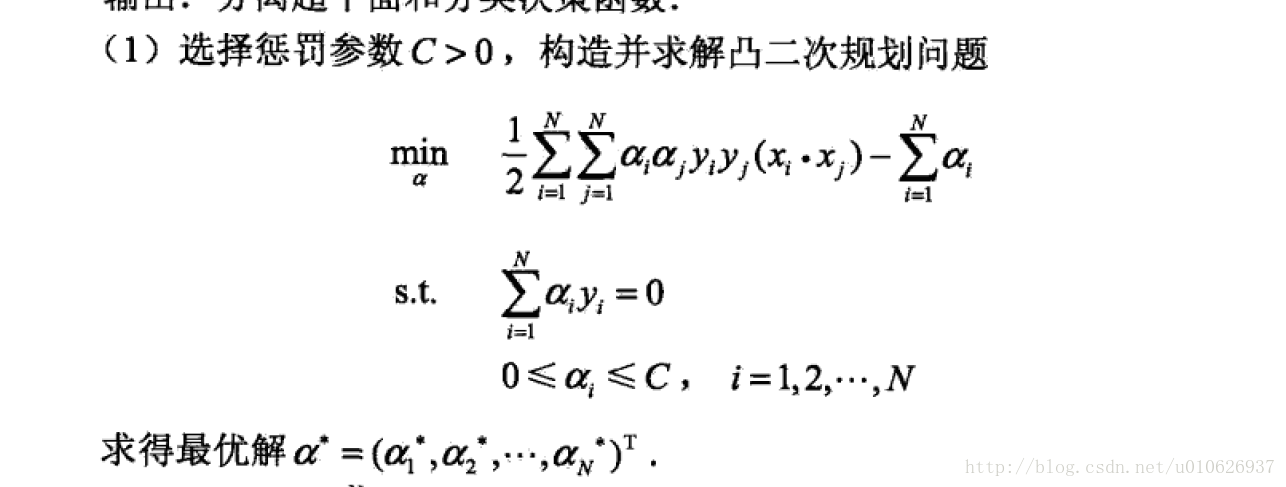
对于非线性数据(数据分布本身就是非线性的):
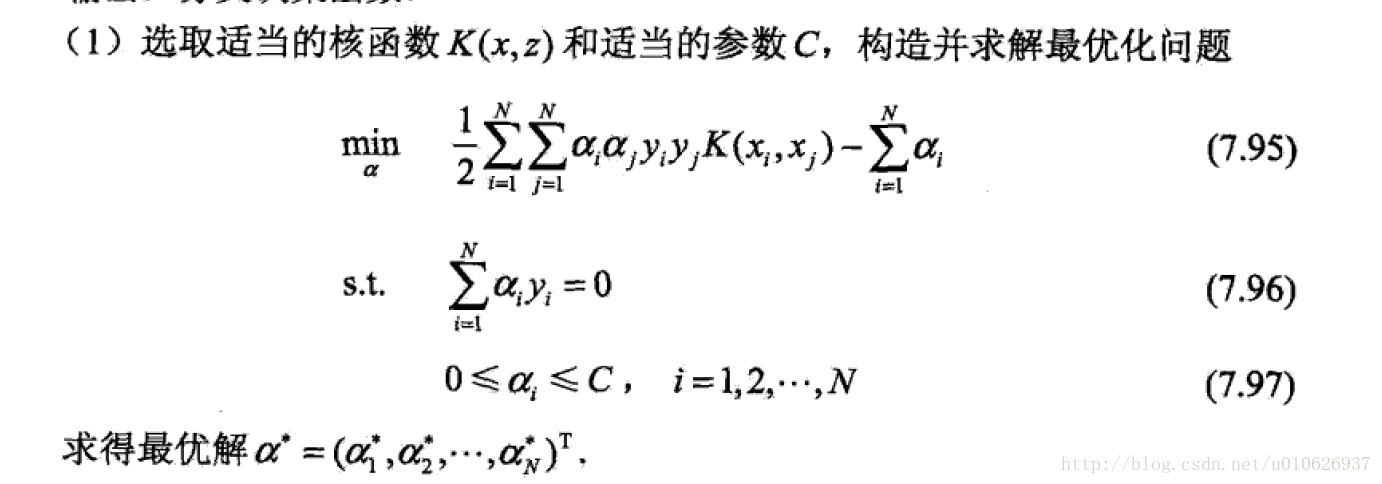
通过观察上图可以看出,对于三种情况的优化问题,形式上是一模一样的,都是需要求解优化问题,得到最优解,然后根据
求解出
最终求解出我们的决策函数:
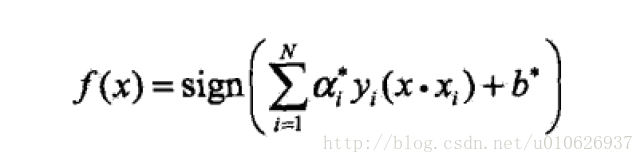
或者
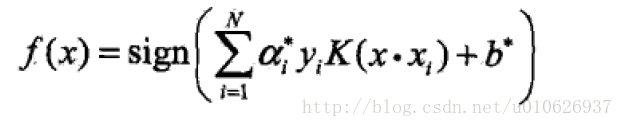
另一种理解
支持向量机的决策过程也可以看做是一种相似性比较的过程。首先,输入样本与一系列模板样本进行相似性比较,模板样本就是训练过程决定的支持向量,而采用的相似性度量就是核函数。样本与各支持向量比较后的,得分进行加权求和,权值就是训练时得到的各支持向量的系数与yi的乘积。最后根据加权求和值大小来进行决策。而采用不同的核函数,就相当于采用不同的相似度的衡量方法。
SVM之多分类
(PS:本部分大部分的内容来自这里)
SVM主要是针对二分类问题,但是,现实中需要解决的问题不只有二类,往往是多分类的问题,那么我们下面介绍两种方法,将SVM扩展到多分类问题上面。
一对多 One-Against-All
比如我们将数据划分为5类:1,2,3,4,5。第一次就把类别1的样本定为正样本,其余2,3,4,5的样本合起来定为负样本,这样得到一个两类分类器,它能够指出一个样本是第1类的,还是其他类的;第二次我们把类别2 的样本定为正样本,把1,3,4,5的样本合起来定为负样本,得到一个分类器。如此下去,我们可以得到5个这样的两类分类器(总是和类别的数目一致)。到了有样本需要分类的时候,我们就拿着这个样本挨个分类器的问:是属于你的么?是属于你的么?哪个分类器点头说是了,文章的类别就确定了。这种方法的好处是每个优化问题的规模比较小,而且分类的时候速度很快(只需要调用5个分类器就知道了结果)。但有时也会出现两种很尴尬的情况,例如拿这个样本问了一圈,每一个分类器都说它是属于它那一类的,或者每一个分类器都说它不是它那一类的,前者叫分类重叠现象,后者叫不可分类现象。分类重叠倒还好办,随便选一个结果都不至于太离谱,或者看看这篇文章到各个超平面的距离,哪个远就判给哪个(在此考虑的是确信度)。不可分类现象就着实难办了,只能把它分给第6个类别了……更要命的是,本来各个类别的样本数目是差不多的,但“其余”的那一类样本数总是要数倍于正类(因为它是除正类以外其他类别的样本之和嘛),这就人为的造成了上一节所说的“数据集偏斜(或者数据不均衡)”问题。
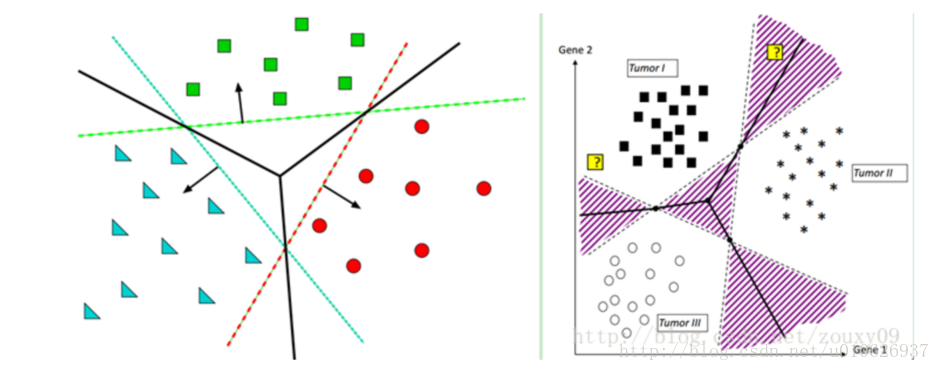
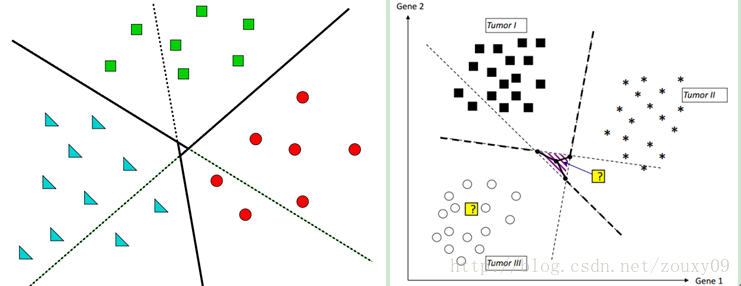
如上图左。红色分类面将红色与其他两种颜色分开,绿色分类面将绿色与其他两种颜色分开,蓝色分类面将蓝色与其他两种颜色分开。
上图右。阴影部分是比较容易会出现分类重叠现象或者不可分类现象。
在这里的对某个点的分类实际上是通过衡量这个点到三个决策边界的距离,因为到决策边界(分离超平面)的距离越大,分类越可信。注意:这里的距离是有符号的!如下图所示:
我们只需要取,所有距离里面的最大者,作为我们最终的类别。因为距离有符号,所以要注意当距离都为负的时候,我们这里的最大就是数学中负数的最大,而不是看绝对值!!!解释一下:因为都为负,所以表示该实例点都不属于该类,所以距离决策边界绝对距离最小的最可信。
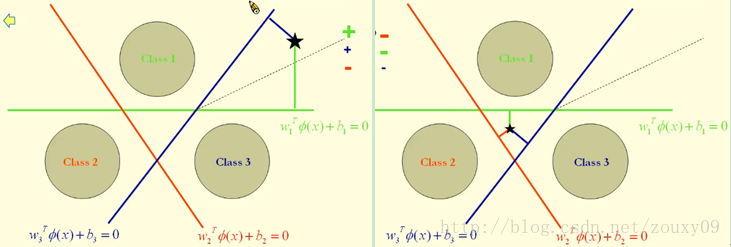
例如上图左,将星星这个点划分给绿色这一类。右图将星星这个点划分给褐色这一类。
一对一 One-Against-One
因为上面的One-Against-All方法存在数据集偏倚的问题,所以在这里,我们将All也改为One,也就是说,One-Against-One方法是每次选择一个类作为正类样本,然后在剩余的类别样本中,只选择一个类别样本,作为第二类样本。因此过程就是算出这样一些分类器,第一个只回答“是第1类还是第2类”,第二个只回答“是第1类还是第3类”,第三个只回答“是第1类还是第4类”,如此下去,你也可以马上得出,这样的分类器应该有5 X 4/2=10个(通式是,如果有k个类别,则总的两类分类器数目为k(k-1)/2)。在真正用来分类的时候,把一个样本扔给所有分类器,第一个分类器会投票说它是“1”或者“2”,第二个会说它是“1”或者“3”,让每一个都投上自己的一票,最后统计票数,如果类别“1”得票最多,就判这篇文章属于第1类。这种方法显然也会有分类重叠的现象,但不会有不可分类现象,因为总不可能所有类别的票数都是0。
如上图左,用3*(3-1)/2=3个平面进行三分类,三条实线所在的平面。上图右图,阴影部分可能会出现分类重叠现象,因为对于这部分的数据点,每个分类器都会投一票,那就不知道归为哪个类了,最简单的就是只能随便扔给某个类了,扔掉了就是你命好,扔错了就不好了;或者衡量这个点到三个决策边界的距离,因为到分类面的距离越大,分类越可信。
注意:
虽然分类器的数目多了,但是在训练阶段(也就是算出这些分类器的分类平面时)所用的总时间却比“一类对其余”方法少很多。因为,在训练过程需要计算的地方就是,分类出现矛盾的地方,需要通过距离计算来进行分类平面的调整(分类器的训练),通过上面的图像介绍可一知道,one-all的方法有四部分的阴影需要来计算,而one-one只有中间一部分交集阴影部分需要计算。
KKT条件
假设我们优化得到的最优解是:αi*,βi*, ξi*, w*和b*。我们的最优解需要满足KKT条件:
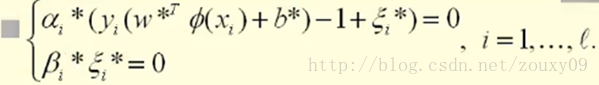
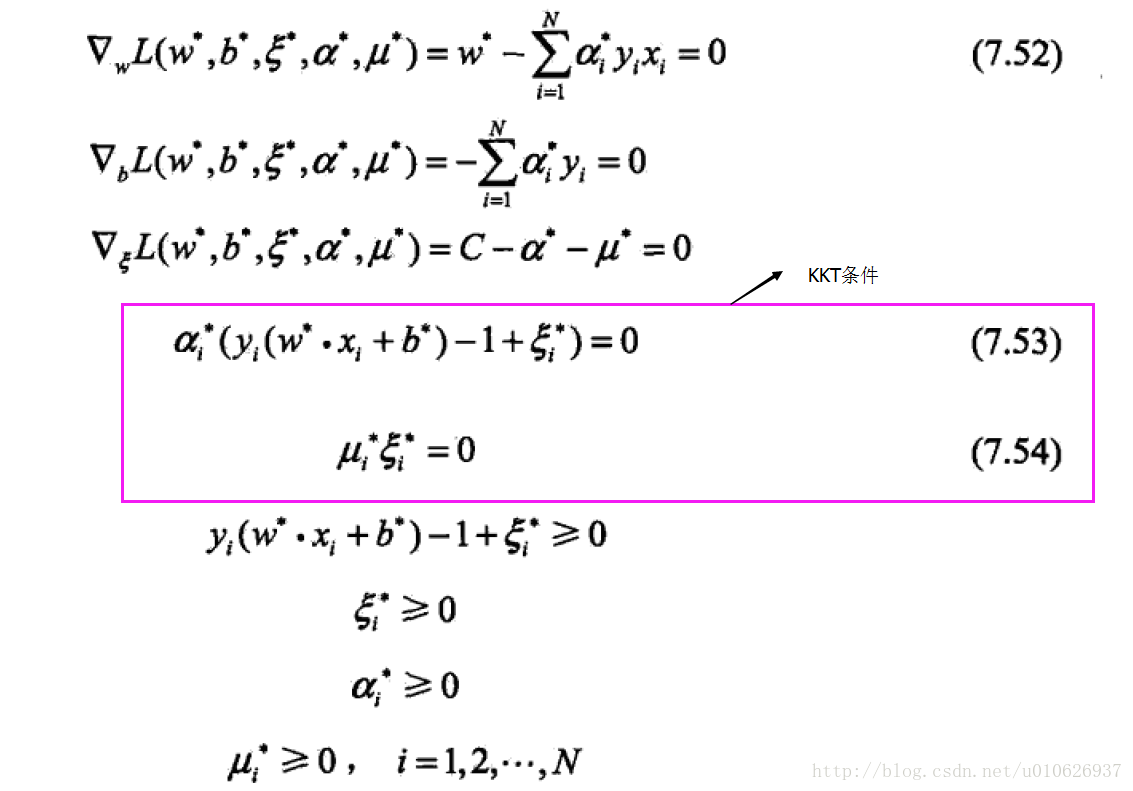
不明白KKT条件的,请点击这里
同时βi*和ξi*都需要大于等于0,对于0<=αi*<=C,可以分以下三种情况讨论:
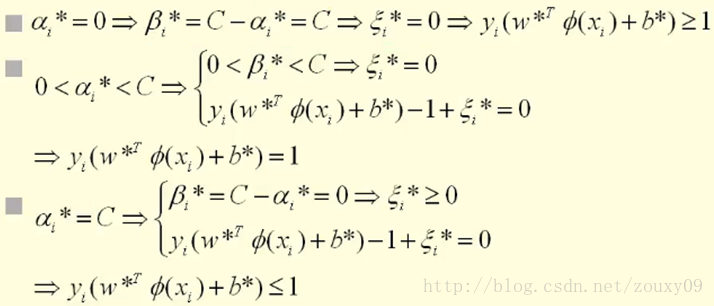
总的来说:
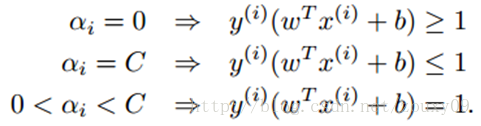
第一个式子表明如果αi=0,那么该样本落在两条间隔线外。第三个式子表明如果αi=C,那么该样本有可能落在两条间隔线内部,也有可能落在两条间隔线上面,主要看对应的松弛变量的取值是等于0还是大于0,(例如,当松弛变量等于0的时候,,此时该样本落在两条间隔线上,当松弛变量大于0的时候,
,此时的样本点落在两条间隔线之间);第二个式子表明如果
,那么该样本一定落在分隔线上(这点很重要,b就是拿这些落在分隔线上的点来求的,因为在分割线上wTx+b=1或者-1嘛,才是等式,在其他地方,都是不等式,求解不了b)。具体形象化的表示如下:
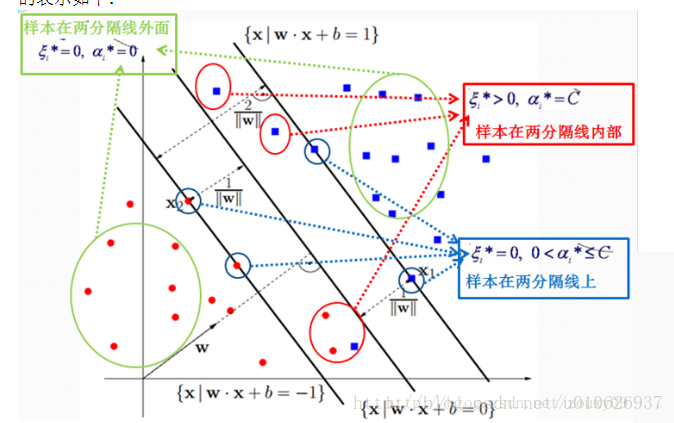
通过KKT条件可知,αi不等于0的都是支持向量,它有可能落在分隔线上,也有可能落在两条分隔线内部。
















 337
337

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











