










在这里解答一下:
int arr[4];
&arr[1] = arr[0] + sizeof(int) ;
静态分配, 即普通数组, 由于在栈中分配, 而栈的生成方向是自高地址向低地址生成。 所以有:
&arr[0] > &arr[1] ....
动态分配的数组。针对动态数组。 动态数组的内存分配在heap中。 而heap 的生成是由低地址向高地址生成。 所以有:
&arr[0] < &arr[1] <...
这是我以为的。 答案是我我错了。
测试一下:
- #include <iostream>
- using namespace std;
- int main() {
- int n = 4;
- int *ptr = new int[n];
- // dynamic array: on heap
- cout << "dynamic array: " << endl;
- for(int i = 0; i < 4; ++i) {
- cout << &ptr[i] << endl;
- }
- // ordinary array: on stack
- int arr[4];
- cout << "ordinary array: " << endl;
- for(int i = 0; i < 4; ++i) {
- cout << &arr[i] << endl;
- }
- return 0;
- }
#include <iostream>
using namespace std;
int main() {
int n = 4;
int *ptr = new int[n];
// dynamic array: on heap
cout << "dynamic array: " << endl;
for(int i = 0; i < 4; ++i) {
cout << &ptr[i] << endl;
}
// ordinary array: on stack
int arr[4];
cout << "ordinary array: " << endl;
for(int i = 0; i < 4; ++i) {
cout << &arr[i] << endl;
}
return 0;
}
结果如下:
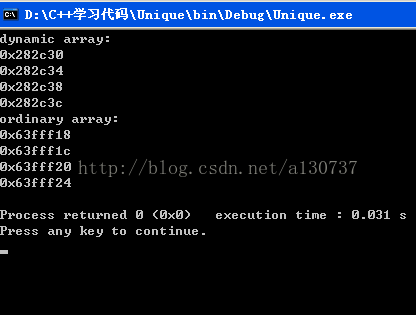
为什么无论是静态数组还是动态数组, 数组元素的分配都是对元素从低地址到高地址。
内部元素都是从低地址到高地址 。
1、内存分配的三种方式:
1)、从静态存储区分配。数据的内存在程序编译时已经被分配,该内存在整个运行期间长期驻留,不会被释放;程序结束时,由操作系统自动释放。这类数据包括静态数据和全局数据。
2)、从栈空间分配。函数执行过程中,函数中的局部变量的内存,在栈上被分配;当函数调用完成后,随函数的返回空间也被释放。
3)、从堆空间分配。由开发者动态的申请内存,并手动的释放内存。
本文具体介绍动态内存分配,C语言中采用malloc、recalloc等函数分配内存;c++中使用new操作符申请内存。
malloc函数的返回值为void*,调用该函数时,需要显式的类型转化。返回值表示内存空间的首地址。如果该地址为NULL,表示系统没有满足的内存可供分配。因此在使用该地址之前,必须判断是否分配成功。例如:
int*p=(int*)malloc(sizeof(int)*10);
if(p != NULL)
{
......//使用该内存空间
}
在该内存使用完成后,需要开发者手动释放该内存:free(p):
这里需要注意:1)、调用free后,p和所指向的内存地址被断开,但是p的值仍然没有变化,此时如果调用p,将会出现错误,这时p就是一个野指针;因此当free(p);之后,应该将p的值赋为NULL,以免p再次调用出现错误。2)、虽然内存已经分配完成,但是并没有初始化,直接使用,取到的结果不正确。
4)、当malloc申请的内存不满足用户使用要求时,就需要重新分配内存,这时可以使用realloc函数。
void *realloc( void *memblock, size_t size );memblock参数表示已经分配的内存地址的指针,即就是p;
size参数表示需要分配的字节数
该函数的返回值为,重新分配的内存空间的首地址。
realloc函数,在malloc函数已经分配的内存基础上再次扩充内存。realloc函数的返回值类型仍为void*。可以分三种情况来解释realloc。
情况一:需要分配的内存空间小于已经分配的空间。
那么这时只是从原来已经分配的内存空间中,将多余的空间释放,保留realloc函数需要的空间大小,将原来空间的的首地址赋值给realloc函数返回(这个地址和p的值是相同的);如果这样做的,可能会导致数据出错,因此一般不要缩小原内存空间;
情况二:需要分配的内存空间等于已经分配的空间。
将原来内存空间的首地址赋值给realloc函数返回;
情况三:需要分配的内存空间大于已经分配的空间。
1)如果原来的内存后,还有足够的空间,满足分配要求,那么直接在原来的内存的后面,分配适量的空间,并将原来空间的首地址赋值给realloc函数,返回;
2)如果原来内存后,没有足量的内存空间,满足分配要求,那么重新选择一块足量的空间分配,并将原来已经分配的空间的数据拷贝到新分配的内存中,将原指针p指向的空间释放。将新分配的空间首地址赋值给realloc函数返回,因此对于原来的空间,realloc函数在分配内存时,已经释放了原来的内存,不需要再次释放,否则会出错。
情况四:当分配的内存大小为0
系统是可以返回一个非NULL值,但是这个空间不能被使用。使用将会出错,效果等同于free(p);
情况五:当原来的指针为NULL
这种情况,的作用就相当于直接调用malloc函数一样;可以这样理解,NULL说明原空间没有分配成功,那么调用realloc函数,肯定需要分配一块新的内存空间,这不就相当于直接调用了malloc函数。
情况六:如果realloc函数调用失败
那么原来的空间地址不会被释放,保留原来的内存,该内存空间可以正常使用。
综上,在使用malloc函数时,需要注意几点:1)调用malloc函数后,需要判断内存是否分配成功;2)使用空间之前,需要给空间赋初始值;3)防止内存越界访问;4)释放内存空间之后free(p);,需要将原指针的值赋空(p=null;),以防再次使用产生错误,出现野指针;5)realloc函数对于原始的内存空间,在分配内存时已经做过处理,因此除realloc函数调用失败外,其余情况不能再次释放原空间内存,否则会出错。
2、既然malloc和free已经可以分配内存了,为什么还要引入new和delete?
首先需要明白,malloc和free是c语言中的c库函数,而new和delete是c++中的标识符;因此这两组拥有不同的性质;
接着,malloc和free不仅可以使用在C语言中,也可以使用在c++语言中,但是new和delete只是c++中特有的属性,在C语言中无法使用,因此new和delete有他的局限性;
再次,new和delete不仅需要分配内存空间,而且在面向对象的语言中,对于对象,还需要完成初始化,触发对象的构造和析构,这些操作是malloc和free无法完成的(笔者就在曾经实现链表的过程中,在结构体定义时,将一个数组元素定义为string类型的,在使用malloc申请内存后,调用过程中无法给该元素赋值。从这个例子中可以看出虽然malloc和new分配的内存大小相等,但是具体的内存内部工作还是有区别的)。
最后,malloc在分配内存时,需要开发者手动的指定元素的大小,并且返回值需要显式的类型转化;但是new就不需要指定和转化。
3、在c++中,既然new和delete可以完成所有分配的工作,为什么还要保留malloc和free?
这是因为c++编译器为了兼容c编译,是c中的所有函数可以在c++编译器上正常使用,因此保留了malloc和free















 1661
1661

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









