







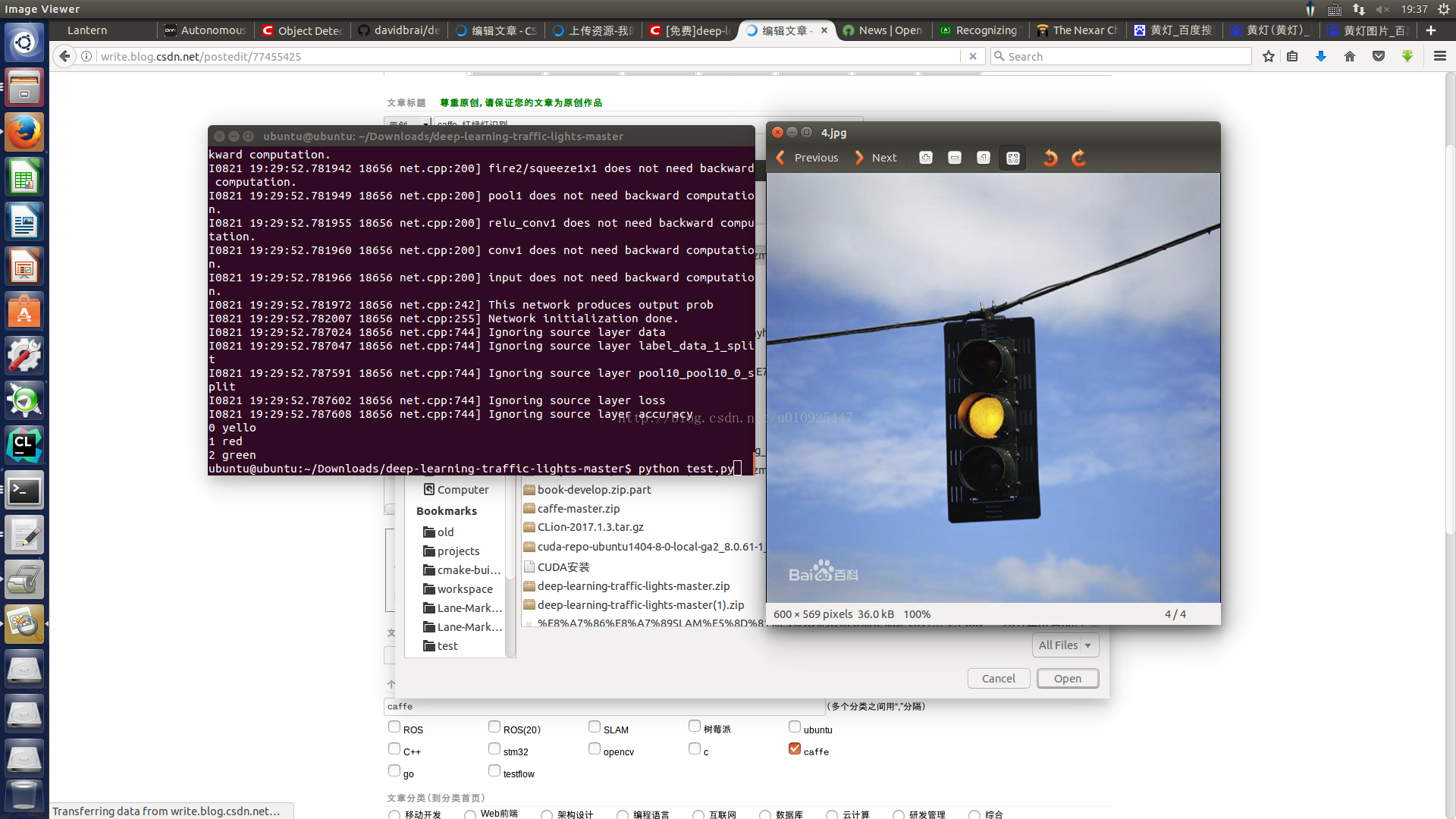
#coding=utf-8 #加载必要的库 import numpy as np import sys,os #设置当前目录 caffe_root = '/home/ubuntu/caffe/' sys.path.insert(0, caffe_root + 'python') import caffe os.chdir(caffe_root) net_file='/home/ubuntu/Downloads/deep-learning-traffic-lights-master/model/deploy.prototxt' caffe_model='/home/ubuntu/Downloads/deep-learning-traffic-lights-master/model/train_squeezenet_scratch_trainval_manual_p2__iter_8000.caffemodel' mean_file=caffe_root + 'python/caffe/imagenet/ilsvrc_2012_mean.npy' net = caffe.Net(net_file,caffe_model,caffe.TEST) transformer = caffe.io.Transformer({'data': net.blobs['data'].data.shape}) transformer.set_transpose('data', (2,0,1)) transformer.set_mean('data', np.load(mean_file).mean(1).mean(1)) transformer.set_raw_scale('data', 255) transformer.set_channel_swap('data', (2,1,0)) im=caffe.io.load_image('/home/ubuntu/Downloads/deep-learning-traffic-lights-master/4.jpg') net.blobs['data'].data[...] = transformer.preprocess('data',im) out = net.forward() imagenet_labels_filename = '/home/ubuntu/Downloads/deep-learning-traffic-lights-master/synset_words.txt' labels = np.loadtxt(imagenet_labels_filename, str, delimiter='\t') top_k = net.blobs['prob'].data[0].flatten().argsort()[-1:-6:-1] for i in np.arange(top_k.size): print top_k[i], labels[top_k[i]] // //
synset_words.txt
yello red green
ilsvrc_2012_mean.npy

















09-19
 1108
1108
1108

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









