







2022-CORL-Planning with Spatial-Temporal Abstraction from Point Clouds for Deformable ObjectManipulation
#开源 #Deformable Object Manipulation #Long-horizon Planning
首发于知乎:https://zhuanlan.zhihu.com/p/641513127?
主页:
https://sites.google.com/view/pasta-plansites.google.com/view/pasta-plan
PPT:
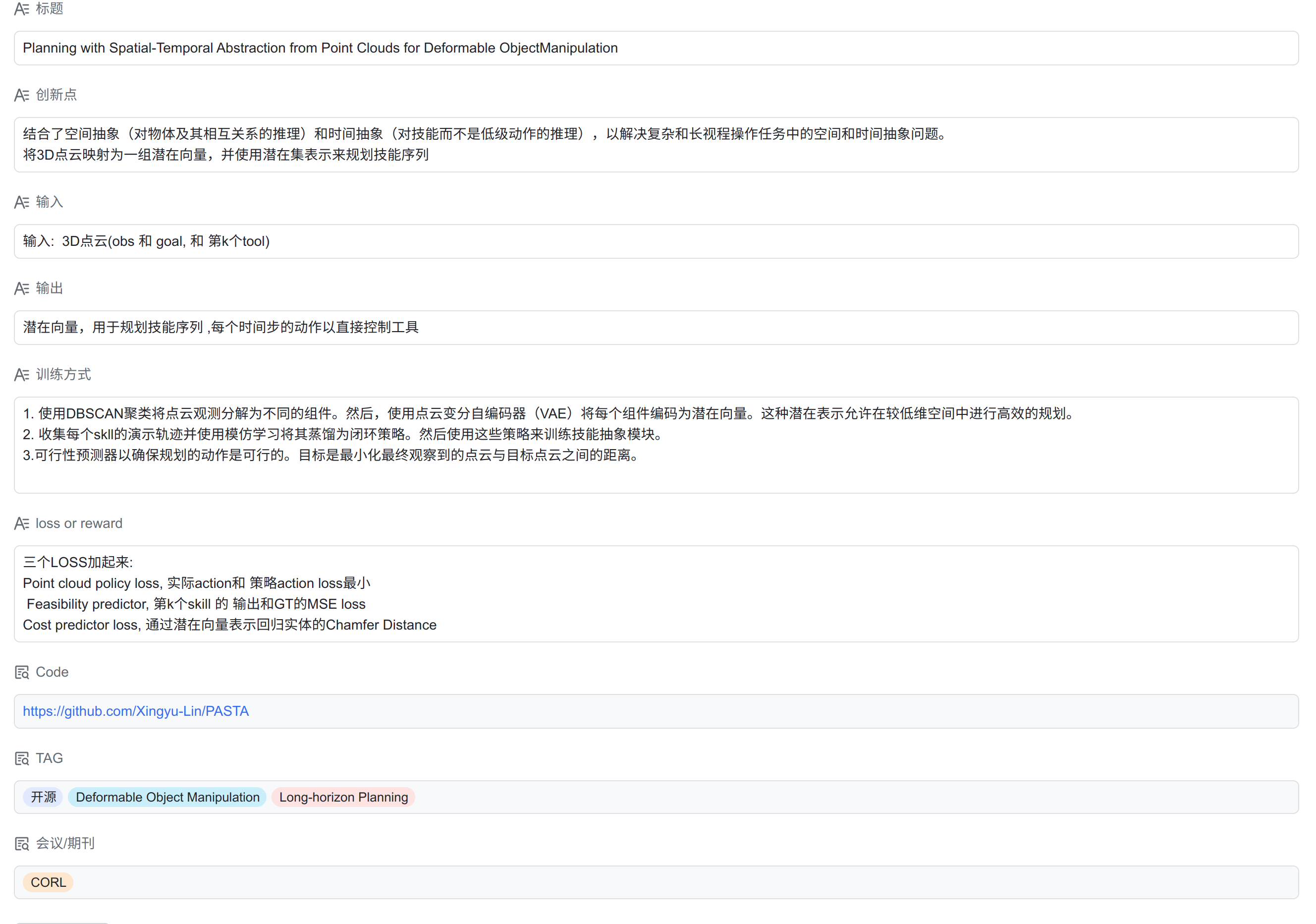
这篇论文提出了一个名为PASTA的框架,用于有效规划长期变形物体的操作,需要在空间和时间层面上具有合适的抽象。与以往方法只侧重于短期任务或假设完全状态信息可用不同,PASTA结合了空间抽象和时间抽象,能够对高维度的三维观测进行映射,并在潜在向量集表示之上进行技能序列规划。
Motivation
大多数developing state abstractions for manipulating deformable objects的方法并没有在时间层面上进行抽象,限制了它们在短期任务中的使用。
使用时间抽象的方法,规划一组解决长期任务的技能, 然而缺乏空间抽象严重限制了它们的泛化能力.
因此,如何在统一的框架内学习空间和时间抽象来完成复杂和长范围的操作任务,仍然是机器人学习中的一个关键问题
Related Work
Model-based Planning for Sequential Manipulation
Task and Motion Planning (TAMP)
- TAMP systems typically assume known object states and known effects for the action operators
- it is difficult to estimate states and dynamics for unknown objects or from partial observations.
- 本工作不假设已知的状态或动作运算符,而是学习 3D 集合表示(3D set representation)以及具有表示的动作模型(action model with the representation.)。
Another approach learns dynamics directly from visual observations
- 一些工作通过一系列技能学习动力学模型,并将其用于刚性物体 [22, 23] 或可变形物体的顺序操作.
- 但是,这些工作不使用以对象为中心的表示,因此不能轻易推广到更复杂的场景
- 本工作的框架统一了时间和空间抽象,并且可以对比以前的工作更多对象的复杂任务执行长范围操作.
Planning with Spatial Abstraction
- 先前的工作利用空间抽象来促进解决涉及复杂动态和高维观察的任务。
- These works either model a compositional system with Graph Neural Networks (GNN) [3, 4, 7, 24, 25] or learn policies directly from object-centric representations [26, 27].
- 但是这些规划任务的学习策略或是one-step动态模型,对于解决长期任务可能很困难
- 本工作的框架将时间扩展的空间抽象与可行性预测器连接起来( connects temporally extended spatial abstractions with a feasibility predictor),以在更长的时间范围内进行规划
Deformable Object Manipulation
- 先前的工作大多只考虑一次使用一种技能的操作。
- In contrast, we consider the task of sequential manipulation using multiple tools
- 使用 3D 集合表示来单独编码场景中的每个实体,从而能够对具有更多对象和更长视野的任务进行组合泛化。
Method
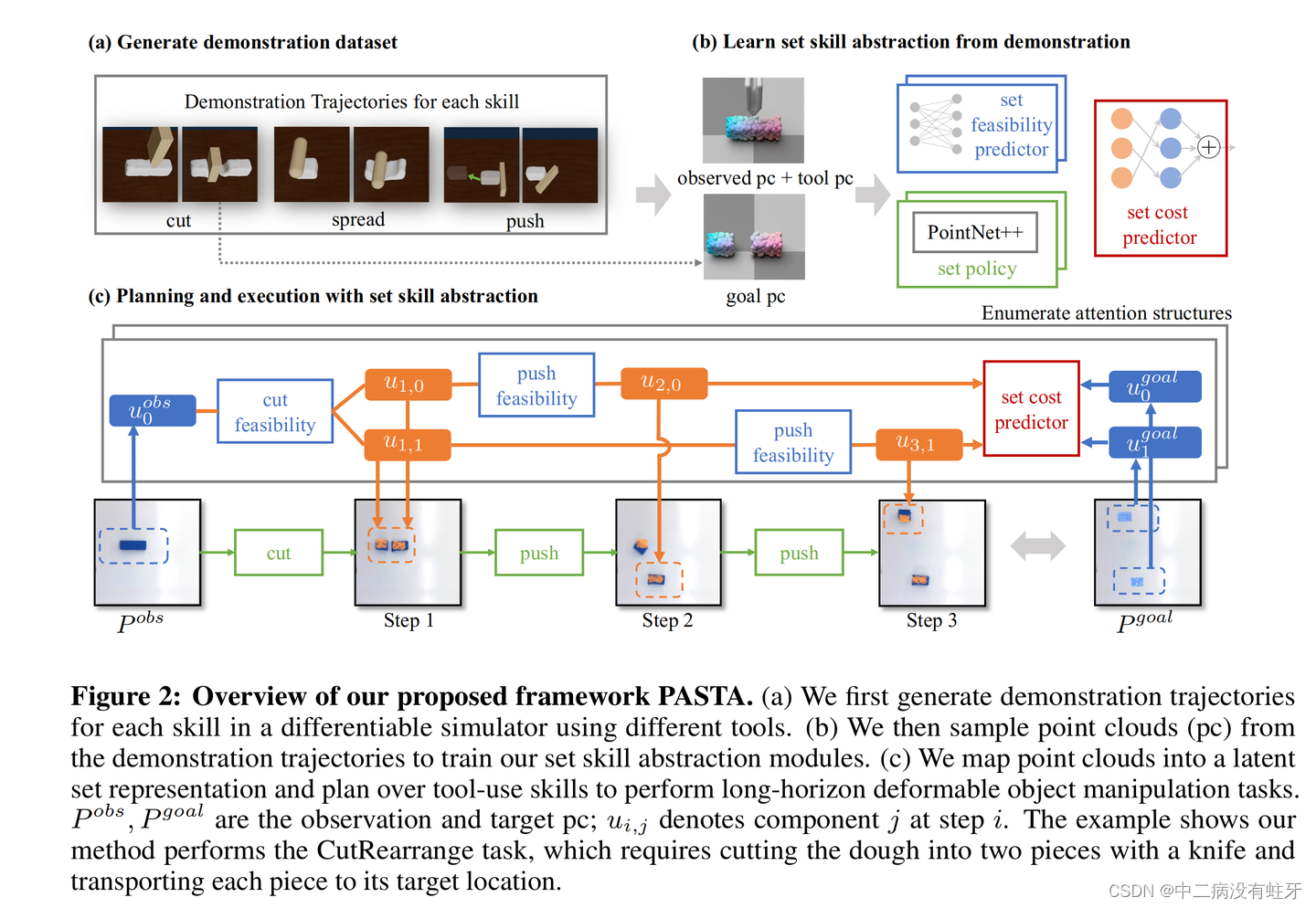
输入: 点云(obs 和 goal) , 轻松地从模拟转移到现实世界,并实现对视角变化的鲁棒性。

Spatial Abstraction from Point Clouds
Scene Decomposition
首先使用DBSCAN根据点云在空间中的接近程度将点聚类到不同的组件中.
密度聚类算法(Density-Based Spatial Clustering of Applications with Noise,简称DBSCAN)是一种聚类算法,用于机器学习和数据挖掘中将在高维空间中紧密聚集在一起的数据点分组。
Entity Encoding
为了在潜在空间中实现有效规划,训练了点云变分自动编码器(VAE)
三部分:
- 点云编码器 , 将每个实体点云映射到潜在向量
- 解码器 , 从潜在空间映射回点云
- 潜在空间上的先验分布space
p
u
p_u
pu可用于在规划过程中从潜在空间生成样本。

Learning Skills by Imitation
将K个技能的演示轨迹转化成K个闭环策略。闭环策略是一组规则,规定了在不同情况下应该采取什么行动。在这种情况下,策略旨在使用观察到的点云和目标点云的子集来控制场景中的工具
这些策略使用**行为克隆和回顾重标记(behavior cloning and hindsight relabeling)**在演示数据集上进行训练,其中涉及模仿专家操作者的行动。在训练和规划过程中,使用注意力掩码来过滤非相关的实体点云。
Hindsight relabeling是一种用于增强强化学习的技术,它通过将当前的失败经验重标记为成功经验来提高智能体的学习效率。 具体来说,在强化学习中,智能体需要在某个状态下做出决策,并根据其做出的决策获得奖励。在一些任务中,如果智能体没有获得预期的奖励,就可能会认为这次决策是失败的。但是,hindsight relabeling技术可以将当前的失败经验重标记为成功经验,以便智能体可以从这个失败的经验中学习到如何更好地处理类似的状态。 例如,在一个机器人抓取物品的任务中,如果机器人没有成功抓取一个物品,那么hindsight relabeling技术可以将该状态重新标记为成功状态,并赋予智能体一个适当的奖励。这个技术可以提高智能体的学习效率,使其在类似的任务中更快地学习到如何获得更好的结果。
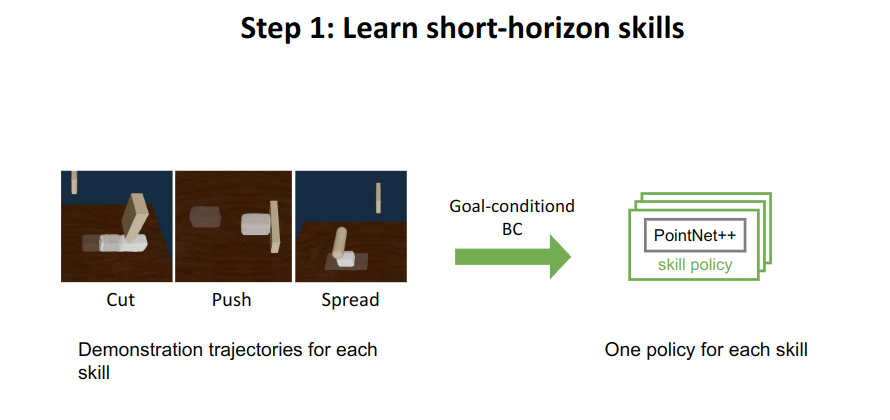
在规划过程中,策略输出每个时间步的操作,直接控制工具。这个过程的目标是实现对具有更多物体的场景进行组合泛化,使得策略可以应用于远远超出演示数据集的新情况。
Training Details
-
We train our point cloud policy with standard behavioral cloning (BC) loss
-
Then, we match point clouds in the observation set to those in the goal set by finding the pairs of point clouds that are within a Chamfer Distance of ε and filter out the non-relevant point clouds.
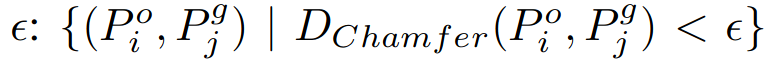
-
Last, we pass the filtered point clouds into the policy and minimize the following loss:
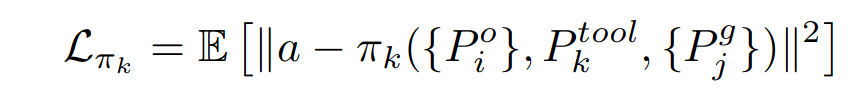
Neural Spatial and Temporal Abstraction
进一步学习可行性预测器和成本预测器
Set Feasibility Predictor
参考DiffSkill, 对于每个技能,训练一个可行性预测器 f k ( U o , U g ) f_k(U^o,U^g) fk(Uo,Ug), 其中,U是观察和目标点云的latent set representations.
类似于DiffSkill,可行性预测器使用一个平坦表示形式(flat representation),将场景中所有物体的潜在向量作为输入。
但是,由于我们的技能(如切割或涂抹)只需要输入一部分物体,因此我们使用相同的注意力机制,并假设可行性预测器仅使用子集作为输入。

观察和目标中的组件数量可以不同,因为组件数量在执行技能之前和之后可能会发生变化
Network Architectures

训练过程:
- 从演示数据集中的同一轨迹中随机抽取两个点云 ( P o b s , P g o a l ) (P^{obs},P^{goal}) (Pobs,Pgoal)来获取可行性预测器的正样本。
- 通过将正样本中的一个实体替换为随机潜在向量来生成负样本。

- train the feasibility predictor for the k-th skill by regressing to the ground-truth feasibility label using mean squared error (MSE)

Set Cost Predictor
作用: 在潜在空间中进行规划,并且训练一个成本预测器作为我们规划的目标,以确定计划与给定目标的接近程度。
成本预测器C采用两个潜在集合表示形式 ( U o , U g ) (U^o,U^g) (Uo,Ug) 作为输入
由于我们的任务重点在于将观察中的每个实体与目标中的实体匹配,因此我们假设它们具有相同数量的组件
计算cost:

其中σ是一个permutation, c θ c_θ cθ是一个成本预测网络,由MLP参数化,用于预测对应于两个潜在向量的点云之间的Chamfer距离。
最后,通过在包含潜在向量的两个集合之间执行匈牙利匹配来优化cost。
Network Architectures: a 3-layer MLP with a hidden dimension of 1024 and ReLU activations.
LOSS:

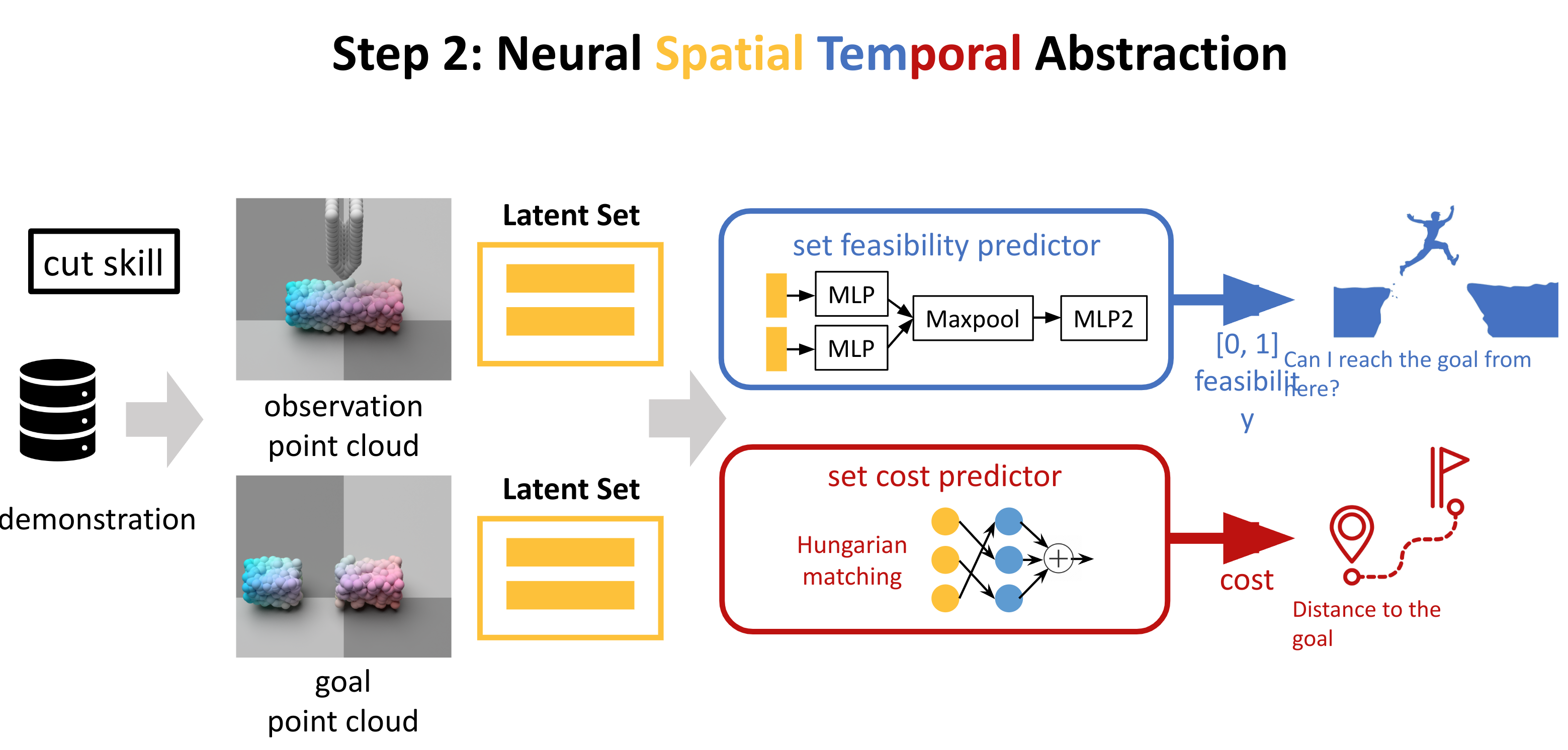
最终三个LOSS加起来:
- Point cloud policy loss, 实际action和 策略action loss最小
- Feasibility predictor, 第k个skill 的 输出和GT的MSE loss
- Cost predictor loss, 通过潜在向量表示回归实体的Chamfer Distance
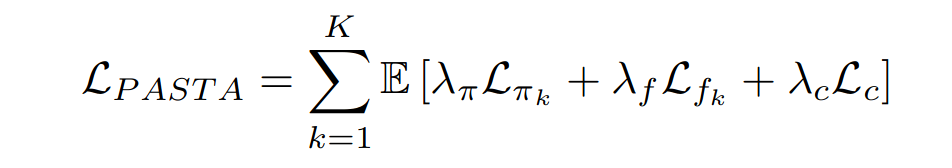
Planning with Set Representation
三级嵌套优化,
- 在顶层,穷举搜索每个步骤应用的技能组合 k
- 在第二级优化中,搜索不同的注意力结构 I。
- 在低级优化中,对于每个注意力结构I,遵循DiffSkill 中的优化方法。首先对潜在子目标集合U进行多次初始化采样,其中集合中的每个潜在向量都从我们的生成模型中初始化。
梯度下降进一步优化以下目标的 latent subgoals:
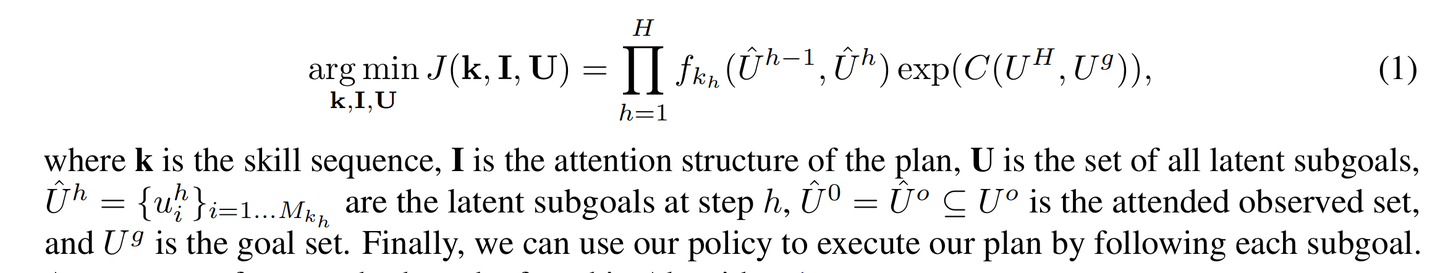
在这里插入图片描述















 948
948











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









