







SSE(Streaming SIMD Extensions)指令是一种SIMD 指令, Intrinsics函数则是对SSE指令的函数封装,利用C语言形式来调用SIMD指令集,大大提高了易读性和可维护。Intrinsics函数的使用可查看手册Intel Intrinsics Guide。
关于本文实现了单精度浮点数组的求和,切实感受SSE带来的速度提升。本文代码主要来自[1].
首先是不使用任何加速手段的求和函数:
//普通版
float sumfloat_base(const float *pbuf,unsigned int cntbuf)
{
float s=0;
for (unsigned int i=0;i<cntbuf;i++)
{
s+=pbuf[i];
}
return s;
}
在程序优化中有一种经常使用的方法:循环展开。循环展开可以降低循环开销,提高指令级并行性能,此处使用四路展开(测试表明,更多路展开难以带来更快的速度):
//四路展开
float sumfloat_base_4loop(const float*pbuf,unsigned int cntbuf)
{
float s=0;
float fSum0=0,fSum1=0,fSum2=0,fSum3=0;
unsigned int i=0;
const float *p=pbuf;
for (;i<=cntbuf-4;i+=4)//cntbuf-4不会每次都计算,编译器实现会计算好循环次数!
{
fSum0+=p[i];
fSum1+=p[i+1];
fSum2+=p[i+2];
fSum3+=p[i+3];
}
s=fSum0+fSum1+fSum2+fSum3;
for (;i<cntbuf;i++)
{
s+=p[i];
}
return s;
}接着使用SSE 进行加速,由于SSE寄存器位宽128,因此一次能处理4个float类型的数据。SSE指令要求内存地址按16字节对齐,因此在声明缓冲区时使用了__declspec(align(16))。对于动态申请的内存可使用_aligned_malloc。
//SSE版
float sumfloat_sse(const float *pbuf ,unsigned int cntbuf)
{
float s=0;
int nBlockWidth=4;//SSE一次处理4个float
int cntBlock=cntbuf/nBlockWidth;
int cntRem=cntbuf%nBlockWidth;
__m128 fSum=_mm_setzero_ps();//求和变量,初值清零
__m128 fLoad;
const float*p=pbuf;
for (unsigned int i=0;i<cntBlock;i++)
{
fLoad=_mm_load_ps(p);//加载
fSum=_mm_add_ps(fSum,fLoad);//求和
p+=nBlockWidth;
}
const float *q=(const float*)&fSum;
s=q[0]+q[1]+q[2]+q[3]; //合并
for (int i=0;i<cntRem;i++)//处理尾部剩余数据
{
s+=p[i];
}
return s;
}本程序中使用的Intrinsics函数为:
__m128 _mm_load_ps (float const* mem_addr):
从16字节对齐的内存mem_addr中加载128位(4个单精度浮点数)到寄存器。对应指令 movaps xmm,m128
__m128 _mm_setzero_ps (void):返回一个_m128类型的全零向量。对应指令:xorps xmm, xmm
__m128 _mm_add_ps (__m128 a, __m128 b):将4对32位浮点数同时进行相加操作。这4对32位浮点数来自两个128位的存储单元,再把计算结果(相加之和)赋给一个128位的存储单元。对应指令:addps xmm,xmm
void _mm_store_ps (float* mem_addr, __m128 a):将128位数据存入16字节对齐的内存中。对应指令:movaps m128, xmm
最后在SSE版本中再次使用循环展开:
//SSE+四路展开
float sumfloat_sse_4loop(const float *pbuf,unsigned int cntbuf)
{
float s=0;
unsigned int nBlockWidth=4*4;
unsigned int cntBlock=cntbuf/nBlockWidth;
unsigned int cntRem=cntbuf%nBlockWidth;
__m128 fSum0=_mm_setzero_ps();//求和变量,初值清零
__m128 fSum1=_mm_setzero_ps();
__m128 fSum2=_mm_setzero_ps();
__m128 fSum3=_mm_setzero_ps();
__m128 fLoad0,fLoad1,fLoad2,fLoad3;
const float *p=pbuf;
for (unsigned int i=0;i<cntBlock;i++)
{
fLoad0=_mm_load_ps(p);//加载
fLoad1=_mm_load_ps(p+4);
fLoad2=_mm_load_ps(p+8);
fLoad3=_mm_load_ps(p+12);
fSum0=_mm_add_ps(fSum0,fLoad0);//求和
fSum1=_mm_add_ps(fSum1,fLoad1);
fSum2=_mm_add_ps(fSum2,fLoad2);
fSum3=_mm_add_ps(fSum3,fLoad3);
p+=nBlockWidth;
}
fSum0=_mm_add_ps(fSum0,fSum1);
fSum2=_mm_add_ps(fSum2,fSum3);
fSum0=_mm_add_ps(fSum0,fSum2);
const float*q=(const float*)&fSum0;
s=q[0]+q[1]+q[2]+q[3]; //合并
for (unsigned int i=0;i<cntRem;i++)//处理尾部剩余数据
{
s+=p[i];
}
return s;
}完整程序:
Timing.h
#include <windows.h>
static _LARGE_INTEGER time_start, time_over;
static double dqFreq;
static inline void startTiming()
{
_LARGE_INTEGER f;
QueryPerformanceFrequency(&f);
dqFreq=(double)f.QuadPart;
QueryPerformanceCounter(&time_start);
}
static inline double stopTiming()
{
QueryPerformanceCounter(&time_over);
return ((double)(time_over.QuadPart-time_start.QuadPart)/dqFreq*1000);
}
#include <stdio.h>
#include <intrin.h>
#include <stdlib.h>
#include <time.h>
#include "Timing.h"
#define BUFSIZE 4096 // = 32KB{L1 Cache} / (2 * sizeof(float))
__declspec(align(16))float buf[BUFSIZE];//内存对齐
typedef float (*TESTPROC)(const float* pbuf, unsigned int cntbuf);//函数指针(用于测试时统一表示)
void RunTest(const char *szname,TESTPROC proc);
float sumfloat_base(const float *pbuf,unsigned int cntbuf);
float sumfloat_base_4loop(const float*pbuf,unsigned int cntbuf);
float sumfloat_sse(const float *pbuf ,unsigned int cntbuf);
float sumfloat_sse_4loop(const float *pbuf,unsigned int cntbuf);
int main()
{
srand( (unsigned)time( NULL ) );
for (int i = 0; i < BUFSIZE; i++)
buf[i] = (float)(rand() & 0x3f);// 使用&0x3f是为了让求和后的数值不会超过float类型的有效位数,便于观察结果是否正确.
RunTest("sumfloat_base",sumfloat_base);
RunTest("sumfloat_base_4loop",sumfloat_base_4loop);
RunTest("sumfloat_sse",sumfloat_sse);
RunTest("sumfloat_sse_4loop",sumfloat_sse_4loop);
return 0;
}
//测试函数
void RunTest(const char *szname,TESTPROC proc)
{
unsigned int testloop=4000;//循环次数
volatile float result;//volatile类型放止编译器优化使得循环内部不执行!
double mpsgood=0;
double mps;
for (int k=0;k<=3;k++)//循环多次,选取最好情况
{
startTiming();
for(unsigned int i=0;i<testloop;i++)
{
result=proc(buf,BUFSIZE);
}
double interval=stopTiming();
mps=testloop*BUFSIZE*4*1000.0/(interval*1024*1024);//单位MB/s
if (mpsgood<mps)mpsgood=mps;
}
printf("%s:\t%f,\t%.0lfMB/s\n",szname,result,mpsgood);//测速单位MB/s
}
//普通版
float sumfloat_base(const float *pbuf,unsigned int cntbuf)
{
float s=0;
for (unsigned int i=0;i<cntbuf;i++)
{
s+=pbuf[i];
}
return s;
}
//四路展开
float sumfloat_base_4loop(const float*pbuf,unsigned int cntbuf)
{
float s=0;
float fSum0=0,fSum1=0,fSum2=0,fSum3=0;
unsigned int i=0;
const float *p=pbuf;
for (;i<=cntbuf-4;i+=4)//cntbuf-4不会每次都计算,编译器实现会计算好循环次数!
{
fSum0+=p[i];
fSum1+=p[i+1];
fSum2+=p[i+2];
fSum3+=p[i+3];
}
s=fSum0+fSum1+fSum2+fSum3;
for (;i<cntbuf;i++)
{
s+=p[i];
}
return s;
}
//SSE版
float sumfloat_sse(const float *pbuf ,unsigned int cntbuf)
{
float s=0;
int nBlockWidth=4;//SSE一次处理4个float
int cntBlock=cntbuf/nBlockWidth;
int cntRem=cntbuf%nBlockWidth;
__m128 fSum=_mm_setzero_ps();//求和变量,初值清零
__m128 fLoad;
const float*p=pbuf;
for (unsigned int i=0;i<cntBlock;i++)
{
fLoad=_mm_load_ps(p);//加载
fSum=_mm_add_ps(fSum,fLoad);//求和
p+=nBlockWidth;
}
const float *q=(const float*)&fSum;
s=q[0]+q[1]+q[2]+q[3]; //合并
for (int i=0;i<cntRem;i++)//处理尾部剩余数据
{
s+=p[i];
}
return s;
}
//SSE+四路展开
float sumfloat_sse_4loop(const float *pbuf,unsigned int cntbuf)
{
float s=0;
unsigned int nBlockWidth=4*4;
unsigned int cntBlock=cntbuf/nBlockWidth;
unsigned int cntRem=cntbuf%nBlockWidth;
__m128 fSum0=_mm_setzero_ps();//求和变量,初值清零
__m128 fSum1=_mm_setzero_ps();
__m128 fSum2=_mm_setzero_ps();
__m128 fSum3=_mm_setzero_ps();
__m128 fLoad0,fLoad1,fLoad2,fLoad3;
const float *p=pbuf;
for (unsigned int i=0;i<cntBlock;i++)
{
fLoad0=_mm_load_ps(p);//加载
fLoad1=_mm_load_ps(p+4);
fLoad2=_mm_load_ps(p+8);
fLoad3=_mm_load_ps(p+12);
fSum0=_mm_add_ps(fSum0,fLoad0);//求和
fSum1=_mm_add_ps(fSum1,fLoad1);
fSum2=_mm_add_ps(fSum2,fLoad2);
fSum3=_mm_add_ps(fSum3,fLoad3);
p+=nBlockWidth;
}
fSum0=_mm_add_ps(fSum0,fSum1);
fSum2=_mm_add_ps(fSum2,fSum3);
fSum0=_mm_add_ps(fSum0,fSum2);
const float*q=(const float*)&fSum0;
s=q[0]+q[1]+q[2]+q[3]; //合并
for (unsigned int i=0;i<cntRem;i++)//处理尾部剩余数据
{
s+=p[i];
}
return s;
}测试结果:
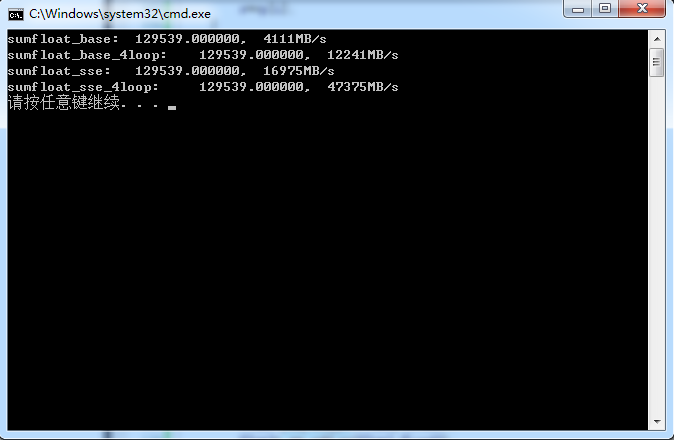
[1]http://www.cnblogs.com/zyl910/archive/2012/10/22/simdsumfloat.html#undefined
















 775
775

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











