










24年6月来自北大、阶跃星辰(stepfun)AI创业公司和UCSD等研究机构的论文“DistServe: Disaggregating Prefill and Decoding for Goodput-optimized Large Language Model Serving”。
DistServe 通过分解预填充和解码计算来提高大语言模型 (LLM) 服务的性能。现有的 LLM 服务系统将两个阶段共置,并在所有用户和请求中批量处理预填充和解码的计算。这种策略不仅会导致强烈的预填充解码干扰,而且还会将两个阶段的资源分配和并行规划结合在一起。LLM 应用程序通常强调每个阶段的单独延迟:预填充阶段的第一个token时间 (TTFT) 和解码阶段每个请求的每个输出token时间 (TPOT)。在存在严格的延迟要求情况下,现有系统必须优先考虑一个延迟,或者过度配置计算资源,以满足两个要求。
DistServe 将预填充和解码计算分配给不同的 GPU,从而消除预填充解码干扰。考虑到应用程序的 TTFT 和 TPOT 要求,DistServe 共同优化了为每个阶段量身定制的资源分配和并行策略。 DistServe 还根据服务集群的带宽安排两个阶段,以最大限度地减少因分解而导致的通信。因此,DistServe 显著提高了 LLM 服务性能,即在每个 GPU 上 TTFT 和 TPOT 约束内可以提供的最大速率。
大语言模型 (LLM) 带来了一个重大挑战:处理端到端 LLM 查询的速度可能比标准搜索查询 [41] 慢得多。为了满足各种应用程序严格的延迟要求,服务提供商需要过度配置计算资源,尤其是许多 GPU,从而导致成本效率不足。因此,在坚持高服务级目标(SLO) 实现度(满足 SLO 的请求比例)的同时,优化每个 LLM 查询的成本对于所有 LLM 服务来说变得越来越重要。
LLM 服务分两个阶段响应用户查询。预填充阶段处理由一系列tokens组成的用户提示,一步生成响应的第一个token。 随后,解码阶段按顺序在多个步骤中生成后续tokens; 每个解码步骤根据前面步骤生成的tokens生成一个新token,直到到达一个终止token。 这种双阶段过程将 LLM 服务与传统服务区分开来 - LLM 服务的延迟通过两个关键指标唯一衡量:TTFT,即预填充阶段的持续时间,以及TPOT,表示为每个请求生成token所需的平均时间(第一个token除外)。 不同的应用程序对每个指标的要求不同。 例如,实时聊天机器人 [1] 优先考虑低 TTFT 以提高响应及时性,而 TPOT 仅在其比人类阅读速度(即 250 字/分钟)更快时才重要。 相反,文档摘要强调低 TPOT 以更快地生成摘要。
因此,考虑到应用程序的 TTFT 和 TPOT 要求,有效的 LLM 服务系统应平衡这些需求并最大化每 GPU 吞吐量,定义为在符合 SLO 实现目标(例如 90%)的情况下为每个 GPU 提供的最大请求率 - 每 GPU 吞吐量越高,每个查询的成本越低。
由于预填充和解码阶段共享 LLM 权重和工作内存,现有的 LLM 服务系统通常将两个阶段共置在 GPU 上,并通过跨请求执行预填充和解码的批处理步骤来最大化整体系统吞吐量(所有用户和请求每秒生成的tokens数)[31, 54]。但是,为了满足延迟要求,这些系统必须过度配置计算资源。为了说明这一点,如图所示解释在使用现有系统 [32] 为 13B LLM 提供服务时,P90 TTFT 和 TPOT 如何随请求率的增加而发生变化,其中工作负载模式和两个延迟约束被设置为采用 LLM 模拟为文章生成简短摘要。
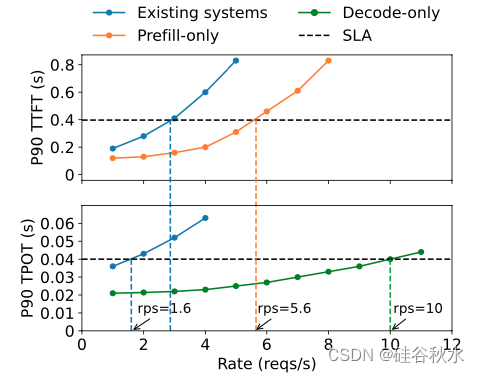
在 SLO 达到 90% 的情况下,单个 A100 GPU 上可实现的最大吞吐量(受 TTFT 和 TPOT 要求中更严格的一个限制)约为每秒 1.6 个请求 (rps)。当每个阶段在单独 GPU 上独立提供服务时,性能形成鲜明对比,如图中橙色和绿色曲线所示,预填充阶段每 GPU 吞吐量为 5.6 rps,解码阶段每 GPU 吞吐量为 10 rps。理想情况下,通过分配 2 个 GPUs 用于预填充,1 个 GPU 用于解码,可以有效地为模型提供 10 rps 的总体吞吐量,或者每个 GPU 3.3 rps,这比现有系统高 2.1 倍。
吞吐量的这个差距主要源于预填充和解码的共置(colocation-) - 两个阶段具有非常不同的计算特性和延迟要求。
首先,共置会导致强烈的预填充解码干扰。预填充步骤通常比解码步骤花费的时间长得多。当一起批处理时,批处理中的解码步骤会因预填充步骤而延迟,从而显著延长其 TPOT;同样,解码步骤的加入会导致 TTFT 大幅增加。即使分别安排它们,问题仍然存在,因为它们开始争夺资源。由于正在进行的预填充任务,等待 GPU 执行的解码任务会受到排队延迟增加的影响,反之亦然。一个阶段优先的调度可能会使另一个阶段的延迟要求无法满足。
其次,预填充和解码计算在延迟要求和对不同形式的并行偏好方面有所不同。然而,将预填充和解码共置会耦合它们的资源分配,并阻止实施更适合满足每个阶段特定延迟要求的不同并行策略。
为了克服这些挑战,建议将 LLM 推理的预填充和解码阶段分解,并将它们分配给单独的 GPU。这种方法有两个好处。首先,在不同的 GPU 上独立操作每个阶段可以消除预填充解码干扰。其次,它允许使用量身定制的资源分配和模型并行策略独立扩展每个阶段,以满足其特定的延迟要求。虽然分解会导致 GPU 之间进行中间状态的通信,但在现代 GPU 集群中,通信开销微不足道,并且如果管理得当,分解可以显着提高每个 GPU 的有效吞吐量。
LLM 服务遵循客户端-服务器架构:客户端将一系列文本作为请求提交给服务器;服务器在 GPU 上托管 LLM,对请求运行推理,并将生成结果响应(或流传输)回客户端。由于独特的预填充解码过程,LLM 服务可能会对 TTFT 和 TPOT 施加激进的服务级目标 (SLO),这些目标会根据应用程序的需求而变化。服务系统必须满足这两个 SLO,同时尽量降低昂贵 GPU 的成本。换句话说,希望服务系统在遵守每个 GPU 的 SLO 实现目标情况下,最大限度地提高每秒处理请求数,即最大限度地提高每个 GPU 的有效吞吐量。
现代 LLM [37, 51] 根据输入序列预测下一个token。此预测涉及计算序列中每个token的隐表示。LLM 可以采用可变数量的输入tokens并行计算其隐表示,其计算工作量随着并行处理的tokens数量超线性增加。无论输入tokens数是多少,计算都需要大量 I/O 来将 LLM 权重和中间状态从 GPU 的 HBM 移动到 SRAM。此过程对于不同的输入大小都是一致的。
预填充步骤处理新序列(通常包含许多tokens),并同时处理这些tokens。与预填充不同,每个解码步骤仅处理上一步生成的一个新token。这导致两个阶段之间存在显着的计算差异。在处理不简短的用户提示时,预填充步骤往往受计算限制。例如,对于 13B LLM,计算 512 个 token 序列的预填充会使 A100 接近计算密集型。相比之下,尽管每一步只处理一个新 token,但解码阶段产生的 I/O 水平与预填充阶段相似,因此受到 GPU 内存带宽的限制。
在这两个阶段,每个 token 位置都会生成中间状态(称为 KV 缓存 [32]),在后面的解码步骤中会再次需要这些中间状态。为了避免重新计算它们,它们被保存在 GPU 内存中。由于内存中 LLM 权重和 KV 缓存的共享使用,大多数 LLM 推理引擎都选择将预填充和解码阶段放在 GPU 上,尽管它们的计算特性截然不同。
在实时在线服务中,多个请求必须在 SLO 内得到满足。批处理和并行化计算是实现低延迟、高吞吐量和高 GPU 利用率的关键。
批处理。当前的服务系统 [9、32、54] 使用一种称为连续批处理的技术。此方法将新请求的预填充与正在进行的请求的解码进行批处理。它提高了 GPU 利用率并最大化整体系统吞吐量 - 所有用户和请求每秒生成的token数。但是,这种方法造成 TTFT 和 TPOT 之间的权衡。连续批处理 [9] 的一种高级版,试图通过将长预填充分解为块并将解码作业与分块预填充附加在一起来平衡 TTFT 和 TPOT - 但本质上,它用 TTFT 换取 TPOT 并且无法消除干扰问题。总之,预填充和解码的批处理不可避免地会导致 TTFT 或 TPOT 的退化。
模型并行。在 LLM 服务中,模型并行通常分为算子内并行性和算子间并行性 [33, 46, 59]。两者都可用于支持更大的模型,但对服务性能的影响可能不同。算子内并行将计算密集型算子(如矩阵乘法)划分到多个 GPU 上,从而加速计算,但会导致大量通信。它减少了执行时间,因此减少了延迟,特别是对于预填充阶段的 TTFT,但需要 GPU 之间的高带宽连接(例如 NVLINK)。算子间并行将 LLM 层组织成阶段,每个阶段都在 GPU 上运行以形成流水线。由于阶段间通信,它会适度增加执行时间,但随每个添加的 GPU,会线性地扩展该系统的比率容量。
设计一个预填充和解码分解为两个阶段的系统,一个关键的考虑因素是管理分解阶段之间的通信,前提是集群设置不同。有两种部署算法:一种用于具有高速跨节点网络的集群,另一种用于缺乏此类基础设施的环境;后者引入了额外的约束。
在配备 Infiniband 具备高节点-亲和度的集群上,跨节点的 KV 缓存传输开销,可以忽略不计,DistServe 可以在任意两个节点上无限制地部署预填和解码实例。针对此类场景提出一种两级部署算法:首先分别优化预填和解码实例的并行配置,以达到阶段级最佳每 GPU 吞吐量;然后,用复制来匹配整体交通率。
然而,由于缺乏简单的分析公式来计算 SLO 实现情况(即满足 TTFT 要求的请求百分比),考虑到工作负载具有不同的输入、输出长度和不规则的到达模式,找到单个实例类型(例如预填实例)的最佳并行配置仍然具有挑战性。通过真实测试平台分析来衡量 SLO 非常耗时。因此,构建一个模拟器来估计 SLO 实现情况,假设事先了解工作负载的到达过程以及输入和输出长度分布。虽然短期间隔无法预测,但较长时间范围内(例如几小时或几天)的工作负载模式通常是可以预测的 [33, 55]。DistServe 从历史请求轨迹中拟合分布,并从分布中重新采样新轨迹作为模拟器的输入工作负载来计算 SLO 实现情况。接下来,DistServe 简单地枚举这些部署,并通过二分搜索和模拟试验找到满足 SLO 实现目标的最大速率。
如图是这个部署算法总览:

一种直接的解决方案是始终将预填充和解码实例共置在同一节点上,使用 NVLINK,这通常在 GPU 节点内可用。对于大型模型,例如具有 175B 参数(350GB),可能无法在 8-GPU 节点(80G×8 = 640G < 350×2GB)中托管(host)一对预填充和解码实例。那么,将其作为额外的放置约束,并与模型并行算法共同优化。如图所示为低节点亲和度的部署算法总览:

关键见解是 KV 缓存传输仅发生在预填充和解码实例的相应层之间。利用算子间并行性,将层分组为阶段,并将每个实例划分为段(称为实例分段),每个分段维护一个特定的操作间(inter-op)阶段。通过将同一阶段的预填充和解码段共置在单个节点内,可以强制中间状态的传输仅通过 NVLINK 进行。在节点内部,为同一实例的分段设置相同的并行和资源分配。考虑到每个节点的 GPU 数量通常有限(通常为 8 个),可以枚举一个节点内的可能配置,并使用模拟器确定产生最佳吞吐量的那个。
如上图算法中所述,首先枚举操作间并行以获取所有可能的实例段。对于每个段,调用 get_intra_node_configs 获取所有可能的节点内并行配置。然后用模拟找到最佳配置并复制它以满足目标交通率。
DistServe 的运行时架构如图所示。DistServe 采用简单的 先来先服务(FCFS) 调度策略。所有传入请求都到达集中控制器,然后分派到队列最短的预填充实例进行预填充处理,接着分派到负载最小的解码实例进行解码步骤。此设置虽然简单,但经过了优化,并针对实际工作负载的细微差别进行了多项关键增强。
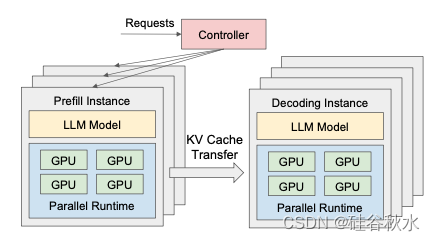
DistServe 是一个端到端的 LLM 分布式服务系统,具有部署算法模块、RESTful API 前端、编排层和并行执行引擎等。部署算法模块、API 前端和编排层由 6.5K 行 Python 代码实现。并行执行引擎由 8.1K 行 C++/CUDA 代码实现。
部署算法模块实现了前面提到的算法和模拟器,为特定模型和集群设置提供部署决策。API 前端支持与 OpenAI API 兼容的接口,客户端可以在其中指定采样参数,例如最大输出长度和温度。编排层管理预填充和解码实例,负责请求调度、KV 缓存传输和结果传递。它利用 NCCL [6] 进行跨节点 GPU 通信,利用异步 CudaMemcpy 进行节点内通信,从而避免在传输过程中阻塞 GPU 计算。每个实例都由一个并行执行引擎驱动,该引擎使用 Ray [35] actor 实现 GPU 工作器,以分布方式执行 LLM 推理并管理 KV 缓存。它集成了许多最新的 LLM 优化,如连续批处理 [54]、Flash Attention [20]、Paged Attention [32],并支持流行的开源 LLM,如 OPT [56] 和 LLaMA [51]。















 997
997

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









