







 本文介绍了如何使用Udacity的自动驾驶数据集,包括dataset1和dataset2,涉及数据格式转换、类别处理、预处理代码以及数据集整理成VOC格式的过程。
本文介绍了如何使用Udacity的自动驾驶数据集,包括dataset1和dataset2,涉及数据格式转换、类别处理、预处理代码以及数据集整理成VOC格式的过程。
一、dataset1
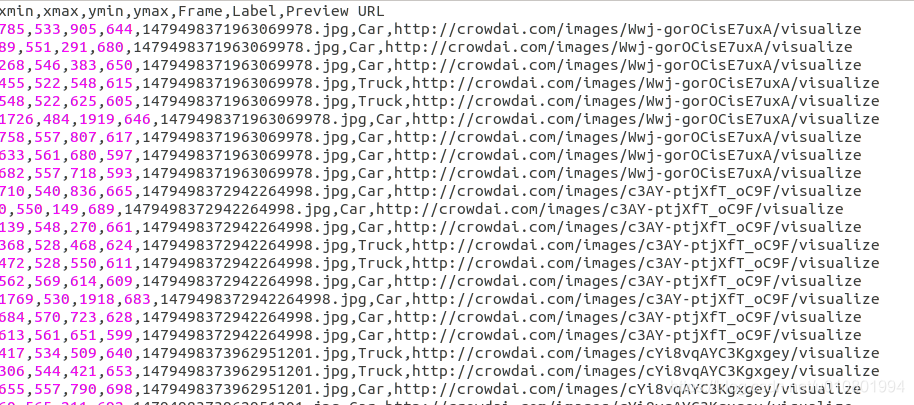
下载dataset1,该数据集大小为1.5G,共有9420张图像。label格式如下图所示,共有Car、Truck、Pedestrian三类。(使用数据格式转化工具可直接实现voc格式的转化,参考博客LITTI、VOC、Udacity等自动驾驶数据集下载及格式转化)
实现:
python main.py --from udacity-crowdai --from-path -crowdai --to voc --to-path datasets
生成类别为:car、truck、person
二、dataset2
下载dataset2,该数据集大小为3.3G,共有15000张图像。label格式如下图所示,共有Car、Truck、Pedestrian、trafficLight(Red、RedLeft、Green、Yellow、YellowLeft)、biker这些类别。其中,有标签的图片共有13063张,暂时不用管,在转化voc过程中,可直接实现无标签图像的清除。
原label的格式如下图
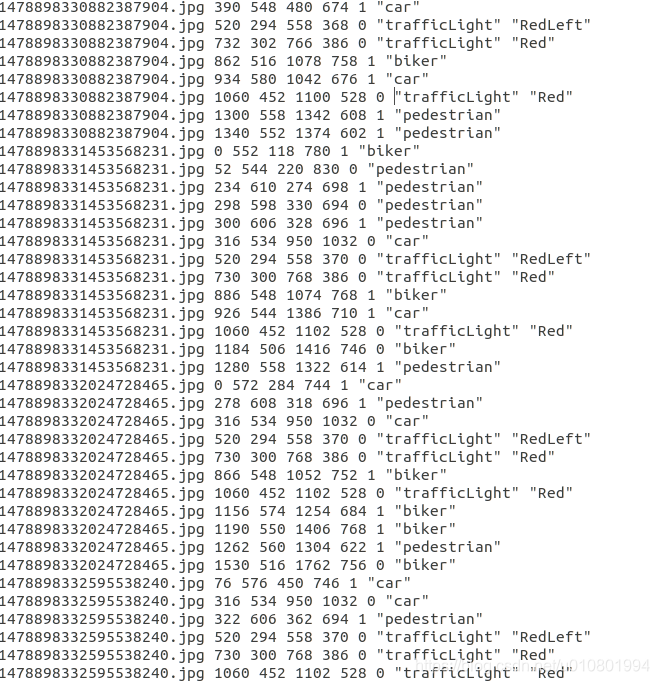
在trafficLight标签类别下,由于想要选取最后一列字符串作为标签label,对该格式文件进行预处理,生成新的格式统一的标签label文件,preprocess.py代码如下:
# preprocess.py
file = open('labels.csv', 'r').readlines()
fileout = open('labels1.csv', 'w')
for line  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1061
1061

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









