










Makefile 中 ARCH参数设置
我的计算机设置为
ARCH= -gencode arch=compute_50,code=[sm_50,compute_50]
显卡为GTX 950M
网上介绍一堆堆原理,没一个实用的参数设置,这里给你需要的东西
查看CUDA版本
john@john-wang:~/yolov3/yolov3_mask_detect$ nvcc -V
查看显卡
john@john-wang:~/yolov3/yolov3_mask_detect$ nvidia-smi
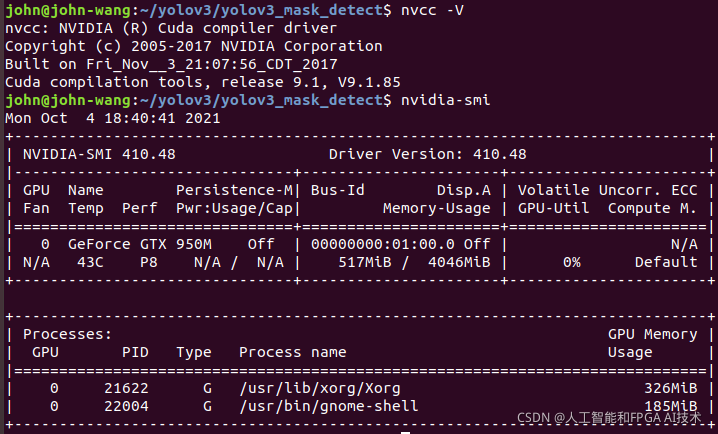
这里应有你需要的
https://github.com/dedoogong/cuda
cuda programming examples
CUDA Architecture CC version
Tegra X2 6.2 nvcc_ARCH = -gencode=arch=compute_62,code=“sm_62,compute_62”
GeForce GTX 1080 6.1 (CUDA 8) nvcc_ARCH = -gencode=arch=compute_61,code=“sm_61,compute_61”
GeForce GTX 1070 6.1 (CUDA 8) nvcc_ARCH = -gencode=arch=compute_61,code=“sm_61,compute_61”
GeForce GTX 1060 6.1 (CUDA 8) nvcc_ARCH = -gencode=arch=compute_61,code=“sm_61,compute_61”
Tesla P100 6.0 (CUDA 8) nvcc_ARCH = -gencode=arch=compute_60,code=“sm_60,compute_60”
Tegra X1 5.3 nvcc_ARCH = -gencode=arch=compute_53,code=“sm_53,compute_53”
GeForce GTX TITAN X 5.2 nvcc_ARCH = -gencode=arch=compute_52,code=“sm_52,compute_52”
GeForce GTX 980 Ti 5.2 nvcc_ARCH = -gencode=arch=compute_52,code=“sm_52,compute_52”
GeForce GTX 980 5.2 nvcc_ARCH = -gencode=arch=compute_52,code=“sm_52,compute_52”
GeForce GTX 970 5.2 nvcc_ARCH = -gencode=arch=compute_52,code=“sm_52,compute_52”
GeForce GTX 960 5.2 nvcc_ARCH = -gencode=arch=compute_52,code=“sm_52,compute_52”
GeForce GTX 950 5.2 nvcc_ARCH = -gencode=arch=compute_52,code=“sm_52,compute_52”
GeForce GTX 980 5.2 nvcc_ARCH = -gencode=arch=compute_52,code=“sm_52,compute_52”
GeForce GTX 980M 5.2 nvcc_ARCH = -gencode=arch=compute_52,code=“sm_52,compute_52” GeForce GTX 970M 5.2 nvcc_ARCH = -gencode=arch=compute_52,code=“sm_52,compute_52” GeForce GTX 965M 5.2 nvcc_ARCH = -gencode=arch=compute_52,code=“sm_52,compute_52” GeForce 920M 5.2 nvcc_ARCH = -gencode=arch=compute_52,code=“sm_52,compute_52” GeForce 910M 5.2 nvcc_ARCH = -gencode=arch=compute_52,code=“sm_52,compute_52” Quadro M6000 5.2 nvcc_ARCH = -gencode=arch=compute_52,code=“sm_52,compute_52” Quadro M5000 5.2 nvcc_ARCH = -gencode=arch=compute_52,code=“sm_52,compute_52” Quadro M4000 5.2 nvcc_ARCH = -gencode=arch=compute_52,code=“sm_52,compute_52” GeForce GTX 750 Ti 5 nvcc_ARCH = -gencode=arch=compute_50,code=“sm_50,compute_50” GeForce GTX 750 5 nvcc_ARCH = -gencode=arch=compute_50,code=“sm_50,compute_50” GeForce GTX 960M 5 nvcc_ARCH = -gencode=arch=compute_50,code=“sm_50,compute_50” GeForce GTX 950M 5 nvcc_ARCH = -gencode=arch=compute_50,code=“sm_50,compute_50” GeForce 940M 5 nvcc_ARCH = -gencode=arch=compute_50,code=“sm_50,compute_50” GeForce 930M 5 nvcc_ARCH = -gencode=arch=compute_50,code=“sm_50,compute_50” GeForce GTX 850M 5 nvcc_ARCH = -gencode=arch=compute_50,code=“sm_50,compute_50” GeForce 840M 5 nvcc_ARCH = -gencode=arch=compute_50,code=“sm_50,compute_50” GeForce 830M 5 nvcc_ARCH = -gencode=arch=compute_50,code=“sm_50,compute_50” Quadro K2200 5 nvcc_ARCH = -gencode=arch=compute_50,code=“sm_50,compute_50” Quadro K1200 5 nvcc_ARCH = -gencode=arch=compute_50,code=“sm_50,compute_50” Quadro K620 5 nvcc_ARCH = -gencode=arch=compute_50,code=“sm_50,compute_50” Quadro K2200M 5 nvcc_ARCH = -gencode=arch=compute_50,code=“sm_50,compute_50” Quadro K620M 5 nvcc_ARCH = -gencode=arch=compute_50,code=“sm_50,compute_50” Tesla K80 3.7 nvcc_ARCH = -gencode=arch=compute_35,code=“sm_35,compute_35” GeForce GTX TITAN Z 3.5 nvcc_ARCH += -gencode=arch=compute_35,code=“sm_35,compute_35” GeForce GTX TITAN Black 3.5 nvcc_ARCH += -gencode=arch=compute_35,code=“sm_35,compute_35” GeForce GTX TITAN 3.5 nvcc_ARCH += -gencode=arch=compute_35,code=“sm_35,compute_35” GeForce GTX 780 Ti 3.5 nvcc_ARCH += -gencode=arch=compute_35,code=“sm_35,compute_35” GeForce GTX 780 3.5 nvcc_ARCH += -gencode=arch=compute_35,code=“sm_35,compute_35” GeForce GT 730 3.5 nvcc_ARCH += -gencode=arch=compute_35,code=“sm_35,compute_35” GeForce GT 720 3.5 nvcc_ARCH += -gencode=arch=compute_35,code=“sm_35,compute_35” GeForce GT 705* 3.5 nvcc_ARCH += -gencode=arch=compute_35,code=“sm_35,compute_35” GeForce GT 640 (GDDR5) 3.5 nvcc_ARCH += -gencode=arch=compute_35,code=“sm_35,compute_35” Quadro K6000 3.5 nvcc_ARCH = -gencode=arch=compute_35,code=“sm_35,compute_35” Quadro K5200 3.5 nvcc_ARCH = -gencode=arch=compute_35,code=“sm_35,compute_35” Quadro K610M 3.5 nvcc_ARCH = -gencode=arch=compute_35,code=“sm_35,compute_35” Quadro K510M 3.5 nvcc_ARCH = -gencode=arch=compute_35,code=“sm_35,compute_35” Tesla K40 3.5 nvcc_ARCH = -gencode=arch=compute_35,code=“sm_35,compute_35” Tesla K20 3.5 nvcc_ARCH = -gencode=arch=compute_35,code=“sm_35,compute_35” Tegra K1 3.2 nvcc_ARCH = -gencode=arch=compute_30,code=“sm_32,compute_30” Jetson TK1 3.2 nvcc_ARCH = -gencode=arch=compute_30,code=“sm_32,compute_30”
修改makefile中的GPU、CUDNN参数
GPU=1
CUDNN=1
OPENCV=1
OPENMP=1
DEBUG=0
convolutional_kernels.o failed



NVCC文件夹位置
#NVCC=nvcc
#NVCC=/usr/local/cuda-10.0/bin/nvcc
**NVCC=/usr/local/cuda/bin/nvcc**

#ARCH= -gencode arch=compute_30,code=sm_30 \
# -gencode arch=compute_35,code=sm_35 \
# -gencode arch=compute_50,code=[sm_50,compute_50] \
# -gencode arch=compute_52,code=[sm_52,compute_52]
# -gencode arch=compute_20,code=[sm_20,sm_21] \ This one is deprecated?
# This is what I use, uncomment if you know your arch and want to specify
# ARCH= -gencode arch=compute_52,code=compute_52
# ARCH= -gencode arch=compute_52,code=[sm_52,compute_52]
ARCH= -gencode arch=compute_50,code=[sm_50,compute_50]
CUDA Error: out of memory
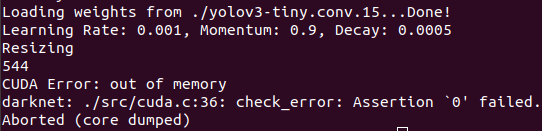
我的计算机为16M内存
batch=64
subdivisions=4
subdivision:这个参数很有意思的,它会让你的每一个batch不是一下子都丢到网络里。而是分成subdivision对应数字的份数,一份一份的跑完后,在一起打包算作完成一次iteration。这样会降低对显存的占用情况。如果设置这个参数为1的话就是一次性把所有batch的图片都丢到网络里,如果为2的话就是一次丢一半。
相对比只用CPU时的速度,快了20倍
输出参数含义
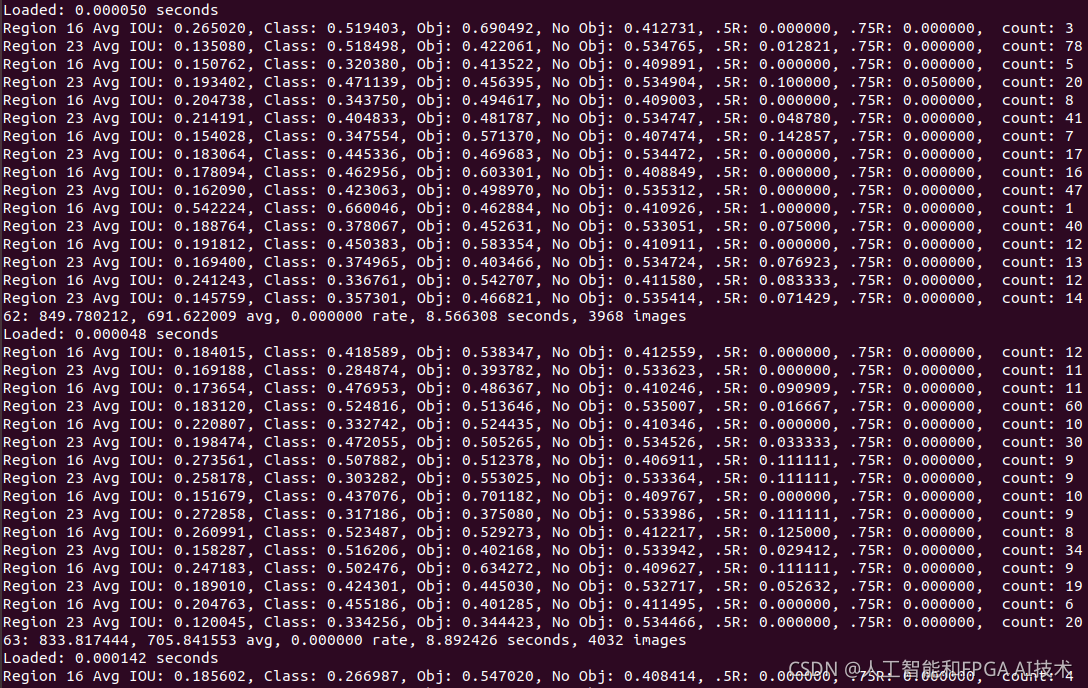
Region Avg IOU: 0.326577: 表示在当前subdivision内的图片的平均IOU,代表预测的矩形框和真实目标的交集与并集之比,这里是32.66%,这个模型需要进一步的训练。
Class: 0.742537: 标注物体分类的正确率,期望该值趋近于1。
Obj: 0.033966: 越接近1越好。
No Obj: 0.000793: 期望该值越来越小,但不为零。
Avg Recall: 0.12500: 是在recall/count中定义的,是当前模型在所有subdivision图片中检测出的正样本与实际的正样本的比值。在本例中,只有八分之一的正样本被正确的检测到。
count: 8:count后的值是所有的当前subdivision图片(本例中一共8张)中包含正样本的图片的数量。在输出log中的其他行中,可以看到其他subdivision也有的只含有6或7个正样本,说明在subdivision中含有不含检测对象的图片。
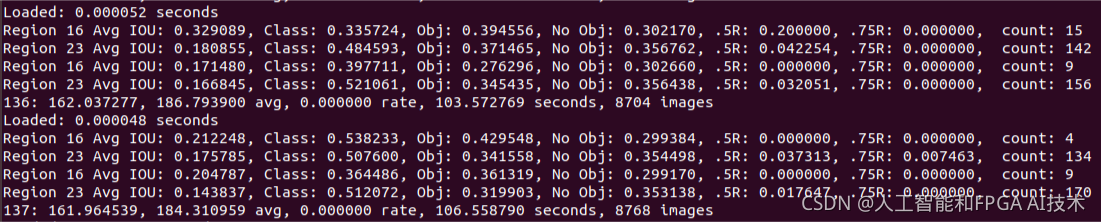
Region 16, Region 20表示两个不同尺度上检测的结果。
16卷积层为最大的预测尺度, 可以预测出较小的物体;
20卷积层为最小的预测尺度, 可以预测出较大的物体。
我们发现每次迭代都有两组Region 16, Region 20。
因为在darknet中,所有训练图片中的一个批次(batch)又被分成subdivision份来进行计算,而该训练过程 .cfg 文件中设置的batch=32,subdivisions=2,所以就有两组Region 16, Region 20,每组中用到了16张图片。
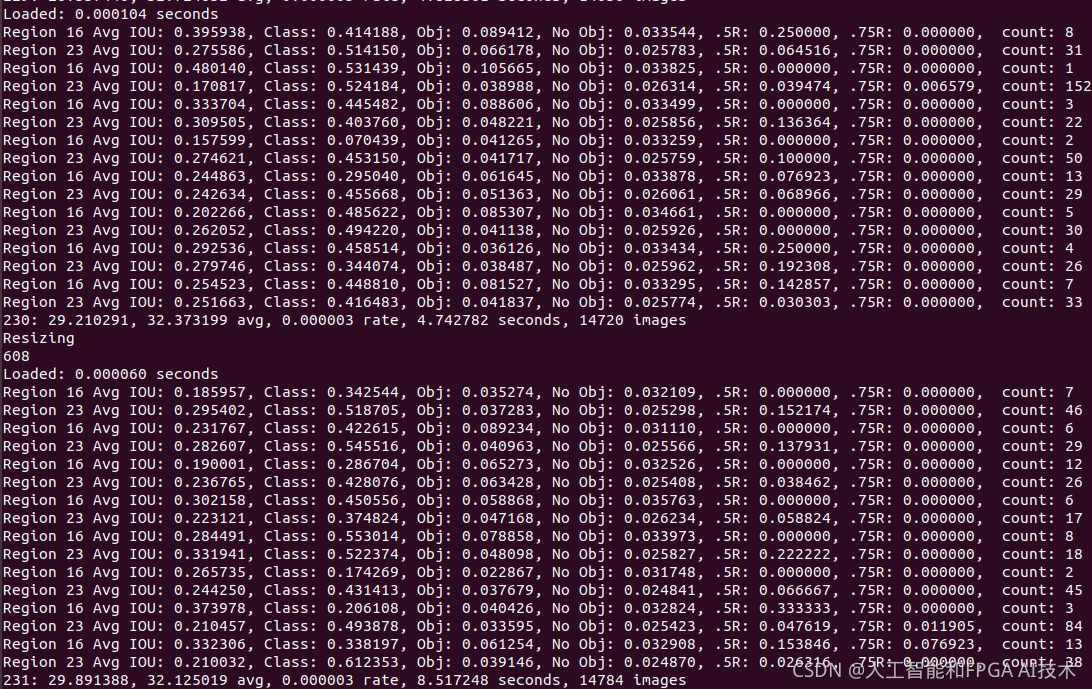
Region xx Avg IOU: 表示在当前subdivision内的图片的平均 IOU(预测的矩形框和真实目标的交集与并集之比);越大越好,最大为1。
Class: 标注物体分类的正确率;越大越好,最大为1。
Obj:越接近 1 越好;
No Obj:期望该值越来越小, 但不为零;
.5R:以与ground true的iou大于0.5为正样本时的recall/count,是当前模型在所有 subdivision 图片中检测出的正样本与实际的正样本的比值。全部的正样本被正确的检测到应该是1。
.75R:以与ground true的iou大于0.75为正样本时的recall/count。
count:所有当前 subdivision 图片(本例中一共 16张)中包含正样本的图片的数量。
用红色框框住的一行参数的含义为:
当前训练的迭代次数
总体的 Loss(损失)
平均 Loss, (一般这个数值低于 0.060730 avg 就可以终止训练了)
当前的学习率
当前批次训练花费的总时间
表示到目前为止, 参与训练的图片的总量;等于迭 代 次 数 ∗ b a t c h 迭代次数*batch迭代次数∗batch
————————————————
版权声明:本文为CSDN博主「干巴他爹」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/tintinetmilou/article/details/88877039
何时停止
Darknet图像训练的步骤 - 宋兴柱 - 博客园 https://www.cnblogs.com/songxingzhu/p/7909522.html
1、当训练过程中,平均Loss(error)不再减少时(Loss越小效果越好),可以停止。如下例中的9002表示当前已迭代次数,0.060730 avg表示Loss。
Region Avg IOU: 0.798363, Class: 0.893232, Obj: 0.700808, No Obj: 0.004567, Avg Recall: 1.000000, count: 8 Region Avg IOU: 0.800677, Class: 0.892181, Obj: 0.701590, No Obj: 0.004574, Avg Recall: 1.000000, count: 8
9002: 0.211667, 0.060730 avg, 0.001000 rate, 3.868000 seconds, 576128 images Loaded: 0.000000 seconds
2、训练开始后,从产生的backup目录下的多个还原点中,挑一个最好的。方法是:
(1)在obj.data文件中,修改valid=valid.txt(格式和train.txt一样),然后使用下列命令检测每个训练结果的效果。
darknet.exe detector recall data/obj.data yolo-obj.cfg backup\yolo-obj_7000.weights
darknet.exe detector recall data/obj.data yolo-obj.cfg backup\yolo-obj_8000.weights
darknet.exe detector recall data/obj.data yolo-obj.cfg backup\yolo-obj_9000.weights
(2)对比输出的结果中IOU(精度,越大越好,比较这个),Recall(也算精度,也是越大越好)。
7586 7612 7689 RPs/Img: 68.23 IOU: 77.86% Recall:99.00%
(3)测试检测效果:
darknet.exe detector test data/obj.data yolo-obj.cfg yolo-obj_8000.weights
darknet.exe detector map data/obj.data yolo-obj.cfg backup\yolo-obj_7000.weights
darknet.exe detector map data/obj.data yolo-obj.cfg backup\yolo-obj_8000.weights
darknet.exe detector map data/obj.data yolo-obj.cfg backup\yolo-obj_9000.weights
./darknet detector map ./cfg/yolov3-tiny.data ./cfg/yolov3-tiny.cfg /media/famu/DISK_DATA/yongqiang/yolov3-tiny_best.weights -i 1
(If you use another GitHub repository, then use darknet.exe detector recall… instead of darknet.exe detector map…)
darknet.exe detector train data/obj.data yolo-obj.cfg darknet53.conv.74 -map
./darknet detector train ./train_cfg/yolov3-tiny.data ./train_cfg/yolov3-tiny.cfg -gpus 0,1,2,3 -map
(107条消息) Darknet - When should I stop training? - 我什么时候应该停止训练?_既然选择了远方 便只顾风雨兼程 - 永强-CSDN博客 https://blog.csdn.net/chengyq116/article/details/103971076















 920
920











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









