










caffe中卷积层的实现
1 caffe卷积前向传播
caffe前向传播涉及到的类主要如下:

首先卷积层conv_layer.cpp中的Fprward进行前向传播,调用父类base_conv_layer.cpp中的forward进行前向传播,该函数调用conv_layer.cpp中的conv_im2col计算输入矩阵转换后的矩阵,然后通过权重矩阵与转换后的矩阵相乘得到卷积计算。其示意图如下:

卷积前向传播中最为主要的就是输入矩阵的转换,其主要代码如下(cafffe源码):
//计算输出矩阵的高 (dilation为卷积中膨胀系数)
const int output_h = (height + 2 * pad_h -
(dilation_h * (kernel_h - 1) + 1)) / stride_h + 1;
//计算输出矩阵的宽
const int output_w = (width + 2 * pad_w -
(dilation_w * (kernel_w - 1) + 1)) / stride_w + 1;
//计算每个通道的大小(N维矩阵都存储为1维数组的形式)
const int channel_size = height * width;
//处理每个通道
for (int channel = channels; channel--; data_im += channel_size) {
//处理核区域中的每个元素
for (int kernel_row = 0; kernel_row < kernel_h; kernel_row++) {
for (int kernel_col = 0; kernel_col < kernel_w; kernel_col++) {
//选取核大小区域的行的初始位置 (如果有pad,则为负,没有在原始数组中补充0)
int input_row = -pad_h + kernel_row * dilation_h;
//处理输出的每一行
for (int output_rows = output_h; output_rows; output_rows--) {
//如果选取在pad行,则都补充0
if (!is_a_ge_zero_and_a_lt_b(input_row, height)) {
for (int output_cols = output_w; output_cols; output_cols--) {
*(data_col++) = 0;
}
} else {
//选取核大小区域的列的初始位置
int input_col = -pad_w + kernel_col * dilation_w;
//处理输出的每一列
for (int output_col = output_w; output_col; output_col--) {
//如果选取的在pad列,则补充0,否则将原矩阵位置输出
if (is_a_ge_zero_and_a_lt_b(input_col, width)) {
*(data_col++) = data_im[input_row * width + input_col];
} else {
*(data_col++) = 0;
}
//由于矩阵存储以1维矩阵,则卷积窗口的滑动直接向后移动
input_col += stride_w;
}
}
input_row += stride_h;
}
}
}
}
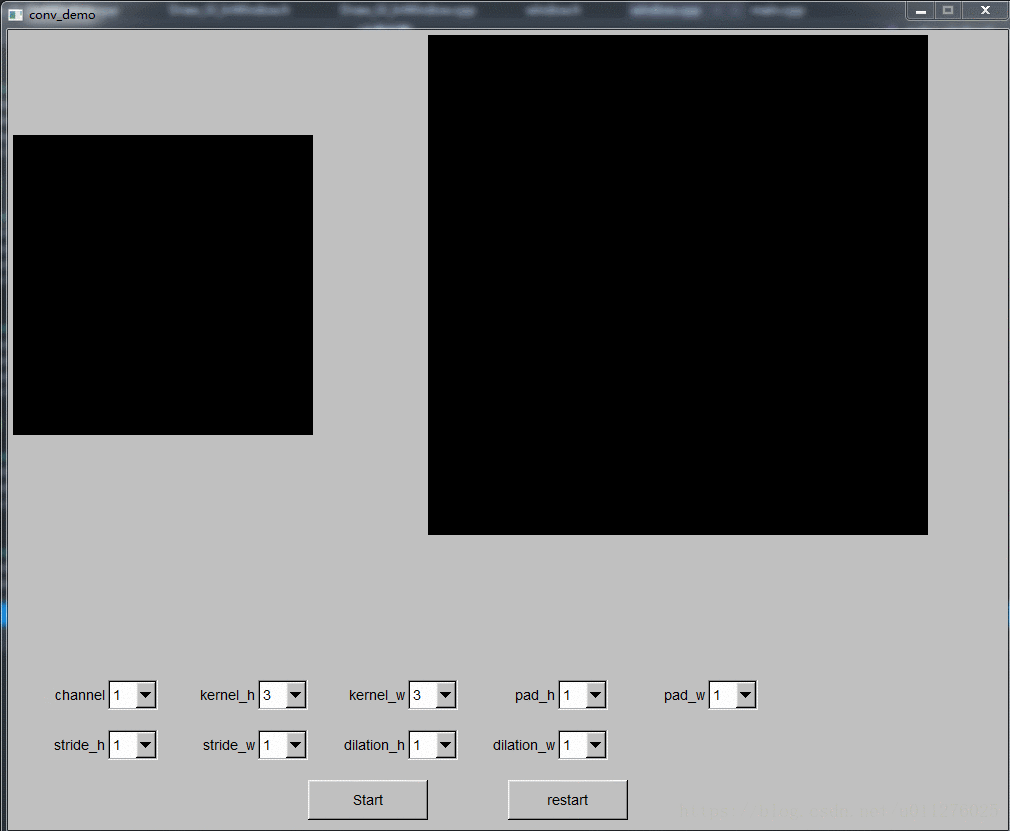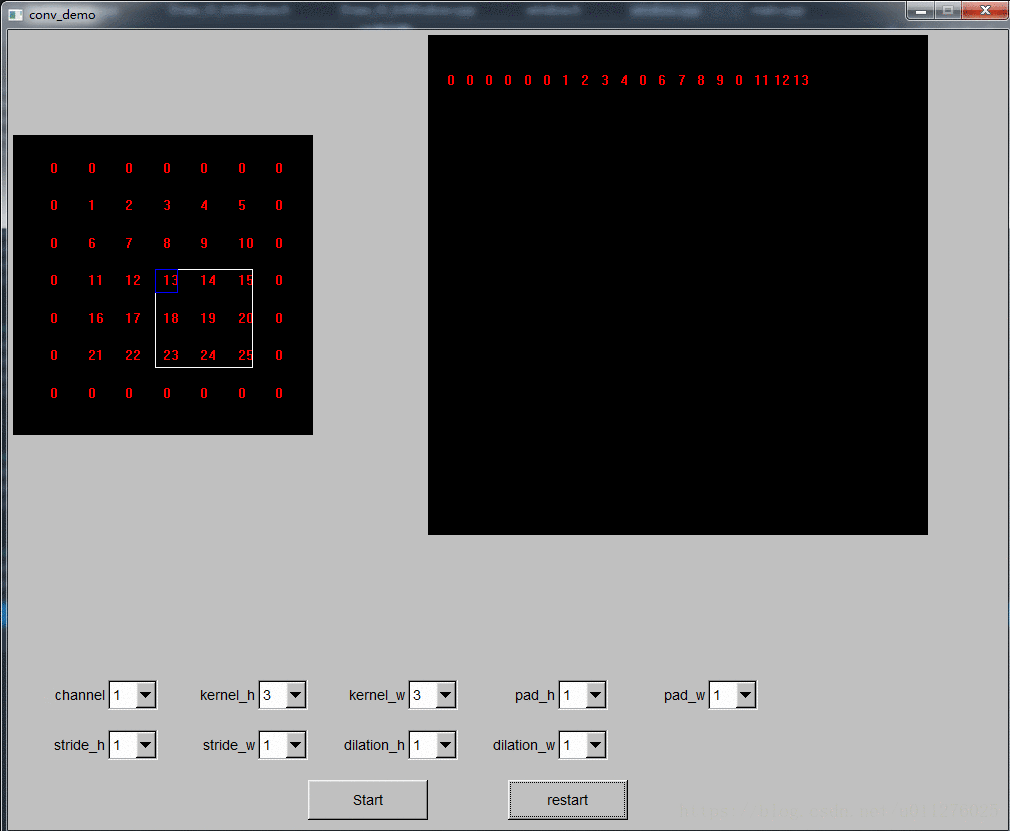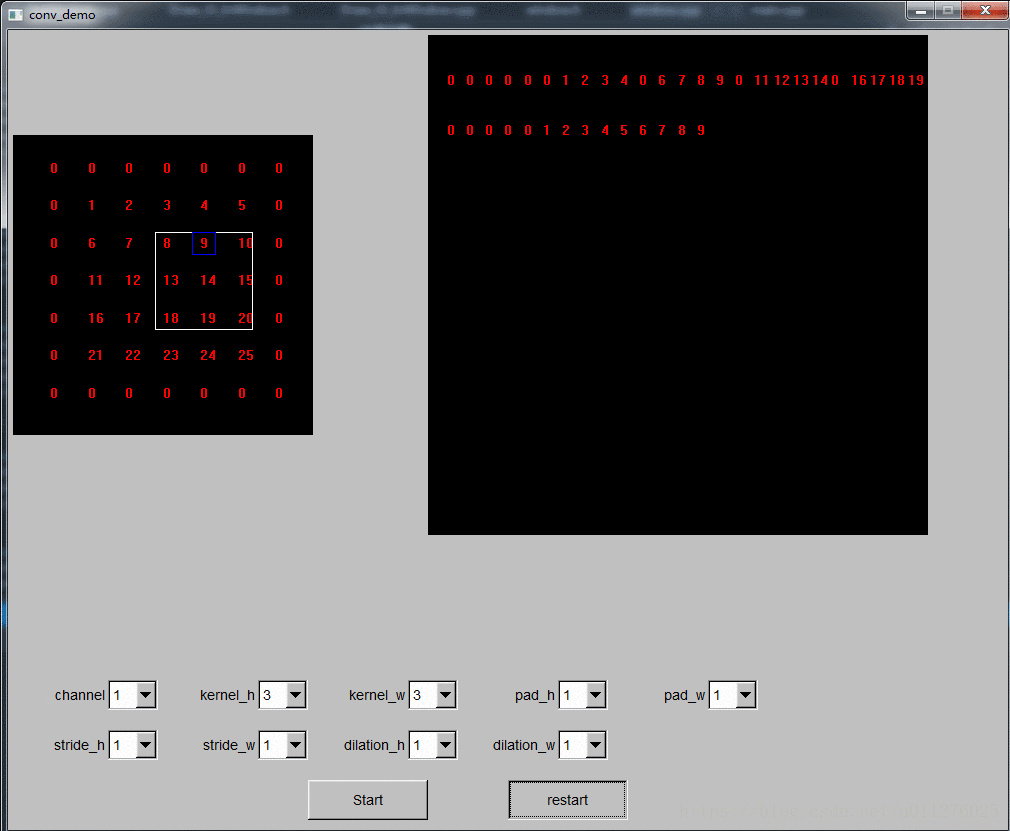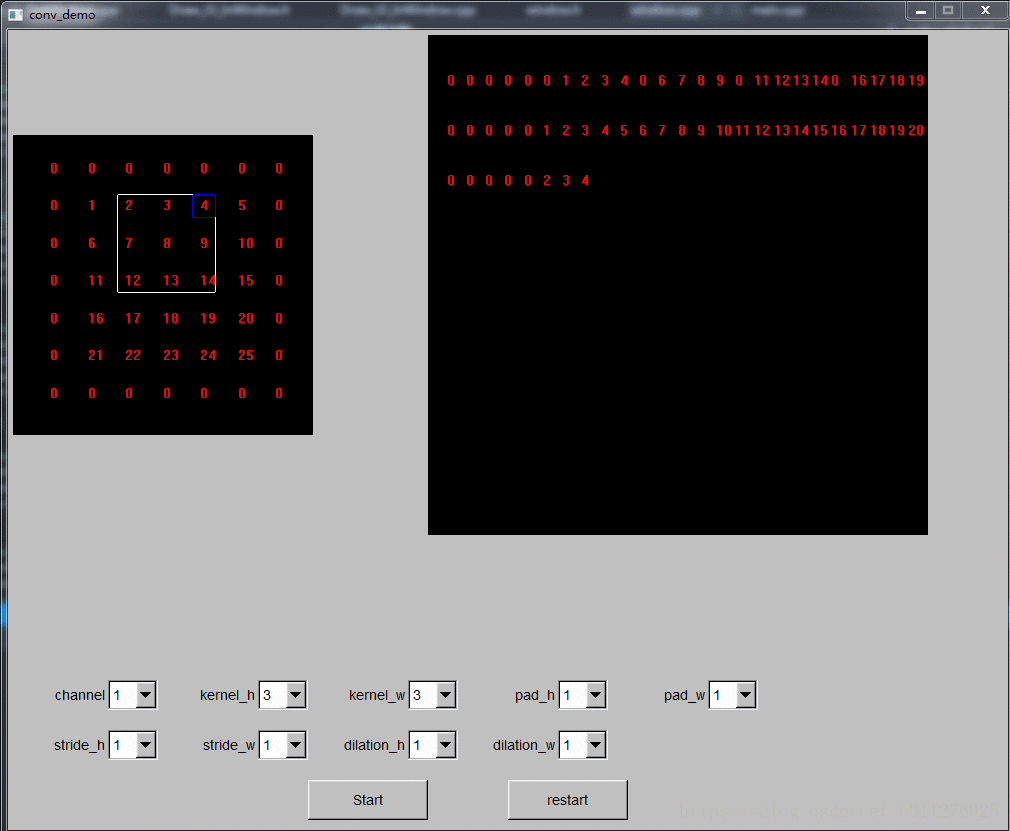
转换是把原始输入矩阵的的第一个卷积和大小的区域拉成一个列向量,然后卷积核区域向后滑动一步,再拉成一个列向量,所有列向量组成一个转换后的矩阵,如果多个通道,每个通道计算的矩阵向下拼接 (就如上面示意图所示)。由于caffe中是行优先,则每次需要先对卷积区域的第一个元素处理,滑动完所有窗口后对第二个元素处理,这样就可以一行一行的生成转换后的输出矩阵了。
其转换过程可视化如下节所示(FLTK+opengl实现,调试了蛮久的,以为是opengl宣传除了bug,最后原来是转换计算时时指针出了问题,完整的demo程序见github)。
卷积中膨胀系数,就是空洞卷积(dilated convolution)的实现,在卷积和中插入0。如在ENet网络中,定义dilated convolution操作为:

2 caffe卷积前向传播动画演示
这里偷一个网上多通道卷积示意图 (Convolutional neural networks for artistic style transfer):

通过最上面的卷积实现示意图可知,卷积的实现是权重矩阵和输入转换的矩阵做矩阵乘法。权重矩阵的大小定义为(out_channels x in_channels/groups x kH x kW),根据上图和矩阵乘法示意图可知,将卷积核与输入的所有通道做卷积计算,所有通道的和作为输出的第一个通道,然后将不同权重卷积核与输入的所有通道做卷积计算,得到第二个输出通道。
3 caffe卷积反向传播
网络反向传播需要需要跟新两项:*weights和deltas,其公式推到见之前博客Neural Network and deep learning。
网络的forward过程是使用权重更新每层的feature,而backward则是使用deltas跟新weights。因此在pyTorch框架中网络层和feature中都有grad,网络层的grad用来跟新权重,feature中的grad则用来传递deltas。
4 根据可变卷积实现caffe自定义卷积层
5 Convolution Operator and Correlation Operator
Convolution Operator是卷机操作,需要将卷机核翻转180度然后滑动窗口做卷机操作,如果进行翻转,则为Correlation Operator操作,如果卷机核是对称的,则两种操作等价。
卷机的其中一方参与这是冲击的影响,即当前时间之前造成的影响,从而卷机的输出等于以前的信号效果累加,这个累加必须从当前时间的逆时间流逝的方向进行。因此需要对卷机核翻转。
deep learning中的卷机并不是严格意义上的卷机,所以没有翻转















 1912
1912

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









