






- .2D数字人技术
- 百度,腾讯,等大厂都有自己的数字平台制作(套壳:api+后台转发+vue前端),国外也有出名的heygen(非常厉害一个)
- 通过开源项目组合实现,再打通每个项目已api的形式提供调用。
- 对口型
- 不对口型
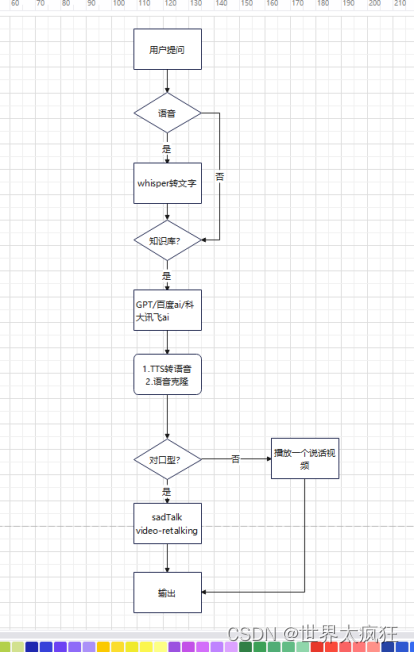
- 组合形式(ai 项目总结)
- 素材准备
a.1张图片或者自己拍摄一个短10秒钟视频(图片效果肯定没有视频好)
b.全新制作一个不存在现实的数字人(制作)
2.全新数字人形象制作。
(1)技术软件:Stable_Diffusion或者Fooocus
选择:Fooocus (对标sd,使用简单,对机器要求不高!)
GitHub - lllyasviel/Fooocus: Focus on prompting and generating
提示词:Beautiful girl with a clear front and face
获得一张形象图片保存好。
Ai软件安装流程大多(每个人遇到问题都可能不一样,使用系统不一样):
conda create -n 名称xx python=xxx
conda activate 名称xx
安装torch touchversion 这里要注意电脑有cuda的可以到
Start Locally | PyTorch 上下载对应的torch 安装 例如下面:pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
安装环境: pip isntall -r requirements.txt
遇到问题:
0.先到项目git的Issues上面查找,一般都能找到。
1.GPT等工具查找问题
2.google或者百度
3.技术群询问
- .10秒视频准备。
- 可以自己拍摄(必须是脸部清晰)
- 去网站上面找,这里就找了韩国美女。
- .换脸:把之前虚拟图片脸换到视频上
技术选型:facefusion
GitHub - facefusion/facefusion: Next generation face swapper and enhancer
- .高清修复。
技术选型:CodeFormer
- 剪影工具裁剪出稳定脸部清晰的2到3帧再拼接成10秒视频,需要注意就是拼接时候要反向合并视频。
- 语音克隆。
技术选型有2种,
- GitHub - Plachtaa/VITS-fast-fine-tuning: This repo is a pipeline of VITS finetuning for fast speaker adaptation TTS, and many-to-many voice conversion
- https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI
选择:RVC 原因就是效果比较好,这样需要知道就是现在语音克隆有两种在底模训练好情况下:
一种是Text-to-speed 也就是文字到语音,测试下来效果不太稳定,10句同样文字输出速率都有可能不一样!
第二种RVC,speed-to-speed 语音到语音,比较稳,但是这里就要多做一步文字转语音再转,这里推荐使用微软免费tts,多国语言选择参考:https://github.com/rany2/edge-tts
pip install edge-tts
edge-tts --voice zh-CN-YunxiNeural --rate=-4% --text "hello 大家好" --write-media hello1.mp3
速度其实和第一种区别不大,RVC转换很快。
- 对口型video-retalking。
- 通过上面的项目进行串联使用api形式进行调用(暂无)。
输入文字=》tts==>RVC ==>video-retalking==>视频














 620
620











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









