









 本文详细介绍如何在IDEA中配置Hive驱动并成功连接Hive数据库,包括配置步骤及常见问题解决方法。
本文详细介绍如何在IDEA中配置Hive驱动并成功连接Hive数据库,包括配置步骤及常见问题解决方法。
问题:
IDEA 是现在很流行的开发工具,其功能很强大,其自带一个数据库连接工具,该工具可以连接mysql,oracle等常用数据库,那么问题来了,我能不能用这个工具连接hive数据库了
经过我的不断尝试,终于可以连接查询hive了!
解决办法:
步骤如下图:
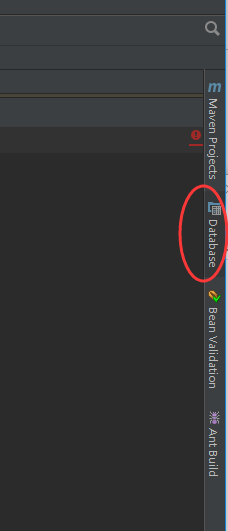
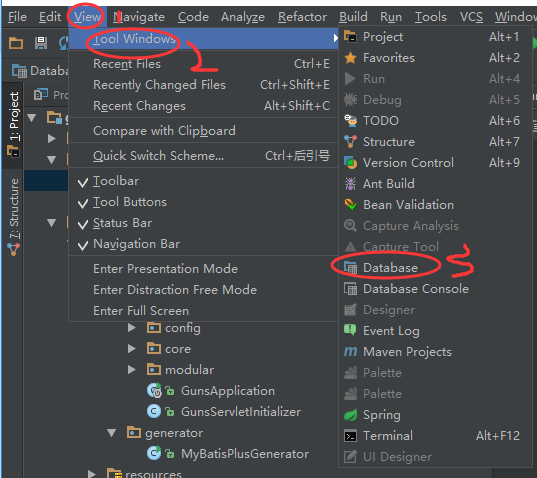
1.如果idea中最右侧你没有看到database这个选项卡那么请按照下图将其显示出来
2.因为IDEA没有内置hive的驱动,所以需要自己新建一个Driver,如下图:
2.1 先打开Database工具,选择Database Source Properties
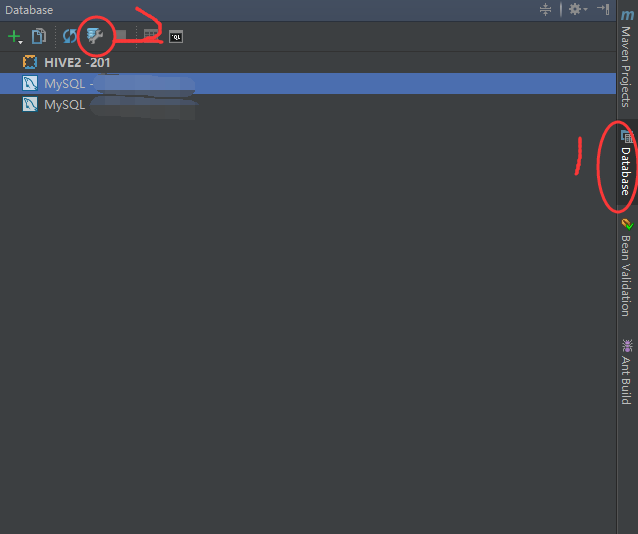
2.2 选择新建Driver
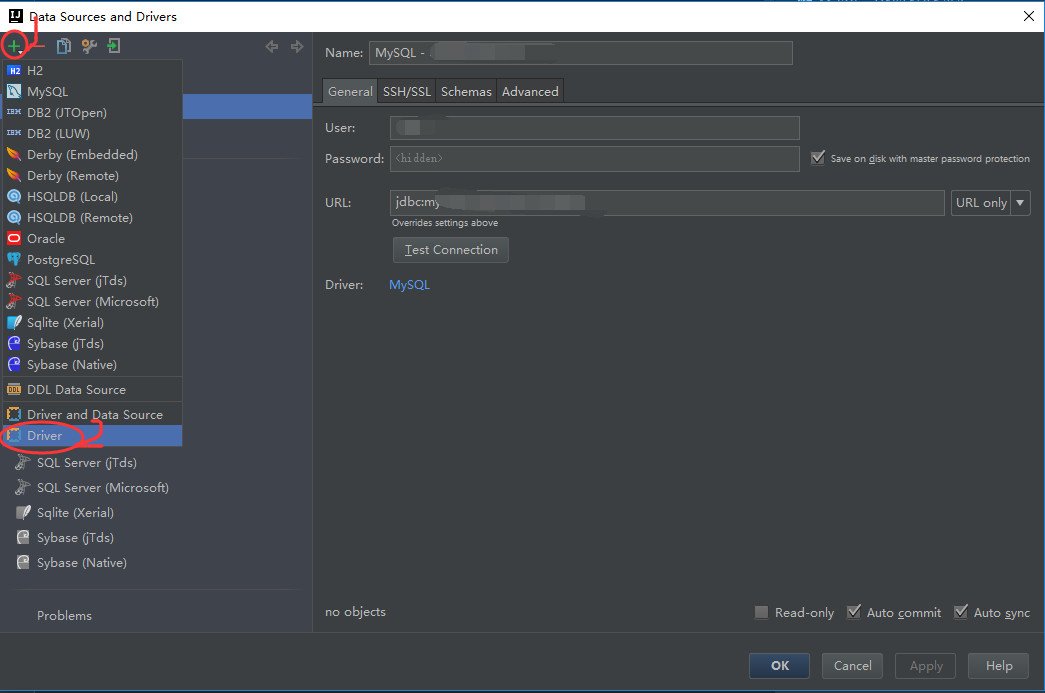
2.3 选择后自动跳转出现新建Driver配置页面
- 修改Name名字(命名驱动的名字,此处我命名为HIVE2)
- 点击绿色+,添加hive相关驱动jar包(我将所有jar包全部放在一个文件夹中,命名为hivelib)
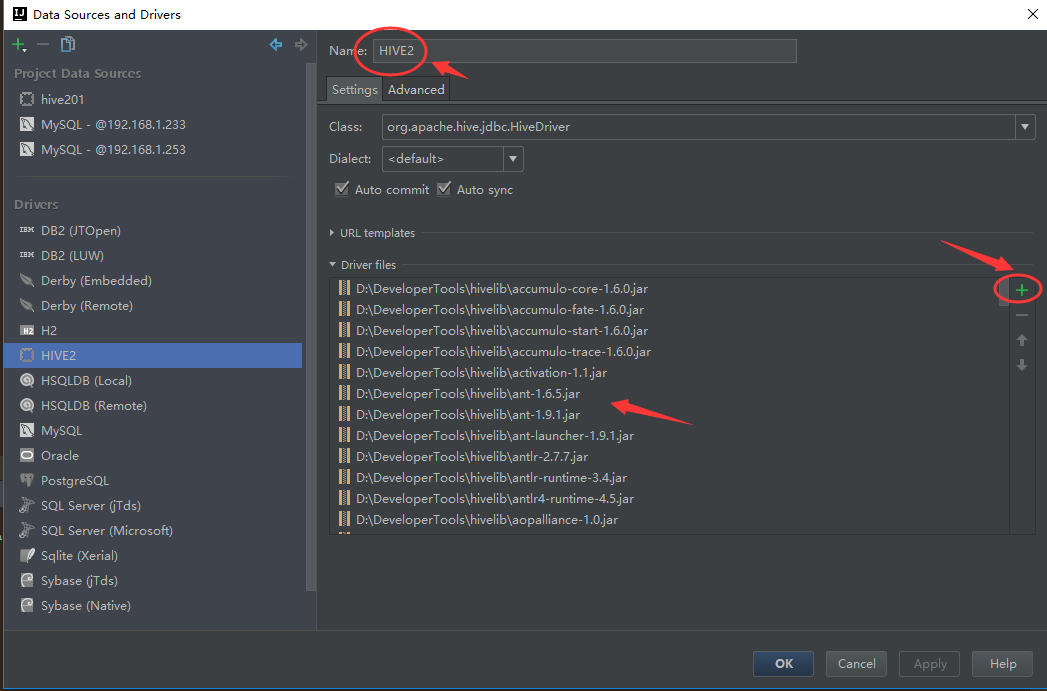
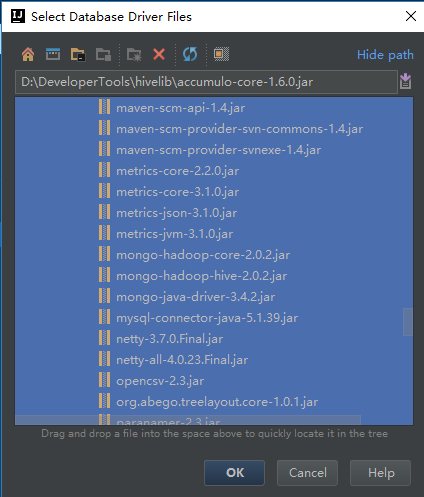
- 选择了jar包后需要等待IDEA扫描jar包,在IDEA下方会出现扫描进度条,如下图

- 扫描完成后,选择驱动的class为org.apache.hive.jdbc.HiveDriver
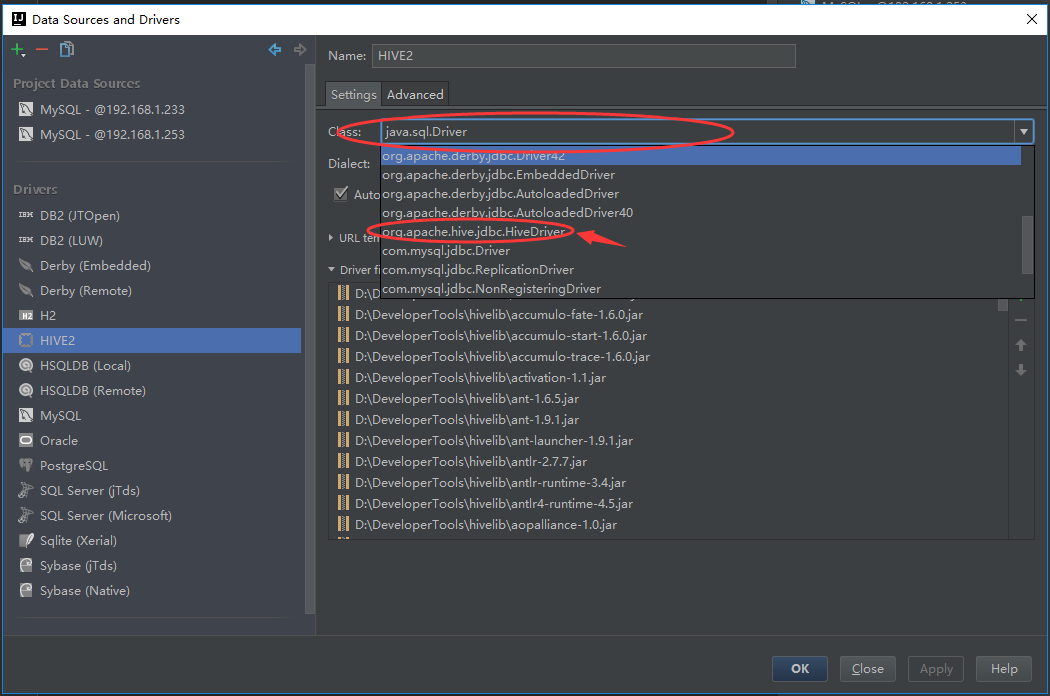
完成配置,点击OK保存,这个步骤可能点击保存了时没有反应(目前没有找到原因,可以多重复这个步骤几次就保存成功了!有知道原因的朋友可以留言,学习一下)
2021-09-22 更新:
现在可以在线下载驱动了,无需手动导入:
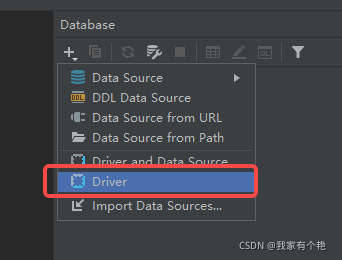
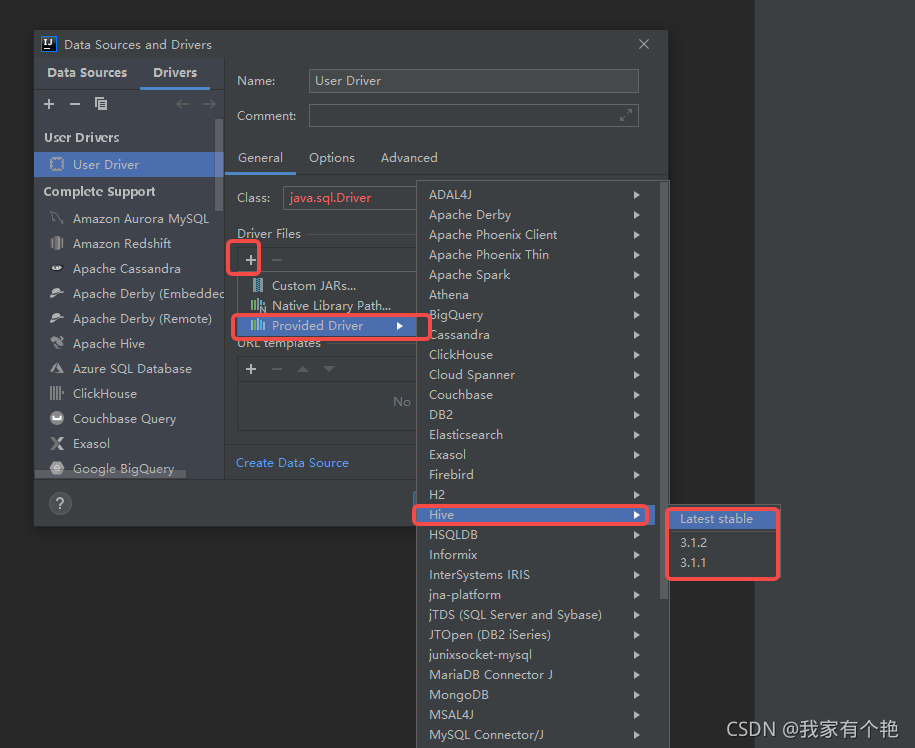
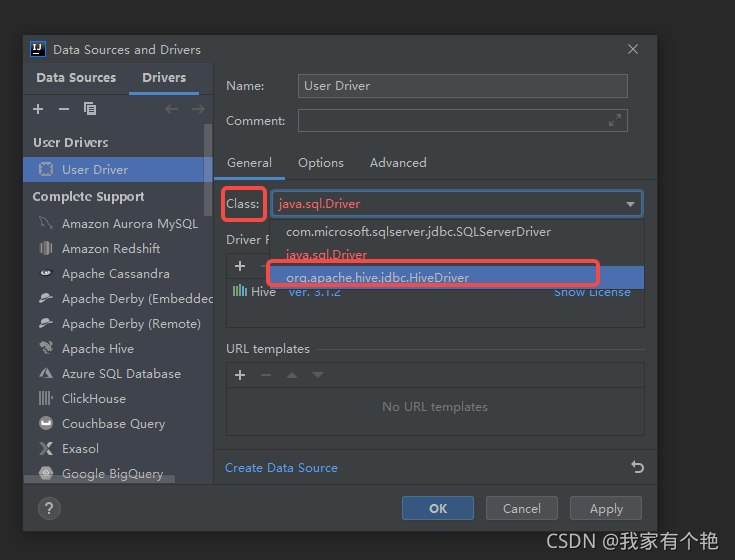
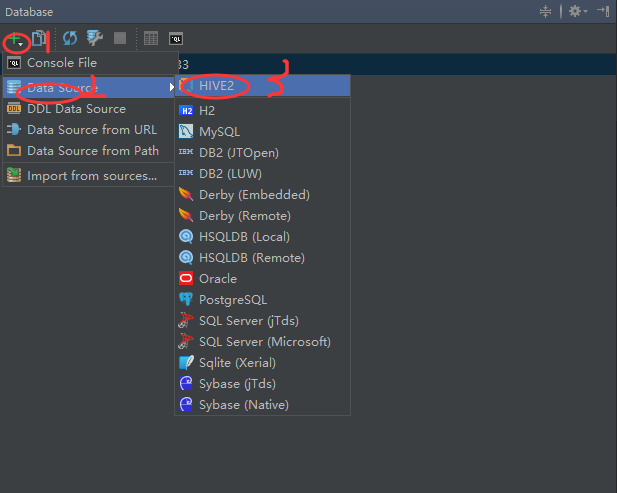
3.到这里驱动已经新建成功了,现在可以新建连接了,如下图
4.修改连接名称(Name),用户名,密码以及链接地址(url格式为:jdbc:hive2://ip地址:port端口号/database数据库)
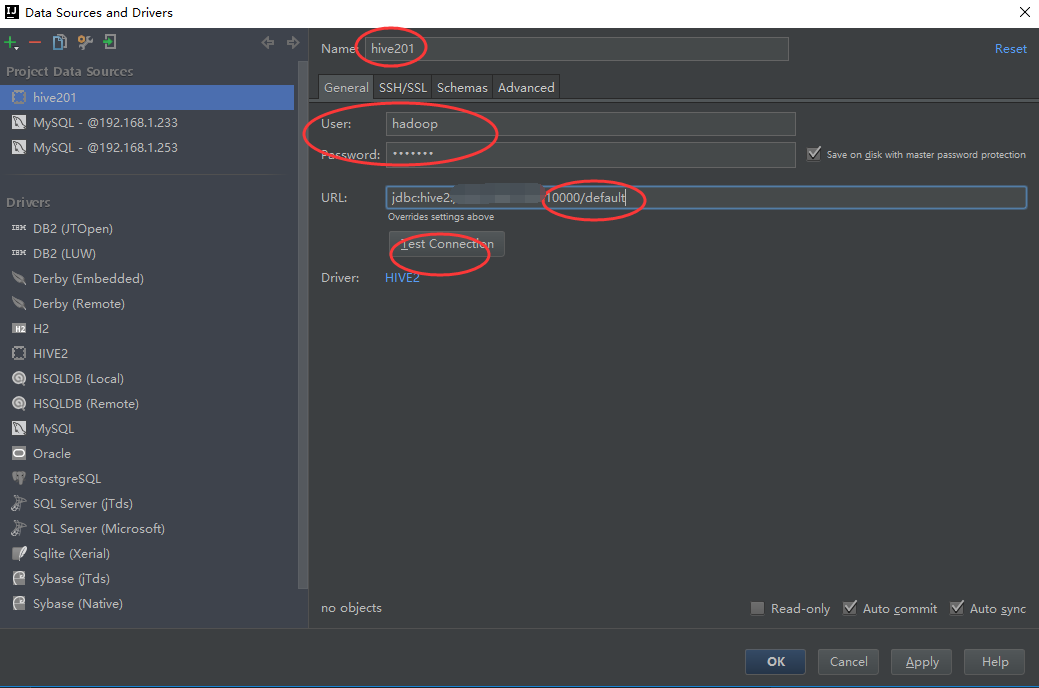
5.填写完成后可以点击Test Connection进行连接测试
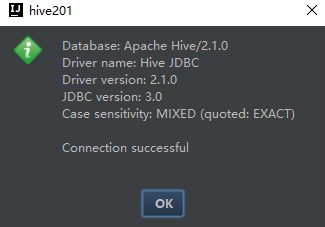
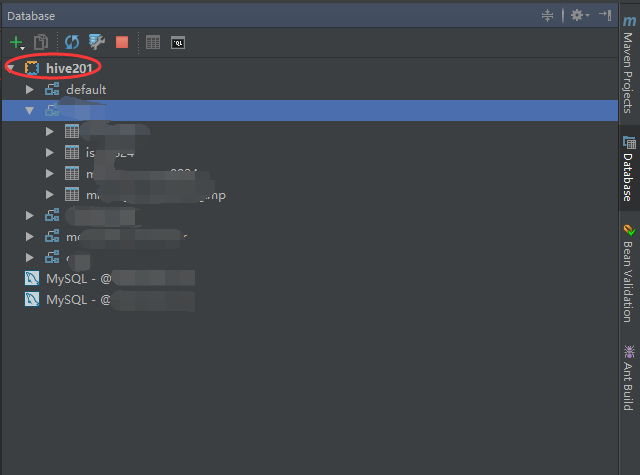
6.测试成功后,点击OK保存,在右侧的Database工具中就会出现新建的连接,可以查看到各个数据库以及库下的每张表
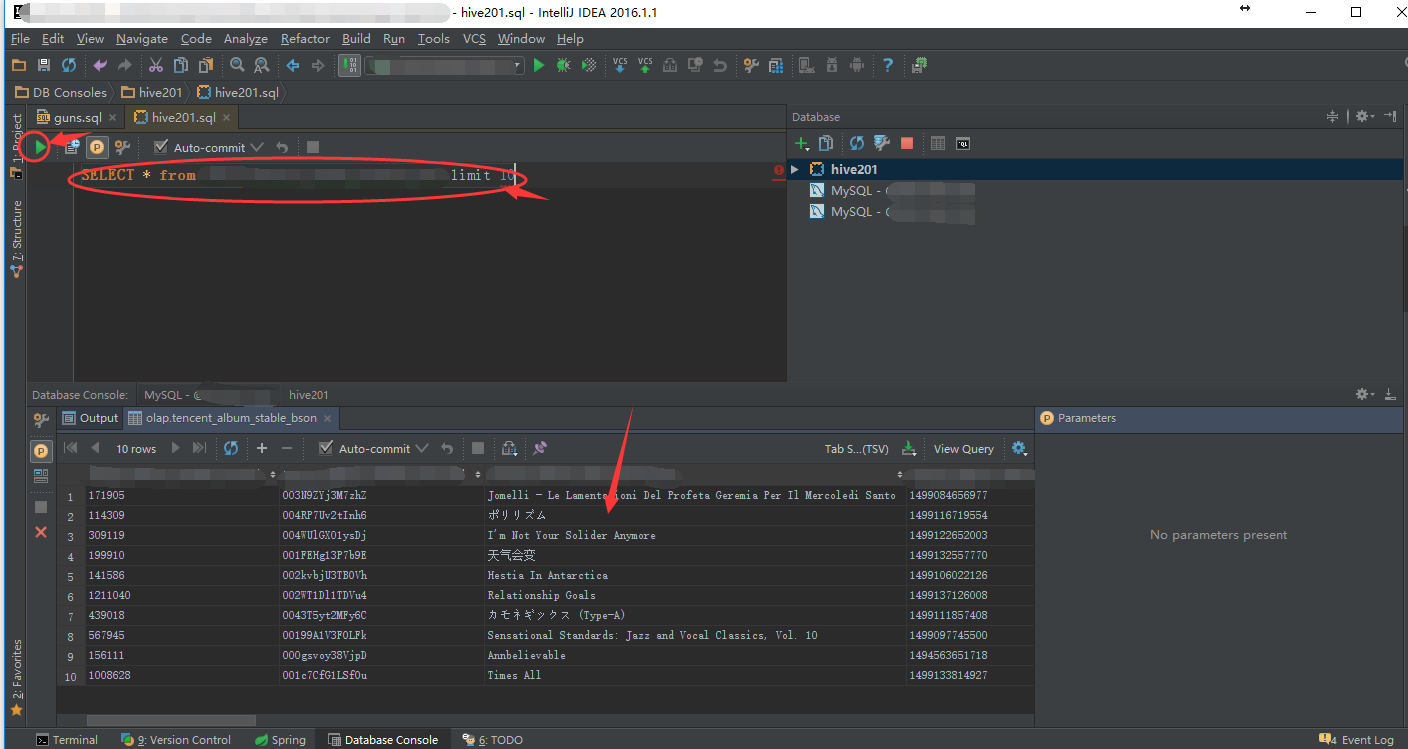
7.双击该连接,会弹出一个页面,可以写一句sql进行测试,写好之后运行的快捷键为ctrl+enter(也可以点击绿色的三角形按钮),查询结果会出现在下方,如下图
总结:到此使用Database工具连接hive完成(此类配置方式应该适用于其他可以使用jdbc连接的数据库,大家可以自己尝试)
可能出现的问题:测试时出现ClassNotFoundException,这个问题的原因是在新建驱动的时候添加的jar没有扫描成功,重新进行添加步骤可解决,或者是你没有添加相应jar包,请自行添加即可。
另附上我的hivelib下载地址如下(码字不容易,该连接下载需要1分的CSDN的下载积分,不下载也可以,我得到的积分也是用于下载别人分享的文件,希望理解支持,谢谢)
http://download.csdn.net/download/u010814849/9953863

















 205
205

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









