







在强化学习所有的思想中,时序差分(TD)学习是最核心,最新颖的思想。蒙特卡洛(MC)往往需要等到完整的一轮结束了之后才能确定真实回报G(t),但实际中很多场景完整一轮的时间非常长,或者根本没有结束状态,这时候用蒙特卡洛的方法就不适合了。
时序差分学习(TD)
时序差分学习是一种从经验片段中进行学习的一种方法,与MC最大的差距就是,TD方法不需要等到一轮结束(即等到终止状态),只需要等到下一个时刻即可。在t+1时刻,根据得到的奖励
R
t
+
1
R_{t+1}
Rt+1和估计值
V
(
S
t
+
1
)
V(S_{t+1})
V(St+1)对当前的估计值
V
(
S
t
)
V(S_t)
V(St)进行跟新,定义为:
V
(
S
t
)
←
V
(
S
t
)
+
α
[
R
t
+
1
+
γ
V
(
S
t
+
1
)
−
V
(
S
t
)
]
V(S_t)\leftarrow V(S_t)+\alpha[R_{t+1}+\gamma V(S_{t+1})-V(S_t)]
V(St)←V(St)+α[Rt+1+γV(St+1)−V(St)]
括号里面的是误差,它是衡量
S
t
S_{t}
St的估计值和更好的估计值
R
t
+
1
+
γ
V
(
S
t
+
1
)
R_{t+1}+\gamma V(S_{t+1})
Rt+1+γV(St+1)之间的差异,定义为:
δ
t
=
R
t
+
1
+
γ
V
(
S
t
+
1
)
−
V
(
S
t
)
\delta_t=R_{t+1}+\gamma V(S_{t+1})-V(S_t)
δt=Rt+1+γV(St+1)−V(St)
注意,每个时刻的误差是当前时刻的误差,取决于下一个时刻的状态和奖励。也就是说,t时刻的误差需要到t+1时刻才能得到。
MC方法更新的目标为 G ( t ) G(t) G(t),TD方法更新的目标为 R t + 1 + γ V ( S t + 1 ) R_{t+1}+\gamma V(S_{t+1}) Rt+1+γV(St+1),乍一看好像说不通,可以结合一个例子看看
例子
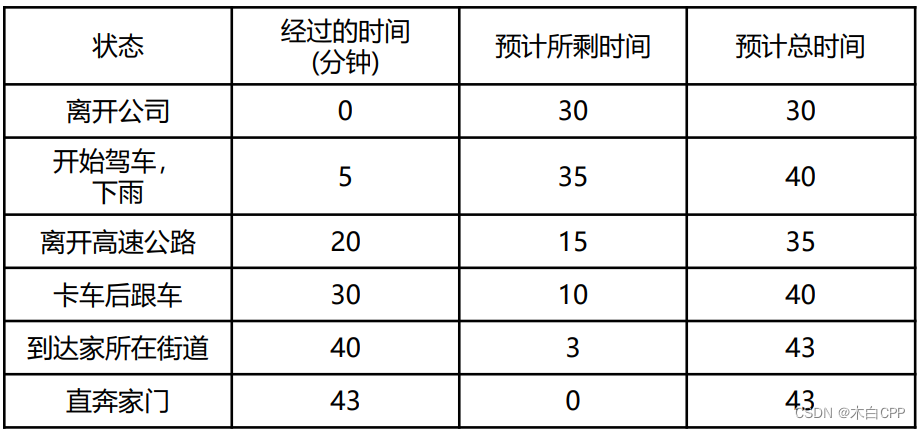
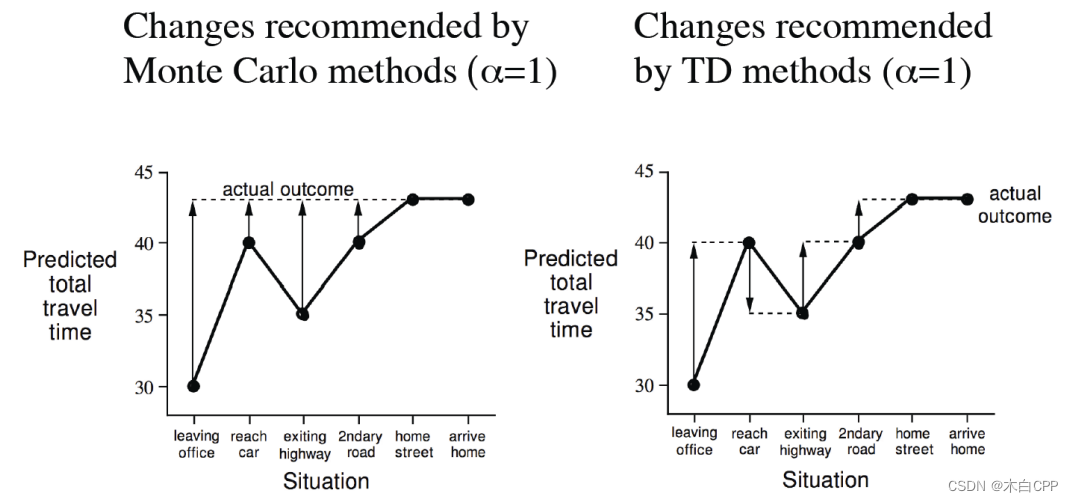
MC方法很好理解,我们已经经过了完整的一轮,G(t)已知,以G(t)为目标,过程会发生一些意外情况,但最后是不断逼近目标值。
TD方法属于一边经历一遍估计的学习方式,不需要经过完整一轮,不知道G(t)的值,每走一步之后,都需要根据经验对未来进行估计,最后一样可以收敛到最终值。
















 518
518











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











