







目录连接
(1) 数据处理
(2) 搭建和自定义网络
(3) 使用训练好的模型测试自己图片
(4) 视频数据的处理
(5) PyTorch源码修改之增加ConvLSTM层
(6) 梯度反向传递(BackPropogate)的理解
(7) 模型的训练和测试、保存和加载
(8) pyTorch-To-Caffe
(总) PyTorch遇到令人迷人的BUG
PyTorch的学习和使用(七)
模型的训练和测试
在训练模型时会在前面加上:
model.train()
在测试模型时在前面使用:
model.eval()
同时发现,如果不写这两个程序也可以运行,这是因为这两个方法是针对在网络训练和测试时采用不同方式的情况,比如Batch Normalization 和 Dropout。
Batch Normalization
BN主要时对网络中间的每层进行归一化处理,并且使用变换重构(Batch Normalizing Transform)保证每层所提取的特征分布不会被破坏,详细参加Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift。该算法主要如下:

训练时是正对每个min-batch的,但是在测试中往往是针对单张图片,即不存在min-batch的概念。由于网络训练完毕后参数都是固定的,因此每个批次的均值和方差都是不变的,因此直接结算所有batch的均值和方差。所有Batch Normalization的训练和测试时的操作不同
Dropout
Dropout能够克服Overfitting,在每个训练批次中,通过忽略一半的特征检测器,可以明显的减少过拟合现象,详细见文章:Dropout: A Simple Way to Prevent Neural Networks from Overtting具体如下所示:
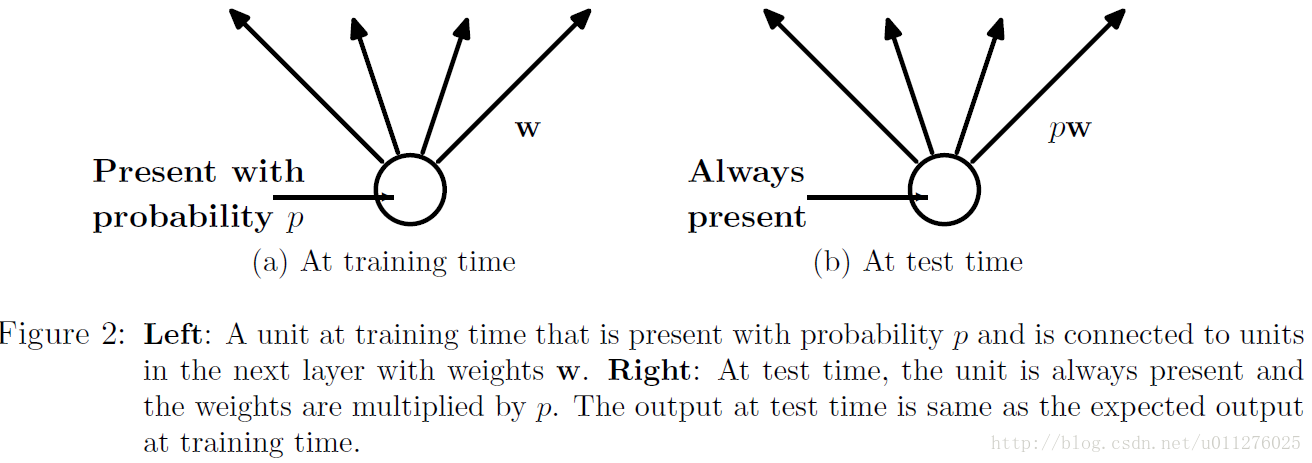
在训练中,每个隐层的神经元先乘概率P,然后在进行激活,在测试中,所有的神经元先进行激活,然后每个隐层神经元的输出乘P。
###模型的保存和加载
模型的保存和加载有两种方式:
(1) 仅仅保存和加载模型参数
torch.save(the_model.state_dict(), PATH)
the_model = TheModelClass(*args, **kwargs)
the_model.load_state_dict(torch.load(PATH))
(2) 保存和加载整个模型
torch.save(the_model, PATH)
the_model = torch.load(PATH)
第一种方式需要自己定义网络,并且其中的参数名称与结构要与保存的模型中的一致(可以是部分网络,比如只使用VGG的前几层),相对灵活,便于对网络进行修改。第二种方式则无需自定义网络,保存时已把网络结构保存,比较死板,不能调整网络结构。















 425
425











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









