






点击上方“AI公园”,关注公众号,选择加“星标“或“置顶”
导读作者:Sik-Ho Tsang
编译:ronghuaiyang
使用可变形卷积,可以提升Faster R-CNN和R-FCN在物体检测和分割上的性能。只要增加很少的计算量,就可以得到性能的提升,非常好的文章,值的一看。
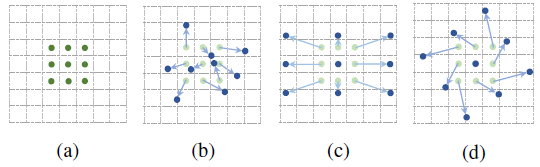
(a) Conventional Convolution, (b) Deformable Convolution, (c) Special Case of Deformable Convolution with Scaling, (d) Special Case of Deformable Convolution with Rotation
传统/常规卷积基于定义的滤波器大小,在输入图像或一组输入特征图的预定义矩形网格上操作。该网格的大小可以是3×3和5×5等。然而,我们想要检测和分类的对象可能会在图像中变形或被遮挡。
在DCN中,网格是可变形的,因为每个网格点都可以通过一个可学习的偏移量移动。卷积作用于这些移动的网格点上,因此称为可变形卷积,类似于可变形RoI池化的情况。通过使用这两个新模块,DCN提高了DeepLab、Faster R-CNN、R-FCN、和FPN等的准确率。
最后,MSRA使用DCN+FPN+Aligned Xception在COCO Detection Challenge中获得第二名,Segmentation Challenge中获得第三名。发表于2017 ICCV,引用次数超过200次。
1. 可变形卷积
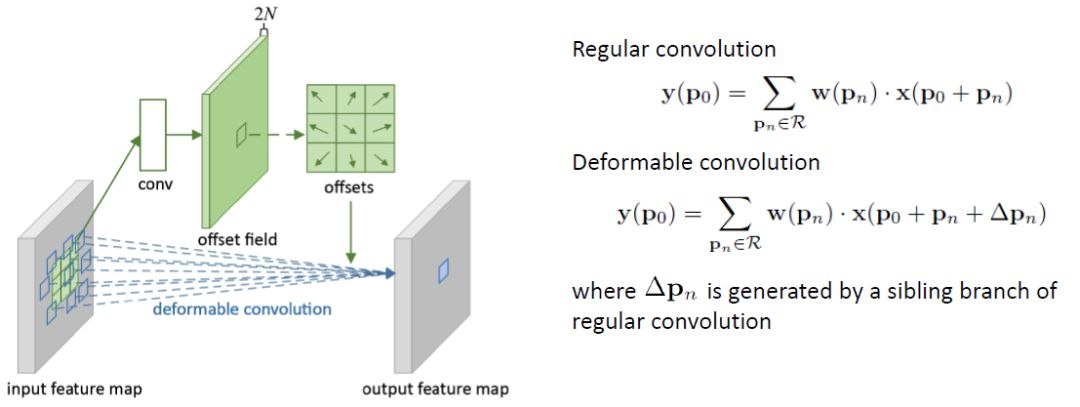
可变形卷积
规则的卷积是在一个规则的网格R上操作的。
对R进行可变形卷积运算,但每个点都增加一个可学习的偏移∆pn。
卷积生成2N个特征图,对应N个2D个偏移量∆pn(每个偏移量对应有x-方向和y-方向)。
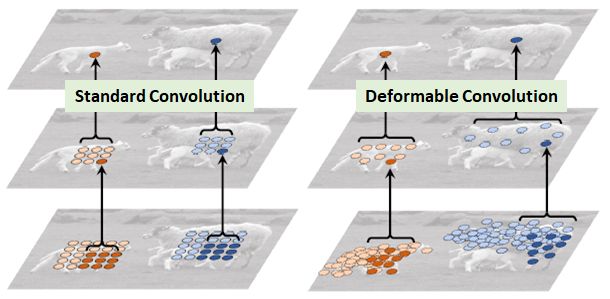
如上所示,可变形卷积将根据输入图像或特征图在不同位置为卷积选择值。
与Atrous convolution相比,Atrous convolution在卷积过程中具有较大但固定的膨胀值。(Atrous convolution也称为dilated convolution或hole算法。
与Spatial Transformer Network (STN)比较:STN对输入图像或特征图进行变换,而可变形卷积可以被视为一个非常轻量级的STN。
2. Deformable RoI Pooling
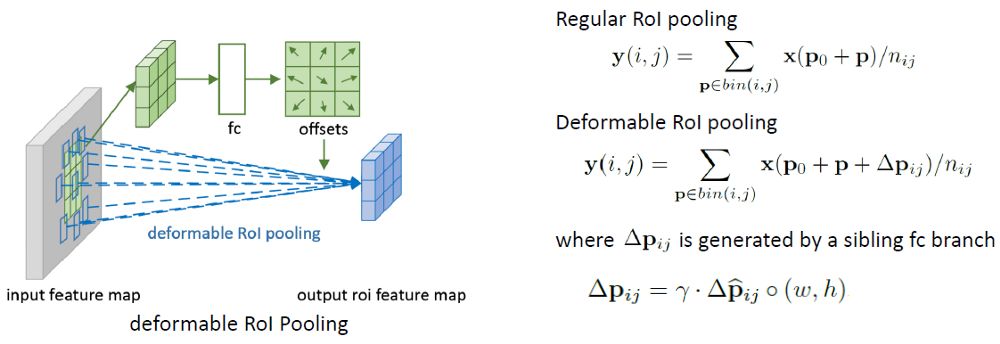
Deformable RoI Pooling
常规RoI Pooling将任意大小的输入矩形区域转换为固定大小的特征。
在Deformable RoI Pooling中,首先,在top path中,我们仍然需要常规的RoI Pooling来生成池化的feature map。
然后,使用一个全连接(fc)层生成归一化的偏移∆p̂ij,然后转化为偏移∆pij(方程在右下角)其中γ= 0.1。
偏移量归一化是必要的,使偏移量的学习不受RoI大小的影响。
最后,在底部路径,我们执行deformable RoI pooling。输出特征图是基于具有增强偏移量的区域进行池化的
3. Deformable Positive-Sensitive (PS) RoI Pooling
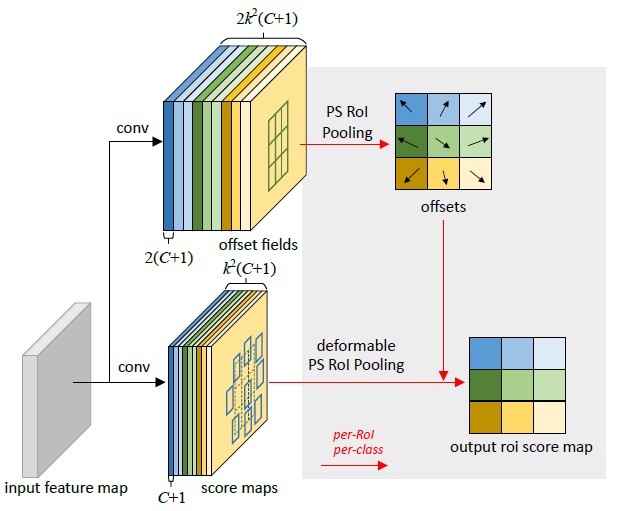
Deformable Positive-Sensitive (PS) RoI Pooling (在这里颜色很重要)
对于原始的R-FCN中的Positive-Sensitive (PS) RoI pooling,所有的输入特征图首先转换为每个类别k²个得分图(假设背景类总共C + 1个类别)(最好是读一下R-FCN,理解一下最初的PS RoI pooling)
在deformable PS RoI pooling中,首先,在顶部路径上,和原始的相似, 卷积用于生成2k²(C + 1)得分图。
这意味着,对于每个类别,有k²个特性图,这些特征图代表了我们要学习的物体的偏移量{上左(TL),上中(TC), . .,右下(BR)}。
偏移量(顶部路径)的原始的PS RoI Pooling是使用图中相同的区域和相同的颜色来池化的。我们在这里得到偏移量。
最后,在底部路径中,我们执行deformable PS RoI pooling来池化偏移量增强的特征图。
4. 可变形卷积用于ResNet-101 & Aligned-Inception-ResNet
4.1. Aligned-Inception-ResNet
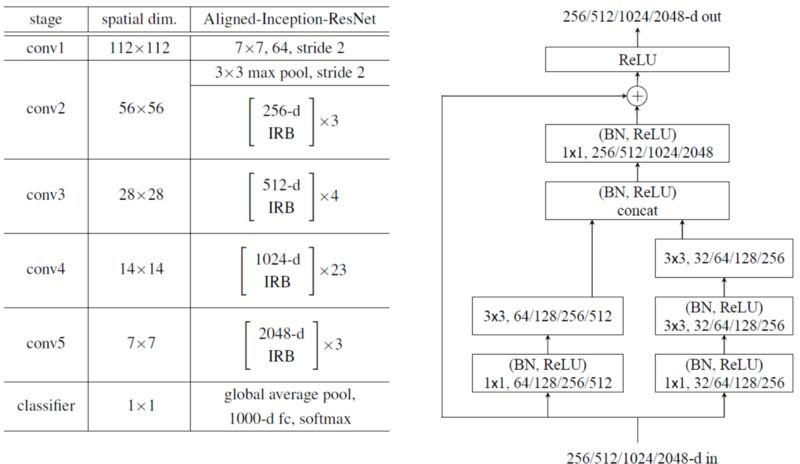
在原始的Inception-ResNet中,存在对齐问题,对于靠近输出的特征图上的单元格,其在图像上的投影空间位置与其感受野中心位置不一致。
在Aligned-Inception-ResNet中,我们可以看到,在Inception Residual Block (IRB)中,所有用于分解的非对称卷积(例如:1×7,7×1,1×3,3×1 conv)都被删除了。如上所示,只使用了一种IRB类型。同样,IRB的数量也不同于incep-resnet -v1或incep-resnet -v2。
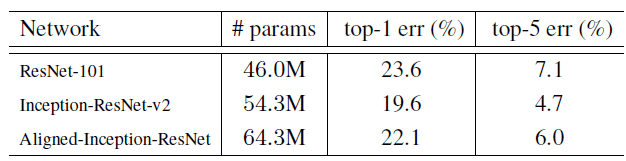
Aligned-Inception-resnet的错误率低于ResNet-101。
虽然Aligned-Inception-resnet的错误率高于Inception-resnet -v2,Aligned-Inception-resnet解决了对齐问题。
4.2. 修改ResNet-101 & Aligned-Inception-ResNet
现在我们得到了两个主要的特征提取方法:ResNet-101和Aligned-Inception-resnet,这最初用于图像分类任务。
但输出特征图太小,不利于目标检测和分割任务。
Atrous convolution(或dilated convolution)在最后一个block (conv5)的开头进行reduce, stride由2变为1。
因此,最后一个卷积块的有效步长由32像素降低到16像素,提高了feature map的分辨率。
4.3. 不同的物体检测器
特征提取后,使用不同的物体检测器或分割方案,如DeepLab、class-aware RPN(或被简化的SSD)、Faster R-CNN和R-FCN。
5. 对比研究和结果
5.1. 使用可变形卷积在不同数量的最后几层上
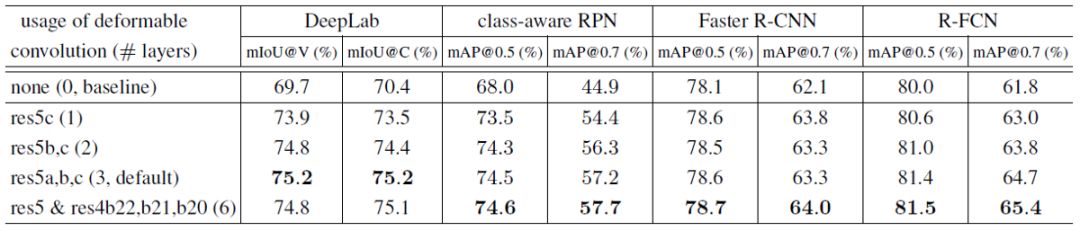
在ResNet-101中最后1、2、3和6个卷积层(3×3滤波器)中使用可变形卷积的结果
3和6个可变形卷积也很好。最后,作者选择3,因为可以很好地权衡用于不同的任务。
我们还可以看到DCN改进了DeepLab,class-aware RPN(或认为是简化的SSD),fast - R-CNN和R-FCN
5.2. 可变形卷积偏移距离分析
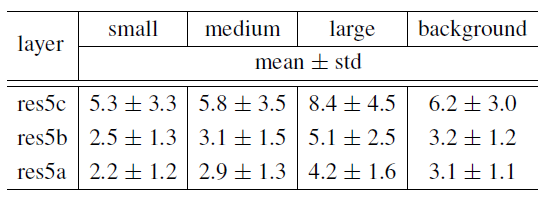

上述分析亦说明了DCN的有效性。首先,根据ground truth bound box标注和滤波器中心的位置,将可变形卷积滤波器分为四类:small、medium、large和background。
然后测量膨胀值(偏移距离)的均值和标准差。
发现可变形滤波器的感受野大小与目标大小相关,说明可以有效地从图像内容中学习变形。
背景区域的滤波器大小介于中、大物体之间,说明识别背景区域需要较大的感受野。

与可变形RoI pooling类似,现在部分被偏移以覆盖非刚性物体。
5.3. 在PASCAL VOC上和Atrous卷积对比
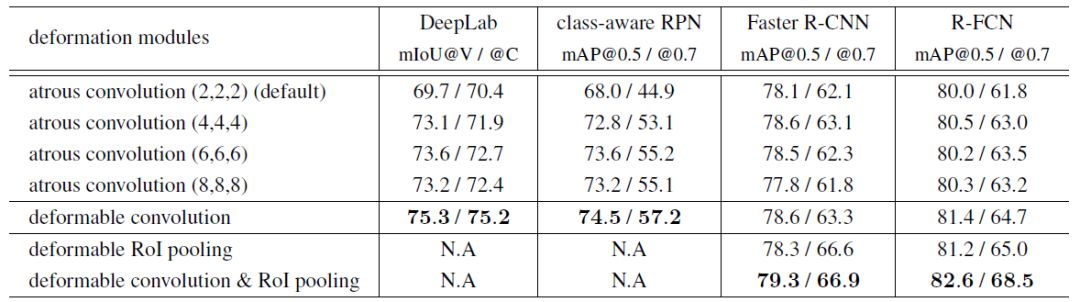
只使用可变形卷积:DeepLab,class-aware RPN, R-FCN使用可变形卷积都得到了改进,已经优于使用atrous convolution实现的DeepLab,RPN和R-FCN。与atrous convolution相比,Faster R-CNN使用可变形卷积更具有竞争优势。
只使用Deformable RoI Pooling:在Faster R-CNN和R-FCN中只使用Deformable RoI Pooling。对于Faster-RCNN,两者差不多,对于R-FCN,Deformable RoI Pooling更好。
使用可变形卷积和Deformable RoI Pooling:对于Faster R-CNN和R-FCN,使用可变卷积核可变ROI池化效果是最好的。
5.4. PASCAL VOC上的模型复杂度和运行时间
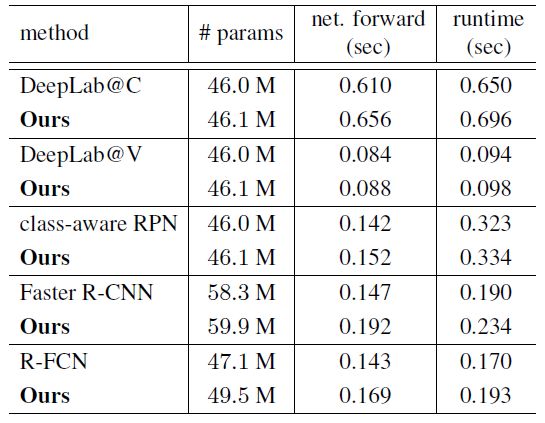
模型复杂度和运行时间
可变形卷积只在模型参数和计算上增加很小的开销
除了增加模型参数之外,显著的性能改进来自于模型几何变换的能力。
 —
END—
—
END—
英文原文:https://towardsdatascience.com/review-dcn-deformable-convolutional-networks-2nd-runner-up-in-2017-coco-detection-object-14e488efce44

请长按或扫描二维码关注本公众号
喜欢的话,请给我个好看吧!![]()

















 3716
3716

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









