







By joey周琦 | http://blog.csdn.net/u011467621
在看英文概率书籍时候遇见上述词汇,概念有所不清,下面我总结下
- pmf:离散随机变量的概率密度函数,也有人翻译为概率质量函数。常见形式:
Cpmf:就是离散随机变量的累积分布函数,不连续。
Pdf:连续随机变量的概率密度函数,常见形式如高斯概率密度函数。
- Cdf:连续随机变量的累积分布函数(分布函数)。就是对pdf的积分,形式如:
- Corelation coefficient:相关系数。如下式:
其中,E是数学期望,cov表示协方差,和 是标准差 - iid = independent identically distributed 独立同分布。
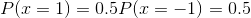
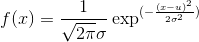
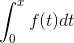
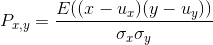
未完待续

















 7333
7333

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









