一、DNN结构实现mnist手写数字图片
import os
import struct
import numpy as np
import tensorflow as tf
def load_mnist(path, kind='train'):
"""load mnist date
Args:
path: date path
kind: train or test
Returns:
images and labels
"""
labels_path = os.path.join(path,'%s-labels.idx1-ubyte'% kind)
images_path = os.path.join(path,'%s-images.idx3-ubyte'% kind)
with open(labels_path, 'rb') as lbpath:
magic, n = struct.unpack('>II',lbpath.read(8))
labels = np.fromfile(lbpath,dtype=np.uint8)
with open(images_path, 'rb') as imgpath:
magic, num, rows, cols = struct.unpack('>IIII',imgpath.read(16))
images = np.fromfile(imgpath,dtype=np.uint8).reshape(len(labels), 784)
return images, labels
def y_onehot(y):
"""one-hot option
Args:
y: labels
Returns:
one-hot label
eg:1->[0,1,0,0,0,0,0,0,0]
"""
n_class = 10
y_labels = np.eye(n_class)[y]
return y_labels
Epoch=100
batch_size=256
learning_rate=0.05
x=tf.placeholder(tf.float32, [None, 784])
y=tf.placeholder(tf.float32, [None, 10])
is_train = tf.placeholder(tf.bool)
keep_prob = tf.placeholder(tf.float32)
W_fc1 = tf.Variable(tf.truncated_normal(shape=[784, 1024], stddev=0.1), name="W_fc1")
b_fc1 = tf.Variable(tf.constant(0.01, shape=[1024]), name="b_fc1")
W_fc2 = tf.Variable(tf.truncated_normal(shape=[1024, 512], stddev=0.1), name="W_fc2")
b_fc2 = tf.Variable(tf.constant(0.01, shape=[512]), name="b_fc2")
W_fc3 = tf.Variable(tf.truncated_normal(shape=[512, 10], stddev=0.1), name="W_fc3")
b_fc3 = tf.Variable(tf.constant(0.01, shape=[10]), name="b_fc3")
def minist_dnn(x, is_train, keep_prob, W_fc1, b_fc1, W_fc2, b_fc2):
layer1 = tf.add(tf.matmul(x, W_fc1), b_fc1)
layer1_bn = tf.layers.batch_normalization(layer1, training=is_train)
layer1_relu = tf.nn.relu(layer1_bn)
layer2 = tf.add(tf.matmul(layer1_relu, W_fc2), b_fc2)
layer2_relu = tf.nn.relu(layer2)
layer2_drop = tf.nn.dropout(layer2_relu, keep_prob)
layer3 = tf.add(tf.matmul(layer2_drop, W_fc3), b_fc3)
pred = tf.nn.softmax(layer3)
return pred
pred = minist_dnn(x, is_train, keep_prob, W_fc1, b_fc1, W_fc2, b_fc2)
loss = -tf.reduce_mean(y*tf.log(tf.clip_by_value(pred, 1e-8, 1)))
correct_prediction = tf.equal(tf.arg_max(y, 1), tf.arg_max(pred,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
optimizer = tf.train.GradientDescentOptimizer(learning_rate=learning_rate)
train_op=optimizer.minimize(loss)
init = tf.global_variables_initializer()
saver = tf.train.Saver(tf.global_variables())
path = 'D:/data/mnist/'
X_train, y_train = load_mnist(path, kind='train')
y_train_labels = y_onehot(y_train)
with tf.Session() as sess:
sess.run(init)
total_batch = int(len(X_train)/batch_size)
for step in range(Epoch):
for i in range(1,total_batch):
batch_x = X_train[(i-1)*batch_size: i*batch_size]
batch_y = y_train_labels[(i-1)*batch_size: i*batch_size]
sess.run(train_op,feed_dict={x:batch_x, y:batch_y, is_train:True, keep_prob:0.5})
entropy ,acc = sess.run([loss, accuracy], feed_dict={x:X_train[0:1000], y:y_train_labels[0:1000], is_train:False, keep_prob:1})
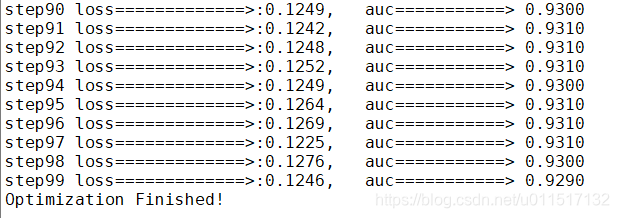
print('step{} loss=============>:{:.4f}, auc===========> {:.4f}'.format(step, entropy, acc) )
print ("Optimization Finished!")
二、CNN结构实现mnist手写数字图片
import os
import struct
import numpy as np
import tensorflow as tf
tf.reset_default_graph()
def load_mnist(path, kind='train'):
"""load mnist date
Args:
path: date path
kind: train or test
Returns:
images and labels
"""
labels_path = os.path.join(path,'%s-labels.idx1-ubyte'% kind)
images_path = os.path.join(path,'%s-images.idx3-ubyte'% kind)
with open(labels_path, 'rb') as lbpath:
magic, n = struct.unpack('>II',lbpath.read(8))
labels = np.fromfile(lbpath,dtype=np.uint8)
with open(images_path, 'rb') as imgpath:
magic, num, rows, cols = struct.unpack('>IIII',imgpath.read(16))
images = np.fromfile(imgpath,dtype=np.uint8).reshape(len(labels), 784)
return images, labels
def y_onehot(y):
"""one-hot option
Args:
y: labels
Returns:
one-hot label
eg:1->[0,1,0,0,0,0,0,0,0]
"""
n_class = 10
y_labels = np.eye(n_class)[y]
return y_labels
Epoch=100
batch_size=256
learning_rate=0.001
x= tf.placeholder(tf.float32, [None, 784])
y=tf.placeholder(tf.float32, [None, 10])
keep_prob = tf.placeholder(tf.float32)
def mnist_cnn(x, keep_prob):
x_image=tf.reshape(x, [-1,28,28,1])
with tf.variable_scope("conv_pool1"):
W_conv1 = tf.get_variable("weights",[5,5,1,32], initializer = tf.truncated_normal_initializer(stddev=0.1))
b_conv1 = tf.get_variable("bias",[32], initializer = tf.constant_initializer(0.01))
h_conv1=tf.nn.conv2d(x_image, filter= W_conv1, strides=[1,1,1,1], padding="SAME")
h_conv1_relu = tf.nn.relu(h_conv1+b_conv1)
h_pooling1 = tf.nn.max_pool(h_conv1_relu, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
with tf.variable_scope("conv_pool2"):
W_conv2 = tf.get_variable("weights",[5,5,32,64], initializer = tf.truncated_normal_initializer(stddev=0.1))
b_conv2 = tf.get_variable("bias",[64], initializer = tf.constant_initializer(0.01))
h_conv2=tf.nn.conv2d(h_pooling1, filter= W_conv2, strides=[1,1,1,1], padding="SAME")
h_conv2_relu = tf.nn.relu(h_conv2+b_conv2)
h_pooling2 = tf.nn.max_pool(h_conv2_relu, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
pool_shape = h_pooling2.get_shape().as_list()
h_pooling2_flat = tf.reshape(h_pooling2, [-1, pool_shape[1]*pool_shape[2]*pool_shape[3]])
with tf.variable_scope("fc1"):
W_fc1 = tf.get_variable("weights",[pool_shape[1]*pool_shape[2]*pool_shape[3], 1024], initializer = tf.truncated_normal_initializer(stddev=0.1))
b_fc1 = tf.get_variable("bias",[1024], initializer = tf.constant_initializer(0.01))
fc1 = tf.add(tf.matmul(h_pooling2_flat, W_fc1), b_fc1)
fc1_relu = tf.nn.relu(fc1)
fc1_drop = tf.nn.dropout(fc1_relu, keep_prob)
with tf.variable_scope("output"):
W_fc2 = tf.get_variable("weights",[1024, 10], initializer = tf.truncated_normal_initializer(stddev=0.1))
b_fc2 = tf.get_variable("bias",[10], initializer = tf.constant_initializer(0.01))
output = tf.add(tf.matmul(fc1_drop, W_fc2), b_fc2)
pred = tf.nn.softmax(output)
return pred
pred = mnist_cnn(x, keep_prob)
loss = -tf.reduce_mean(y*tf.log(tf.clip_by_value(pred,1e-11,1.0)))
correct_prediction = tf.equal(tf.argmax(pred,1), tf.argmax(y,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
optimizer = tf.train.GradientDescentOptimizer(learning_rate=learning_rate)
train_op=optimizer.minimize(loss)
init = tf.global_variables_initializer()
saver = tf.train.Saver(tf.global_variables())
path = 'D:/data/mnist/'
X_train, y_train = load_mnist(path, kind='train')
y_train_labels = y_onehot(y_train)
with tf.Session() as sess:
sess.run(init)
total_batch = int(len(X_train)/batch_size)
for step in range(Epoch):
for i in range(1,total_batch):
batch_x = X_train[(i-1)*batch_size: i*batch_size]
batch_y = y_train_labels[(i-1)*batch_size: i*batch_size]
sess.run(train_op,feed_dict={x:batch_x, y:batch_y, keep_prob:0.5})
entropy ,acc = sess.run([loss, accuracy], feed_dict={x:X_train[0:1000], y:y_train_labels[0:1000], keep_prob:1})
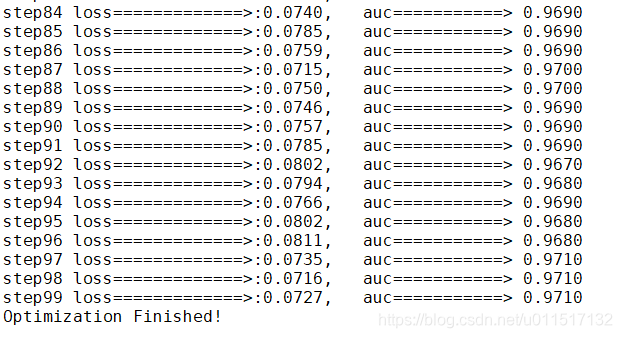
print('step{} loss=============>:{:.4f}, auc===========> {:.4f}'.format(step, entropy, acc) )
print ("Optimization Finished!")
三、LSTM结构实现mnist手写数字图片
import os
import struct
import numpy as np
import tensorflow as tf
tf.reset_default_graph()
def load_mnist(path, kind='train'):
"""load mnist date
Args:
path: date path
kind: train or test
Returns:
images and labels
"""
labels_path = os.path.join(path,'%s-labels.idx1-ubyte'% kind)
images_path = os.path.join(path,'%s-images.idx3-ubyte'% kind)
with open(labels_path, 'rb') as lbpath:
magic, n = struct.unpack('>II',lbpath.read(8))
labels = np.fromfile(lbpath,dtype=np.uint8)
with open(images_path, 'rb') as imgpath:
magic, num, rows, cols = struct.unpack('>IIII',imgpath.read(16))
images = np.fromfile(imgpath,dtype=np.uint8).reshape(len(labels), 784)
return images, labels
def y_onehot(y):
"""one-hot option
Args:
y: labels
Returns:
one-hot label
eg:1->[0,1,0,0,0,0,0,0,0]
"""
n_class = 10
y_labels = np.eye(n_class)[y]
return y_labels
Epoch=100
learning_rate=0.05
timestep=28
num_input=28
lstm_hidden_size=64
num_of_layers = 2
x= tf.placeholder(tf.float32, [None, 784])
y=tf.placeholder(tf.float32, [None, 10])
lstm_keep_prob = tf.placeholder(tf.float32)
keep_prob = tf.placeholder(tf.float32)
batch_size = tf.placeholder(tf.int32, [])
def mnist_lstm(x, lstm_keep_prob, keep_prob, batch_size):
x_image = tf.reshape(x, [-1,timestep, num_input])
with tf.variable_scope("lstmlayer"):
stacked_lstm = tf.nn.rnn_cell.MultiRNNCell([tf.nn.rnn_cell.DropoutWrapper(tf.nn.rnn_cell.BasicLSTMCell(lstm_hidden_size), input_keep_prob=1, output_keep_prob =lstm_keep_prob ) for _ in range(num_of_layers)])
init_state = stacked_lstm.zero_state(batch_size, dtype=tf.float32)
lstm_outputs, _ = tf.nn.dynamic_rnn(stacked_lstm, x_image, initial_state=init_state, dtype=tf.float32)
lstm_output = lstm_outputs[:,-1,:]
with tf.variable_scope("fc1"):
W_fc1 = tf.get_variable('weight', shape=[lstm_hidden_size, 10], initializer = tf.truncated_normal_initializer(stddev=0.1), dtype=tf.float32)
b_fc1 = tf.get_variable('bias', shape=[10], initializer = tf.constant_initializer(0.1), dtype=tf.float32)
output = tf.add(tf.matmul(lstm_output, W_fc1), b_fc1)
pred = tf.nn.softmax(output)
return pred
pred = mnist_lstm(x, lstm_keep_prob, keep_prob, batch_size)
loss = -tf.reduce_mean(y*tf.log(tf.clip_by_value(pred,1e-11,1.0)))
correct_prediction = tf.equal(tf.argmax(pred,1), tf.argmax(y,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
optimizer = tf.train.GradientDescentOptimizer(learning_rate=learning_rate)
train_op=optimizer.minimize(loss)
init = tf.global_variables_initializer()
path = 'D:/data/mnist/'
X_train, y_train = load_mnist(path, kind='train')
y_train_labels = y_onehot(y_train)
with tf.Session() as sess:
sess.run(init)
total_batch = int(len(X_train)/256)
for step in range(Epoch):
for i in range(1,total_batch):
batch_x = X_train[(i-1)*256: i*256]
batch_y = y_train_labels[(i-1)*256: i*256]
sess.run(train_op,feed_dict={x:batch_x, y:batch_y, lstm_keep_prob:0.5, keep_prob:0.5, batch_size:256})
entropy ,acc = sess.run([loss, accuracy], feed_dict={x:X_train[0:1000], y:y_train_labels[0:1000], lstm_keep_prob:1, keep_prob:1, batch_size:1000})
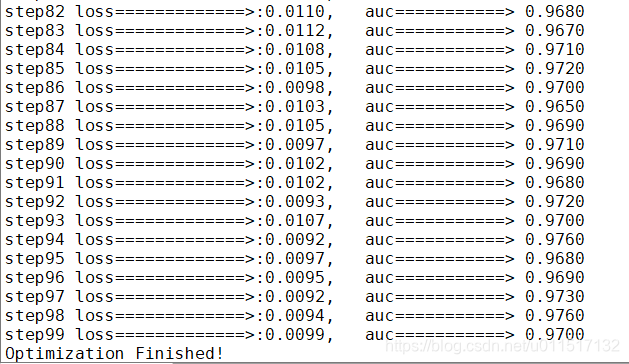
print('step{} loss=============>:{:.4f}, auc===========> {:.4f}'.format(step, entropy, acc) )
print ("Optimization Finished!")


























 2560
2560

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









